Spark任务的划分和调度
一. Job、Stage、Task的概念
在讲Spark的任务的划分和调度之前,需要明确Spark中Job、Stage、Task的概念。
- Job:Spark中的算子分为转换(transformation)算子和行动(action)算子,一个action就会触发一个Job。
- Stage:一个Job分为一个或者多个Stage,Stage以RDD宽依赖(也就是shuffle)为界,shuffle前后的RDD属于不同的Stage,Stage的数量等于shuffle操作的数量+1,如图
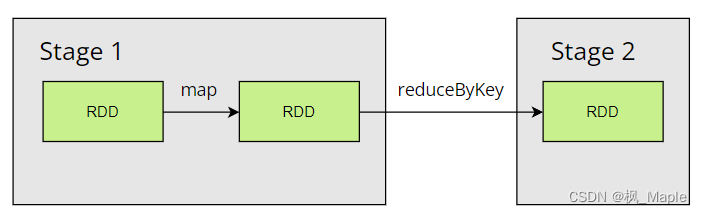
- Task:一个Stage包含一个或者多个Task,一个Stage包含的Task的数量等于这个Stage最后一个RDD的partition的数量。Task中包含了这个计算任务的计算逻辑以及数据位置等信息,Task是Executor执行任务的最小单位。
二. Spark任务执行的流程
在上一篇文章中,我们讲解了Spark提交任务的整个流程(Spark on Yarn提交任务过程)。以yarn cluster模式提交一个Spark任务之后,会依次做以下几件事情:
- 启动ApplicationMaster
- ApplicationMaster会启动Driver线程
- Driver线程进行SparkContext的初始化,SparkContext中有三个重要的组件:DAGScheduler,TaskScheduler,SchedulerBackend
- ApplicationMaster向yarn ResourceManager申请Container资源,申请成功后启动Executor,Executor会向Driver反向注册
- action行动算子触发,向Driver线程提交一个Job
- Job执行完毕,Spark程序执行完成
这篇文章主要就是讲解第5步。action行动算子触发后,会生成一个Job,然后向Driver提交,整个过程如何呢?
1. DAGScheduler,TaskScheduler,SchedulerBackend
DAGScheduler,TaskScheduler,SchedulerBackend是Driver中三个非常重要的组件,他们的作用如下:
- DAGScheduler:根据RDD的依赖关系,将Job划分为一个或多个Stage,每个Stage会依据最后一个RDD的partition的数量生成一个或多个Task,同一Stage的Task属于同一TaskSet(任务集),DAGScheduler向TaskScheduler提交任务是以TaskSet为单位
- TaskScheduler:接收来自DAGScheduler提交的TaskSet,向Executor分发Task
- SchedulerBackend:TaskScheduler与Executor进行RPC通信的后台

2. Job提交的流程
RDD经过一系列transformation算子,形成RDD的血缘关系图,并得到ResultRDD。ResultRDD提交给DAGScheduler,DAGScheduler能通过ResultRDD得到所有RDD的依赖关系(DAG图),并依据DAG图将Job划分得到一个或多个Stage,每一个Stage会形成一个TaskSet,DAGScheduler会依次向TaskScheduler提交这些TaskSet。TaskScheduler负责Task级别的调度,调度过程由SchedulerBackend向TaskScheduler返回可用的Executor列表,TaskScheduler依据一定的策略从TaskPool中取出TaskSet,然后将TaskSet中的Task分发给Executor执行,分发Task的命令同样由SchedulerBackend通过RPC向Executor传达。各个模块之间的交互如图所示:
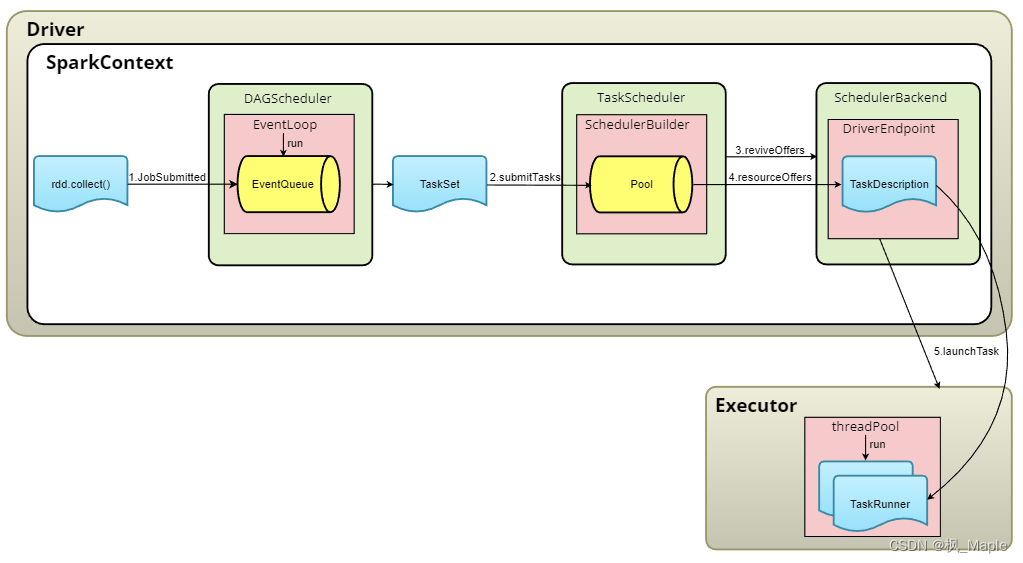
三. DAGScheduler
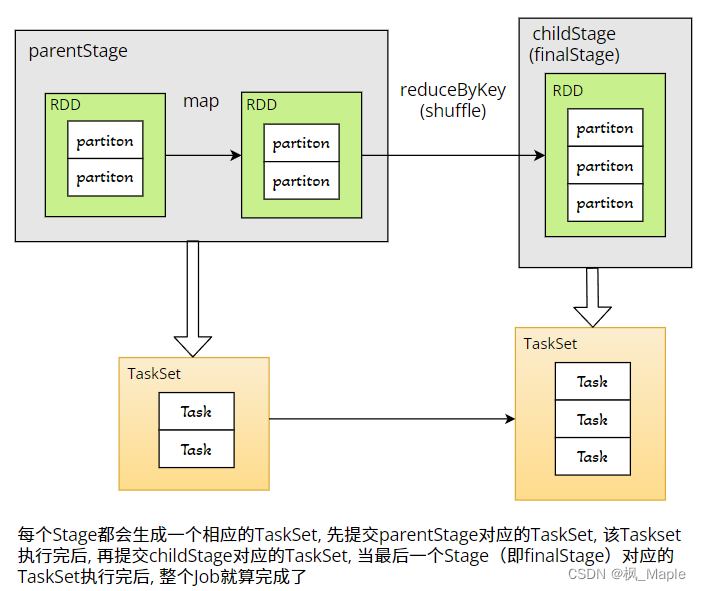
DAGScheduler的runJob方法用来对RDD的行动算子生成一个Job,并对Job进行调度和提交,整个过程如下:
- 为这个Job生成一个JobId,这个JobId是全局唯一的。
- 生成finalStage,finalStage是RDD的DAG图中最后一个Stage。
