前言
首先要确保自己引入的spring-boot-starter-data-elasticsearch版本与elasticsearch一直,通常情况下会遇到使用了如,spring-boot-dependencies,parent等版本依赖管理导致es版本不对应的情况。此时记得手动指定如下jar版本例如我使用的是7.12.0:
<!-- 重写覆盖 spring-boot-dependencies 中的依赖版本 -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>4.2.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
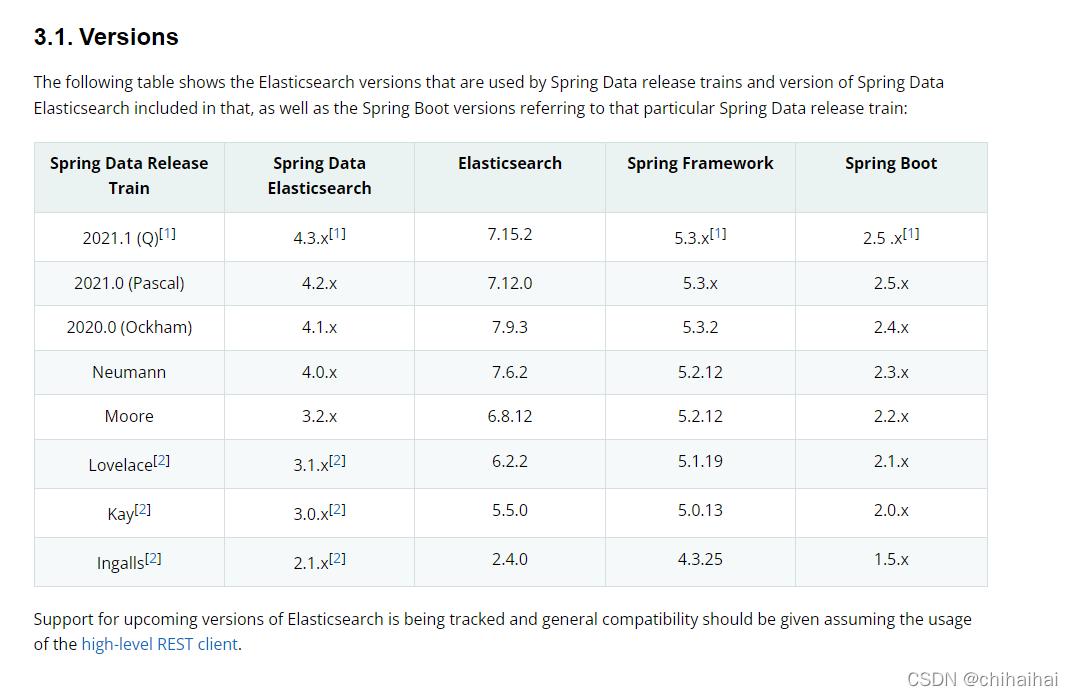
版本对应关系:https://docs.spring.io/spring-data/elasticsearch/docs/current/reference/html/#preface.versions
一、配置
这里简单使用配置文件方式演示
elasticsearch:
rest:
username: elastic
password: xxxxxx
uris: http://xxxxxxxxxx:9200
connection-timeout: 1000
read-timeout: 1000
二、创建索引映射
这里我们尽量使用spring-data提供的自动创建方式,避免手动创建致使字段无法对应导致出错。尤其是date类型字段最容易产生问题,依照下方实例spring在启动时会自动判断是否已经创建如果没有会自动帮我们创建。同时使用@setting与@mapping注解通过导入json配置文件的方式丰富mapping创建。
@Persistent
@Inherited
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
public @interface Document {
String indexName(); // 索引库的名称,个人建议以项目的名称命名
@Deprecated
String type() default ""; // 类型,7.x之后以废弃
short shards() default 1;//默认分区数
short replicas() default 1; // 每个分区默认的备份数
String refreshInterval() default "1s"; // 刷新间隔
String indexStoreType() default "fs"; // 索引文件存储类型
boolean createIndex() default true; // 是否创建索引
VersionType versionType() default VersionType.EXTERNAL; // 版本
}
/**
* @author 池海
* @version 1.0.0
* @description: TODO
* @date 2021/12/16
* * 注解说明
* * @Document:在类级别应用,以指示该类是映射到数据库的候选对象。最重要的属性是:
* * indexName:用于存储此实体的索引的名称。它可以包含SpEL模板表达式,例如 "log-#{T(java.time.LocalDate).now().toString()}"
* * type:映射类型。如果未设置,则使用小写的类的简单名称。(从版本4.0开始不推荐使用)
* * shards:索引的分片数。
* * replicas:索引的副本数。
* * refreshIntervall:索引的刷新间隔。用于索引创建。默认值为“ 1s”。
* * indexStoreType:索引的索引存储类型。用于索引创建。默认值为“ fs”。
* * createIndex:标记是否在存储库引导中创建索引。默认值为true。请参见使用相应的映射自动创建索引
* * versionType:版本管理的配置。默认值为EXTERNAL。
* * @Id:在字段级别应用,以标记用于标识目的的字段。
* * @Transient:默认情况下,存储或检索文档时,所有字段都映射到文档,此注释不包括该字段。
