JDBC
一、概述
在Java中,数据库存取技术可分为如下⼏类:
1、JDBC直接访问数据库
2、 JDO技术(Java Data Object)
3、第三⽅O/R⼯具,如Hibernate, Mybatis 等
JDBC是java访问数据库的基⽯,JDO, Hibernate等只是更好的封装了JDBC。
二、理解
JDBC(Java Database Connectivity)是⼀个独⽴于特定数据库管理系统(DBMS)、通⽤的SQL数据库存取和操作的公共接⼝(⼀组API),定义了⽤来访问数据库的标准Java类库,使⽤这个类库可以以⼀种标准的⽅法、⽅便地访问数据库资源
JDBC为访问不同的数据库提供了⼀种统⼀的途径,为开发者屏蔽了⼀些细节问题。
JDBC的⽬标是使Java程序员使⽤JDBC可以连接任何提供了JDBC驱动程序的数据库系统,这样就使得程序员⽆需对特定的数据库系统的特点有过多的了解,从⽽⼤⼤简化和加快了开发过程。
如果没有JDBC,那么Java程序访问数据库时是这样的:

有JDBC,那么Java程序访问数据库时是这样的:

三、JDBC API
JDBC API是⼀系列的接⼝,它统⼀和规范了应⽤程序与数据库的连接、执⾏SQL语句,并到得到返回结果等各类操作。声明在java.sql与javax.sql包中。
1、DriverManager类 管理不同的驱动
2、Connection 接⼝ 应⽤和数据库的连接
3、Statement 接⼝ ⽤于执⾏sql语句
4、 ResultSet 接⼝ 保存查询的结果
四、JDBC的使用
1、下载驱动:
驱动程序由数据库提供商提供下载。 MySQL的驱动下载地址:http://dev.mysql.com/downloads/
2、创建项⽬导⼊jar包
3、 使⽤:
① 注册驱动(加载驱动)
② 获取连接对象
③ 创建命令对象
④ 编写sql命令
⑤ 执⾏sql命令 返回结果
⑥ 处理结果
⑦ 释放资源
private static void queryAll() throws ClassNotFoundException, SQLException {
// 1、加载驱动
// DriverManager.registerDriver(new com.mysql.jdbc.Driver());
Class.forName("com.mysql.jdbc.Driver");
// 2、获取连接 参数1:连接路径 参数2:用户名 参数3:密码
// https://downloads.mysql.com/archives/c-j/
Connection connection = DriverManager
.getConnection("jdbc:mysql://localhost:3306/java0210", "root", "123456");
System.out.println(connection);
System.out.println(connection==null?"连接失败":"连接成功");
//3、 编写sql语句
String sql = "select * from user";
//4、创建命令对象
Statement statement = connection.createStatement();
//5、执行sql语句 返回结果
ResultSet rs = statement.executeQuery(sql);
//6、处理结果 rs.next()如果为true 集合中还有内容 如果为false 数据获取完毕
while(rs.next()){
String name = rs.getString("name");
int age = rs.getInt("age");
System.out.println("姓名:"+name+"\t姓名:"+age);
// System.out.println(rs.getString("name")+" 年龄:"+rs.getInt("age"));
}
//7、释放资源 遵循 先开后关原则
rs.close();
statement.close();
connection.close();
}
五、连接池
5.1、为什么使用连接池
1、数据库连接是⼀种关键的有限的昂贵的资源,传统数据库连接每发出⼀个请求都要创建⼀个连接对象,使⽤完直接关闭不能重复利⽤;
2、关闭资源需要⼿动完成,⼀旦忘记会造成内存溢出;
3、请求过于频繁的时候,创建连接极其消耗内存;
4、⽽且⼀旦⾼并发访问数据库,有可能会造成系统崩溃。
为了解决这些问题,我们可以使⽤连接池。
5.2、连接池原理
数据库连接池负责分配、管理和释放数据库连接,它的核⼼思想就是连接复⽤,通过建⽴⼀个数据库连接池,这个池中有若⼲个连接对象,当⽤户想要连接数据库,就要先从连接池中获取连接对象,然后操作数据库。⼀旦连接池中的连接对象被⽤完了,判断连接对象的个数是否已达上限,如果没有可以再创建新的连接对象,如果已达上限,⽤户必须处于等待状态,等待其他⽤户释放连接对象,直到连接池中有被释放的连接对象了,这时候等待的⽤户才能获取连接对象,从⽽操作数据库。这样就可以使连接池中的连接得到⾼效、安全的复⽤,避免了数据库连接频繁创建、关闭的开销。这项技术明显提⾼对数据库操作的性能。
5.3、连接池的好处
1、程序启动时提前创建好连接,不⽤⽤户请求时创建,给服务器减轻压⼒;
2、连接关闭的时候不会直接销毁connection,这样能够重复利⽤;
3、如果超过设定的连接数量但是还没有达到最⼤值,那么可以再创建;
