一、死锁定位
1 什么是死锁?
死锁指A线程想使用资源但是被B线程占用了,B线程线程想使用资源被A线程占用了,导致程序无法继续下去了。
1.1 程序举例
死锁程序实例
public class Deadlock {
public static void main(String[] args) {
Object lock1 = new Object();
Object lock2 = new Object();
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
synchronized (lock1){
System.out.println("线程一得到了lock1");
try{
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程一获取lock2");
synchronized (lock2){
System.out.println("线程一得到了lock2");
}
}
}
});
thread1.start();
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
synchronized (lock2){
System.out.println("线程二得到了lock2");
try{
//让线程2,获取锁1
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程二获取lock1");
//尝试获取lock1
synchronized (lock1){
System.out.println("线程二得到了lock1");
}
}
}
});
thread2.start();
}
}
1.2 死锁产生条件
形成死锁的条件:
- 互斥条件:资源是独占的且排他使用,进程互斥使用资源,即任意时刻一个资源只能给一个进程使用,其他进程若申请一个资源,而该资源被另一进程占有时,则申请者等待直到资源被占有者释放。
- 不可剥夺条件:进程所获得的资源在未使用完毕之前,不被其他进程强行剥夺,而只能由获得该资源的进程资源释放。
- 请求和保持条件:进程每次申请它所需要的一部分资源,在申请新的资源的同时,继续占用已分配到的资源。
- 循环等待条件:在发生死锁时必然存在一个进程等待队列{P1,P2,…,Pn},其中P1等待P2占有的资源,P2等待P3占有的资源,…,Pn等待P1占有的资源,形成一个进程等待环路,环路中每一个进程所占有的资源同时被另一个申请,也就是前一个进程占有后一个进程所深情地资源。
以上给出了导致死锁的四个必要条件,只要系统发生死锁则以上四个条件至少有一个成立。事实上循环等待的成立蕴含了前三个条件的成立,似乎没有必要列出然而考虑这些条件对死锁的预防是有利的,因为可以通过破坏四个条件中的任何一个来预防死锁的发生。
2 使用jdk内置工具检测死锁
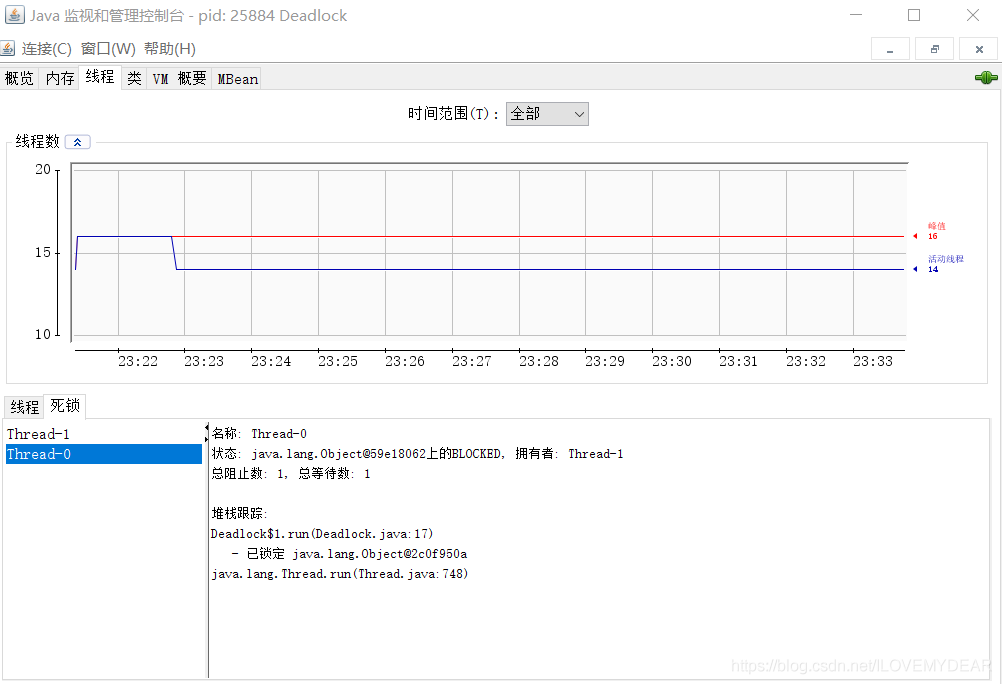
2.1 方法一:jconsole检测死锁
jconsole在jdk的安装路径中就能找到:jdk/bin/jconsole.exe
打开之后,可以直接检测死锁,Thread-0、Thread-1位我们创建的线程

检测结果:
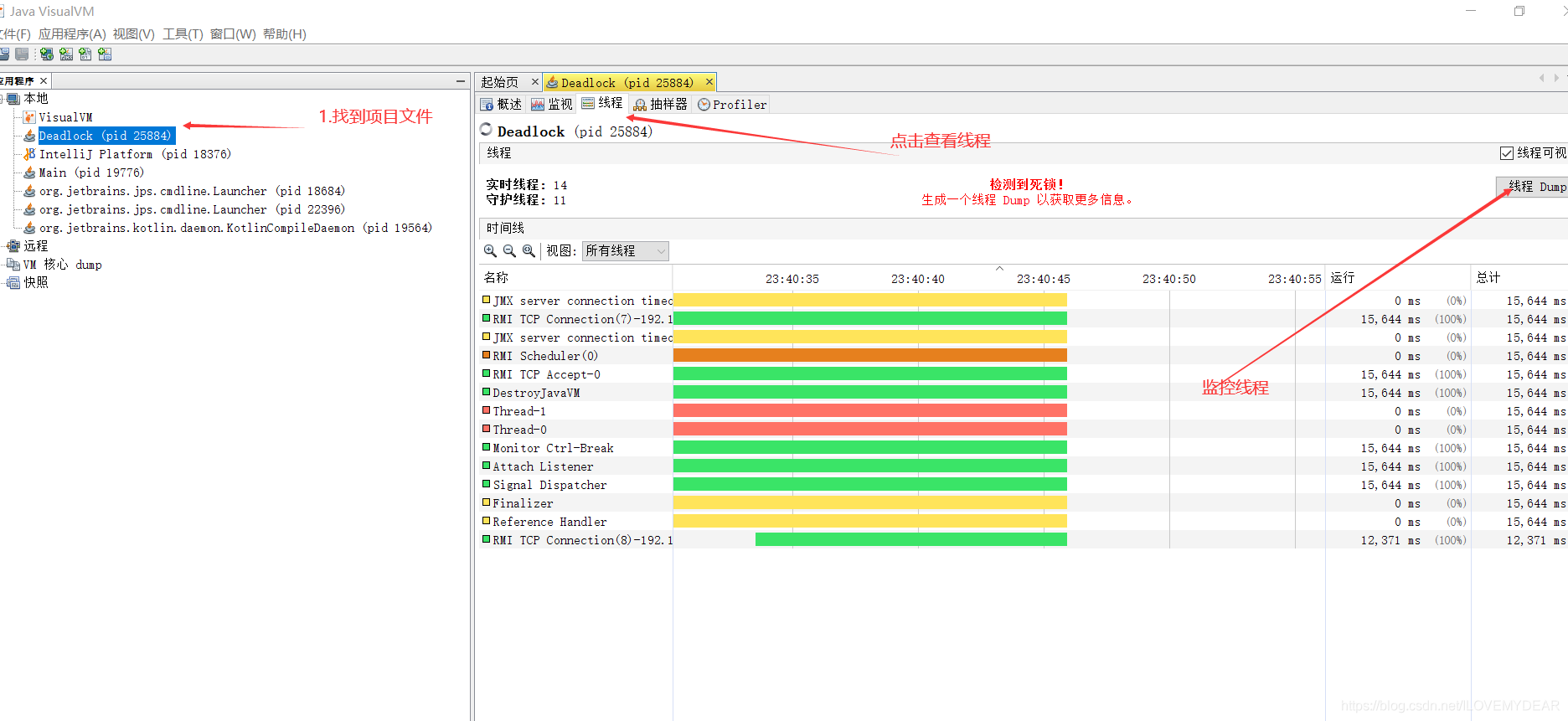
2.2 方法二:jvisualvm.exe
jvisualvm在jdk的安装路径中就能找到:jdk/bin/jvisualvm.exe。jvisualvm的功能比较细,比较全面,但是加载有点慢!