* * @PersistenceConstructor:标记从数据库实例化对象时要使用的给定构造函数,甚至是受保护的程序包。构造函数参数按名称映射到检索到的Document中的键值。
* * @Field:在字段级别应用并定义字段的属性,大多数属性映射到各自的Elasticsearch映射定义(以下列表不完整,请查看注释Javadoc以获得完整参考):
* * name:字段名称,它将在Elasticsearch文档中表示,如果未设置,则使用Java字段名称。
* * type:字段类型,可以是Text, Keyword, Long, Integer, Short, Byte, Double, Float, Half_Float,
* Scaled_Float, Date, Date_Nanos, Boolean, Binary, Integer_Range, Float_Range, Long_Range, Double_Range,
* Date_Range, Ip_Range, Object, Nested, Ip, TokenCount, Percolator, Flattened, Search_As_You_Type。请参阅Elasticsearch映射类型
* * format和日期类型的pattern定义。必须为日期类型定义format
* * store:标记是否将原始字段值存储在Elasticsearch中,默认值为false。
* * analyzer,searchAnalyzer,normalizer用于指定自定义分析和正规化。
* * @GeoPoint:将字段标记为geo_point数据类型。如果字段是GeoPoint类的实例,则可以省略。
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@Document(indexName = "longzhu")
@Builder
@Setting(settingPath = "/json/settings/settings.json")
public class Product {
@Id
long id;
/** IP所属地域 如,日本、大陆、欧美 可组合 */
@Field(type = FieldType.Keyword, copyTo = "all")
private String territory;
/** 所属ip 如,龙珠、海贼、火影 */
@Field(type = FieldType.Keyword, copyTo = "all")
private String ip;
/** 分类 如,景品 GK 版权 手办 */
@Field(type = FieldType.Keyword, copyTo = "all")
private String type;
/** 产品正式名称 */
@CompletionField(analyzer = "completion_analyzer",searchAnalyzer = "ik_smart")
private String name;
/** 国语简称,即玩家起的简称 */
@CompletionField(analyzer = "completion_analyzer",searchAnalyzer = "ik_smart")
private String nickname;
/** 简介 */
@Field(type = FieldType.Text, analyzer = "text_analyzer")
private String description;
/** 生产商 */
@Field(type = FieldType.Text,analyzer = "text_analyzer", copyTo = "all")
private String production;
/** 生产时间 */
@Field(type = FieldType.Date,format = DateFormat.year_month_day)
@JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "uuuu-MM-dd", timezone = "GMT+8")
