AudioTrack之数据传递
简介
接上一篇AudioTrack播放音频之建立通道找到了通道的唯一句柄值output,这个output实质就是在AudioFlinger创建PlaybackThread后,以key-value形式上保存(output, PlaybackThread)的key值,通过output就可以找到播放音频将从哪个PlaybackThread线程传递数据,这个线程相当于一个中间角色,应用层进程将音频数据以匿名共享内存方式传递给PlaybackThread,而PlaybackThread也是以匿名共享内存方式传递数据给HAL层;其实也能理解,跨进程传递大数据,效率高一点的就是共享内存了;
这里用PlaybackThread泛指所有的回拨线程,但是实际的线程有可能是MixerThread、DirectOutputThread、OffloadThread等等线程,那这个output指向是哪个线程呢?一般来说是传递的音频参数Flag决定的
这里我们就需要知道应用层与AudioFlinger(PlaybackThread属于AudioFlinger模块)、AudioFinger与HAL之间的共享内存是如何建立以及数据在上面是如何传递的?
应用层与AudioFlinger的共享内存建立
AudioFlinger服务端模块创建匿名共享内存
创建共享内存时机位于AudioFlinger中,获取输出通道成功后,位于下图红色箭头指向的地方:

sp<IAudioTrack> AudioFlinger::createTrack(const CreateTrackInput& input,
CreateTrackOutput& output,
status_t *status)
{
.......
audio_attributes_t localAttr = input.attr;
//入参localAttr音频属性,从AudioPolicyService获取输出通道output句柄等信息
lStatus = AudioSystem::getOutputForAttr(&localAttr, &output.outputId, sessionId, &streamType,
clientPid, clientUid, &input.config, input.flags,
&output.selectedDeviceId, &portId, &secondaryOutputs);
........
{
Mutex::Autolock _l(mLock);
/** outputId是AudioPolicyService返回的,就是输出通道output句柄,
* 这个id其实一开始来源于AudioFlinger在打开HAL层的device时创建的
* PlaybackThread线程,key-value形式保存在AudioFlinger的
* mPlaybackThreads成员中,这里就是从成员中找到对应的PlaybackThread
* */
PlaybackThread *thread = checkPlaybackThread_l(output.outputId);
if (thread == NULL) {
ALOGE("no playback thread found for output handle %d", output.outputId);
lStatus = BAD_VALUE;
goto Exit;
}
/** clientPid是应用层那边的,这里注册也就是用一个Client类保存客户端信息
* ,并保存在AudioFlinger的集合成员mClients内
* */
client = registerPid(clientPid);
//保存音频属性
output.sampleRate = input.config.sample_rate;
output.frameCount = input.frameCount;
output.notificationFrameCount = input.notificationFrameCount;
output.flags = input.flags;
/** 在AudioFlinger端创建一个Track,对应应用层端的AudioTrack,一一对应的
* ,共享内存也是在这里面的逻辑完成的
* */
track = thread->createTrack_l(client, streamType, localAttr, &output.sampleRate,
input.config.format, input.config.channel_mask,
&output.frameCount, &output.notificationFrameCount,
input.notificationsPerBuffer, input.speed,
input.sharedBuffer, sessionId, &output.flags,
callingPid, input.clientInfo.clientTid, clientUid,
&lStatus, portId);
LOG_ALWAYS_FATAL_IF((lStatus == NO_ERROR) && (track == 0));
// we don't abort yet if lStatus != NO_ERROR; there is still work to be done regardless
output.afFrameCount = thread->frameCount();
output.afSampleRate = thread->sampleRate();
output.afLatencyMs = thread->latency();
output.portId = portId;
}
.......