使用步骤:
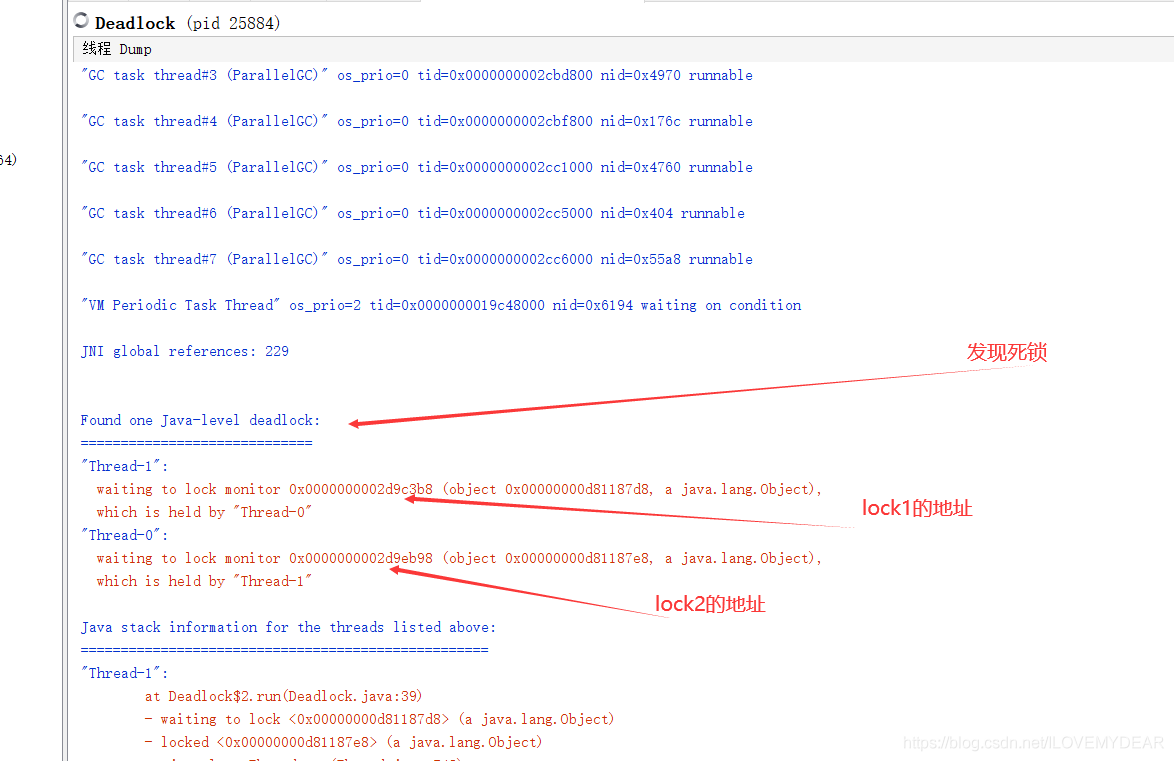
可以在里面看到是该项目代码的第39行出现了死锁。
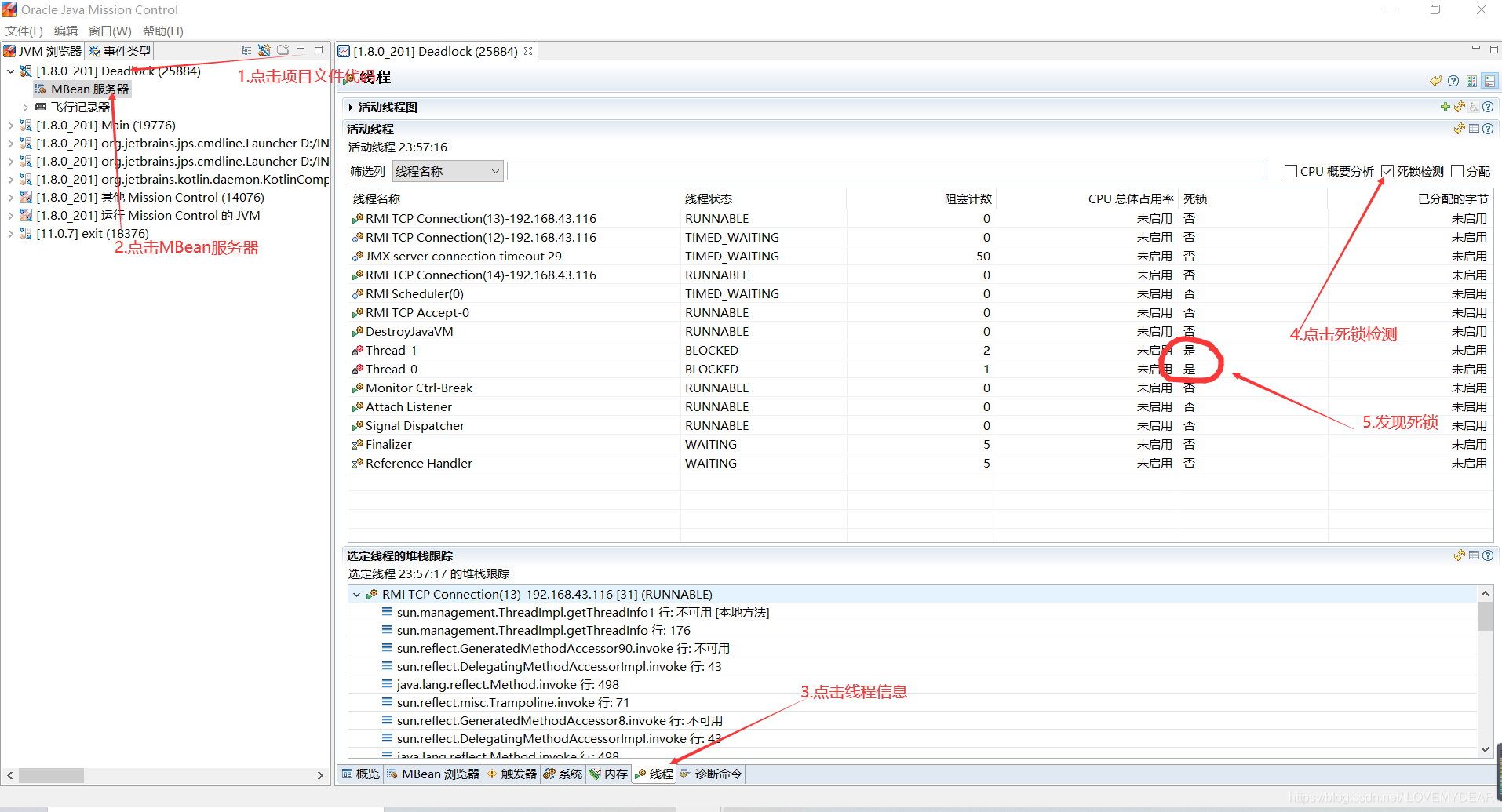
2.3 方法三:jmc.exe
jmc在jdk的安装路径中就能找到:jdk/bin/jmc.exe。jmc可以对所以死锁进行判断,但是没有给出解决方法。
使用步骤:
3 死锁解决方法
通过死锁的形成条件来解决死锁问题,从根源上消除死锁。
- 请求拥有条件(一个线程所持有一个资源后又试图请求另一个资源)可修改
- 环路等待条件(多个线程在获取资源时形成一个环形链)可修改
举例修改:修改环路等待条件,即让线程二和线程一竞争同一个锁,修改为并行,这样避免出现环路
public class Deadlock {
public static void main(String[] args) {
Object lock1 = new Object();
Object lock2 = new Object();
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
synchronized (lock1){
System.out.println("线程一得到了lock1");
try{
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程一获取lock2");
synchronized (lock2){
System.out.println("线程一得到了lock2");
}
}
}
});
thread1.start();
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
synchronized (lock1){
//让线程二和线程一竞争同一个锁,修改为并行,这样避免出现环路
System.out.println("线程二得到了lock1");
try{
//让线程2,获取锁1
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程二获取lock1");
//尝试获取lock1
synchronized (lock2){
System.out.println("线程二得到了lock2");
}
}
}
});
thread2.start();
}
}
二、CPU飙高定位
我们用一个死循环来模拟CPU飙高问题,代码如下:
/**
* CPU过高程序的demo,死循环
*/
public class JstackCase {
private static ExecutorService executorService = Executors.newFixedThreadPool(5);
public static void main(String[] args) {
Task task1 = new Task();