- 依据DAG图,从finalStage一级一级向上找他的parent stage,直到第一级的Stage,第一级的Stage没有parent stage,即他不依赖其他的Stage。
- 将第一级Stage生成为一个TaskSet,TaskSet包含了一系列Task,每一个Task就是这个Stage的RDD的一个partiton的计算任务,Task中包含了这个计算任务的计算逻辑以及partiton的数据位置等信息。
- 将这个TaskSet提交给TaskScheduler。
- TaskScheduler执行完TaskSet中的所有Task,会通知DAGScheduler,DAGScheduler对这个TaskSet对应的Stage的childStage执行第4步,如此往复循环,直到执行完finalStage,整个Job就算完成了。
如图所示:
四. TaskScheduler
TaskScheduler接收来自DAGScheduler提交的TaskSet,并放入任务池(Pool),通过一定的策略不断地从Pool中取出TaskSet,然后将TaskSet中的Task分发给Executor执行。整个过程如下:
- 将TaskSet封装为一个TaskSetManager
- 将TaskSetManager加入到Pool中
- TaskScheduler向SchedulerBackend发出一条ReviveOffers命令
- SchedulerBackend接收到命令,向TaskScheduler返回可用的Executor列表以及这些Executor的相关的信息
- TaskScheduler按照一定的策略和任务优先级从Pool中依次取出TaskSetManager,然后将TaskSetManager中的Task分发给Executor,分发的原则是尽可能地将Task均匀地分发给Executor,同时会考虑节点本地性
- TaskScheduler将Task->Executor的映射信息打包成TaskDescription发送给SchedulerBackend。
- SchedulerBackend根据TaskDescription将每个Task分发到其对应的Executor
- Executor执行完分发给他的Task,通知TaskScheduler
- 如果TaskScheduler发现TaskSet中的所有Task都已经完成了,则会通知DAGScheduler,然后DAGScheduler继续向TaskScheduler提交下一个TaskSet
整个过程如图所示:

五. TaskScheduler的调度TaskSet和分配Task的原理
1. TaskSet的调度
TaskScheduler内部有两个调度算法:FIFO(先进先出算法)和FAIR(公平调度算法),默认是使用FIFO算法,也就是哪个TaskSet先提交,哪个TaskSet的优先级就越高。而FAIR算法则会综合考虑TaskSet的Task数量以及Task运行所需要的资源,总的来说就是,Task数越少、Task运行所需资源越少的TaskSet优先级越高。
2. Task的分配
Task的分配指的是将TaskSet中的哪个Task分配给哪个Executor,依据的原则主要是Task的节点本地性(TaskLocality)。
2.1 什么是节点本地性
Task内部有一个成员变量:
def preferredLocations: Seq[TaskLocation] = Nil
preferredLocations表明了这个Task的位置偏好,这个变量的值是根据Task的数据的位置得到的,可以是一个hostName或者execotorId。例如,如果Task的数据是在192.168.5.101和192.168.5.102这两台机器上,那么:
preferredLocations=["192.168.5.101","192.168.5.102"]
然后,TaskSetManager内部有这么几个变量,用来保存他的所有的Task的节点偏好:
// Set of pending tasks for each executor.
val forExecutor = new HashMap[String, ArrayBuffer[Int]]
// Set of pending tasks for each host. Similar to pendingTasksForExecutor, but at host level.
