文章目录
摘要
受许可的区块链由已识别但单独不可信的节点支持,这些节点共同维护一个复制的分类账,其内容是可信的。Hyperledger Fabric允许区块链系统的目标是高吞吐量的事务处理。Fabric使用一组节点来执行使用共识的事务排序任务。另外的对等点批准和验证事务,并维护分类帐的副本。将新事务块从排序节点快速传播到所有对等节点的能力对于性能和一致性都至关重要。广播是通过一个八卦协议来处理的,它使用对等体之间的随机块交换。
我们展示了当前Fabric中闲话的实现会导致块传播延迟的严重尾部分布,影响性能、一致性和公平性。我们为Fabric中的八卦提供了一个新颖的设计,该设计同时优化了传播时间、尾延迟和带宽消耗。通过使用一个100节点的集群,我们展示了我们增强的八卦允许块传播到所有节点的速度比原始实现快10倍以上,同时减少了超过40%的总体网络带宽消耗。通过高吞吐量和并发应用程序,不同块大小的无效事务减少17%到36%。
1 介绍
随着比特币加密货币[39]的首次发布,区块链在过去十年获得了强劲的势头。区块链是一个不可变的、只能追加的、全局复制的数据结构。区块链的内容在其客户端提交的事务评估之后发展。满足有效性和决定论标准的事务最终以某种独特的顺序执行。事务被分组到块中,这些块被链接成一个链:每个新块的头包含前一个块的加密散列,重复直到第一个(起源)块,允许检查链和它的任何块的一致性。一组节点支持区块链基础设施。区块链的关键好处是,客户端不需要信任单个节点或任何其他客户端,而是可以将其信任作为一个整体的基础设施:区块链是互不信任的参与者之间的相互协议来源。区块链支持许多新的应用,从加密货币[19]、[39]开始,然后是供应链管理[21]、医疗保健管理[34]和电子投票[33]。
区块链基础设施是一个多层系统,它结合了几个关键的启用特性[15]。交易可以用特定领域的语言(例如比特币[39]中的金融交易)或更通用的语言(例如以太坊[48]中的图灵完备性和确定性固体性,或通用语言,如Go或Hyperledger Fabric[2]中的JavaScript)编写。运行时允许使用特定的虚拟机[25]或基于容器的隔离,根据分类账的当前状态(即所有验证过的事务的序列)执行事务。密码原语允许检查块和区块链本身的有效性。
除了语言、运行时和密码学构建块之外,区块链还依赖于两个关键的分布式协议:共识和广播。
共识管理向链中添加新块。
由于单个基础设施节点通常是不可信任的,并且可能试图破坏链的内容或强加格式不正确的块,因此拜占庭容错共识通常是必要的。在某些场景中,崩溃容错(CFT)共识可能就足够了。在开放或无许可的区块链中,例如比特币[39]、以太坊[48]或零现金[42],任何称为矿工的节点都可以参与BFT共识,并试图向链中添加新的区块。没有身份管理,因此BFT共识协议必须能够抵御sybil攻击[16]。
另一方面,受许可的区块链假设存在一个受信任的成员管理服务,并且参与基础设施的节点都由该机构认证。这允许使用经典的拜占庭容错共识算法,该算法假设可识别的参与者,称为orderers,如PBFT[11]、Zyzzyva[32]或BFT-Smart[7],或CFT协议,如主-备份复制[22]、[26]。被允许的区块链的例子是Hyperledger Fabric [2], Tendermint[10]和Corda[24]。
广播原语用于区块链的多个级别,是性能和可靠性的基础。它将交易从客户端传播到开放区块链中的矿工,并将新区块从矿工或订购者传播到所有其他节点。由于区块链可以被数百个节点支持,直接从其源节点发送区块到所有其他节点不是一个有效的选项。此外,区块链预计将在具有挑战性的条件下工作,如流失、丢包和缺乏同步性。确定性算法表现不佳,在这种条件下不能很好地扩展,因此区块链中的鲁棒广播依赖于使用随机八卦协议[8],[13]。流言通过节点之间的概率交换传播信息,类似于流行病的传播。
动机和贡献。尽管区块链中拜占庭容错共识的性能和可伸缩性受到了极大关注,但广播的性能和可伸缩性及其对区块链的整体性能和可靠性的影响却很少受到关注。这项工作的目标是缩小这一差距,重点是被许可的区块链。我们分析了Hyperledger Fabric[2]中基于八卦的广播的性能和对可靠性和一致性的影响,并提出、实现和测试协议修改以减少这种影响。我们使用100节点集群进行的实验验证表明,我们增强的八卦模块允许向所有节点传播块的速度比原始实现快10倍以上,同时减少了超过40%的总体网络带宽消耗。这将导致在验证时无效事务减少17%到36%,具体取决于块生成周期。剩余的冲突是由于共识和验证的延迟造成的,因此我们增强的八卦模块基本上消除了大部分因传播效率低下或不公平而产生的冲突。我们的代码以开源的形式发布,可在https://github.com/ berendeanicolae/fabric/tree/fair-and-efficient-gossip获得。
