为了方便维护,一般公司的数据在数据库内都是分表存储的,比如用一个表存储所有用户的基本信息,一个表存储用户的消费情况。所以,在日常的数据处理中,经常需要将两张表拼接起来使用,这样的操作对应到SQL中是join,在Pandas中则是用merge来实现。这篇文章就讲一下merge的主要原理。
上面的引入部分说到merge是用来拼接两张表的,那么拼接时自然就需要将用户信息一一对应地进行拼接,所以进行拼接的两张表需要有一个共同的识别用户的键(key)。总结来说,整个merge的过程就是将信息一一对应匹配的过程,下面介绍merge的四种类型,分别为'inner'、'left'、'right'和'outer'。
一、inner
merge的'inner'的类型称为内连接,它在拼接的过程中会取两张表的键(key)的交集进行拼接。什么意思呢?下面以图解的方式来一步一步拆解。
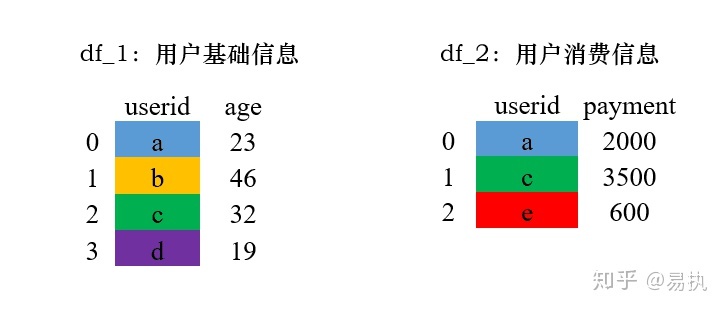