val forHost = new HashMap[String, ArrayBuffer[Int]]
// Set containing pending tasks with no locality preferences.
val noPrefs = new ArrayBuffer[Int]
// Set of pending tasks for each rack -- similar to the above.
val forRack = new HashMap[String, ArrayBuffer[Int]]
// Set containing all pending tasks (also used as a stack, as above).
val all = new ArrayBuffer[Int]
- forExecutor是一个HashMap,key为executorId,value是preferredLocations为这个executor的所有task的taskId
- forHost是一个HashMap,key为hostName,value是preferredLocations为这个host的所有task的taskId
- noPrefs是一个Array,保存了所有无任何preferredLocations的task的taskId
- forRack是一个HashMap,key为rackName,value是preferredLocations为这个rack的所有task的taskId
- all是一个Array,保存了所有task的taskId,可以理解为是上面4个集合的taskId的并集
TaskSetManager中还有一个重要的成员变量:
private[scheduler] var myLocalityLevels:Array[TaskLocality.TaskLocality]
这个变量保存了TaskSetManager的本地性级别(locality levels),这个变量是根据上述5个集合是否为空来确定的:
//伪码:
myLocalityLevels=new Array[TaskLocality.TaskLocality]
if forExecutor.isNotEmpty:
myLocalityLevels += PROCESS_LOCAL
if forHost.isNotEmpty:
myLocalityLevels += NODE_LOCAL
if noPrefs.isNotEmpty:
myLocalityLevels += NO_PREF
if forRack.isNotEmpty:
myLocalityLevels += RACK_LOCAL
myLocalityLevels += Any
举个例子:
TaskSetManager中有3个Task,他们的preferredLocations分别为:
task1:preferredLocations=["192.168.5.101"] //task1的数据在192.168.5.101这台机器上
task2:preferredLocations=["executor 1"] //task2的数据在executor 1这个executor上
task3:preferredLocations=["192.168.5.102"] //task3的数据在192.168.5.102这台机器上
那么5个集合的值为:
forExecutor:["executor 1"->[2]] //task2的preferredLocations为executor 1
forHost:["192.168.5.101"->[1],"192.168.5.102"->[3]] //task1的preferredLocations为"192.168.5.101",task3的preferredLocations为"192.168.5.102"
noPrefs:None
forRack:None
all:[1,2,3] //一共有三个task,task1,task2和task3
那么myLocalityLevels的值为:
myLocalityLevels = [PROCESS_LOCAL,NODE_LOCAL,ANY]
2.2 如何按照preferredLocations来分配Task