2 超级账本结构的解剖
Hyperledger是一个开源区块链项目的集合,由Linux基金会于2015年12月发起,并得到了几个关键的工业参与者的支持。Fabric[2]是Hyperledger的一个被允许的区块链系统部分。在本节中,我们首先介绍Fabric的体系结构和组件。然后,我们将解释Fabric如何处理客户端事务,并讨论其一致性模型如何导致冲突和丢弃事务。请注意,基于八卦的Fabric广播,以及它对一致性的影响,是这项工作的核心,在第三节中详细介绍。
A. Fabric架构
Fabric的架构如图1所示。Fabric支持名为链码的智能合约,由客户端提交并根据分类账的内容执行。链代码可以用通用语言编写,如node.js或Go。与其他区块链一样,链码必须是确定的:对于给定的输入集,写入的值集在执行过程中应该是唯一的。此属性允许在多个互不信任的节点上执行和验证链代码。Fabric执行模型没有链接到加密货币。
Fabric假定存在一个可信的成员服务提供者(MSP),该提供者惟一地验证由订购者和对等体组成的基础设施节点的身份。Fabric将新块的引入(由orderers处理)与链代码的验证和执行(由peer处理)分隔开来。该分区允许订购者使用可插入的共识协议,例如基于Apache Kafka[22]的崩溃容错服务,或使用bbt - smart[7]、[45]的拜占庭容错服务。
Fabric采用了一种执行-订单-验证(EOV)模型,由对等体进行事务处理和执行,这些对等体都维护账本的完整副本。一个称为背书者的对等体子集首先执行链码的初始执行(称为模拟)。客户收集背书并将它们合并到一个交易建议中。建议被提交给订阅者,订阅者将它们附加到一个块中,最终作为共识操作的结果添加到区块链中。然后,每个新块被广播到所有对等点,在那里进行本地验证。然后将有效事务的输出集成到分类帐的本地副本中。注意,这个EOV模型与所有的开放区块链是相反的,在开放区块链中,所有的事务都在所有的对等点上执行,形成临时区块,所有的对等点都参与到共识中,这导致了一个本质上顺序的执行模型。
B. Fabric中事务的执行
我们详细描述了Fabric中事务的生命周期,从客户端提交链码到在区块链上执行结果事务。Fabric支持多通道(独立的分类账)和跨多个组织部署,如图1所示。在此工作的其余部分中,我们将考虑具有惟一区块链(通道)的部署。
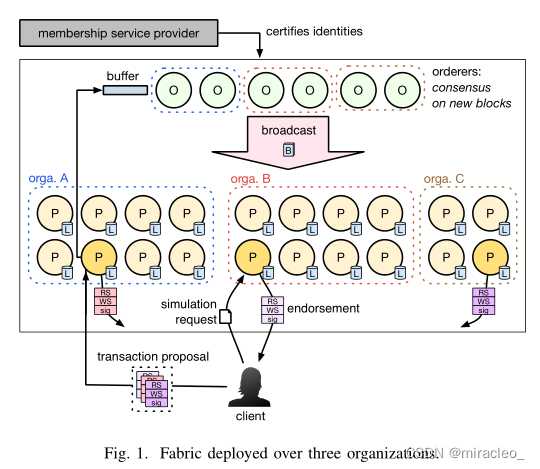

图2详细描述了事务准备和处理的时间轴。客户端将其链码提交给一组模拟交易的对等体,这些对等体充当背书者。它们的数量和来源由背书政策决定。例如,三个对等体可以接收事务并独立模拟链代码。链中的值集(所有有效事务执行的结果)在本地的键/值存储中具体化,并用作模拟链代码的输入。V值与版本号相关联。模拟事务的读集包含所有访问键的版本号。链码在Docker容器中独立运行,并为多个键生成一组新值,形成其写集。非确定性链码产生不同的读和/或写集,这可以被客户端检测到。读和写集合在背书人签署的背书中编译并返回给客户端。
客户端将收到的背书合并到一个事务建议中。该提议被发送给对等体,对等体将其转发给订购服务。事务保存在缓冲区中,最终集成到一个新的块中。订购者不对事务提议执行任何验证。当它的大小达到最大大小时,或在计时器过期后,一个新的块被提议以达成共识。Fabric v1.2中的示例值为99 MB和2秒,但必须针对目标应用程序进行调整。
共识以唯一的顺序输出链块。新块必须传播到所有对等点,以允许未来的事务对新值进行操作。订购者将一个新块发送到每个组织中的一个对等点。这个领导对等体负责向其组织中的所有对等体发起广播块。对于这种广播使用直接发送的方法是不可扩展的,因为领导者对等体的传播时间和带宽使用都随组织的规模线性增加。因此,任何拥有少数同行的组织都会求助于基于八卦的广播协议。我们将在第三节中详细介绍如何在Fabric中实现八卦。
