AWS 的cloudfront是如何实现S3桶的file缓存的
CloudFront介绍:
CloudFront 边缘站点 已经包含了超过 410 个节点(超过 400 个边缘站点和 13 个区域性边缘缓存)的全球网络,该网络覆盖 47 个国家/地区的 90 余个城市。目的是通过边缘站点来就近提供给使用者需要的访问资源,来提高使用者体验。
CloudFront安全性:
CloudFront与AWS Shield、AWS Web 应用程序防火墙 (WAF) 和 Amazon Route 53 无缝协作,创建了灵活的分层安全边界来抵御多种类型的攻击,包括网络和应用层 DDoS 攻击。
下图说明了请求和响应如何流经 CloudFront 边缘站点和区域边缘缓存。
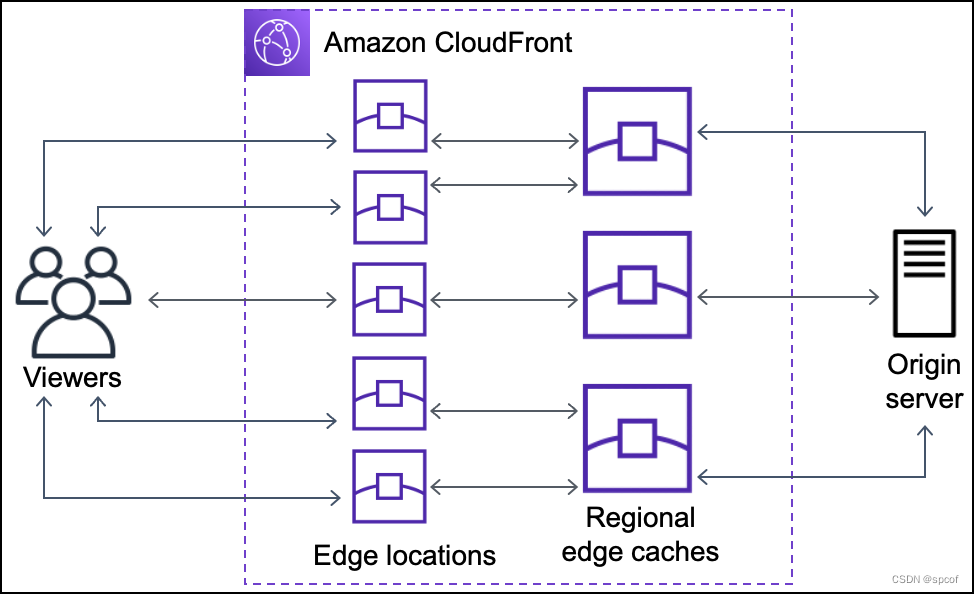
运作原理说明如下:
1.所有cache 都放在edge 端;但Regional Edge Caches 的出现,变成了Edge Location 与origin server 之间的cache
2. client送出HTTP reuqest 后,当origin server 回应,会同时存在于Regional Edge Caches & Edge Location 中
3. Regional Edge Caches 的储存容量更大,可以cache 更多且更久的object (等于是第二层cache)
4. 透过Regional Edge Caches,可以提升Edge Location 运作的效率,回源时可以只回到Regional Edge Caches 而非origin server
经过上面的介绍大家大概也了解了CloudFront,其实就是我们平时所说的DNS,那么如何使用CloudFront来缓存我们WEB页面的内容呢?接下来我们就开始带大家进行构建一下。
1. 创建一个我们自己的CloudFront
当你点击创建的时候我们会创建第一个分配(distribution)
CloudFront distribution 的作用是什么呢?