//TrackHandler包裹内部Track,返回给AudioTrack客户端,这个Track是通过Binder通信的
trackHandle = new TrackHandle(track);
//错误失败情况下回释放资源
Exit:
if (lStatus != NO_ERROR && output.outputId != AUDIO_IO_HANDLE_NONE) {
AudioSystem::releaseOutput(portId);
}
*status = lStatus;
return trackHandle;
}
从上面函数可以得出,获取输出通道后output句柄后,会找到其对应PlaybackThread线程,在用这个线程创建一个Track,此Track与应用层的AudioTrack一一对应,他们之间可通过binder IPC方式访问,PlaybackThread在创建Track的同时会完成匿名共享内存的创建与分配使用,可以说Track管理者共享内存;其内部逻辑相对复杂,我们先列一个流程图,讲解其中的关键点即可:

上图在TrackBase构造函数中,使用了参数client来完成创建共享内存,client在AudioFlinger中创建的,保存了应用端的信息
从上图可以看出,流程的最后使用匿名共享内存方式来传递音频数据,匿名共享内存大致原理是:在tmpfs文件系统上创建的文件绑定到虚拟地址空间,而tmpfs文件系统存在于pageCache和swap缓存上,IO处理速度快,当mmap映射时触发实际的物理内存分配并映射到进程空间,这样进程就可以直接使用这块内存了;Android的匿名共享内存原理不是本文重点,如你感兴趣可点击查阅匿名共享内存原理、共享内存和文件内存映射的区别这里我们关注创建的流程以及创建共享内存后返回的是什么,以及如何去使用?
我们看看MemoryHeapBase中如何创建共享内存的,在它的构造方法中:
MemoryHeapBase::MemoryHeapBase(size_t size, uint32_t flags, char const * name)
: mFD(-1), mSize(0), mBase(MAP_FAILED), mFlags(flags),
mDevice(nullptr), mNeedUnmap(false), mOffset(0)
{
const size_t pagesize = getpagesize();
size = ((size + pagesize-1) & ~(pagesize-1));
//在tmpfs临时文件系统上创建匿名共享内存
int fd = ashmem_create_region(name == nullptr ? "MemoryHeapBase" : name, size);
ALOGE_IF(fd<0, "error creating ashmem region: %s", strerror(errno));
if (fd >= 0) {
//映射共享内存到当前进程空间,方便操作
if (mapfd(fd, size) == NO_ERROR) {
if (flags & READ_ONLY) {
ashmem_set_prot_region(fd, PROT_READ);
}
}
}
}
status_t MemoryHeapBase::mapfd(int fd, size_t size, off_t offset)
{
......
if ((mFlags & DONT_MAP_LOCALLY) == 0) {
//映射共享内存到本进程
void* base = (uint8_t*)mmap(nullptr, size,
PROT_READ|PROT_WRITE, MAP_SHARED, fd, offset);
if (base == MAP_FAILED) {
ALOGE("mmap(fd=%d, size=%zu) failed (%s)",
fd, size, strerror(errno));
close(fd);
return -errno;
}
//mBase是分配的地址
mBase = base;
mNeedUnmap = true;
} else {
mBase = nullptr; // not MAP_FAILED
mNeedUnmap = false;
}
mFD = fd; //共享内存的文件描述符
mSize = size; //内存大小
mOffset = offset; //偏移地址
return NO_ERROR;
}
上面代码是匿名共享内存分配过程,注意它分配完成后返回的两个参数mFd是文件描述符,mBase是映射的内存地址;这两个是如何被使用的?在TrackBase中可以查看到:
AudioFlinger::ThreadBase::TrackBase::TrackBase(
ThreadBase *thread,
const sp<Client>& client,
const audio_attributes_t& attr,
uint32_t sampleRate,
audio_format_t format,
audio_channel_mask_t channelMask,
size_t frameCount,
//static模式 buffer有值不为空
void *buffer,
size_t bufferSize,
audio_session_t sessionId,
pid_t creatorPid,
uid_t clientUid,
bool isOut,
alloc_type alloc,
track_type type,
audio_port_handle_t portId)
.......
{
//roundup向上取舍,为frameCount+1
size_t minBufferSize = buffer == NULL ? roundup(frameCount) : frameCount;
// check overflow when computing bufferSize due to multiplication by mFrameSize.
if (minBufferSize < frameCount // roundup rounds down for values above UINT_MAX / 2
|| mFrameSize == 0 // format needs to be correct
|| minBufferSize > SIZE_MAX / mFrameSize) {
android_errorWriteLog(0x534e4554, "34749571");
return;
}
//在乘一个每帧的大小
minBufferSize *= mFrameSize;
if (buffer == nullptr) {
bufferSize = minBufferSize; // allocated here.