4、如果空闲了,会默认销毁(释放)⼀些连接,让系统性能达到最优;
5.4、常见的开源连接池
1、 【DBCP】是Apache提供的数据库连接池,速度相对c3p0较快,但因⾃身存在BUG,Hibernate3已不再提供⽀持
2、【C3P0】是⼀个开源组织提供的⼀个数据库连接池,速度相对较慢,稳定性还可以
3、【Druid】是阿⾥提供的数据库连接池,据说是集DBCP 、C3P0 、Proxool 优点于⼀身的数据库连接池,但是速度不知道是否有BoneCP快
5.5、连接池的使用
5.5.1、c3p0连接池
1、下载导包 c3p0-0.9.5.2.jar mchange-commons-java-0.2.11.jar
代码配置⽅式
① 创建c3p0连接池对象
//1、创建连接池对象
ComboPooledDataSource cpds = new ComboPooledDataSource();
② 配置信息 (必配、选配) 【创建 c3p0.properties 放在src⽬录下】
#必配信息
c3p0.driverClass = com.mysql.jdbc.Driver
c3p0.jdbcUrl = jdbc:mysql://localhost:3306/java0210
c3p0.user = root
c3p0.password = 123456
#选配
c3p0.InitialPoolSize = 10 #初始连接数
c3p0.MaxPoolSize = 200 #最大连接数
c3p0.MinPoolSize = 15 #最小连接数
c3p0.MaxIdleTime = 30 #最大空闲时间
③ 从池⼦中获取连接
//从池子中获取连接
Connection connection = cpds.getConnection();
④ sql 操作
//1、编写sql
String sql = "select * from user where age = 23";
//2、创建命令对象
Statement statement = connection.createStatement();
//3、执行命令 返回结果
ResultSet resultSet = statement.executeQuery(sql);
//4、处理结果
if (resultSet.next()){
String name = resultSet.getString("name");
int age = resultSet.getInt("age");
System.out.println("姓名:"+name+"\t姓名:"+age);
}
//5、把连接对象放回连接池
connection.close();
5.5.2、Druid连接池
1、下载导包 druid-1.1.10.jar 在lib目录下
2、 编写druid.properties 放在src⽬录下
#必配
driver.ClassName = com.mysql.jdbc.Driver
url = jdbc:mysql://localhost:3306/java0210
username = root
password = 123456
#选配
initialSize = 15 #初始连接数
maxActive = 100 #最大连接数
minIdle = 5 #最小连接数
maxWait = 30000 #最大空闲时间
3、读取配置文件
// 一、读取配置文件
Properties properties = new Properties();
// 根据当前线程对象的上下文类加载器 以流的方式 读取src目录下的文件
InputStream asStream = Thread.currentThread()
.getContextClassLoader().getResourceAsStream("druid.properties");
properties.load(asStream);
4、创建druid连接池对象
// 二、创建druid连接池对象
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
5、从连接池中获取连接
//从池子中获取连接
Connection connection = dataSource.getConnection();
6、sql 操作
//1、编写sql
String sql = "select * from user where age = 23";
//2、创建命令对象
Statement statement = connection.createStatement();
//3、执行命令 返回结果
ResultSet resultSet = statement.executeQuery(sql);
//4、处理结果
if (resultSet.next()){
String name = resultSet.getString("name");
int age = resultSet.getInt("age");
System.out.println("姓名:"+name+"\t姓名:"+age);
}
//5、把连接对象放回连接池
connection.close();
5.6、封装JDBCTools
ThreadLocal类
【理解】JDK 1.2的版本中就提供java.lang.ThreadLocal,ThreadLocal为解决多线程程序的并发问题提供了⼀种新的思路。使⽤这个⼯具类可以很简洁地编写出优美的多线程程序。
