文章目录
本文内容为 同济子豪兄图像分类系列视频的学习笔记, 项目参考代码
前言
人工智能黑箱子灵魂之问
- Al的脑回路是怎样的? Al如何做出决策?是否符合人类的直觉和常识?
- Al会重点关注哪些特征,这些特征是不是真的有用?
- 如何衡量不同特征对Al预测结果的不同贡献?
- Al什么时候work,什么时候不work ?
- AI有没有过拟合?泛化能力如何?
- 会不会被黑客误导,让AI指鹿为马?
- 如果样本的某个特征变大15,会对Al预测结果产生什么影响?
- 如果Al误判,为什么会犯错?如何能不犯错?
- 两个AI预测结果不同,该信哪一-个?
- 能让AI把学到的特征教给人类吗?
可解释性就是希望寻求对模型工作机理的直接理解,打破人工智能的黑盒子。常见的可解释性分析算法有CAM系列算法、Lime算法、DFF算法等。本文将会先粗略的介绍部分算法的大致框架,然后利用现有的可解释性机器学习库(torch-cam、captum、lime等工具包)进行代码实战。
理论简介
CAM算法
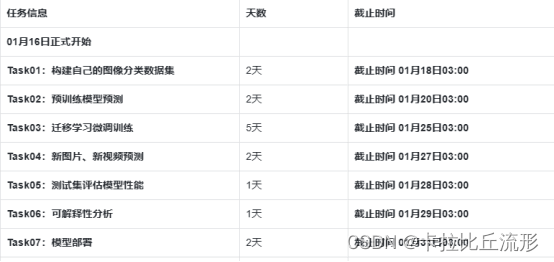
CAM算法奠定了可解释分析的基石,它的大致框架如下:
- 输入原始图像,经过多层无池化的全卷积神经网络处理得到最后一层512个14×14的channel
- 使用GAP对512个channel分别求平均值,得到512个平均数
- 最后经过一个线性分类层得到每个类别对这512个平均数的权重 w i , i = 1 , 2...512 w_i,i=1,2...512 wi,i=1,2...512(相当于有512个关注区域,平均数的大小反映了不同区域的重要程度);对每个类别的线性分类分数进行softmax操作得到,将置信度最高的类别作为预测的类别
- 对每个channel进行线性组合得到最终的类别激活热力图,将这个14×14的矩阵以双线性插值的方式缩放回原图大小
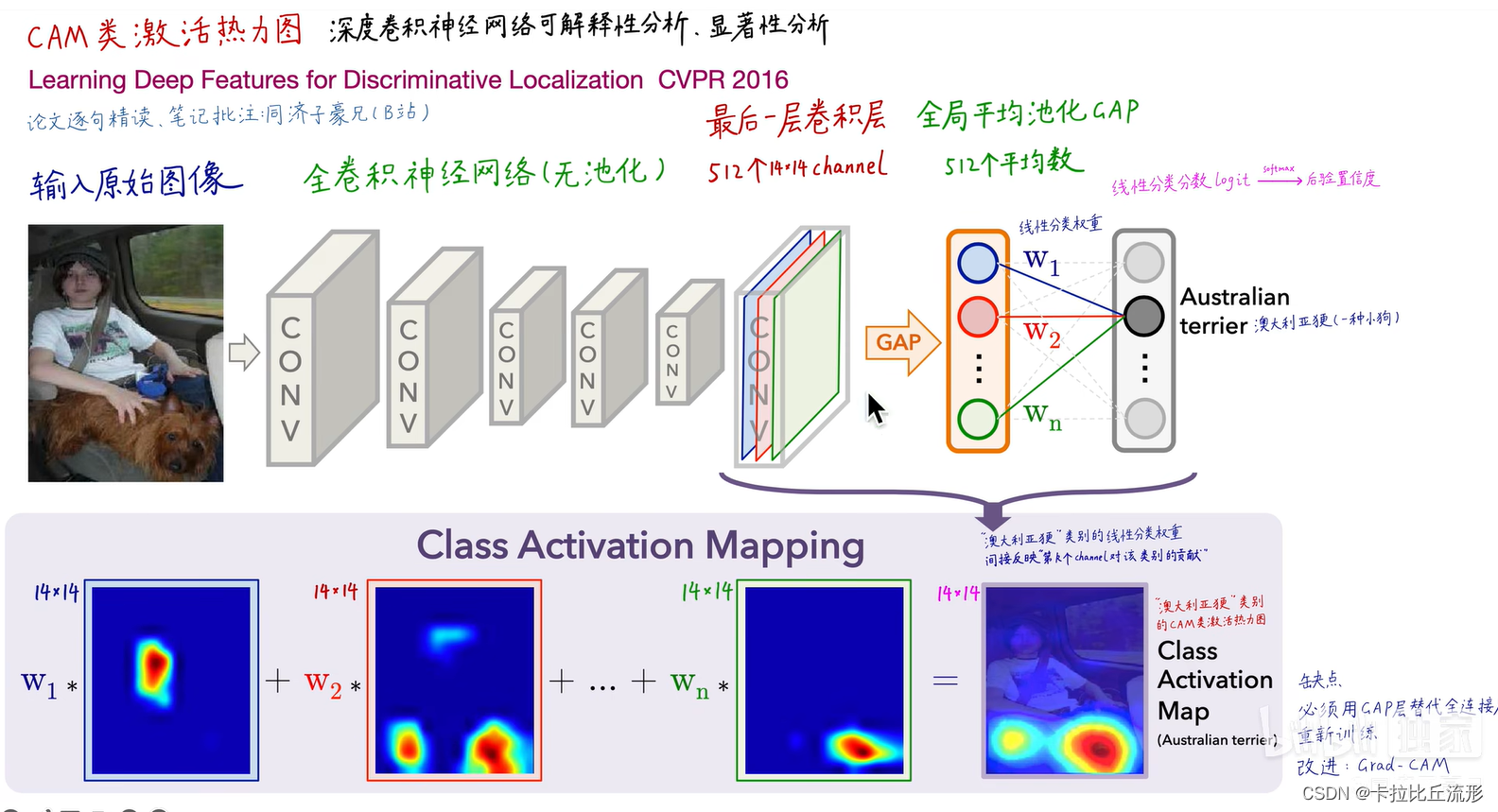
后面很多工作都是CAM算法的改进,如下图所示:
Lime算法
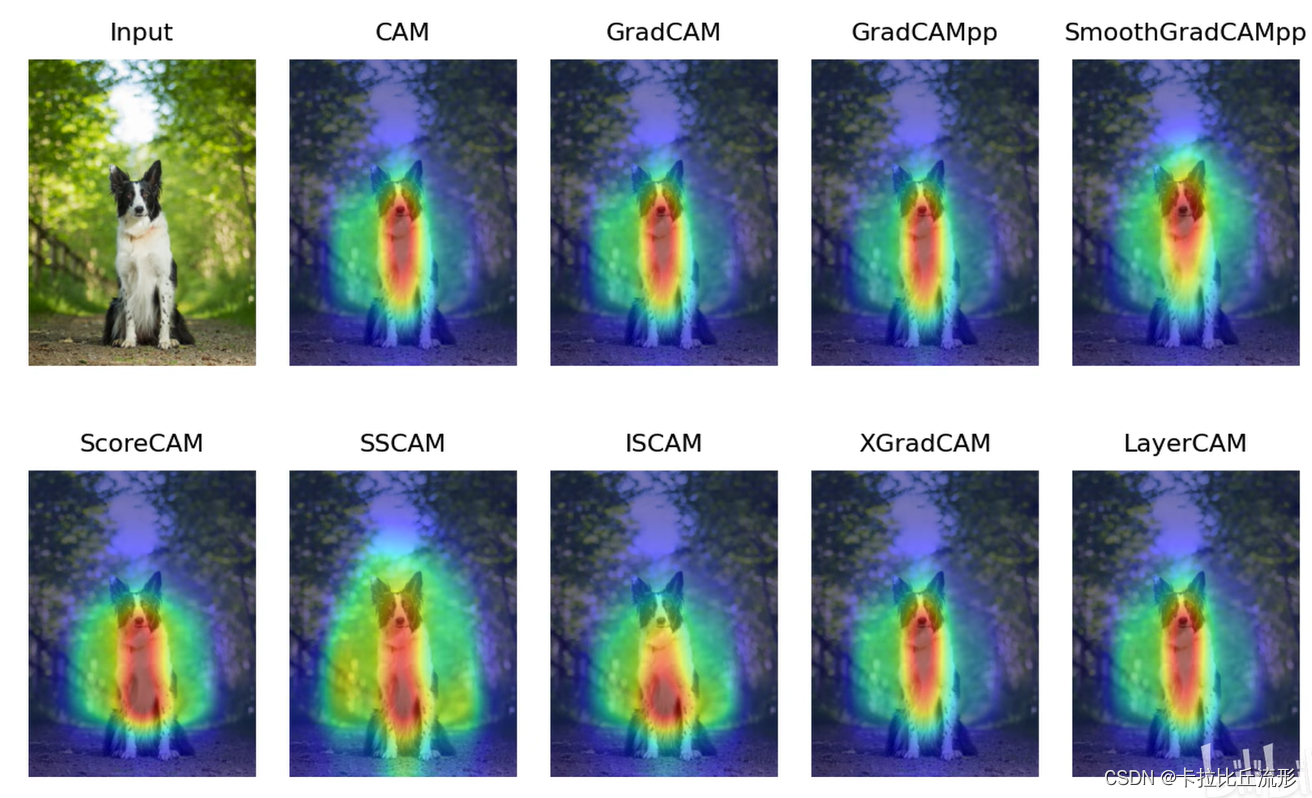
选取待测空间中的一个样本————>生成出离它很久的邻域数据————>离它近的点权重比较高,选的点权重比较低————>将生成的邻域样本输入到模型中获取邻域样本的预测结果————>选择一个可解释的模型(线性模型)————>用邻域样本的特征和它在原模型中的预测结果去训练出一个简单的线性模型,这个线性模型在局部邻域可以拟合出原模型的行为,拟合的权重可以反映特征的重要性
DFF算法
DFF算法可以找到


W反映了概念的特征表示,H反映了了概念和像素之间的关系(即不同类别对应不同颜色),进而我们可以得到像素的特征表示,从而得到像素对应某一个概念的贡献(同一类别颜色的深浅)。
代码实战
基本环境的配置在前面的文章中已经多次介绍过了,在这里就省略了,环境配置可以参考项目参考代码,这里利用torch-cam、pytorch-gradcam、captum、shap、lime工具包进行可解释性分析实战
torch-cam工具包实战
使用自己训练的水果分类模型,利用torch-cam工具包对单张水果图片进行基于CAM的可解释性分析。
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
from PIL import Image
import torch
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device', device)
# windows操作系统
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
#导入自己训练的水果分类模型
model = torch.load('checkpoint/fruit30_pytorch_20230123.pth')
model = model.eval().to(device)
# 测试集图像预处理-RCTN:缩放、裁剪、转 Tensor、归一化
from torchvision import transforms
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
导入可解释性分析方法,这里我们使用的是GradCAMpp算法,除此之外我们还可以使用CAM、GradCAM、GradCAMpp、ISCAM、LayerCAM、SSCAM、ScoreCAM、SmoothGradCAMpp、XGradCAM