//不允许设置的缓存区大小bufferSize比最小缓存区还小,会导致提供的数据过小
} else if (minBufferSize > bufferSize) {
android_errorWriteLog(0x534e4554, "38340117");
return;
}
//audio_track_cblk_t是一个结构体
size_t size = sizeof(audio_track_cblk_t);
if (buffer == NULL && alloc == ALLOC_CBLK) {
// check overflow when computing allocation size for streaming tracks.
//因为至少要分配一个audio_track_cblk_t结构体大小
if (size > SIZE_MAX - bufferSize) {
android_errorWriteLog(0x534e4554, "34749571");
return;
}
/** 总容量=mFrameSize * frameCount + sizeof(audio_track_cblk_t)
* frameCount来源于应用端传递,等于用户设置的缓存区大小/每帧数据大小
* */
size += bufferSize;
}
if (client != 0) {
/** 这个就是上面分配匿名共享内存的调用,它返回的是Allocation类型,
* 因为他对MemoryHeapBase做了一次包裹分装
* */
mCblkMemory = client->heap()->allocate(size);
if (mCblkMemory == 0 ||
//pointer函数返回的是MemoryHeapBase的mBase,也就是其实际映射的内存地址,然后
//在把其墙砖为audio_track_cblk_t类型,并赋值给mCblk成员
(mCblk = static_cast<audio_track_cblk_t *>(mCblkMemory->pointer())) == NULL) {
ALOGE("%s(%d): not enough memory for AudioTrack size=%zu", __func__, mId, size);
client->heap()->dump("AudioTrack");
mCblkMemory.clear();
return;
}
} else {
//如果找不到客户端client的话,就直接本地映射
mCblk = (audio_track_cblk_t *) malloc(size);
if (mCblk == NULL) {
ALOGE("%s(%d): not enough memory for AudioTrack size=%zu", __func__, mId, size);
return;
}
}
// construct the shared structure in-place.
if (mCblk != NULL) {
//赋值构造函数,但是初始值也是空
new(mCblk) audio_track_cblk_t();
switch (alloc) {
........
case ALLOC_CBLK:
//stream模式使用匿名共享内存
if (buffer == NULL) {
//mBuffer是共享内存映射地址的第1个,不是第0个
mBuffer = (char*)mCblk + sizeof(audio_track_cblk_t);
memset(mBuffer, 0, bufferSize);
} else {
//static模式就直接使用应用层传过来的buffer
mBuffer = buffer;
#if 0
mCblk->mFlags = CBLK_FORCEREADY; // FIXME hack, need to fix the track ready logic
#endif
}
break;
.......