接收到新块的对等体验证它包含的所有事务提议。如果票据的背书数量和背书来源符合背书政策,票据有效。此外,它必须根据分类帐中最新的值进行操作。这可以基于建议的读集进行检查,其中所有键的版本必须与本地键/值存储中的版本相同。所有有效事务的输出都应用到键/值存储区,并将块附加到链的本地副本(无需重新执行链代码)。无效的事务仍然保留在区块链中,但除了浪费存储空间外没有任何影响。
C. Fabric的一致性
即使Fabric定序者在提交的事务上定义了一个总订单,并且对等方最终同意使用相同的账本副本,但一致性冲突可能在此期间出现,导致事务失效,并降低客户端的服务质量,因为客户必须准备和重新提交新的事务建议。如果没有适当的保护措施,这可能会在应用程序级别造成问题,例如数字市场中的无效交易。我们区分了两种类型的冲突:提议时间冲突和验证时间冲突。
提案时间冲突可能发生在两个或多个背书人在账本的不同高度上执行交易时,因为他们还没有收到同一组区块。
即使链码是确定的,如果其中一个背书人还没有看到最近的写,其结果也可能不同。通过比较读集中的版本号,可以在客户端检测到这种冲突,但它浪费资源并导致延迟,因为客户端必须收集额外的背书。
当两个事务发出对公共值的写操作而不知道彼此的执行情况时,就会发生验证时冲突。当两个链码至少共同访问一个密钥并在分类账的相同内容上执行时,就会发生这种情况。这些相互冲突的提议可能被安排在不同的区块中,或者在同一区块的不同位置。这可能导致弱一致性系统的写入冲突。在Fabric中,由分类帐强加的总顺序允许自然的“先写者赢”冲突解决策略。第一个事务被认为是有效的,它的输出在验证时应用到本地副本,而第二个事务将无法通过验证检查。
验证时间冲突比建议时间冲突具有更高的影响。首先,提交事务的客户机在事务失效后才知道它在与另一个事务的竞争中失败了,这导致在准备和重新提交新的事务提议之前有很长时间的延迟。其次,它在分类帐中创建无用的、无效的条目,消耗所有对等节点上宝贵的存储资源。
发生这两种类型的冲突是因为背书者模拟事务时没有对其状态进行同步。这是一个由信任假设引导的有意识的设计选择。在详细介绍Fabric[2]的论文中,作者提到了一致性问题。他们提到仔细的应用程序设计(例如,避免写入相同值的链代码)可以避免冲突,但是如何在相互不信任的组织中执行如此强的约束还不清楚。另一种建议的方法是使用无冲突复制数据类型[44],允许并发写确定地合并到单个值,但显著限制了编程模型。第三种方法是为每个链代码使用一个主背书者,作为其所有执行的序列化点。这种方法可以避免相同链代码实例之间的冲突。然而,这是昂贵的,并且对需要访问和写入相同值的不同链代码没有影响。
3 八卦在织物中传播
A.八卦在Fabric中传播
在本节中,我们详细介绍了目前Fabric1中基于流行/八卦的广播是如何实现的。Fabric使用八卦有很多目的[37]:对等体使用它来建立和维护网络中其他对等体的本地视图;他们也会在第一次加入网络或崩溃后使用它。
八卦被用来传播元数据,如账本高度和活动链码。最后,八卦主要用于向组织内的所有对等者传播新块,然后这些对等者独立地验证它们的内容,并将有效交易的结果应用到他们本地的分类账副本。
在这项工作中,我们关注的是基于八卦的数据块从订购服务到对等点的传播。我们提到,在这种情况下,八卦是可选的,出于信任的原因,只允许在同一组织的同行之间进行。因此,我们假设我们在一个至少有一个足够大的组织的环境中运行,对于这个组织来说,从leader对等点直接广播到所有其他对等点的成本将非常高。
图3说明了组织中块的传播。订购服务首先将新块的副本发送给领导对等体,领导对等体向组织中的其他对等体发起八卦广播。由于所有的对等体都知道组织中所有其他对等体的身份,因此八卦协议在一个完整的图上运行。织物结合了三种传播原语:推、拉和回收。
推。Fabric使用感染和死亡的推送模型[18]。每当一个对等体第一次收到一个区块(它被感染了),它就向随机选择的其他对等体推送一次该区块,但如果它随后收到相同的区块就不再推送(它推送,然后死亡)。更为技术性的是,新的区块首先被放入一个缓冲区,当缓冲区满了或者一个短的定时器tpush到期时,再进行推送。图3显示了一个推送阶段,fout=2。Fabric的默认配置使用fout = 3和tpush = 10毫秒。一些对等体在推送阶段多次收到一个块(如P1、P2、P3和P6),而其他对等体没有收到它(如P5和P8)。