from torchcam.methods import GradCAMpp
# CAM GradCAM GradCAMpp ISCAM LayerCAM SSCAM ScoreCAM SmoothGradCAMpp XGradCAM
cam_extractor = GradCAMpp(model)
from torchcam.utils import overlay_mask
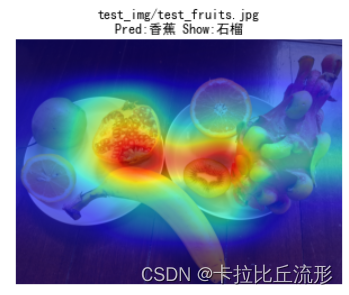
img_path = 'test_img/test_fruits.jpg'
#载入类别名称和索引号映射字典
idx_to_labels = np.load('idx_to_labels.npy', allow_pickle=True).item()
labels_to_idx = np.load('labels_to_idx.npy', allow_pickle=True).item()
# 可视化热力图的类别,如果不指定,则为置信度最高的预测类别
show_class = "石榴" #我们可以指定画面中任意一种水果
# 前向预测
img_pil = Image.open(img_path)
input_tensor = test_transform(img_pil).unsqueeze(0).to(device) # 预处理
pred_logits = model(input_tensor)
pred_id = torch.topk(pred_logits, 1)[1].detach().cpu().numpy().squeeze().item()
if show_class:
class_id = labels_to_idx[show_class]
show_id = class_id
else:
show_id = pred_id
# 获取热力图
activation_map = cam_extractor(show_id, pred_logits)
activation_map = activation_map[0][0].detach().cpu().numpy()
result = overlay_mask(img_pil, Image.fromarray(activation_map), alpha=0.4)
plt.imshow(result)
plt.axis('off')
plt.title('{}\nPred:{} Show:{}'.format(img_path, idx_to_labels[pred_id], show_class))
plt.show()
pytorch-gradcam工具包实战
对单张图像,进行Deep Feature Factorization可解释性分析,展示Concept Discovery概念发现图
import warnings
warnings.filterwarnings('ignore')
import requests
from PIL import Image
import numpy as np
import pandas as pd
import cv2
import json
import matplotlib.pyplot as plt
%matplotlib inline
from pytorch_grad_cam import DeepFeatureFactorization
from pytorch_grad_cam.utils.image import show_cam_on_image, preprocess_image, deprocess_image
from pytorch_grad_cam import GradCAM
from torchvision.models import resnet50
import torch
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
device = 'cpu'
print('device', device)
预处理函数
# 测试集图像预处理-RCTN:缩放、裁剪、转 Tensor、归一化
from torchvision import transforms
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
def get_image_from_path(img_path):
'''
输入图像文件路径,输出 图像array、归一化图像array、预处理后的tensor
'''