}
}
}
从上面代码可以得出,在AudioFlinger模块,匿名共享内存创建是由MemoryHeapBase完成的,管理由Track和TrackBase来管理,内部成员mCblk成员是一个audio_track_cblk_t类型,是负责客户端和服务端的匿名共享内存使用调度的,相当重要,而真正传递数据的内存块在mBuffer成员负责,内存大小等于frameSize*frameCount+sizeof(audio_track_cblk_t),但是也要注意如果是static模式,mBuffer是应用端传过来的buffer,而不是使用前面创建的共享内存

匿名共享内存分配图如上,audio_track_cblk_t是用于同步处理client与server端的写入读取关系,buffer是真正用于数据读写的内存;可以理解mBuffer是一个缓行缓冲区,rear是写入的位置指针,front是读取的位置指针,每次写入都会从rear地址处写入,每次读取都会从front读取;但是每次写入时能写多少,读取时又能读多少呢?这个就由前面的audio_track_cblk来控制了
AudioFlinger服务端模块管理共享内存
在回到Track的构造函数中去,会有一个负责和应用程序端交互管理共享内存的类,如下:
AudioFlinger::PlaybackThread::Track::Track(
PlaybackThread *thread,
const sp<Client>& client,
audio_stream_type_t streamType,
const audio_attributes_t& attr,
uint32_t sampleRate,
audio_format_t format,
audio_channel_mask_t channelMask,
size_t frameCount,
void *buffer,
size_t bufferSize,
const sp<IMemory>& sharedBuffer,
audio_session_t sessionId,
pid_t creatorPid,
uid_t uid,
audio_output_flags_t flags,
track_type type,
audio_port_handle_t portId)
: TrackBase(thread, client, attr, sampleRate, format, channelMask, frameCount,
(sharedBuffer != 0) ? sharedBuffer->pointer() : buffer,
(sharedBuffer != 0) ? sharedBuffer->size() : bufferSize,
sessionId, creatorPid, uid, true /*isOut*/,
(type == TYPE_PATCH) ? ( buffer == NULL ? ALLOC_LOCAL : ALLOC_NONE) : ALLOC_CBLK,
type, portId)
{
//mCblk是在TrackBase中已经完成赋值,如果为空,说明共享内存分配失败了直接返回
if (mCblk == NULL) {
return;
}
//shareBuffer来源于应用程序端,0表示stream模式,非0是static模式
if (sharedBuffer == 0) {
//stream模式
mAudioTrackServerProxy = new AudioTrackServerProxy(mCblk, mBuffer, frameCount,
mFrameSize, !isExternalTrack(), sampleRate);
} else {
//static模式,注意这里的mBuffer实质就是应用端传递过来的内存地址
mAudioTrackServerProxy = new StaticAudioTrackServerProxy(mCblk, mBuffer, frameCount,
mFrameSize);
}
//这个mServerProxy就是与应用程序端交互共享内存、同步等
mServerProxy = mAudioTrackServerProxy;
......
}
以上重要的逻辑就是要记住mAudioTrackServerProxy,它负责管理与同步匿名共享内存的使用,IPC通信,应用端也会有一套ClientProxy对应,通过这个Proxy应用端和服务端使用obtainBuffer申请内存,控制写入读取等;到这里服务端AudioFlinger对于共享内存的工作也就做完了;stream模式下mBuffer等于服务端自己创建的匿名共享内存地址,而Static模式mBuffer来源于应用端传递过来的sharedBuffer
后面在PlaybackThread中还有一点重要工作要处理,如下:
sp<AudioFlinger::PlaybackThread::Track> AudioFlinger::PlaybackThread::createTrack_l(.....){
.......
track = new Track(this, client, streamType, attr, sampleRate, format,
channelMask, frameCount,
nullptr /* buffer */, (size_t)0 /* bufferSize */, sharedBuffer,
sessionId, creatorPid, uid, *flags, TrackBase::TYPE_DEFAULT, portId);
mTracks.add(track);
.......
return track;
}
sp<IAudioTrack> AudioFlinger::createTrack(const CreateTrackInput& input,
CreateTrackOutput& output,
status_t *status)
{
........
Track track = thread->createTrack_l(client, streamType, localAttr, &output.sampleRate,
input.config.format, input.config.channel_mask,
&output.frameCount, &output.notificationFrameCount,
input.notificationsPerBuffer, input.speed,
input.sharedBuffer, sessionId, &output.flags,
callingPid, input.clientInfo.clientTid, clientUid,
&lStatus, portId);
........
// return handle to client
trackHandle = new TrackHandle(track);
}
上面代码有两个关键点:
- PlaybackThread将track加入了自身的mTracks成员,它这么做得意义是什么,这点很重要?
- 对track做了一次包裹封装为TrackHandle,返回给应用层;那么应用层模块拿到TrackHandle如何处理?
应用层模块处理共享内存
应用层收到AudioFlinger服务端模块创建Track成功后,代码逻辑如下:
status_t AudioTrack::createTrack_l()
{
.......
IAudioFlinger::CreateTrackOutput output;
//返回的TrackHandler内包含了AudioFlinger的创建的Track,Track内则包含了各种
//portId\outPutId、session等,还有共享内存信息
sp<IAudioTrack> track = audioFlinger->createTrack(input,
output,
&status);
.......