首先我们有以下的数据,左侧和右侧的数据分别代表了用户的基础信息和消费信息,连接两张表的键是userid。


现在用'inner'的方式进行merge
In [6]: df_1.merge(df_2,how='inner',on='userid')
Out[6]:
userid age payment
0 a 23 2000
1 c 32 3500
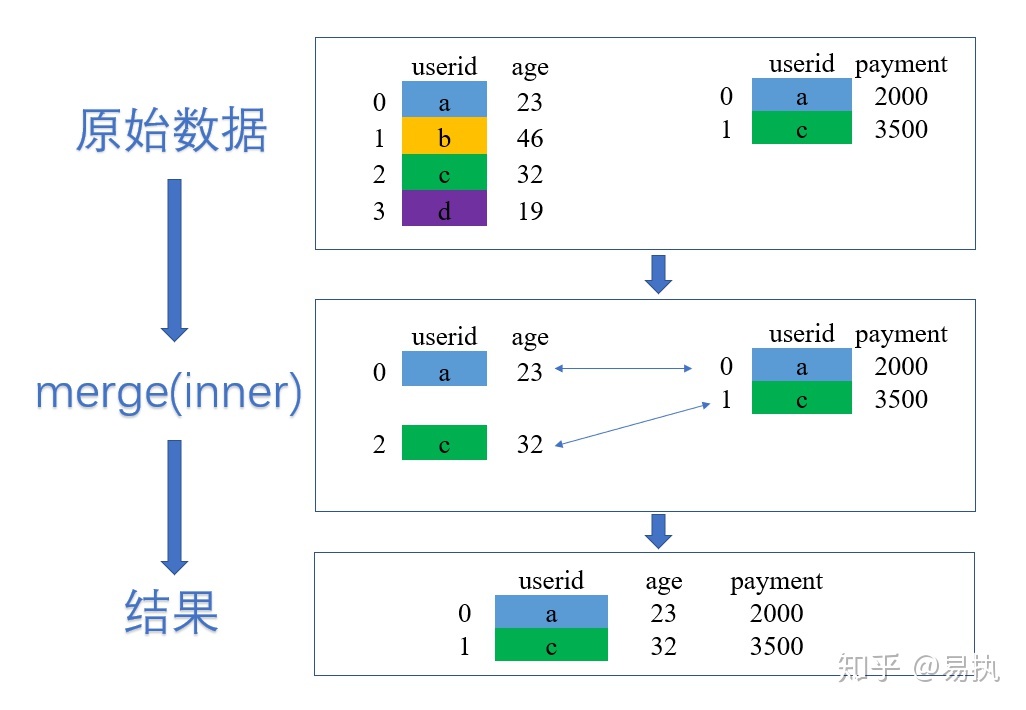
过程图解:
①取两张表的键的交集,这里df_1和df_2的userid的交集是{a,c}
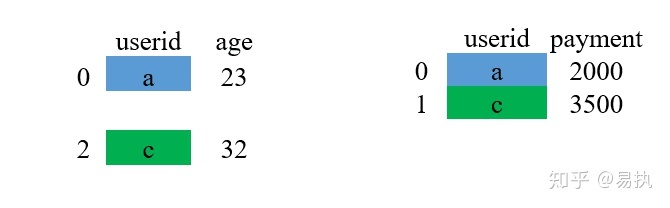
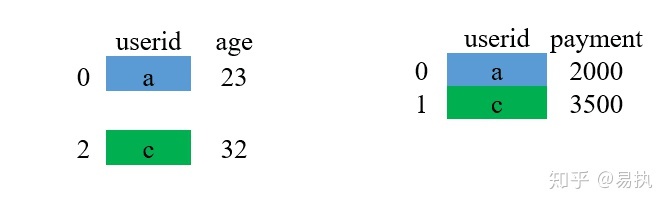
②对应匹配
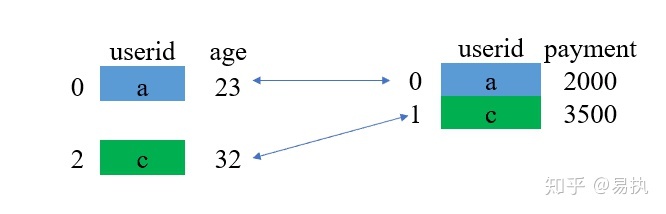