img = np.array(Image.open(img_path))
rgb_img_float = np.float32(img) / 255
input_tensor = preprocess_image(rgb_img_float,
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
return img, rgb_img_float, input_tensor
def create_labels(concept_scores, top_k=2):
""" Create a list with the image-net category names of the top scoring categories"""
labels = {
0:'Hami Melon',
1:'Cherry Tomatoes',
2:'Shanzhu',
3:'Bayberry',
4:'Grapefruit',
5:'Lemon',
6:'Longan',
7:'Pears',
8:'Coconut',
9:'Durian',
10:'Dragon Fruit',
11:'Kiwi',
12:'Pomegranate',
13:'Sugar orange',
14:'Carrots',
15:'Navel orange',
16:'Mango',
17:'Balsam pear',
18:'Apple Red',
19:'Apple Green',
20:'Strawberries',
21:'Litchi',
22:'Pineapple',
23:'Grape White',
24:'Grape Red',
25:'Watermelon',
26:'Tomato',
27:'Cherts',
28:'Banana',
29:'Cucumber'
}
concept_categories = np.argsort(concept_scores, axis=1)[:, ::-1][:, :top_k]
concept_labels_topk = []
for concept_index in range(concept_categories.shape[0]):
categories = concept_categories[concept_index, :]
concept_labels = []
for category in categories:
score = concept_scores[concept_index, category]
label = f"{
labels[category].split(',')[0]}:{
score:.2f}"
concept_labels.append(label)
concept_labels_topk.append("\n".join(concept_labels))
return concept_labels_topk
载入模型
model = torch.load('checkpoint/fruit30_pytorch_20230123.pth')
model = model.eval().to(device)
封装函数
classifier = model.fc
# concept个数(图块颜色个数)
n_components = 5
# 每个概念展示几个类别
top_k = 2
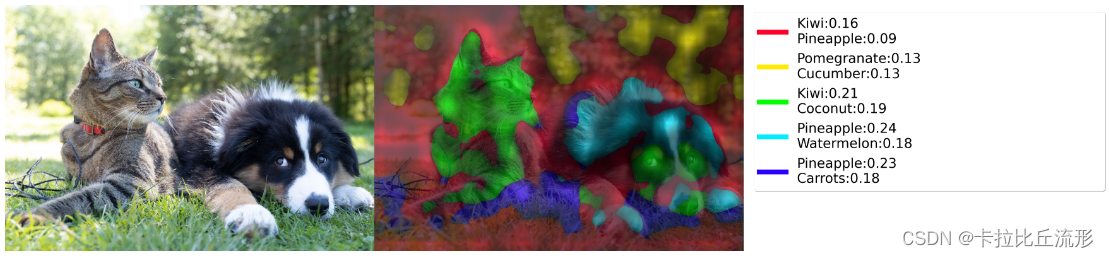
def dff_show(img_path='test_img/cat_dog.jpg', n_components=5, top_k=2, hstack=False):
img, rgb_img_float, input_tensor = get_image_from_path(img_path)
dff = DeepFeatureFactorization(model=model,
target_layer=model.layer4,
computation_on_concepts=classifier)
concepts, batch_explanations, concept_outputs = dff(input_tensor, n_components)#初始化DFF算法
concept_outputs = torch.softmax(torch.from_numpy(concept_outputs), axis=-1).numpy()#concept与类别的关系