distribution的作用是用来告诉 CloudFront 您希望从哪里交付内容,以及有关如何跟踪和管理内容交付的详细信息。

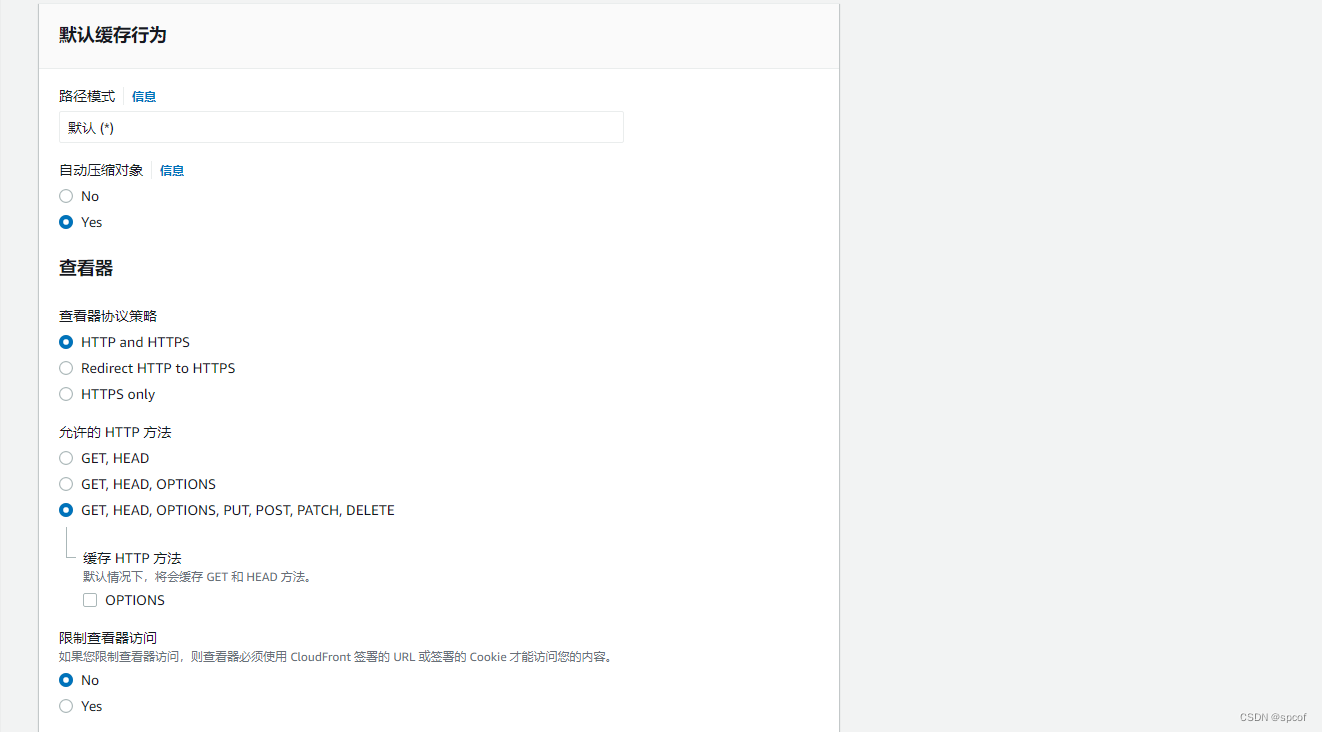
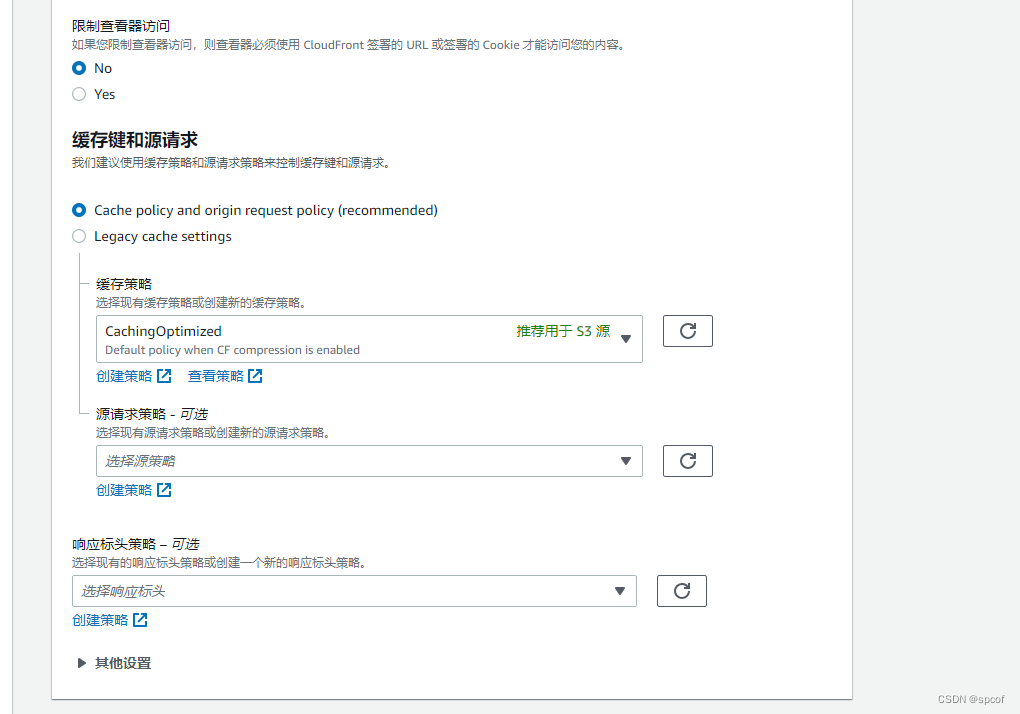
这里我要说一下我们要根据具体需求来变更缓存策略,因为我们配置的是缓存S3桶的image所以我这里选的是缓存优先。