private LocalDate productionTime;
/** 出厂价格 默认单位人民币 -1.00 代表抽赏 -2.00 代表赠送 */
@Field(type = FieldType.Double, copyTo = "all")
private Double price;
/** 发售形式 */
@Field(type = FieldType.Text)
private String releaseForm;
/** 发售地区 */
@Field(type = FieldType.Text)
private String salesArea;
/** 发售数量 -1.00 代表未知 */
@Field(type = FieldType.Text)
private String indultNumber;
/** 最近价格 -1.00 代表未知 */
@Field(type = FieldType.Double, index = false)
private Double currentPrice;
/** 商品比例 直接存储数字8代表1/8 6代表 1/6 */
@Field(type = FieldType.Text, copyTo = "all")
private String ratio;
/** 商品高度 */
@Field(type = FieldType.Double)
private Double height;
/** 商品材质 */
@Field(type = FieldType.Text, copyTo = "all")
private String material;
/** 商品重量 */
@Field(type = FieldType.Double)
private Double weight;
/** 总评分 */
@Field(type = FieldType.Double)
private Double grade;
/** 档案创始人,即首个提交完善资料的用户 */
@Field(type = FieldType.Long, index = false)
private long originatorId;
/** 元气贡献者, 即后续进行信息补充、纠错、数据更新的用户 */
@Field(type = FieldType.Keyword)
private long[] contributors ;
}
setting.json文件参考:
{
"analysis": {
"analyzer": {
"text_analyzer":{
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer":{
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py":{
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"lowercase": false,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
}
启动后我们在kibana查询一下确保创建成功,GET /longzhu

三、使用spring-data为我们提供的便捷代理接口操作Es
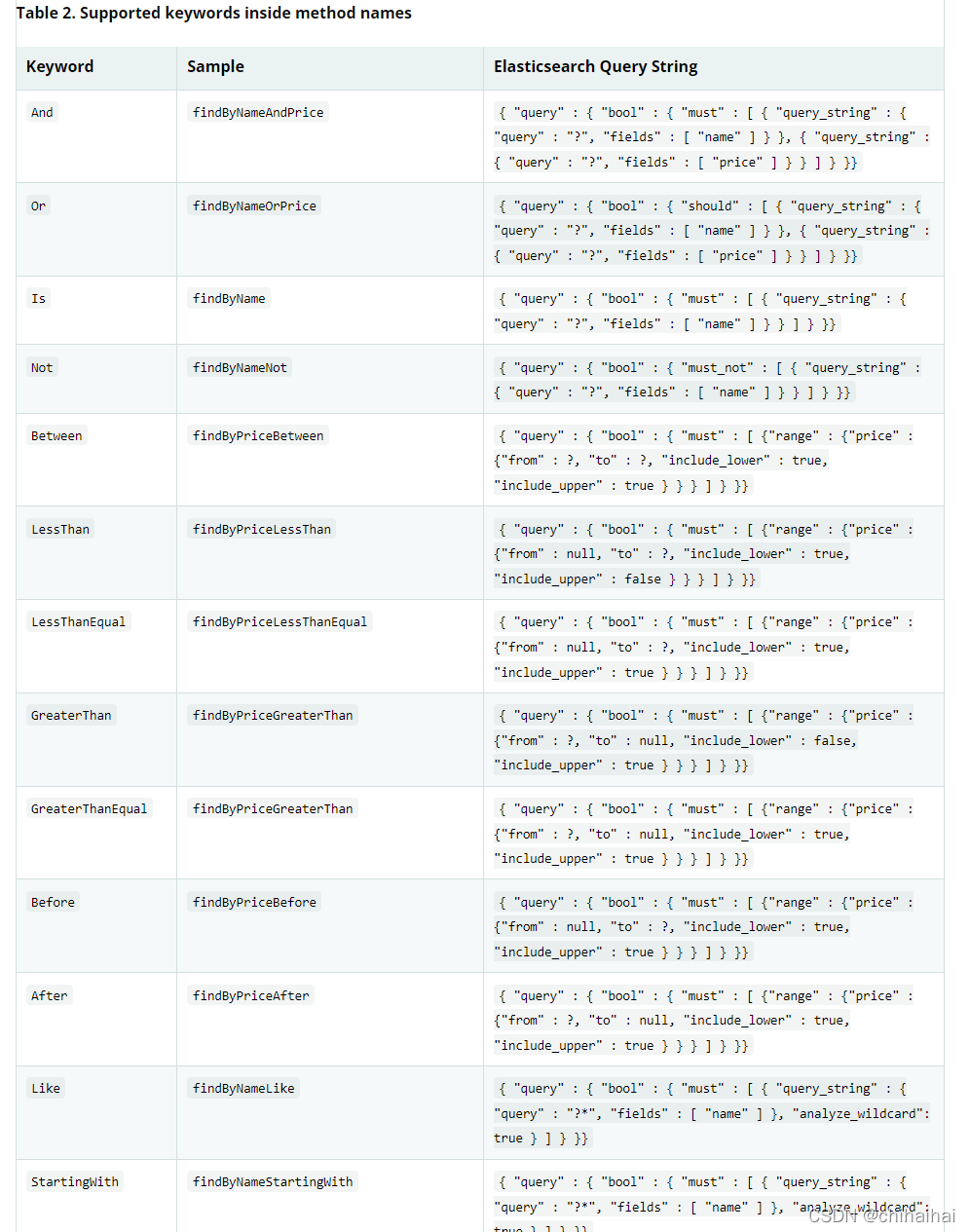
基础操作使用很简单,我们只需要创建一个接口继承ElasticsearchRepository就可以帮我自动代理生成一些基础操作方法,同时也支持如spring-data-jpa一样通过方法名称自动帮我们生成对应查询操作,如我下方自定义了一个根据名称查询的接口。
@Repository
public interface ProductDao extends ElasticsearchRepository<Product, Long> {
List<Product> findByName(String name);
}
详情可参考官方提问的文档https://docs.spring.io/spring-data/elasticsearch/docs/current/reference/html/#elasticsearch.repositories