【原理】
ThreadLocal⽤于保存某个线程共享变量,原因是在Java中,每⼀个线程中都有⼀个ThreadLocalMap<ThreadLocal, Object>,其key就是⼀个ThreadLocal,⽽Object即为该线程的共享变量。⽽这个map是通过ThreadLocal的set和get⽅法操作的。对于同⼀个static ThreadLocal,不同线程只能从中get,set,remove⾃⼰的变量,⽽不会影响其他线程的变量。
【使⽤】
1、ThreadLocal.get: 获取ThreadLocal中当前线程共享变量的值。
2、ThreadLocal.set: 设置ThreadLocal中当前线程共享变量的值。
3、ThreadLocal.remove: 移除ThreadLocal中当前线程共享变量的值。
public class JDBCPoolTools2 {
static DataSource dataSource;
// 实例化ThreadLocal类
private static ThreadLocal<Connection> t = new ThreadLocal<>();
static {
try{
// 一、读取配置文件
Properties properties = new Properties();
// 根据当前线程对象的上下文类加载器 以流的方式 读取src目录下的文件
InputStream asStream = Thread.currentThread()
.getContextClassLoader().getResourceAsStream("druid.properties");
properties.load(asStream);
//2、创建连接池
dataSource = DruidDataSourceFactory.createDataSource(properties);
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
// 定义一个获取连接的静态方法
public static Connection getConnection(){
try {
//1、从连ThreadLocal中获取连接
Connection connection = t.get();
if (connection==null){
//2、如果连接为空,从连接池中获取一个连接对象
t.set(dataSource.getConnection());
//3、把这个连接对象绑定到ThreadLocal类
connection = t.get();
}
return connection;
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
//封装释放连接对象的方法
public static void release(){
// 1、将连接对象 和 ThreadLocal类 解绑
Connection connection = t.get();
t.remove();
// 2、释放资源
if (connection!=null){
try {
connection.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
}
测试类
public static void main(String[] args) {
// 建立连接 从JDBCPoolTools2中调用 getConnection()方法
Connection connection = JDBCPoolTools2.getConnection();
try {
// sql操作
String sql = "select * from admin_user";
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery(sql);
while (resultSet.next()){
String username = resultSet.getString("username");
String password = resultSet.getString("password");
System.out.println("账号:"+username+"\t密码:"+password);
}
} catch (SQLException e) {
throw new RuntimeException(e);
}finally {
// 必须必须【解绑】和【释放资源】,从JDBCPoolTools2中调用 release()方法
if (connection!=null){
Up_DruidPool_03.release();
}
}
}
六、juint
6.1、概述
JUnit是⼀个Java语⾔的单元测试框架。测试分为:⿊盒测试和⽩盒测试。
⿊盒测试⼜称功能测试,主要检测每个功能是否都能正常使⽤。在测试中,把程序看作⼀个不能打开的⿊盒⼦,在完全不考虑程序内部结构和内部特性的情况下,进⾏测试,主要针对软件界⾯和软件功能进⾏测试。 ⽩盒测试⼜称结构测试、透明盒测试、逻辑驱动测试或基于代码的测试,主要检测程序内部逻辑是否正常。在测试中测试者必须检查程序的内部结构,从检查程序的逻辑着⼿,得出测试数据。按照程序内部的结构进⾏测试。这⼀⽅法是把测试对象看作⼀个打开的盒⼦,测试⼈员清楚盒⼦内部的东⻄以及⾥⾯是如何运作的单元测试Junit就属于⽩盒测试.