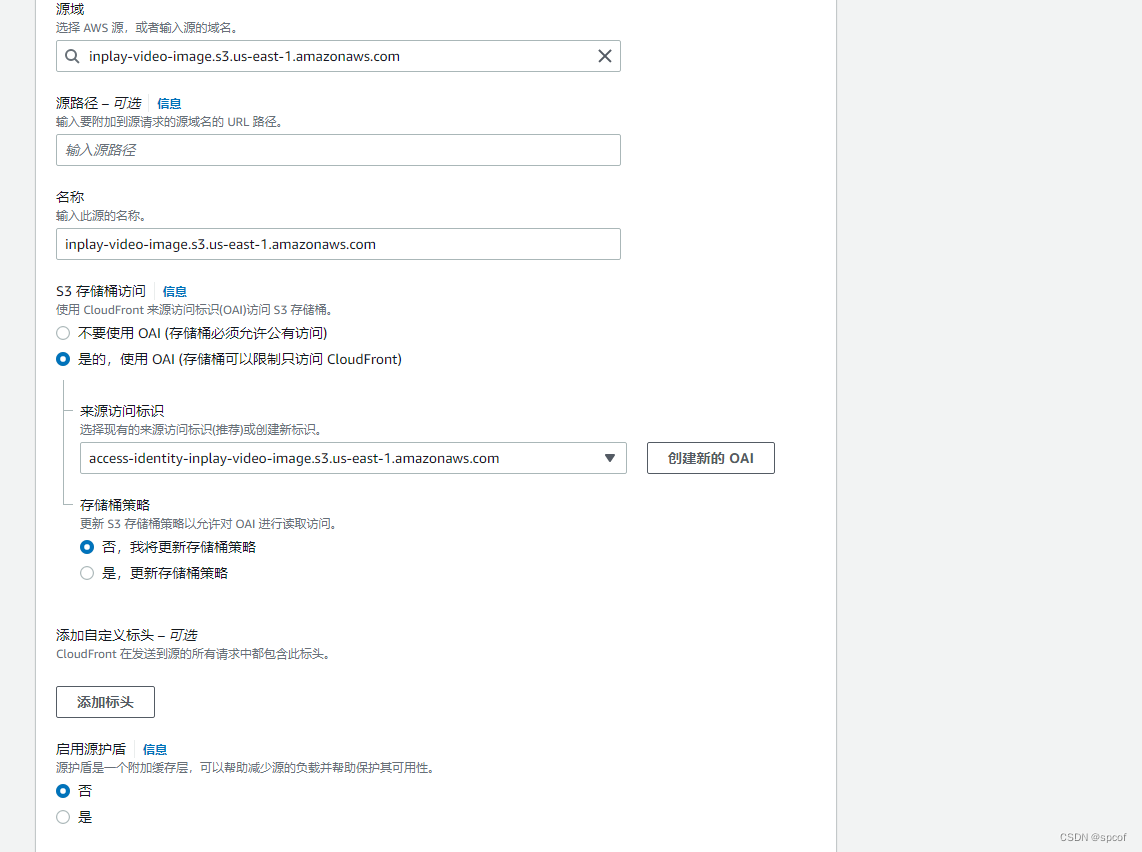
我们来说下origins
origins是文件存储内容的位置,CloudFront 从该位置获取内容以提供给查看者。
源都可以是些什么呢?
可以是S3bucket, 可以是API Gateway(自定义URL)、ELB、MediaPackages、MediaStore,
**我们来说下behaviors **
behaviors 这里的行为讲的是响应行为。
那么默认的响应行为有那些行为呢?