TaskScheduler为Executor分配Task时,会遍历myLocalityLevels,依次按照PROCESS_LOCAL、NODE_LOCAL、NO_PREF、RACK_LOCAL、Any的顺序来为Executor分配Task,如果某个Executor能找到符合当前TaskLocality的Task,那么就把这个Task分配给这个Executor。仍然以上面那个例子为例,TaskSetManager的5个集合以及myLocalityLevels为:
forExecutor:["executor 1"->[2]] //task2的preferredLocations为executor 1
forHost:["192.168.5.101"->[1],"192.168.5.102"->[3]] //task1的preferredLocations为"192.168.5.101",task3的preferredLocations为"192.168.5.102"
noPrefs:None
forRack:None
all:[1,2,3] //一共有三个task,task1,task2和task3
myLocalityLevels = [PROCESS_LOCAL,NODE_LOCAL,ANY]
Executor及其所在的及其的hostname为:
"executor 1" -> "192.168.5.101"
"executor 2" -> "192.168.5.102"
"executor 3" -> "192.168.5.103"
- 当前TaskLocality为PROCESS_LOCAL,遍历所有的Executor,发现 “executor 1” 在forExecutor的keySet中,并且对应的value为[2],因此将task2分配为“executor 1”
- 当前TaskLocality为NODE_LOCAL,遍历所有的Executor,发现 “executor 1” 所在的host为 “192.168.5.101”,且 “192.168.5.101” 在forHost的keySet中,对应的value为[1],因此将task1分配给“executor 1”;发现"executor 2" 所在的host为 “192.168.5.102”,且 “192.168.5.102” 在forHost的keySet中,对应的value为[3],因此将task3分配给“executor 2”
- 当前TaskLocality为ANY,但所有Task都已经分配完了,因此不进行分配
- 分配结束
用伪码表示这个过程:
for currentLocality <- taskSetManager.myLocalityLevels:
for executor <- allExecutors:
if executor in currentLocality对应的集合:
task = 集合中executor对应的value
if task未分配:
将task分配给executor
2.3 一个小坑
在Standalone模式下,如果Task的数据源是HDFS,那么Task在计算他的preferredLocations时,计算出的是这个Task的数据所在机器的hostname,例如,task1的数据在HDFS集群的192.168.5.101这个节点上有一个副本,而192.168.5.101这台服务器的hostname为“hadoop1”那么他的preferredLocations为:
preferredLocations=["hadoop1"]
然而,Spark计算某个Executor所在的节点时,默认情况下使用的是这个节点的IP地址,如果executor 1所在的host为192.168.5.101,那么在遍历forHost集合时,会认为“192.168.5.101”不在forHost的keySet中(因为forHost的keySet保存的是服务器的hostname,而不是ip地址),而实际上“192.168.5.101”和"hadoop1"是同一台服务器,因此在按照TaskLocality分配Task的过程中,可能不会正确地将task1分配给executor 1。
那么怎么解决这个问题呢?只需要在每个节点的spark-env.sh配置文件中显示地指定这个节点的hostname:
export SPARK_LOCAL_HOSTNAME=*hostname of this node*
注意,这个坑只在Standalone模式下才会出现,yarn模式下是不会出现的。