Task task2 = new Task();
executorService.execute(task1);
executorService.execute(task2);
}
public static Object lock = new Object();
static class Task implements Runnable{
public void run() {
synchronized (lock){
long sum = 0L;
while (true){
sum += 1;
}
}
}
}
}
1 步骤一:定位占用CPU最高的服务进程
找到cpu占用比较高的进程:top -c,一般异常的进程cpu的占用会很高,记录下这进程的PID。
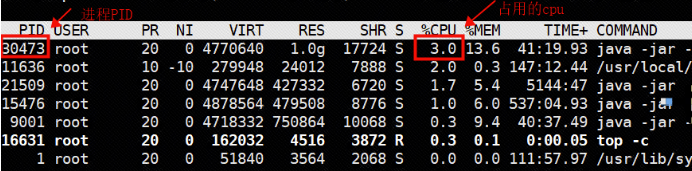
根据上图,我们可以找出pid为21340的Java进程,它占用了最高的CPU资源。注意,这里是进程,不是线程。
2 步骤二:查看该pid进程下,各个线程的CPU使用情况
通过top -Hp 21340可以查看该进程下,各个线程的cpu使用情况,如下:
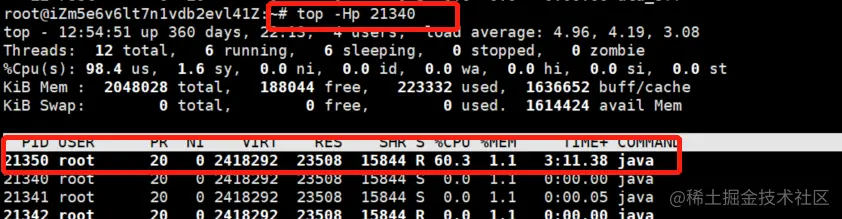
可以发现pid为21350的线程,CPU资源占用最高。
需要将上图中的线程ID,转换成16进制(如:21350转为16进制=5366),然后在下面的第四步(jstack 进程id > ps.txt)导出的文件中搜索,就可以定位到具体有问题的线程、类。
3 步骤三: jstack pid 查看当前java进程的堆栈状态
通过top命令定位到cpu占用率较高的线程之后,接着使用jstack pid命令来查看当前java进程的堆栈状态,jstack 21350后,内容如下:
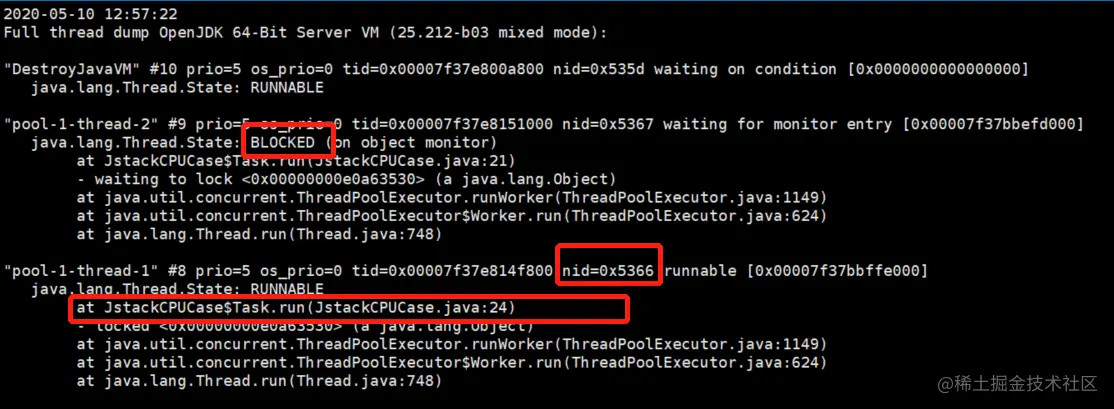

4 步骤四:将堆栈信息打到一个文件里进行分析
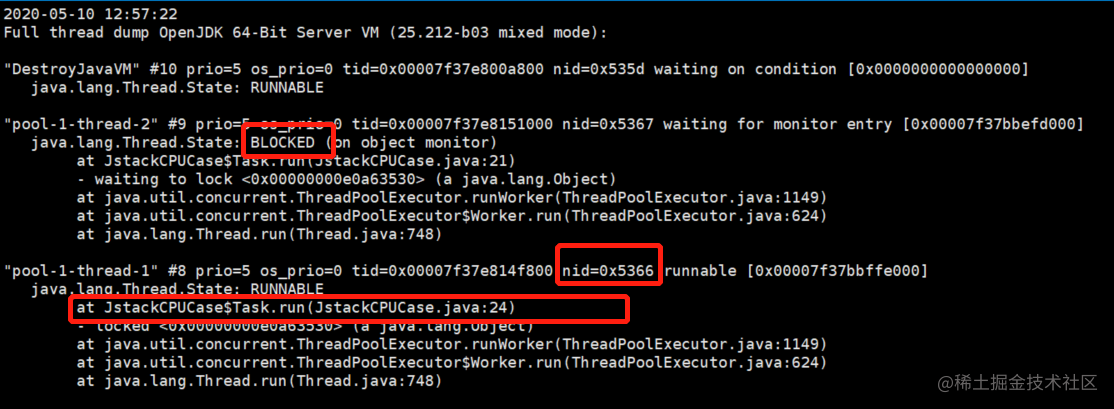
其实,前3个步骤,堆栈信息已经出来啦。但是一般在生成环境,我们可以把这些堆栈信息打到一个文件里进行分析:jstack -l [PID] >/tmp/log.txt
我们把占用cpu资源较高的线程pid(本例子是21350),将该pid转成16进制的值为 5366。在thread dump中,每个线程都有一个nid,我们找到对应的nid(5366),发现一直在跑(24行),这时我们就可以去程序中查看代码了。
三、内存泄漏 & 内存溢出
1 内存泄漏
1.1 什么是内存泄漏(Memory Leak)
- 严格来说,只有对象不会再被程序用到了,但是GC又不能回收他们的情况,才叫内存泄漏。
- GC Roots集合所连接的对象中有一些我们不想用了,但是又忘记断开了他们的引用,那么也无法被垃圾回收,就造成了内存泄漏
- 但实际情况很多时候一些不太好的实践(或疏忽)会导致 对象的生命周期变得很长甚至导致内存溢出OOM,也可以叫做宽泛意义上的内存泄漏。