6.2、使用
1、把junit4.x的测试jar,添加到该项⽬中来;
2、定义⼀个测试类 测试类的名字: XxxTest,如EmployeeDAOTest
3、 在EmployeeDAOTest中编写测试⽅法:如
@BeforeClass public static void beforeClass(){ } @Before public void bef(){ } @Test public void testXxx() throws Exception { } @After public void aft(){ } @AfterClass public static void afterClass(){ }注意:⽅法是public修饰的,⽆返回的,该⽅法上必须贴有@Test标签,XXX表示测试的功能名字
4、选择某⼀个测试⽅法,⿏标右键选择 [run as junit],或则选中测试类,表示测试该类中所有的测试⽅法.
6.3、常见注解
1、@Test:要执⾏的测试⽅法
2、@Before:每次执⾏测试⽅法之前都会执⾏
3、@After: 每次执⾏测试⽅法之后都会执⾏
4、 @BeforeClass:在所有的Before⽅法之前执⾏,只在最初执⾏⼀次. 只能修饰静态⽅法
5、@AfterClass:在所有的After⽅法之后执⾏,只在最后执⾏⼀次. 只能修饰静态⽅法
七、SQL注入
7.1、理解
SQL 注⼊是利⽤某些系统没有对⽤户输⼊的数据进⾏充分的检查,⽽在⽤户输⼊数据中注⼊⾮法的 SQL 语句段或命令,从⽽利⽤系统的 SQL 引擎完成恶意⾏为的做法。对于 Java ⽽⾔,要防范 SQL 注⼊,只要⽤
PreparedStatement 取代 Statement 就可以了。
7.2、解决
SQL注入问题:sql语句中拼接了一些特殊字符 导致sql语句发生变化的现象
引发原因:特殊字符导致解决:将特殊字符转义为普通字符 将传递的字符作为一个整体 Statement命令对象 换成PreparedStatementPreparedStatement 原理:预编译命令对象1、sql语句时 使用?作为占位符 如果里面有特殊符号 自动转义
2、先编译sql语句 执行时再传递参数
PreparedStatement 好处:
1. 不用拼接字符串 避免了拼接字符串产生的问题2. 自检特殊字符3. 可以复用sql语句
【案例】
模拟用户登录的功能
1. 输入账户和密码2. 查询数据库中是否有该用户有 登录成功没有 登录失败
public class JDBCTest2 {
String username;
String pwd;
Connection connection;
@Before
public void bef(){
Scanner input = new Scanner(System.in);
System.out.println("请输入用户名:");
username = input.nextLine();
System.out.println("请输入密码:");
pwd = input.nextLine();
connection = JDBCTools.getConnection();
}
@Test // 使用Statement
public void testLogin1(){
// 根据用户名和密码查询用户
try {
// select * from user where name='大洋洋' and password='123321';
String sql = "select * from user where name='"+username+"' and password='"+pwd+"'";
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery(sql);
System.out.println(resultSet.next()?"登录成功!":"登录失败!");
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
@Test // 使用PreparedStatement
public void testLogin2(){
try {
// 1. 编写sql语句
String sql = "select * from user where name=? and password=?";
// 2. 创建命令对象 预编译sql语句
PreparedStatement preparedStatement = connection.prepareStatement(sql);
// 3. 传递sql中的参数
preparedStatement.setString(1, username);