Pull:对等体使用Pull组件来获取它们在推送阶段没有收到的块。在每个时间间隔tpull时,每个对等体发起一个pull,以随机选择对等体。如果fin = 3, peer P联系peer Q, R, S,它首先从Q, R, S请求最近块的摘要,然后它们将这些摘要转发回P。然后,P从所有接收到的摘要中,向Q、R、S请求它还没有的块,这些块最后被转发给P。注意,当一个对等体从一个拉请求中收到一个新的数据块时,它不会直接将这个数据块推给其他对等体,而只会回复拉请求。Fabric pull组件的默认参数是fin = 3和tpull = 4秒。我们在图3中使用fin = 1,为了清晰起见,只显示P5和P8的拉交互。Pull对于某些对等点可能会导致高延迟,因为它很少被启动。例如,对等体P5只在第二次尝试从对等体P2处接收新块。
恢复:Fabric的恢复八卦组件允许对等体通过请求一批丢失的块来跟上分类账的内容,可以是在它们加入网络时,也可以是在由于停机、高延迟或任何其他原因造成的长时间延迟后。在每次时间间隔恢复时,每个对等体都观察元数据信息,其中包含通道中其他对等体的分类帐高度。与推拉组件相反,这并不局限于同一组织中的对等体。如果一个对等体落后于其他对等体,它会向一个分类账最高的对等体请求连续丢失的块。Fabric恢复组件的默认参数是recovery = 10秒。实际上,在一个稳定的网络中,恢复对传播延迟没有影响。
B.八卦对带宽和冲突的影响
广播的性能直接导致了Fabric中不一致的发生:次序者和对等体之间的长传播时间会导致验证时间冲突,而提议时间冲突则是次序者和对等体之间传播时间不均匀的直接结果。在使用八卦来广播有序块的大型组织中,由拉和恢复组件引起的默认延迟(4秒和10秒)比建议一致块之前的计时器(2秒)要大。
换句话说,很大一部分冲突在本质上是由广播尾部延迟引起的,即延迟分布的尾部,对应于对等体在订购服务添加新块后接收新块所需的时间。因此,我们希望有一种广播协议,它能够尽可能快地向所有对等点交付新块,以便Fabric进行扩展,而不会大量增加冲突的发生。
对于云[6]中最终一致的键值存储也进行了类似的观察。
八卦层对Fabric节点的带宽消耗也有很大影响。对于大块和高吞吐量,数据块的带宽占主导地位,这可能会产生争用和负载平衡问题,导致额外的延迟和更高的操作成本。因此,这项工作的目标是分析和优化Fabric的广播层,关注效率、公平性和成本。
4 加强疫情传播
关于流行病传播的理论和实践文献是大量的,八卦协议被提出用于各种各样的问题,如复制数据库维护[13]、传播[5]、成员[29]、流[20]、总排序[38]和许多分布式信号处理任务[14]。然而,有精确理论保证的同时针对实际应用的工作很少。一方面,理论工作通常假设通信发生在同步轮中,并且在对等点之间建立通信的成本是免费的,并为忽略昂贵的乘法常数[30]的大型部署提供了渐近结果。另一方面,实际工作一般是经验的,不估计不完美传播的概率。
Fabric八卦模块的主要优点是它的模块化,非常实用:推、拉和恢复组件完全解耦。这使得推得快,拉得少。
Fabric的感染-死亡推组件有两个主要缺点:通信开销高,向所有对等体传播块的概率低。例如,在我们的n = 100个对等点和fout = 3的网络实验中,我们可以很容易地计算出感染-死亡推将每个块平均传播给94个对等点,标准差为2.6,同时传输每个块整整282次。在推阶段结束时未被告知的对等点必须求助于不频繁的拉或恢复组件来接收块,从而导致高延迟。在推送阶段以高概率3到达所有对等点需要一个大的fout,这将导致负载平衡和争用问题,并需要传输n·fout次块。
我们现在描述我们对Fabric八卦模块所做的增强,如表一所示。
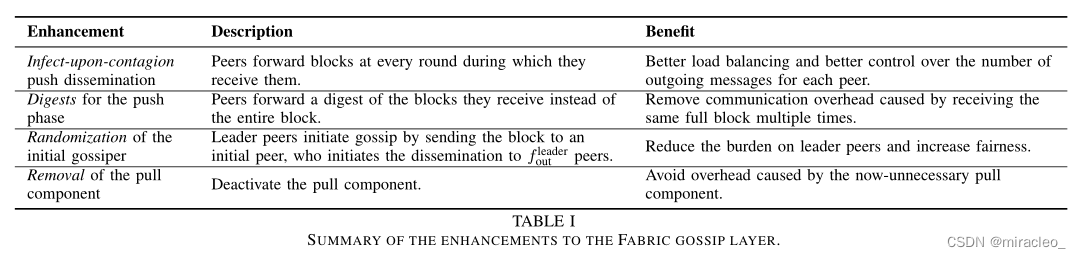
增强描述受益感染对感染推送传播对等体在每一轮接收block时都向前推进block。
更好的负载平衡和更好地控制每个对等体的传出消息数量。
对等体向前转发它们接收到的块的摘要,而不是整个块。
消除多次接收相同的完整块所造成的通信开销。
领导者同伴通过将消息块发送给一个初始同伴发起八卦,这个初始同伴发起向f个领导者同伴的传播。减轻领导同龄人的负担,增加公平性。
拉组件的拆卸关闭拉组件。避免不必要的拉组件造成的开销。
表一总结了对织物八卦层的增强。
感染上传染推送传播。我们用感染上传染的推送算法[31]来取代感染和死亡的推送组件。在这个模型中,对等人在每一轮他们收到区块时都会转发。与众所周知的感染-永久模型[17]相比,感染-上-传染推送的主要优势在于其负载平衡,因为它不会给发起谣言的对等体带来不必要的负担。我们的协议需要一个停止条件:我们给每个区块附加一个计数器r,初始化为0。当一个对等体第一次收到计数器r=k的区块b(确切的一对(b,k)),它将其计数器增加到k+1,并将b转发给均匀随机选择的fout其他对等体的样本。