- 内存泄漏的堆积最终会导致内存溢出。
1.2 内存泄漏举例
因为HotSpot虚拟机使用的是可达性分析算法,因此举引用计数算法的循环引用是不恰当的,下面列举几种例子:
- 单例模式:单例的生命周期和应用程序是一样长的,所以单例程序中,如果持有对外部对象的引用的话,那么这个外部对象是不能被回收的,则会导致内存泄漏的产生。
- 一些提供close的资源未关闭导致内存泄漏 :如:数据库连接( dataSourse. getConnection()),网络连接(socket)和io连接必须手动close,否则是不能被回收的。
2 内存溢出(Out Of Memory)
2.1 什么是内存溢出(Out Of Memory)
- IavaDoc中对OutOfMemoryError的解释是:没有空闲内存,并且垃圾收集器也无法提供更多内存。
- 由于GC一直在发展,所有一般情况下,除非应用程序占用的内存增长速度非常快,造成垃圾回收已经跟不上内存消耗的速度,否则不太容易出现OOM的情况。
内存没有空闲的情况分析
- Java虚拟机的堆内存设置不够;
- 代码中创建了大量大对象,并且长时间不能被垃圾收集器收集(存在被引用)。
- 内存泄漏的堆积最终会导致内存溢出。
在抛出0utOfMemoryError之 前,通常垃圾收集器会被触发,尽其所能去清理出空间
- 在抛出0utOfMemoryError之 前,通常垃圾收集器会被触发,尽其所能去清理出空间。
- 但也不是在任何情况下垃圾收集器都会被触发的。比如,我们去分配一个超大对象,类似一个超大数组超过堆的最大值,JVM可以判断出垃圾收集并不能解决这个问题,所以直接拋出OutOfMemoryError。
2.2 内存溢出发生的地方
JVM 运行时数据区主要包括:
- 程序计数器
- 虚拟机栈;
- 本地方法栈;
- Java堆;
- 方法区(运行时常量池是方法区的一部分);
- 直接内存;(直接内存并不是运行时数据区的一部分,但这部分内存也会被频繁的使用)
在JVM中,除了程序计数器之外,其他几个运行时数据区的区域都有发生OOM(内存溢出)异常的可能,如下:
- 堆溢出;
- 虚拟机栈和本地方法栈溢出;
- 方法区和运行时常量池溢出;
- 直接内存溢出;
3 内存泄漏、内存溢出、CPU飙高三者之间的关系
在实际开发过程中,如果服务器上的一个java程序,占用的CPU突然飙升,导致服务器宕机。大概率是Java程序内存溢出,JVM频繁的进行FullGC尝试释放内存空间,进而导致的CPU飙升。
4 内存溢出 & 内存泄漏 定位
4.1 方式一:dump文件 + jvisualvm(线下分析)
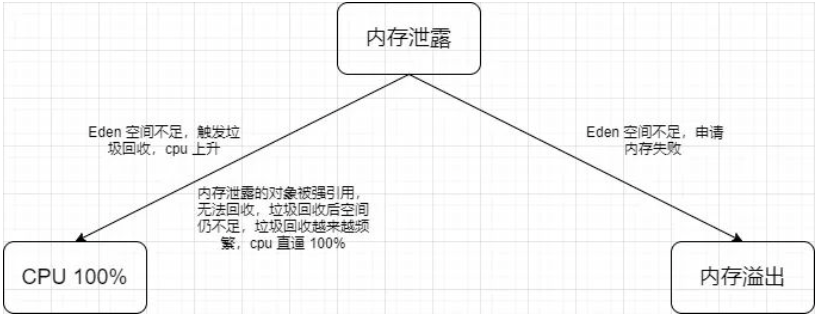
步骤一:设置jvm参数,OutOfMemoryError时打印当前内存快照到指定文件中。
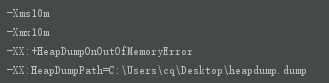
