YARN作为Hadoop集群的御用调度器,在整个集群的资源管理上立下了汗马功劳。今天我们用大白话聊聊YARN存在意义。
有了机器就有了资源,有了资源就有了调度。举2个很鲜活的场景:
- 在单台机器上,你开了3个程序,分别是A、B、C,3个程序把资源基本上耗光了,你再想开个D,系统没有资源了,或者变的很卡,所以你关掉了A和B,腾出来的资源让D用,这就是人肉调度。
- 由多台机器上组成的集群,情况更加复杂,一共有多少CPU,MEM,怎么把指定的应用跑在合适的机器上,总会想均衡,不要累死的累死,闲死的闲死,这就要调度,几台还好,人肉可以登录过来,登录过去看着每台跑的应用和用的资源去调度,要是成百上千台的机器呢,人肉那就累死了。
还是搞个自动化的调度工具吧,想想只要干好几个事,简单说也不难:
- 资源管理:要把所有机器的资源都管理起来,起码知道这个分布式的集群有多少资源,摸清家底。
- 资源监控:要时时刻刻监控当前用了哪些资源,哪些资源还没用。
- 分配资源:应用要申请了,你要给资源,给多少,是不是够用,让他跑到哪台机器上。
- 回收资源:不能让应用一直占着,你要时刻问问或者让他上报,用完了要及时归还。
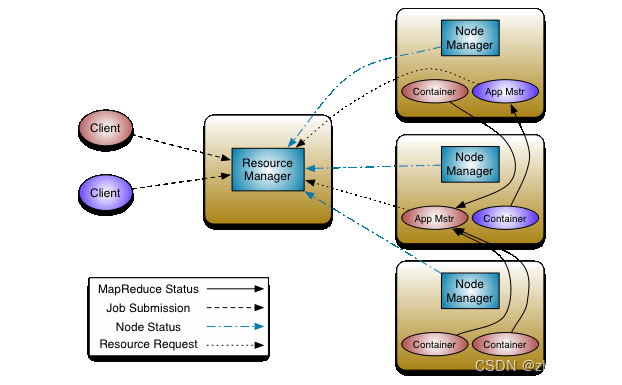
简单的想来YARN就是这么多,基本上每个资源调度器都是干的主要这些事,ResourceManager就是集群老大,在台机器上安插小弟NodeManager,对机器进行资源管理和任务管理,定时向老大汇报各个机器资源情况;一个ApplicationMaster就是一个任务的老大,他负责和ResourceManger老大交涉,比如我需要多少资源,老大都同意小弟还不照做;NodeManager为ApplicationMaster启动若干Container执行task;这些task向他的老大ApplicationMaster汇报状态;当干完活了,释放资源吧,ApplicationMaster告诉ResourceManager你可以回收资源了,接着老大让小弟NodeManger清理现场回收资源。
下面的架构图来自ApacheHadoop官网,写了组件之间的行为,没有写具体工作流程,大家看着上面内容大致理解了,其实原理很简单,当然具体实现有难度,不然成不了角。
参考文章