//getCblk就是获取服务端TrackBase的mCblkMemory成员,共享内存的总管理
sp<IMemory> iMem = track->getCblk();
if (iMem == 0) {
ALOGE("%s(%d): Could not get control block", __func__, mPortId);
status = NO_INIT;
goto exit;
}
//这个pointer是分配内存映射的首地址,首地址是一个audio_track_cblk_t成员
void *iMemPointer = iMem->pointer();
if (iMemPointer == NULL) {
ALOGE("%s(%d): Could not get control block pointer", __func__, mPortId);
status = NO_INIT;
goto exit;
}
// mAudioTrack是之前与AudioFlinger服务端交互的TrackHandler,如果存在,则把之前的关系注销
if (mAudioTrack != 0) {
IInterface::asBinder(mAudioTrack)->unlinkToDeath(mDeathNotifier, this);
mDeathNotifier.clear();
}
//audioFlinger那边的创建成功的track,保存后续可以binder方式交互
mAudioTrack = track;
mCblkMemory = iMem;
IPCThreadState::self()->flushCommands();
//第一个字节强制转换成audio_track_cblk_t结构体,后面的则是实际映射地址
audio_track_cblk_t* cblk = static_cast<audio_track_cblk_t*>(iMemPointer);
mCblk = cblk;
.......
//buffer是实际的映射地址
void* buffers;
if (mSharedBuffer == 0) {
buffers = cblk + 1;
} else {
//static模式就直接用客户端的产生的地址
buffers = mSharedBuffer->pointer();
if (buffers == NULL) {
ALOGE("%s(%d): Could not get buffer pointer", __func__, mPortId);
status = NO_INIT;
goto exit;
}
}
mAudioTrack->attachAuxEffect(mAuxEffectId);
// If IAudioTrack is re-created, don't let the requested frameCount
// decrease. This can confuse clients that cache frameCount().
if (mFrameCount > mReqFrameCount) {
mReqFrameCount = mFrameCount;
}
// reset server position to 0 as we have new cblk.
mServer = 0;
// update proxy; stream模式往哪里写数据,就是这个mProxy内部的
/**
* mProxy是最终的代理proxy,数据内存;static模式是StaticAudioTrackClientProxy,
* buffers内存由app客户端提供;stream模式是AudioTrackClientProxy,内存buffer由audioFlinger提供
* */
if (mSharedBuffer == 0) {
mStaticProxy.clear();
mProxy = new AudioTrackClientProxy(cblk, buffers, mFrameCount, mFrameSize);
} else {
mStaticProxy = new StaticAudioTrackClientProxy(cblk, buffers, mFrameCount, mFrameSize);
mProxy = mStaticProxy;
}
.......
}
在应用层端,拿到服务端的TrackHandle后,主要工作从TrackHandle中取出共享内存管理结构体audio_track_cblk_t和实际的内存映射地址buffers,如果是static模式,就直接使用客户端创建的分配的内存地址mShareBuffer,最后客户端也对buffers、audio_track_cblk_t做了包裹封装为AudioTrackClientProxy,用于后续数据写入与内存的管理,最后应用层与AudioFlinger服务端用图总结如下:

上图需要注意的是,clientProxy与ServerProxy之间通信方式是Binder通信IPC,他们通信的内容就是匿名共享内存的信息,怎么写入,写入到哪个地方等;音频数据读写走的是下面的匿名共享内存buffer;
static模式其sharedBuffer是什么?也是匿名共享内存吗?
答案:是的,印证这个答案就要去应用端static模式下创建sharedBuffer逻辑处,位于应用端创建AudioTrack时,在android_media_AudioTrack.cpp的android_media_AudioTrack_setup函数下:
static jint
android_media_AudioTrack_setup(){
......
switch (memoryMode) {
case MODE_STREAM:
......
case MODE_STATIC:
//static模式是客户端应用程序自身创建内存
if (!lpJniStorage->allocSharedMem(buffSizeInBytes)) {
ALOGE("Error creating AudioTrack in static mode: error creating mem heap base");
goto native_init_failure;
}
......