当本地被传播的块的计数器达到一个商定的生存时间TTL值时,传播就会停止。请注意,在这种情况下,轮次的概念,即使是异步的,也是不必要的。
不完全传播的概率pe,即一个块在推送阶段没有到达所有对等点的概率,取决于n、fout和TTL。我们可以非常精确地计算出pe。我们的分析总结在附录中。
在我们的实验中,对于n = 100个对等体的网络,我们的目标pe = 10−6。我们考虑实现这一目标的两种配置:(1)fout = bln nc = 4和TTL = 9;(2) fout = 2, T T L = 19。如果pe = 10−6不足,将TTL从9增加到12,fout = 4,则会导致pe = 10−12,这十有八九小于给定对等体的硬件崩溃概率。尽管这些看起来很高的TTL值,但由于没有预先确定的子弹,这一阶段的速度明显快于拉和恢复组件的频率。还要注意TTL随n的变化缓慢;因此,我们可以在查找表中存储(n, pe)对的少量TTL值。对等体可以使用表中出现的对等体数量的最低上限来调整TTL。
我们还删除了Fabric中嵌入数据块的tpush = 10ms计时器,不是为了提高延迟,而是为了确保无偏置的随机性。更准确地说,计时器会导致偏差,因为在10ms的间隔内收到一个计数器值不同的块b的对等体将它们放在同一个缓冲区中,并将它们发送给相同的fout对等体,减少了消息的数量,这增加了不完美传播的概率pe,高于理论保证。解决这个问题最简单的方法是为数据块设置tpush = 0,确保每个对(b, k)被转发到fout对等体的随机样本。
推送阶段的摘要:当我们增加T T L时,在传播的最后,大多数(如果不是所有)对等点已经被通知了,并不断向彼此发送相同的块。这将导致不可接受的通信开销。因此,我们为推阶段引入了摘要,就像对许多现有的推协议所做的那样。当一个对等体收到一个计数器r小于T T L的块时,它首先随机选择fout对等体样本,并向它们发送该块的摘要。尚未拥有该块的对等体将请求它,然后将该块推给它们。我们可以进一步改进这一点,在有少量碰撞的情况下,不带摘要地推直到TTLdirect,带摘要地推直到TT l。当n = 100, fout = 4时,我们可以设置TTLdirect = 2。在我们的局域网实验中,这个特性对延迟的影响很小,可以省略。
我们的推送协议每块发送的信息数量是k ln n,其中k是一个大常数。为了在不使用pull的情况下以高概率到达所有对等体,这是不可避免的。有了摘要,我们确保大区块只被传送n+o(n)次,其他消息是小的摘要。使用推拉算法,Θ(n ln n ln n)消息是最优的[30],但这假设对等体知道区块何时到达网络,并且对等体之间建立通信是免费的。 如果没有这些不现实的、不切实际的假设,就必须尊重各轮之间的大时间。因此,我们的协议比这个变体快了好几个数量级。
初始八卦者的随机化:在Fabric中,从订购服务接收所有区块的领导同伴总是发起传播。因此,它的下行带宽是普通对等体的fout倍。为了减轻这个负担,我们将f leaderout设置为1。根据预期,这将在其他网络同伴之间平均分配八卦阶段的开始阶段。
去除牵引力成分:通过将不完美传播的概率设置得足够低,牵引力成分就失去了它的作用,因此我们就去掉了它。在不太可能发生的情况下,对等端在推送阶段结束时无法接收到块,它将在恢复期间被提取。恢复组件可以满足其他基本需求,比如在崩溃后恢复,我们保持原样。
5 评估
我们评估我们改进的Fabric八卦模块,并将其与原始版本进行比较。我们的评估集中在三个标准:块传播的延迟、延迟对一致性冲突的影响和带宽消耗。
A.实验设置
我们使用1.2版本的Fabric。我们建立了一个由100个对等点组成的网络,它们属于一个单一的组织、一个客户端和一个CFT订购服务,由4个Kafka[22]节点和3个Zookeeper[26]节点组成,对应于基于Kafka的设置的默认配置。所有节点部署在15台8核Intel®Xeon®L5420 2.5 GHz 8核L5420处理器和8gb内存的集群上,通过1gbps以太网互连。所有组件都在Docker容器中运行,至少有一个专用内核。
在我们的第一组实验中,我们使用来自Fabric高吞吐量网络示例的链代码,该链代码建模n个加密货币资产,其值经常被修改[1]。