concept_label_strings = create_labels(concept_outputs, top_k=top_k)#每个concept展示前top_k个类别
#生成可视化效果
visualization = show_factorization_on_image(rgb_img_float,
batch_explanations[0],
image_weight=0.3, # 原始图像透明度
concept_labels=concept_label_strings)
if hstack:#是否将原始图像和之前的图像并排显示
result = np.hstack((img, visualization))
else:
result = visualization
display(Image.fromarray(result))
dff_show(hstack=True)
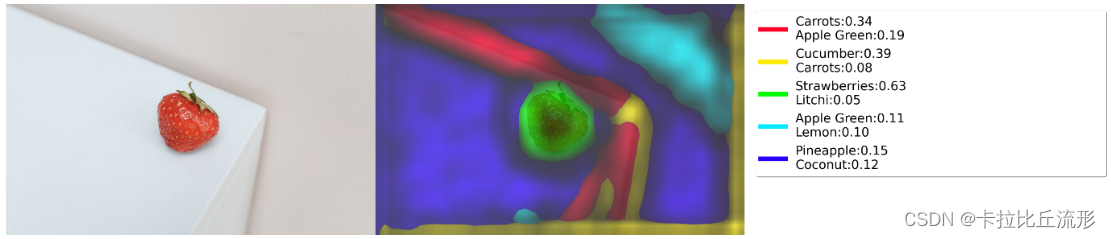
dff_show(img_path='test_img/test_草莓.jpg', hstack=True)
captum工具包实战
用小滑块,滑动遮挡图像上的不同区域,观察哪些区域被遮挡后会显著影响模型的分类决策。
import os
import json
import numpy as np
import pandas as pd
from PIL import Image
import torch
import torch.nn.functional as F
import torchvision
from torchvision import models
from torchvision import transforms
# from captum.attr import IntegratedGradients
# from captum.attr import GradientShap
from captum.attr import Occlusion
# from captum.attr import NoiseTunnel
from captum.attr import visualization as viz
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
%matplotlib inline
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device', device)
#载入预训练ResNet模型
model = models.resnet18(pretrained=True)
model = model.eval().to(device)
#载入ImageNet 1000图像分类标签
import pandas as pd
df = pd.read_csv('imagenet_class_index.csv')
idx_to_labels = {
}
idx_to_labels_cn = {
}
for idx, row in df.iterrows():
idx_to_labels[row['ID']] = row['class']
idx_to_labels_cn[row['ID']] = row['Chinese']
#图像预处理
from torchvision import transforms
# 缩放、裁剪、转 Tensor、归一化
transform_A = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor()
])
transform_B = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
下面对新输入的图片进行预测
## 预处理
#缩放、裁剪
rc_img = transform_A(img_pil)
# 调整数据维度
rc_img_norm = np.transpose(rc_img.squeeze().cpu().detach().numpy(), (1,2,0))
# 色彩归一化
input_tensor = transform_B(rc_img).unsqueeze(0).to(device)
##前向预测
pred_logits = model(input_tensor)
pred_softmax = F.softmax(pred_logits, dim=1) # 对 logit 分数做 softmax 运算
#预测的置信度