四、@Query注解查询
这种方式用到的场景相对较少,我们简单看一下官方给出的实例
interface BookRepository extends ElasticsearchRepository<Book, String> {
@Query("{"match": {"name": {"query": "?0"}}}")
Page<Book> findByName(String name,Pageable pageable);
}
The String that is set as the annotation argument must be a valid Elasticsearch JSON query. It will be sent to Easticsearch as value of the query element; if for example the function is called with the parameter John, it would produce the following query body:
{
"query": {
"match": {
"name": {
"query": "John"
}
}
}
}
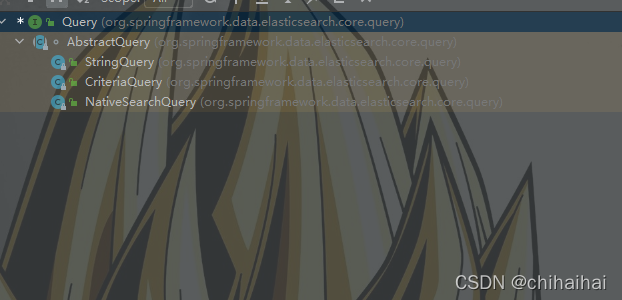
五、restTemplate高级查询
1.常规
在进行restTemplate.search(Query var1, Class var2);调用时我们发现都需要传入一个query参数。从下图看到其下有三个实现类,我们最常用到的就是NatviveSearchQuery原生查询的方法。
下面是一个简单的分页+排序的案例:
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
NativeSearchQuery query = queryBuilder
.withQuery(QueryBuilders.multiMatchQuery("景品","type"))
// 分页
.withPageable(PageRequest.of(0,10))
// 根据查询结果按时间升序
.withSort(SortBuilders.fieldSort("productionTime").order(SortOrder.ASC)).build();
SearchHits<Product> searchHits = restTemplate.search(query,Product.class);
searchHits.stream().iterator().forEachRemaining(System.out::println);

上面的写法也可以简写为:
withPageable(PageRequest.of(0,10, Sort.Direction.ASC, "productionTime"))
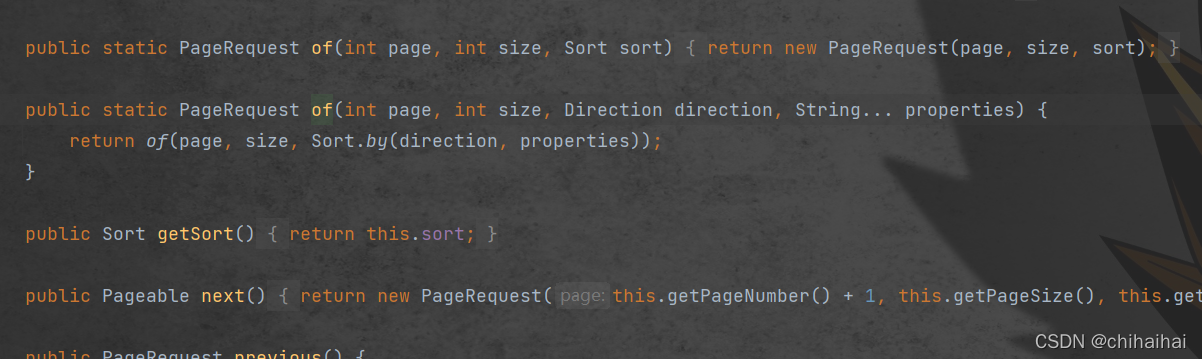
我们看到of()方法结尾是一个可变参数,所以允许我们传入多个排序字段。如果在日期相同的情况下我们想根据手办高度排序即只需要再追加一个高度字段
withPageable(PageRequest.of(0,10, Sort.Direction.ASC, "productionTime","height"))

更多有趣的API还需要我们自己去慢慢探索
2.高亮
// 默认样式
.withHighlightFields(new HighlightBuilder.Field("type"))
// 自定义
.withHighlightBuilder(new HighlightBuilder().field("type").preTags("<p style='color:yellow'> ").postTags("<p>"))
先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小。自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。添加下方名片,即可获取全套学习资料哦