}
bool allocSharedMem(int sizeInBytes) {
mMemHeap = new MemoryHeapBase(sizeInBytes, 0, "AudioTrack Heap Base");
if (mMemHeap->getHeapID() < 0) {
return false;
}
mMemBase = new MemoryBase(mMemHeap, 0, sizeInBytes);
return true;
}
是不是很熟悉mMemHeap,它是一个MemoryHeapBase类,也就是负责创建匿名共享内存的;所以无论是stream还是static模式,AudioFlinger和应用端之间的音频数据传递都是共享内存,区别就是创建者不一样,分配的大小不一样。
应用层写入数据到AudioFlinger服务端模块
这里以stream模式写数据进行讲解,static模式大同小异,都是共享内存传递的方式,stream模式的数据写入逻辑大致如下图:
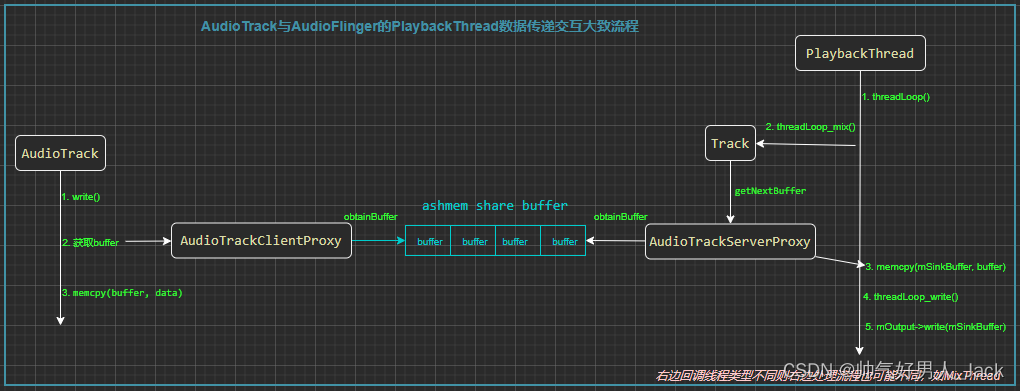
上图没有涉及应用层java到native上图部分,只显示从native的AudioTrack到AudioFlinger的数据传递部分,也是我们需要关注的部分;这部分代码逻辑相对复杂,有了上面的精炼图,只需要共享内存的两端,如何写入,如何读出?
应用层写入
位于AudioTrack的write函数中:
ssize_t AudioTrack::write(const void* buffer, size_t userSize, bool blocking)
{
if (mTransfer != TRANSFER_SYNC && mTransfer != TRANSFER_SYNC_NOTIF_CALLBACK) {
return INVALID_OPERATION;
}
.......
size_t written = 0;
Buffer audioBuffer;
while (userSize >= mFrameSize) {
audioBuffer.frameCount = userSize / mFrameSize;
//从共享内存中获取内存buffer
status_t err = obtainBuffer(&audioBuffer,
blocking ? &ClientProxy::kForever : &ClientProxy::kNonBlocking);
if (err < 0) {
if (written > 0) {
break;
}
if (err == TIMED_OUT || err == -EINTR) {
err = WOULD_BLOCK;
}
return ssize_t(err);
}
size_t toWrite = audioBuffer.size;
//拷贝音频数据到audioBuffer
memcpy(audioBuffer.i8, buffer, toWrite);
buffer = ((const char *) buffer) + toWrite;
userSize -= toWrite;
written += toWrite;
releaseBuffer(&audioBuffer);
}
if (written > 0) {
mFramesWritten += written / mFrameSize;
if (mTransfer == TRANSFER_SYNC_NOTIF_CALLBACK) {
//t为回调线程,回调给java上层应用层
const sp<AudioTrackThread> t = mAudioTrackThread;
if (t != 0) {
t->wake();
}
}
}
return written;
}
以上主要就是向共享内存先obtain申请空闲内存,然后memcpy写入数据,然后AudioFlinger那端就会进行读取操作;上面函数的obtainBuffer最终会执行到ClientProxy的obtainBuffer中去,我们进去看看:
status_t ClientProxy::obtainBuffer(Buffer* buffer, const struct timespec *requested,
struct timespec *elapsed)
{
.......