pred_conf, pred_id = torch.topk(pred_softmax, 1)
pred_conf = pred_conf.detach().cpu().numpy().squeeze().item()
#预测的id
pred_id = pred_id.detach().cpu().numpy().squeeze().item()
#预测的标签
pred_label = idx_to_labels[pred_id]
下面利用遮挡实验进行可解释性分析,在输入图像上,用遮挡滑块,滑动遮挡不同区域,探索哪些区域被遮挡后会显著影响模型的分类决策,我们经常修改滑块的大小sliding_window_shapes和步长strides来进行测试
# 获得输入图像每个像素的 occ 值
attributions_occ = occlusion.attribute(input_tensor,
strides = (3, 8, 8), # 遮挡滑动移动步长
target=pred_id, # 目标类别
sliding_window_shapes=(3, 15, 15), # 遮挡滑块尺寸
baselines=0) # 被遮挡滑块覆盖的像素值
# 转为 224 x 224 x 3的数据维度
attributions_occ_norm = np.transpose(attributions_occ.detach().cpu().squeeze().numpy(), (1,2,0))
viz.visualize_image_attr_multiple(attributions_occ_norm, # 224 224 3
rc_img_norm, # 224 224 3
["original_image", "heat_map"],
["all", "positive"],
show_colorbar=True,
outlier_perc=2)
plt.show()
shap工具包实战
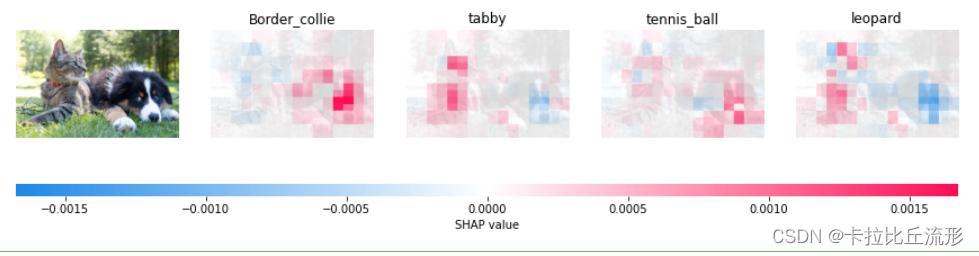
对Pytorch模型库中的ImageNet预训练图像分类模型进行可解释性分析。可视化指定预测类别的shap值热力图。
import json
import numpy as np
from PIL import Image
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms
import shap
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device', device)
#载入ImageNet1000类别标注名称
with open('data/imagenet_class_index.json') as file:
class_names = [v[1] for v in json.load(file).values()]
#载入一张测试图像,整理维度
img_path = 'test_img/cat_dog.jpg'
img_pil = Image.open(img_path)
X = torch.Tensor(np.array(img_pil)).unsqueeze(0)
#预处理
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
def nhwc_to_nchw(x: torch.Tensor) -> torch.Tensor:
if x.dim() == 4:
x = x if x.shape[1] == 3 else x.permute(0, 3, 1, 2)
elif x.dim() == 3:
x = x if x.shape[0] == 3 else x.permute(2, 0, 1)
return x
def nchw_to_nhwc(x: torch.Tensor) -> torch.Tensor:
if x.dim() == 4:
x = x if x.shape[3] == 3 else x.permute(0, 2, 3, 1)
elif x.dim() == 3:
x = x if x.shape[2] == 3 else x.permute(1, 2, 0)
return x
transform= [
transforms.Lambda(nhwc_to_nchw),
transforms.Resize(224),
transforms.Lambda(lambda x: x*(1/255)),
transforms.Normalize(mean=mean, std=std),