preparedStatement.setString(2, pwd);
// 4. 执行sql命令
ResultSet resultSet = preparedStatement.executeQuery();
// 5. 处理结果
System.out.println(resultSet.next()?"登录成功!":"登录失败!");
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
@After
public void aft(){
JDBCTools.release();
}
}
八、事务实现
1、 ⼿动开启事务 setAutoCommit(false)
2、 成功 提交 commit()
3、失败 回滚 rollback()
public class JDBCTxTest {
Connection connection;
@Before
public void bef(){
connection = JDBCTools.getConnection();
}
@Test // 使用事务
public void textUseTx(){
try {
// 1. 设置事务提交为手动 2. 开启一个新的事务
connection.setAutoCommit(false);
String sql = "update user set money=? where uid=?";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.setDouble(1, 900);
preparedStatement.setInt(2, 1);
preparedStatement.executeUpdate();
// 模拟异常
int i = 10/0;
preparedStatement.setDouble(1, 1100);
preparedStatement.setInt(2, 2);
preparedStatement.executeUpdate();
connection.commit();
System.out.println("转账成功!");
} catch (SQLException throwables) {
try {
connection.rollback();
} catch (SQLException e) {
e.printStackTrace();
}
throwables.printStackTrace();
}
}
@After
public void aft(){
JDBCTools.release();
}
}
九、批处理
9.1、概述
JDBC操作数据库的时候,需要⼀次性插⼊⼤量的数据的时候,如果每次只执⾏⼀条SQL语句,效率可能会⽐较低。这时可以使⽤batch操作,每次批量执⾏SQL语句,调⾼效率。
9.2、实现
1、 添加批处理 addBacth();
2、执⾏批处理 executeBacth();
3、清除批处理 clearBatch();
public class JDBCBatchTest {
Connection connection;
@Before
public void bef(){
connection = JDBCTools.getConnection();
}
@Test // 使用批处理
public void textUseBatch(){
try {
String sql = "insert into user(name, password, money) values(?,?,?)";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
long start = System.currentTimeMillis();
for(int i=1; i<=10000; i++){
preparedStatement.setString(1,"root"+i);
preparedStatement.setString(2, i+"");
preparedStatement.setDouble(3, i);
// 保存到批处理中
preparedStatement.addBatch();
if(i%100==0){
// 执行批处理
preparedStatement.executeBatch();
// 清除批处理 便于下一次使用
preparedStatement.clearBatch();
}
}
long end = System.currentTimeMillis();