不断往堆内存中添加数据,报OutOfMemoryError后会将当前内存快照输出到指定目录的heapdump.dump文件中
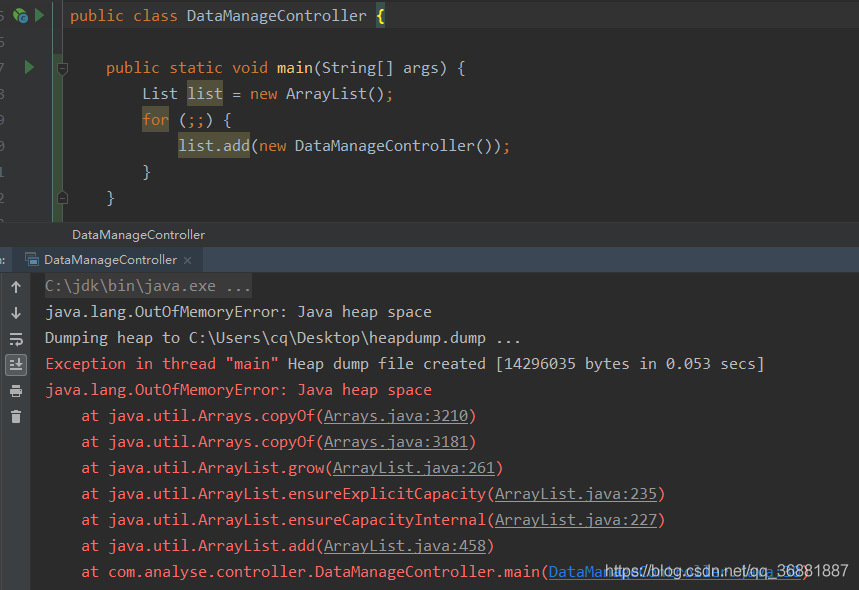
步骤二:打开jvisualvm.exe,点击文件->装入,选中.dump文件打开。
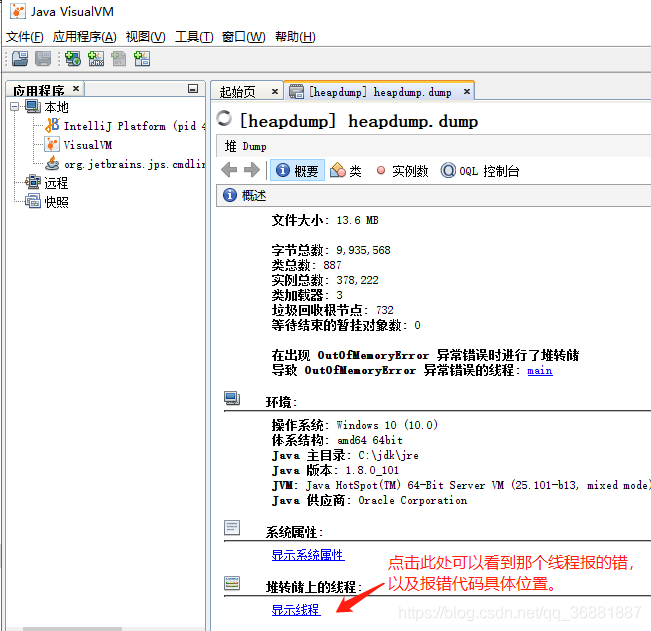
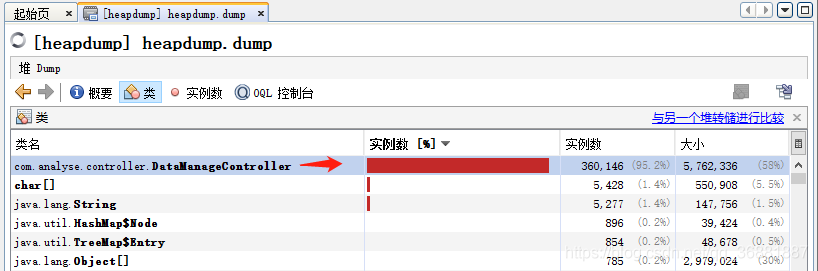
步骤三:通过“类”来查看到类的实例数量,36w多个实例。。。
4.2 方式二:CPU飙高定位 + jmap生成dump(jmap会暂停JVM 不推荐)
在线上的应用,内存往往会设置得很大,这样发生OOM再把内存快照dump出来的文件就会很大,可能大到在本地的电脑中已经无法分析了(因为内存不足够打开这个dump文件)。这里介绍另一种处理办法。
步骤一:首先我们需要利用CPU飙高的分析方法,定位是哪个进程CPU飙高,获取其pid
步骤二:使用jstat分析gc活动情况
jstat是一个统计java进程内存使用情况和gc活动的工具,参数可以有很多,可以通过jstat -help查看所有参数以及含义
> jstat -gcutil -t -h8 24836 1000
Timestamp S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
29.1 32.81 0.00 23.48 85.92 92.84 84.13 14 0.339 0 0.000 0.339
30.1 32.81 0.00 78.12 85.92 92.84 84.13 14 0.339 0 0.000 0.339
31.1 0.00 0.00 22.70 91.74 92.72 83.71 15 0.389 1 0.233 0.622
上面是命令意思是输出gc的情况,输出时间,每8行输出一个行头信息,统计的进程号是24836,每1000毫秒输出一次信息。
输出信息列的含义是:
- Timestamp是距离JCM启动的时间
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
S0、S1、E是新生代的两个Survivor和Eden,O是老年代区,M是Metaspace,CCS使用压缩比例。这里虽然发生了gc,但是老年代内存占用率根本没下降,说明有的对象没法被回收(当然也不排除这些对象真的是有用)。
虽然我们经过上面的分析可以知道,是频繁 GC 导致的 CPU 占满,但是并没有找到问题的根本原因,因此也无从谈起如何解决。GC 的直接原因是内存不足,怀疑算法程序存在内存泄漏。
步骤三:使用jmap工具dump出内存快照
jmap可以把指定java进程的内存快照dump出来,效果和第一种处理办法一样,不同的是它不用等OOM就可以做到,而且dump出来的快照也会小很多。
jmap -dump:live,format=b,file=heap.bin 24836