// compute number of frames available to write (AudioTrack) or read (AudioRecord)
int32_t front; //front是读取指针 rear是写入指针
int32_t rear;
//mIsOut标致着是写入数据
if (mIsOut) {
//为了使写入数据能尽可能成功,所以要尽可能知道最新能写入的空间有多少,
//所以读取最新的mFront指针,看服务端读取了多少数据
// The barrier following the read of mFront is probably redundant.
// We're about to perform a conditional branch based on 'filled',
// which will force the processor to observe the read of mFront
// prior to allowing data writes starting at mRaw.
// However, the processor may support speculative execution,
// and be unable to undo speculative writes into shared memory.
// The barrier will prevent such speculative execution.
front = android_atomic_acquire_load(&cblk->u.mStreaming.mFront);
rear = cblk->u.mStreaming.mRear;
} else {
// On the other hand, this barrier is required.
rear = android_atomic_acquire_load(&cblk->u.mStreaming.mRear);
front = cblk->u.mStreaming.mFront;
}
// write to rear, read from front计算已有的数据占用的空间
ssize_t filled = audio_utils::safe_sub_overflow(rear, front);
// pipe should not be overfull
if (!(0 <= filled && (size_t) filled <= mFrameCount)) {
if (mIsOut) {
ALOGE("Shared memory control block is corrupt (filled=%zd, mFrameCount=%zu); "
"shutting down", filled, mFrameCount);
mIsShutdown = true;
status = NO_INIT;
goto end;
}
// for input, sync up on overrun
filled = 0;
cblk->u.mStreaming.mFront = rear;
(void) android_atomic_or(CBLK_OVERRUN, &cblk->mFlags);
}
// Don't allow filling pipe beyond the user settable size.
// The calculation for avail can go negative if the buffer size
// is suddenly dropped below the amount already in the buffer.
// So use a signed calculation to prevent a numeric overflow abort.
ssize_t adjustableSize = (ssize_t) getBufferSizeInFrames();
//avail表示空闲内存的大小
ssize_t avail = (mIsOut) ? adjustableSize - filled : filled;
if (avail < 0) {
avail = 0;
} else if (avail > 0) {
// 'avail' may be non-contiguous, so return only the first contiguous chunk
size_t part1;
if (mIsOut) {
rear &= mFrameCountP2 - 1;
part1 = mFrameCountP2 - rear;
} else {
front &= mFrameCountP2 - 1;
part1 = mFrameCountP2 - front;
}
//part1是计算出来的最终空闲内存大小
if (part1 > (size_t)avail) {
part1 = avail;
}
//如果part1比buffer要求的帧数大,用不了这么多就取实际buffer需求的大小
if (part1 > buffer->mFrameCount) {
part1 = buffer->mFrameCount;
}
buffer->mFrameCount = part1;
//mRaw存放内存地址指针,rear是写入指针位移数,mFrameSize是每个位移的单位大小
buffer->mRaw = part1 > 0 ?
&((char *) mBuffers)[(mIsOut ? rear : front) * mFrameSize] : NULL;
buffer->mNonContig = avail - part1;
mUnreleased = part1;
status = NO_ERROR;
break;
}
......
}
上图主要是获取空闲buffer,计算剩余的内存空间是否满足buffer要求的大小,满足就把空闲地址指针rear赋值给buffer的mRaw即可;在返回到AudioTrack的write函数中,写入音频数据到buffer中即可,写入完成后要releaseBuffer,这个releaseBuffer并不是释放内存,因为服务端还没把数据读走,这里的releaseBuffer只是保存写入指针状态,如下函数:
/**
* releaseBuffer并不是释放内存,只是把写入数据状态更新到mCblk的rear和front指针中去
* **/
__attribute__((no_sanitize("integer")))
void ClientProxy::releaseBuffer(Buffer* buffer)
{
LOG_ALWAYS_FATAL_IF(buffer == NULL);
//stepCount记录此次写入的帧数
size_t stepCount = buffer->mFrameCount;
if (stepCount == 0 || mIsShutdown) {
// prevent accidental re-use of buffer
buffer->mFrameCount = 0;
buffer->mRaw = NULL;
buffer->mNonContig = 0;
return;
}
.......