③结果
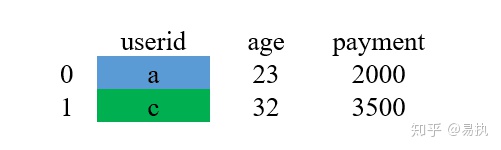
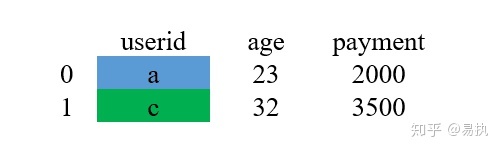
过程汇总:

相信整个过程并不难理解,上面演示的是同一个键下,两个表对应只有一条数据的情况(一个用户对应一条消费记录),那么,如果一个用户对应了多条消费记录的话,那又是怎么拼接的呢?
假设现在的数据变成了下面这个样子,在df_2中,有两条和a对应的数据:


同样用inner的方式进行merge:
In [12]: df_1.merge(df_2,how='inner',on='userid')
Out[12]:
userid age payment
0 a 23 2000
1 a 23 500
2 b 46 1000
3 c 32 3500
整个过程除了对应匹配阶段,其他和上面基本都是一致的。
过程图解:
①取两张表的键的交集,这里df_1和df_2的userid的交集是{a,b,c}
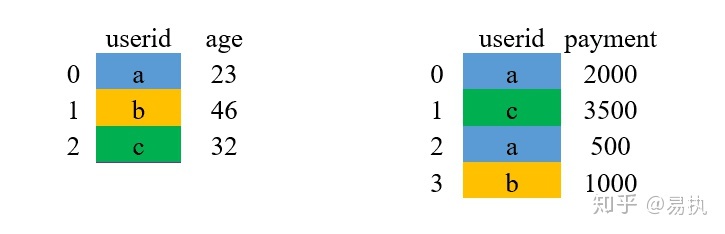
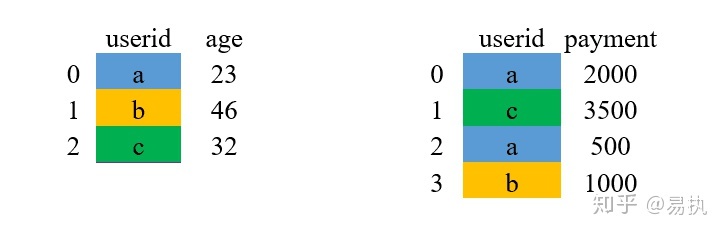
②对应匹配时,由于这里的a有两条对应的消费记录,故在拼接时,会将用户基础信息表中a对应的数据复制多一行来和右边进行匹配。
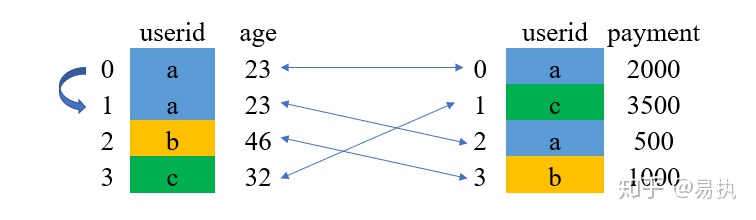

③结果

论文复现机器学习模型案例大本营(收藏)
二、left 和right
论文复现机器学习模型案例大本营(收藏)
'left'和'right'的merge方式其实是类似的,分别被称为左连接和右连接。这两种方法是可以互相转换的,所以在这里放在一起介绍。
'left'
merge时,以左边表格的键为基准进行配对,如果左边表格中的键在右边不存在,则用缺失值NaN填充。
'right'
merge时,以右边表格的键为基准进行配对,如果右边表格中的键在左边不存在,则用缺失值NaN填充。
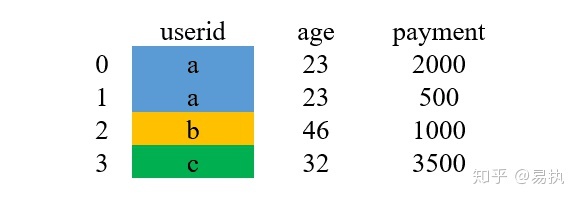
什么意思呢?用一个例子来具体解释一下,这是演示的数据

现在用'left'的方式进行merge
In [21]: df_1.merge(df_2,how='left',on='userid')
Out[21]:
userid age payment
0 a 23 2000.0
1 b 46 NaN
2 c 32 3500.0
3 d 19 NaN
过程图解:
①以左边表格的所有键为基准进行配对。图中,因为右表中的e不在左表中,故不会进行配对。


②若右表中的payment列合并到左表中,对于没有匹配值的用缺失值NaN填充


过程汇总:


对于'right'类型的merge和'left'其实是差不多的,只要把两个表格的位置调换一下,两种方式返回的结果就是一样的(),如下:
In [22]: df_2.merge(df_1,how='right',on='userid')
Out[22]:
userid payment age
0 a 2000.0 23
1 c 3500.0 32
2 b NaN 46
3 d NaN 19
至于'left'和'right'中(乃至于下面将介绍的'outer')连接的键是一对多的情况,原理和上方的'inner'是类似的,这里便不再赘述。
三、outer
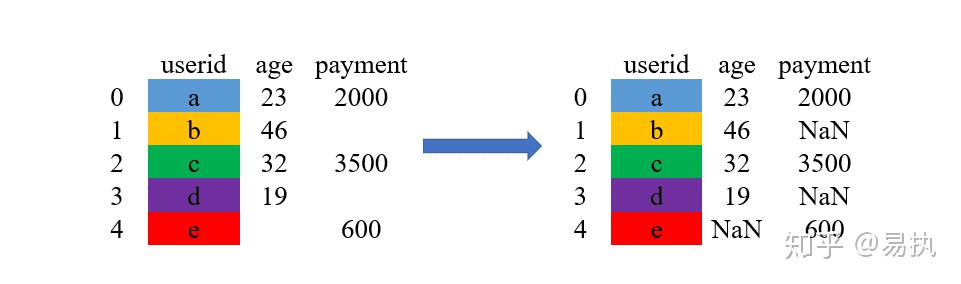
'outer'是外连接,在拼接的过程中它会取两张表的键(key)的并集进行拼接。看文字不够直观,还是上例子吧!
还是使用上方用过的演示数据
这次使用'outer'进行merge
In [24]: df_1.merge(df_2,how='outer',on='userid')
Out[24]:
userid age payment
0 a 23.0 2000.0
1 b 46.0 NaN
2 c 32.0 3500.0
3 d 19.0 NaN
4 e NaN 600.0
图解如下:
①取两张表键的并集,这里是{a,b,c,d,e}
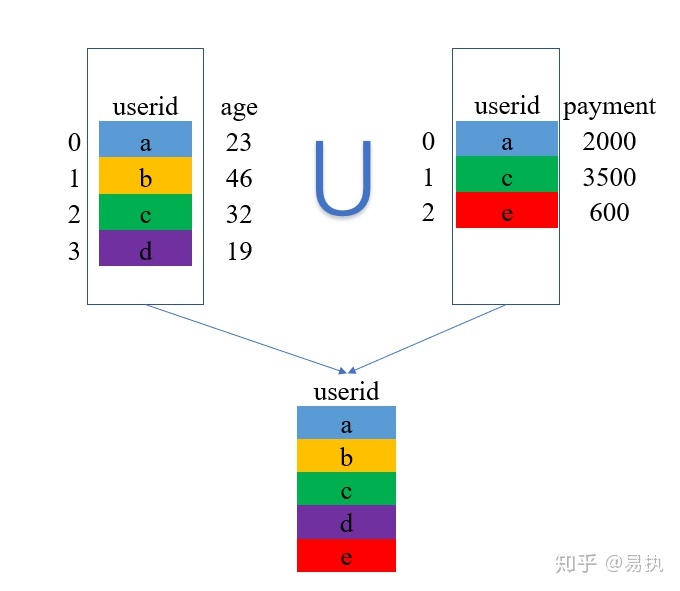
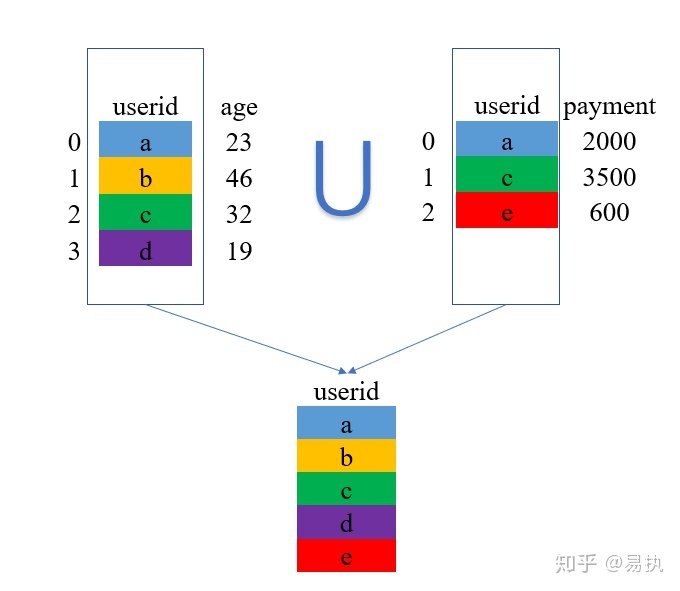
②将两张表的数据列拼起来,对于没有匹配到的地方,使用缺失值NaN进行填充
能读到这里的小伙伴想必也基本理解了merge的整个过程,总结来说,merge的不同类型区别就在于拼接时,选用的是两表的键的集合不同。关于Pandas的merge就介绍到这里!
转https://zhuanlan.zhihu.com/p/102274476