System.out.println("插入10000条花费的时间:"+(end-start)); // 6080
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
@After
public void aft(){
JDBCTools.release();
}
}
十、DBUtils
10.1、简介
commons-dbutils 是 Apache 组织提供的⼀个开源 JDBC⼯具类库,它是对JDBC的简单封装,学习成本极低,并且使⽤dbutils能极⼤简化jdbc编码的⼯作量,同时也不会影响程序的性能。
10.2、作用
DbUtils :提供如关闭连接、装载JDBC驱动程序等常规⼯作的⼯具类,⾥⾯的所有⽅法都是静态的。
该包封装了SQL的执⾏,是线程安全的。
1、可以实现增、删、改、查、批处理、
2、考虑了事务处理需要共⽤Connection。
3、该类最主要的就是简单化了SQL查询,它与ResultSetHandler组合在⼀起使⽤可以完成⼤部分的数据库操作,能够⼤⼤减少编码量。
10.2、常用方法
1、操作:update()
public int update(Connection conn, String sql, Object… params) throws SQLException:
⽤来执⾏⼀个更新(插⼊、更新或删除)操作。
2、 查询:query()
public Object query(Connection conn, String sql, ResultSetHandler rsh,Object…
params) throws SQLException:执⾏⼀个查询操作,在这个查询中,对象数组中的每个元素值被⽤来作为查询语句的置换参数。该⽅法会⾃⾏处理 PreparedStatement 和 ResultSet 的创建和关闭。
【注】:该接⼝⽤于处理 java.sql.ResultSet,将数据按要求转换为另⼀种形式。ResultSetHandler 接⼝提供了⼀个单独的⽅法:Object handle (java.sql.ResultSet rs)该⽅法的返回值将作为QueryRunner类的query()⽅法的返回值
【⽅法】:
ArrayHandler:把结果集中的第⼀⾏数据转成对象数组。
ArrayListHandler:把结果集中的每⼀⾏数据都转成⼀个数组,再存放到List中。
BeanHandler:将结果集中的第⼀⾏数据封装到⼀个对应的JavaBean实例中。
BeanListHandler:将结果集中的每⼀⾏数据都封装到⼀个对应的JavaBean实例中,存放到List⾥。
ColumnListHandler:将结果集中某⼀列的数据存放到List中。
KeyedHandler(name):将结果集中的每⼀⾏数据都封装到⼀个Map⾥,再把这些map再存到⼀个map⾥,其
key为指定的key。
MapHandler:将结果集中的第⼀⾏数据封装到⼀个Map⾥,key是列名,value就是对应的值。
MapListHandler:将结果集中的每⼀⾏数据都封装到⼀个Map⾥,然后再存放到List
10.4、使用
1、下载导包 commons-dbutils-1.7.jar
2、创建核⼼对象
QueryRunner qr = new QueryRunner();
3、执⾏命令
// 执⾏增删改
int update = qr.update(connection,sql,params);
// 查询单条数据
T t = qr.query(connection,sql,new BeanHandler,params);
// 查询多条数据
List t = qr.query(connection,sql,new BeanListHandler,params);
// 查询特殊数据类型,如返回值为数量等等
Object t = qr.query(connection,sql,new ScalerHandler,params);
十一、Dao封装
11.1、介绍
Data Access Object访问数据信息的类和接⼝,包括了对数据的CRUD(Create、Retrival、Update、Delete),⽽不包含任何业务相关的信息
11.2、作用
为了实现功能的模块化,更有利于代码的维护和升级。
11.3、封装
封装通用的类:可以对任何表都能实现 增删改查的功能
1. 增 删 改的方法2. 查询的方法[单查、多查、查询个数]
public class BasicDao<T> {
QueryRunner qr;
{
qr = new QueryRunner();
}
// 1. 增删改方法
public int update(String sql, Object...params){