transforms.Lambda(nchw_to_nhwc),
]
inv_transform= [
transforms.Lambda(nhwc_to_nchw),
transforms.Normalize(
mean = (-1 * np.array(mean) / np.array(std)).tolist(),
std = (1 / np.array(std)).tolist()
),
transforms.Lambda(nchw_to_nhwc),
]
transform = torchvision.transforms.Compose(transform)
inv_transform = torchvision.transforms.Compose(inv_transform)
#构建模型预测函数
def predict(img: np.ndarray) -> torch.Tensor:
img = nhwc_to_nchw(torch.Tensor(img)).to(device)
output = model(img)
return output
def predict(img):
img = nhwc_to_nchw(torch.Tensor(img)).to(device)
output = model(img)
return output
设置shap可解释性分析算法
Xtr = transform(X)#预处理
out = predict(Xtr[0:1])
classes = torch.argmax(out, axis=1).detach().cpu().numpy()
# 构造输入图像
input_img = Xtr[0].unsqueeze(0)
batch_size = 50
n_evals = 5000 # 迭代次数越大,显著性分析粒度越精细,计算消耗时间越长
# 定义 mask,遮盖输入图像上的局部区域
masker_blur = shap.maskers.Image("blur(64, 64)", Xtr[0].shape)
# 创建可解释分析算法
explainer = shap.Explainer(predict, masker_blur, output_names=class_names)
指定多个预测类别
# 232 边牧犬 border collie
# 281:虎斑猫 tabby
# 852 网球 tennis ball
# 288 豹子 leopard
shap_values = explainer(input_img, max_evals=n_evals, batch_size=batch_size, outputs=[232, 281, 852, 288])
# 整理张量维度
shap_values.data = inv_transform(shap_values.data).cpu().numpy()[0] # 原图
shap_values.values = [val for val in np.moveaxis(shap_values.values[0],-1, 0)] # shap值热力图
# 可视化
shap.image_plot(shap_values=shap_values.values,
pixel_values=shap_values.data,
labels=shap_values.output_names)
lime工具包实战
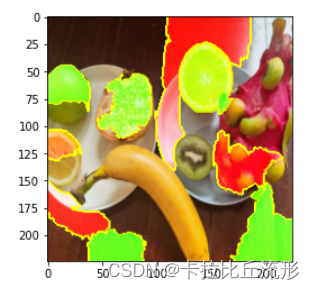
对自己训练得到的30类水果图像分类模型,运行LIME可解释性分析。可视化某个输入图像,某个图块区域,对模型预测为某个类别的贡献影响。
import matplotlib.pyplot as plt
from PIL import Image
import torch.nn as nn
import numpy as np
import os, json
import torch
from torchvision import models, transforms
from torch.autograd import Variable
import torch.nn.functional as F
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device', device)
#载入测试图片
img_path = 'test_img/test_fruits.jpg'
img_pil = Image.open(img_path)