1. 将尚未cache的内容,就会把request发送给S3
2. 允许clinet 通过http/https 进行存取资料
3. 边缘站点会负责响应client
4. 将未缓存的数据cache起来,保存时间为24小时
5. 仅会将基本的 header 转发回 origins server,而且 cache 时不会以这些 header value 为基础进行 cache,当然还可以自定义header头
6. 所有人都可以透过 CloudFront 存取放在 S3 的内容
7. 不会自动对传输内容进行压缩
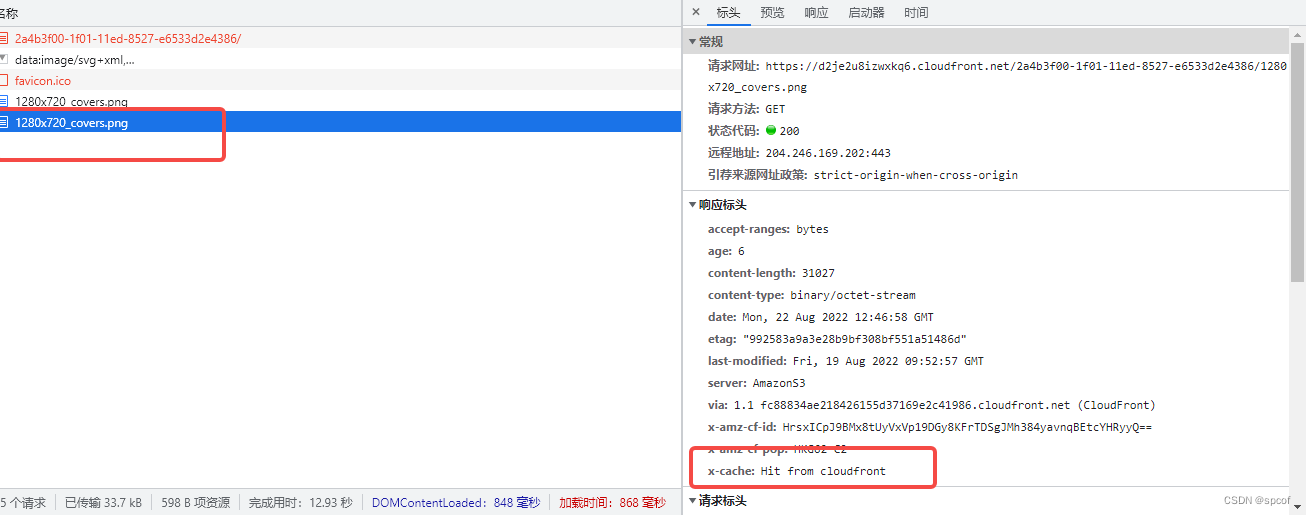
好!我们刚才通过cloudfront 创建了针对s3桶缓存源和响应行为,那我们来看看效果如何!

这是两个相同的请求,那么既然是缓存 那么第一次请求肯定是miss状态,因为缓存里面并没有我们想要的东西。
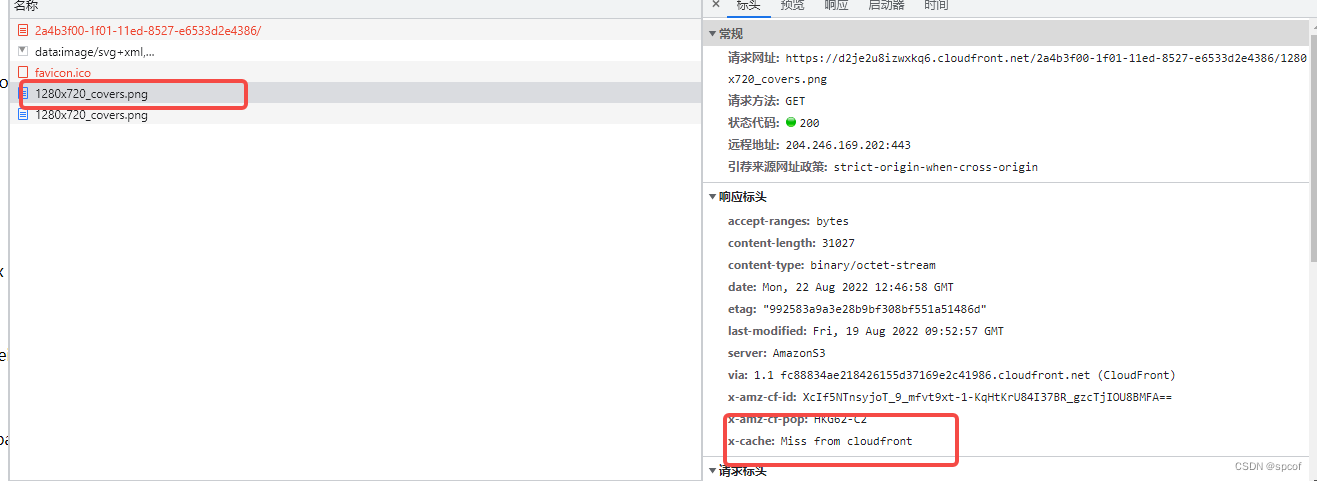
那么接下来我们看第二个请求,这时候你会发现我们命中了缓存,因为第一次请求的时候cloudfront 帮我们记录了相同请求的响应数据,当你发生第二次请求的时候cloudfront会给你返回缓存数据。