jmap是一个多功能命令,它可以生成Java应用的dump文件,也可以查看堆内对象的统计信息、查看ClassLoader信息和finalizer队列等,但是jmap会将整个JVM的线程全部暂停,所以在生产环境中慎重jmap命令。
四、栈溢出
1 什么是栈溢出
- 栈存放什么:栈存储运行时声明的变量——对象引用(或基础类型, primitive)内存空间, 栈的实现是先入后出的。
- 堆存放什么:堆分配每一个对象内容(实例)内存空间。
栈溢出两种情况
-
线程请求的栈深度大于虚拟机允许的最大深度 StackOverflowError ==》java.lang.StackOverflowError
-
虚拟机在扩展栈深度时,无法申请到足够的内存空间 OutOfMemoryError
2 栈溢出定位
方式一:栈内存是线程私有,尝试是否能够从线程堆栈信息查处具体原因
# 查看java进程
jps -l
76017 sun.tools.jps.Jps
48469
59846 org.apache.catalina.startup.Bootstrap
75358 org.jetbrains.jps.cmdline.Launcher
# dump出线程队栈信息
jstack -l 59846 >> /Users/xxx/Desktop/dump.log
如果内存溢出异常时间太短,可以将栈内存增加到100M,同时加上打印GC详情信息
-XX:+PrintGCDetails -Xss100M
[GC (Allocation Failure) [PSYoungGen: 889056K->81675K(953344K)] 2710703K->1903340K(3749888K), 0.1361416 secs] [Times: user=0.06 sys=0.55, real=0.14 secs]
[GC (Allocation Failure) [PSYoungGen: 629515K->281504K(972800K)] 2451180K->2179106K(3769344K), 0.1584534 secs] [Times: user=0.21 sys=0.55, real=0.15 secs]
[GC (Allocation Failure) [PSYoungGen: 829344K->282720K(952320K)] 2726946K->2450456K(3748864K), 0.2698855 secs] [Times: user=0.36 sys=1.07, real=0.27 secs]
[GC (Allocation Failure) [PSYoungGen: 837728K->290944K(966144K)] 3005464K->2729323K(3762688K), 0.2007395 secs] [Times: user=0.65 sys=0.64, real=0.20 secs]