我们对orderers使用以下配置:块最多包含50个事务,如果接收到的事务少于50个,则超时2秒。在每次测试期间,我们依次启动50,000个事务,这样每1.5秒就会创建一个包含50个事务的完整块。这将导致1,000个块,每个块≈160 KB。
B.评估基线(原始Fabric八卦模块)
为了进行比较,我们使用上面描述的实验设置,在没有任何修改的情况下,对Fabric的原始八卦模块进行初步测试。对于push、pull和recovery组件,我们使用默认参数:push组件使用fout = 3和tpush = 10 ms的计时器,pull组件使用fin = 3,每个对等体每tpull = 4秒执行一次,对等体每recovery = 10秒执行一次恢复组件。
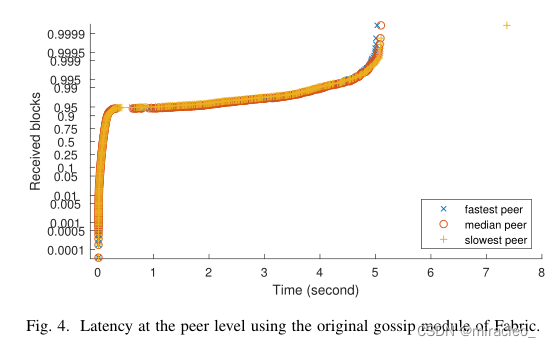
图4首先说明了对等层的延迟,它显示了从它们的传播开始接收块所需的时间(即由来自orderer节点的接触对等体接收它们)。它包括三个cdf,用于平均延迟最慢、中位数和最快的对等体。图5通过显示给定块到达每个网络对等点的速度,演示了块级别的延迟。
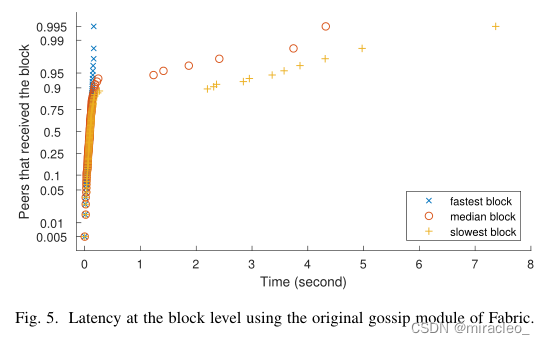
我们为最慢、中位和最快播散块包括三个cdf。图4和图5是基于逻辑分布的对数刻度的概率图,原因有二。首先,这允许关注尾部延迟。第二,大多数推送传播协议像逻辑函数一样增长(即在传播开始时呈指数增长,然后缓慢增长以通知最后的未通知过程),正如我们从图左侧的线性拟合中观察到的那样。在两张图中,胖尾和长尾都很明显,对应着从快速推阶段到较慢的拉阶段的过渡。
图6显示了leader对等体和随机选择的另一个对等体的带宽消耗(所有非leader对等体的行为都类似)。注意,出于可读性的考虑,我们将每个间隔的带宽聚合为10秒,因此在图中没有出现≈4 MB/s的最高流量峰值。事务的生成在≈1500秒后结束。图中还显示了1500 ~ 2000秒网络处于空闲状态时,所有任务的后台流量为0.4 MB/s,说明了优化疫情传播的带宽需求的相关性。领导对等点和其他对等点之间的主要区别是,领导对等点从订购服务接收每个块一次,并将其传播给其他对等点,而其他对等点并不总是这样做,因为有些块的感染和死亡推送阶段在未到达它们之前终止。
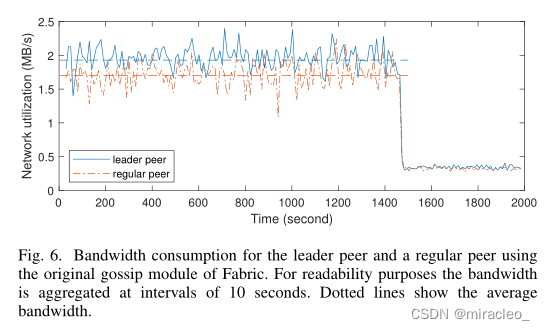
图6所示。leader对等体和普通对等体使用Fabric自带的gossip模块的带宽消耗。出于可读性的目的,带宽以10秒为间隔聚合。虚线表示平均带宽。
C.我们增强的Fabric八卦模块的评估
我们现在测试我们的增强型织物流言模块的性能,并将其与原始基线进行比较。我们选择参数以获得在一个由n=100个对等体组成的组织中不完美传播的概率为10-6,也就是说,在推送阶段,一个块没有到达所有对等体,需要恢复组件的概率最多为10-6。正如第四节所讨论的,我们再次强调,TTL可以对任何n进行精确计算,而且由于它随着n的变化而缓慢变化,所以可以在查找表中存储一些值。我们首先设置f leaderout = 1以减少领导者对等体的带宽负担。从领导者对等体那里收到块的对等体启动了流言。我们还完全删除了拉动阶段,因为它与恢复部分是多余的。
我们最后为数据块设置了tpush=0。令人惊讶的是,删除这个计数器对平均端到端延迟有不利影响,然而正如第四节所讨论的,这是确保无偏的随机性的最简单方法,导致我们协议的理论传播保证,而无需进一步修改Fabric代码库。
我们注意到,由于所选择的参数,我们的任何实验都不需要在任何点上求助于恢复组件,除非它在推阶段的中间被触发。出于传播的目的,这是从来没有必要的,但在某个时刻,如果我们用数百万个区块进行试验,就会出现这种情况。
在第一次计算中,我们设fout = blog nc = 4, TTL = 9。我们进一步设置TTLdirect = 2,因为碰撞在前两轮中非常罕见,可以避免发送摘要。与基线相同,图7、图8和图9分别显示了对等体级别的延迟、块级别的延迟以及领导对等体和其他对等体的带宽消耗。
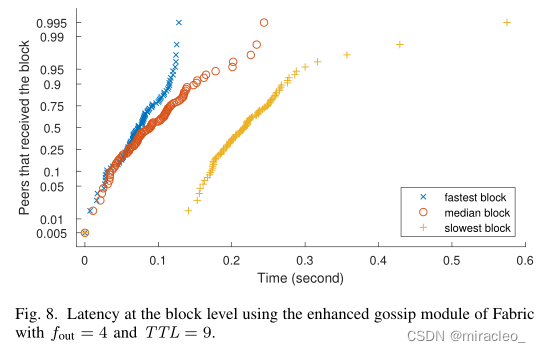
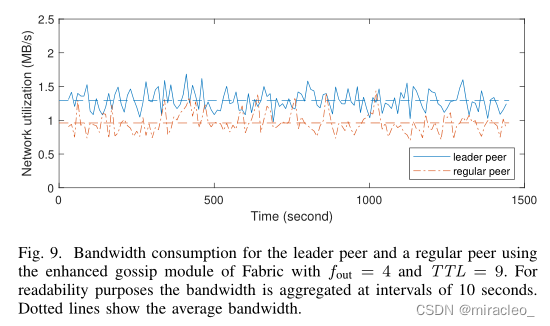
图9所示。使用Fabric的增强八卦模块,fout = 4, TTL = 9,对leader对等体和普通对等体的带宽消耗。出于可读性的目的,带宽以10秒为间隔聚合。虚线表示平均带宽。