try {
return qr.update(JDBCTools.getConnection(), sql, params);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
// 2. 查询单个
public T querySingle(String sql, Class<T> clazz, Object...params){
try {
return qr.query(JDBCTools.getConnection(), sql, new BeanHandler<>(clazz), params);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
// 3. 查询多个
public List<T> queryMore(String sql, Class<T> clazz, Object...params){
try {
return qr.query(JDBCTools.getConnection(), sql, new BeanListHandler<>(clazz), params);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
// 4. 查询个数
public Object scale(String sql, Object...params){
try {
return qr.query(JDBCTools.getConnection(), sql, new ScalarHandler<>(), params);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
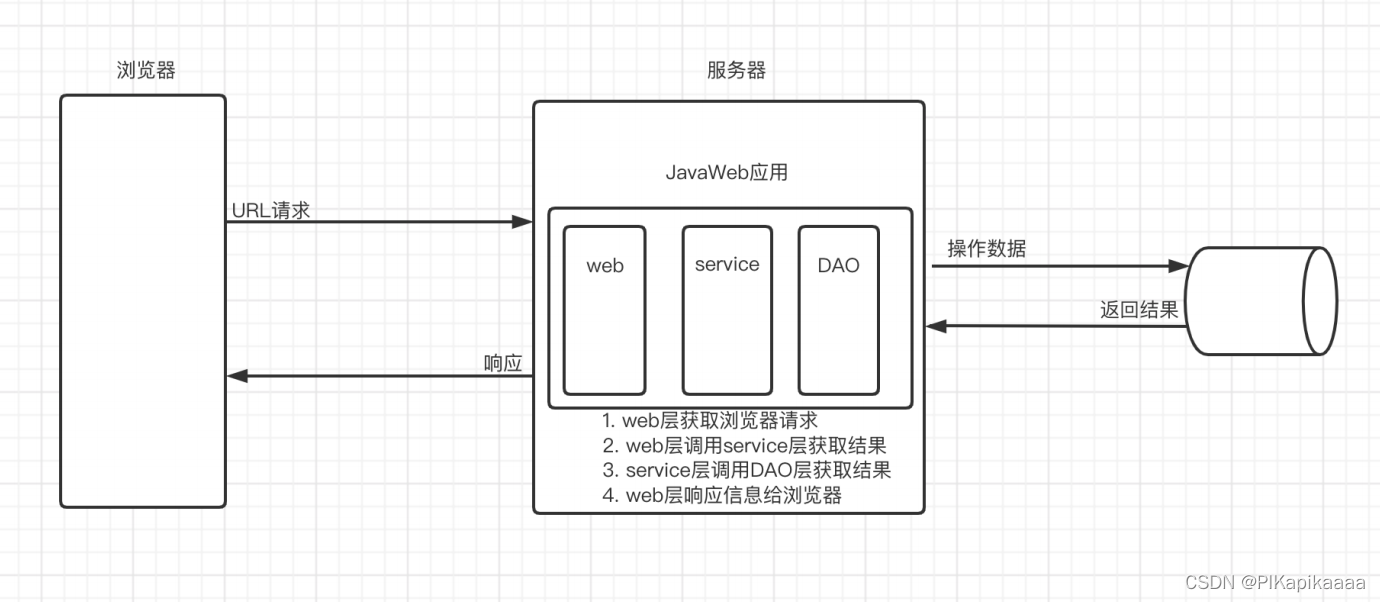
十二、项目三层架构
12.1、理解
【三层架构】 通常意义上的三层架构就是将整个业务应⽤划分为:界⾯层、业务逻辑层、数据访问层。区分层次的⽬的即为了 “⾼内聚低耦合” 的思想。在软件体系架构设计中,分层式结构是最常⻅,也是最重要的⼀种结构。微软推荐的分层式结构⼀般分为三层,从下⾄上分别为:数据访问层、业务逻辑层(⼜或称为领域层)、表示层。
表示层(JSP)
表现层也称为界⾯层,位于最外层(最上层),离⽤户最近。⽤于显示数据和接收⽤户输⼊的数据,为⽤户提供⼀种交互式操作的界⾯。
业务层(service)
业务层在体系架构中的位置很关键,它处于数据访问层与表示层中间,起到了数据交换中承上启下的作⽤。
由于层是⼀种弱耦合结构,层与层之间的依赖是向下的,底层对于上层⽽⾔是“⽆知”的,改变上层的设计对于其调⽤的底层⽽⾔没有任何影响。如果在分层设计时,遵循了⾯向接⼝设计的思想,那么这种向下的依赖也应该是⼀种弱依赖关系。
持久层(DAO)
持久层,有时候也称为是数据访问层,其功能主要是负责数据库的访问,可以访问数据库系统
12.2、特点
1、上⼀层可以调⽤下⼀层 但是 下⼀层不能调⽤上⼀层
2、不可以隔层调⽤
return qr.query(JDBCTools.getConnection(), sql, new ScalarHandler<>(), params);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
## 十二、项目三层架构
### 12.1、理解
> 【**三层架构**】 通常意义上的三层架构就是将整个业务应⽤划分为:界⾯层、业务逻辑层、数据访问层。区分层次的⽬的即为了 “⾼内聚低耦合” 的思想。在软件体系架构设计中,分层式结构是最常⻅,也是最重要的⼀种结构。微软推荐的分层式结构⼀般分为三层,从下⾄上分别为:数据访问层、业务逻辑层(⼜或称为领域层)、表示层。
>
> **表示层(JSP)**
>
> 表现层也称为界⾯层,位于最外层(最上层),离⽤户最近。⽤于显示数据和接收⽤户输⼊的数据,为⽤户提供⼀种交互式操作的界⾯。
>
> **业务层(service)**
>
> * 业务层在体系架构中的位置很关键,它处于数据访问层与表示层中间,起到了数据交换中承上启下的作⽤。
>
> * 由于层是⼀种弱耦合结构,层与层之间的依赖是向下的,底层对于上层⽽⾔是“⽆知”的,改变上层的设计对于其调⽤的底层⽽⾔没有任何影响。如果在分层设计时,遵循了⾯向接⼝设计的思想,那么这种向下的依赖也应该是⼀种弱依赖关系。
>
> **持久层(DAO)**
>
> 持久层,有时候也称为是数据访问层,其功能主要是负责数据库的访问,可以访问数据库系统
### 12.2、特点
> 1、上⼀层可以调⽤下⼀层 但是 下⼀层不能调⽤上⼀层
>
> 2、不可以隔层调⽤