[Full GC (Ergonomics) [PSYoungGen: 290944K->0K(966144K)] [ParOldGen: 2438379K->955318K(2184704K)] 2729323K->955318K(3150848K), [Metaspace: 103144K->103144K(1142784K)], 0.8445731 secs] [Times: user=1.65 sys=1.29, real=0.85 secs]
[GC (Allocation Failure) [PSYoungGen: 555008K->291040K(974336K)] 1510326K->1246358K(3159040K), 0.1659465 secs] [Times: user=0.90 sys=0.12, real=0.16 secs]
[GC (Allocation Failure) [PSYoungGen: 870624K->304192K(982528K)] 1825942K->1533716K(3167232K), 0.2576112 secs] [Times: user=0.93 sys=0.72, real=0.25 secs]
[GC (Allocation Failure) [PSYoungGen: 883776K->304384K(993280K)] 2113300K->1820275K(3177984K), 0.2969893 secs] [Times: user=1.07 sys=0.67, real=0.30 secs]
[GC (Allocation Failure) [PSYoungGen: 895744K->309952K(993792K)] 2411635K->2112280K(3178496K), 0.3110348 secs] [Times: user=1.20 sys=0.67, real=0.31 secs]
[Full GC (Ergonomics) [PSYoungGen: 309952K->0K(993792K)] [ParOldGen: 1802328K->2060148K(2796544K)] 2112280K->2060148K(3790336K), [Metaspace: 103144K->103144K(1142784K)], 1.0683581 secs] [Times: user=3.92 sys=0.06, real=1.07 secs]
2022-07-17 20:51:27.481 [http-nio-8081-exec-3] ERROR
从日志可以看到栈内存溢出前,一直尝试做FullGC,持续了大约5~8秒。然后我们在异常溢出前继续dump出线程堆栈信息,就可以清楚的定位到哪个对象产生的问题。
参考:http://www.360doc.com/content/22/0616/12/10087950_1036248397.shtml
参考:https://blog.csdn.net/qq_36881887/article/details/106738536