Fabric的原始配置需要1到6秒才能到达最后5%的对等体,而增强的八卦模块在不到半秒的时间内就能将所有的块传播到所有的对等体。注意,图7和图8中的曲线几乎是线性的,这是我们从基于逻辑分布的对数刻度的概率图中预期的。
达到最后5%的对等点/块的坡度较缓,不是由于理论上预期的流行病传播,而是由于其他延迟来源。例如,图8右侧的黄色曲线对应的是本次实验中最慢的块。我们观察到这个块花了≈0.15秒到达发起广播的对等端,这是由于在领导对等端有延迟。
在带宽方面,对比图6和图9,我们观察到增强模块使普通对等体的带宽消耗减少了40%以上;总网络带宽消耗也减少了40%。我们强调,对于更大的块,这种差异将更加显著,因为它们的传播使所有其他系统任务的后台带宽相形见绌。
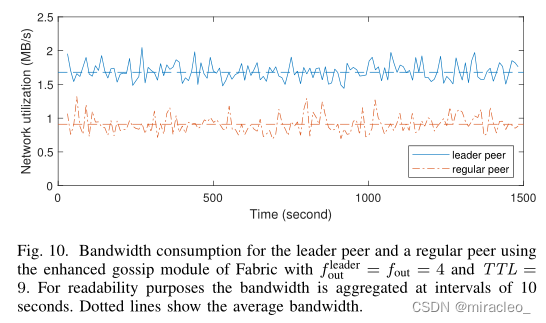
图10所示。leader对等体和普通对等体的带宽消耗使用Fabric的增强八卦模块,f leaderout = fout = 4, TTL = 9。出于可读性的目的,带宽以10秒为间隔聚合。虚线表示平均带宽。
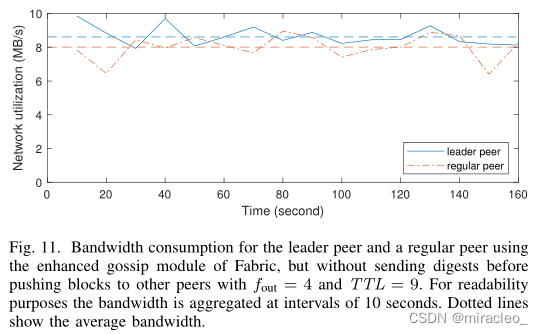
图11所示。使用Fabric的增强八卦模块,leader对等体和普通对等体的带宽消耗,但在fout = 4和TTL = 9向其他对等体推送块之前不发送摘要。出于可读性的目的,带宽以10秒为间隔聚合。虚线表示平均带宽。
请注意,为领导对等体设置f leaderout = 1和添加摘要并不是无用的奢侈。图10报告了同一评估的带宽使用情况,例外的是,领导对等体像其他节点一样使用f leaderout = fout = 4。我们观察到,在这种情况下,领导者对等体的带宽消耗要比其他对等体的高得多,这可能会导致大区块和/或高吞吐量应用的争夺问题。这很容易解释:根据预期,随机对等体对每个区块接收和传输一次,而领导者对等体将每个区块传播给其他对等体。最好是在其他99个对等体中均匀地随机委托这个初始广播阶段。更糟糕的是,图11报告了当对等体系统性地推送没有摘要的区块时,同一评估的带宽跳升到8MB/s。一旦在前三轮后有超过n log n个对等体被告知,碰撞的数量就会迅速增加,达到已经被告知的对等体之间不断交换相同区块的程度。
在第二次评估中,我们设定fout = 2和TTL = 19,这也保证了在推送阶段,一个区块以至少1 - 10-6的概率被传播给每个对等体。
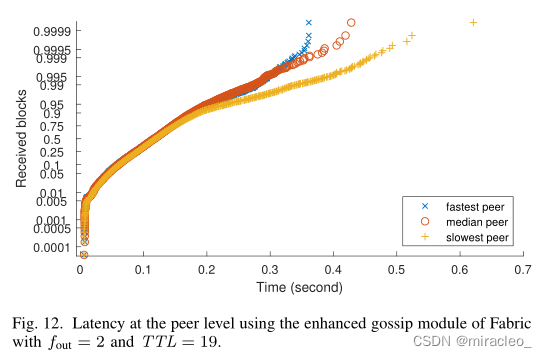
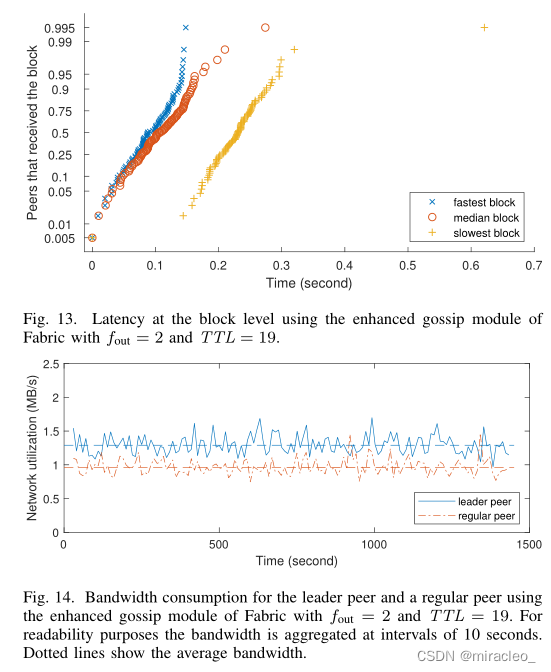
在这种设置下,我们可以使用TTLdirect = 3。再次,图12、13和14分别显示了对等水平的延迟、块水平的延迟以及领导者对等和其他对等的带宽消耗。通过比较图9和图14,我们发现平均和总体带宽消耗基本上没有变化。这并不奇怪,因为传输的摘要总数取决于不完美传播的概率,在两次评估中固定为10-6。我们还观察到,与图7相比,将fout从4减少到2使图12中的曲线斜率减半,这也是预期的。然而,有趣的观察是,两个实验的尾部和最坏情况下的延迟都相当相似。这意味着fout=4是一个积极的选择:虽然它加快了传播的早期阶段,但它不再是最慢的块和对等体的主要延迟来源。在更均匀的负载平衡下,fout = 2对我们的网络来说是个不错的选择。
D. 对织物一致性冲突的影响
我们最后评估了广播性能对一致性冲突发生的影响。我们专注于验证时间冲突,因此使用单一的认可对等体。我们改变了生成新区块的计时器,同时以每秒5个交易的固定速度发布。新区块只有在验证后才被对等人使用,验证所需的时间与每个区块的交易数量成正比,在我们的评估中,每个交易约50毫秒。较小的区块生成周期和较小的区块验证时间使我们更加重视传播延迟对冲突发生的影响。我们比较了原始Fabric八卦模块和我们使用fout=4和TTL=9的增强型八卦模块之间的一致性错误数量。
我们用一个简单的链码建立了一个实验,它将100个初始化为0的整数值中的一个递增,并存储在账本中。每个整数被递增100次。我们在每一轮递增之间使用随机排列的递增顺序。这就导致了总共有10,000个交易。递增一个整数需要读取其当前值。基于相同基值的两个增量将导致验证时间冲突。我们不重新发送冲突的交易;10,000和最终账本中所有计数器的总和之间的差值给出了验证时间冲突的数量。表二显示了我们在0.75秒到2秒之间的定时器值的结果。表中的每一项都是五个实验中冲突的平均数。