#载入模型
model = torch.load('checkpoint/fruit30_pytorch_20230123.pth')
model = model.eval().to(device)
idx_to_labels = np.load('idx_to_labels.npy', allow_pickle=True).item()
#预处理
trans_norm = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
trans_A = transforms.Compose([
transforms.Resize((256, 256)),
transforms.CenterCrop(224),
transforms.ToTensor(),
trans_norm
])
trans_B = transforms.Compose([
transforms.ToTensor(),
trans_norm
])
trans_C = transforms.Compose([
transforms.Resize((256, 256)),
transforms.CenterCrop(224)
])
对原始图像进行分类预测,得到置信度最高的五种水果的id
input_tensor = trans_A(img_pil).unsqueeze(0).to(device)
pred_logits = model(input_tensor)
pred_softmax = F.softmax(pred_logits, dim=1)
top_n = pred_softmax.topk(5)
top_n
torch.return_types.topk(
values=tensor([[0.4603, 0.2951, 0.0648, 0.0620, 0.0259]], grad_fn=),
indices=tensor([[16, 28, 1, 0, 4]]))
定义分类预测函数并进行LIME可解释性分析
def batch_predict(images):
batch = torch.stack(tuple(trans_B(i) for i in images), dim=0)
batch = batch.to(device)
logits = model(batch)
probs = F.softmax(logits, dim=1)
return probs.detach().cpu().numpy()
#LIME可解释性分析
from lime import lime_image
explainer = lime_image.LimeImageExplainer()
explanation = explainer.explain_instance(np.array(trans_C(img_pil)),
batch_predict, # 分类预测函数
top_labels=len(idx_to_labels),
hide_color=0,
num_samples=3000) # LIME生成的邻域图像个数
对预测最高的类别进行可视化
from skimage.segmentation import mark_boundaries
temp, mask = explanation.get_image_and_mask(explanation.top_labels[16], positive_only=False, num_features=11, hide_rest=False)
img_boundry = mark_boundaries(temp/255.0, mask)
plt.imshow(img_boundry)
plt.show()
总结
本文简要的介绍了一下CAM算法、LIME算法和DFF算法,之后实战部分利用torch-cam、pytorch-gradcam、captum、shap、lime工具包对模型可解释性分析,通过可解释性分析我们能够知道哪部分区域对预测结果比较重要,哪部分区域对预测结果产生正向影响,哪部分产生负面影响。通过可解释性分析我们可以在一定程度上找到模型预测出错的原因,例如在lime实战中,预测概率最大的一类是芒果,但是图片中并没有芒果,通过观察可解释性分析结果可以发现颜色对模型预测的干扰比较大,之后我们就可以朝这个方向改进模型了。
参考资料
LIME机器学习可解释性分析
CAM可解释性分析-算法讲解
Deep Feature Factorizations for better model explainability