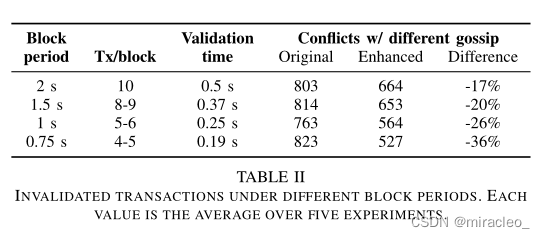
表二 在不同的区块周期下无效的事务。每个值都是五次实验的平均值。
使用原始的八卦模块时,冲突的数量平均在763到823之间。令人惊讶的是,我们观察到冲突的数量基本上与世代时期保持稳定。原因是,虽然广播需要几百毫秒将一个块传播到95%的对等点,但要到达最慢的5%的对等点却需要几秒钟(图5)。不管我们使用什么块周期,这种尾部传播延迟支配着排序和验证时间。
我们增强的八卦模块,具有较小的平均和最坏情况下的传播延迟(图8),显著地改进了原始Fabric八卦。如表II所示,平均冲突数量随着阻塞周期的增加而减少,在阻塞周期为2 s时减少到664,在阻塞周期为0.75 s时减少到527。这对应于与原始Fabric实现相比,无效事务的数量减少了17%到36%。
6 相关工作
尽管原生Fabric实现的分析和优化得到了很多关注,但很少有人关注八卦层或块传播。我们所知道的在这个方向上的唯一工作是Barger等人[4]的一个海报演示,他们讨论了Fabric的BlockStorm流行协议的早期工作。BlockStorm的目标是在广播过程中抵抗对手的影响。
由Lev-Ari等人[36]提出的FairLedger引入了一种经过许可的BFT区块链协议,该协议在Hyperledger Iroha上进行了测试,这是Fabric的替代框架,目标是在参与者将其交易附加到分类帐的机会方面实现公平性。该协议的核心再次聚焦于抗对抗广播,能够检测到对等的不当行为,如扣留消息。如果Fabric将八卦扩展到跨组织的工作中,这些解决方案代表了我们打算探索的补充工作线。
在多个研究中评估了Fabric的吞吐量和延迟。Sukhwani等[46]使用随机Petri网对织物的性能进行建模。他们表明,更大的块通过减少订购服务的瓶颈来提高吞吐量,但代价是更高的延迟。Baliga等人[3]提出了在各种场景中度量Fabric事务吞吐量和延迟的微基准测试。Thakkar等人[47]建议使用缓存和并行对背书阶段进行优化,而Javaid等人[28]建议对Fabric的验证阶段进行优化。Kwon和Y u[35]还评估了Fabric中订购和背书阶段的性能。本段中提到的所有工作都没有在足够多的同行中进行测试,以使广播八卦在公平或吞吐量方面发挥重要作用。
其他作品比较了Fabric不同版本的性能,并将Fabric与其他区块链框架进行了比较。Han等人[23]对Fabric (v0.6和v1.0)和Ripple[43]进行了比较。它关注BFT共识的影响。作者的结论是,拜占庭共识并不适合大型区块链部署,尽管Fabric达到了比Ripple更好的吞吐量。Pongnumkul等[41]提出了Fabric和使用单个区块链节点的以太坊私有部署之间的有限比较。作者得出的结论是,在这种基本设置下,Fabric的吞吐量和延迟都更好。Brandenburger等人[9]对原生Fabric实现和使用Intel SGX enclave集成可信链代码执行的体系结构进行了比较。使用飞地会导致少量的吞吐量降低和少量的延迟增加。
7 讨论及未来工作
在这个工作中,我们增强了Fabric八卦层。通过减少其延迟,我们减少了高吞吐量和并发应用程序中无效事务的数量。
我们增强的协议还显著降低了总体网络带宽消耗。我们提出了三个进一步改进的途径。
Fabric目前不允许在不同组织的对等体之间广播数据块。这是由于访问控制规则:可以通过随时从通道中删除组织来驱逐组织,而将块发送到外部组织的权限紧密依赖于这些规则。解决这个问题需要一些记账,但是围绕Fabric的开发社区正在考虑在未来的版本中启用它。随着Fabric的扩展,这肯定是一个很好的特性,因为由于大数定律,随着对等体数量的增加,流行病算法的良好属性会变得更加突出。
在理论方面,我们没有考虑到对抗性对等体试图通过故意丢弃从其他对等体接收到的块来阻碍传播。尽管在这种情况下,八卦流行传播明显优于确定性协议,但有必要对敌对同伴的影响和可能的对策进行正式分析。
使用交易流而不是区块,正如StreamChain[27]所提议的那样,可以大大减少订单的延迟,并更强调八卦的影响。一旦StreamChain被集成到Fabric中,我们将在这种设置下对增强的八卦进行评估,以备将来的工作。
我们最终打算将对八卦及其对一致性、公平性和性能的影响的研究扩展到其他区块链,包括许可的(如Sawtooth[40])和开放的(如以太坊[48])