mUnreleased -= stepCount;
audio_track_cblk_t* cblk = mCblk;
// Both of these barriers are required
//写入数据情况下,同步mRear指针
if (mIsOut) {
int32_t rear = cblk->u.mStreaming.mRear;
android_atomic_release_store(stepCount + rear, &cblk->u.mStreaming.mRear);
读取数据情况下,同步mFront指针
} else {
int32_t front = cblk->u.mStreaming.mFront;
android_atomic_release_store(stepCount + front, &cblk->u.mStreaming.mFront);
}
}
插入一个细节,实质上在write写入音频数据之前,要先调用AudioTrack的start函数,framework已经帮我们调用了,无需手动调用;start函数执行后会通过TrackHandle跨进程到AudioFlinger的Track中的start,看看Track的start函数关键细节:
status_t AudioFlinger::PlaybackThread::Track::start(AudioSystem::sync_event_t event __unused,
audio_session_t triggerSession __unused)
{
......
status = playbackThread->addTrack_l(this);
......
}
status_t AudioFlinger::PlaybackThread::addTrack_l(const sp<Track>& track)
{
mActiveTracks.add(track);
}
也就是把当前这个track加入到PlaybackThread的mActiveTracks中去,再看看上面的数据转移框图,就知道PlaybackThread线程是确定使用哪个Track了
AudioFlinger服务端模块读取应用端的数据
服务端的数据读取过程和客户端的写入其实有很多相近之处,从cblk中得到front指针
void AudioFlinger::DirectOutputThread::threadLoop_mix()
{
size_t frameCount = mFrameCount;
int8_t *curBuf = (int8_t *)mSinkBuffer;
// output audio to hardware
while (frameCount) {
AudioBufferProvider::Buffer buffer;
buffer.frameCount = frameCount;
status_t status = mActiveTrack->getNextBuffer(&buffer);
if (status != NO_ERROR || buffer.raw == NULL) {
// no need to pad with 0 for compressed audio
if (audio_has_proportional_frames(mFormat)) {
memset(curBuf, 0, frameCount * mFrameSize);
}
break;
}
//拷贝音频数据到curBuf,也就是mSinkBuffer中去
memcpy(curBuf, buffer.raw, buffer.frameCount * mFrameSize);
frameCount -= buffer.frameCount;
curBuf += buffer.frameCount * mFrameSize;
mActiveTrack->releaseBuffer(&buffer);
}
mCurrentWriteLength = curBuf - (int8_t *)mSinkBuffer;
mSleepTimeUs = 0;
mStandbyTimeNs = systemTime() + mStandbyDelayNs;
mActiveTrack.clear();
}
这里使用的DirectOutputThread,这种线程里面只能有一个Track,所以这里是mActiveTrack,并不是一个复数;如果是MixThread,内部用mActiveTracks保存多个Track,而且还涉及到混音等;
上面就是一个简单的读取过程,找到已写入数据的内存,将数据拷贝出来,拷贝到mSnkBuffer成员中,在threadloop_write时将数据在写出去:
ssize_t AudioFlinger::PlaybackThread::threadLoop_write()
{
LOG_HIST_TS();
mInWrite = true;
ssize_t bytesWritten;
const size_t offset = mCurrentWriteLength - mBytesRemaining;
// If an NBAIO sink is present, use it to write the normal mixer's submix
if (mNormalSink != 0) {
const size_t count = mBytesRemaining / mFrameSize;
ATRACE_BEGIN("write");
// update the setpoint when AudioFlinger::mScreenState changes
uint32_t screenState = AudioFlinger::mScreenState;
if (screenState != mScreenState) {
mScreenState = screenState;
MonoPipe *pipe = (MonoPipe *)mPipeSink.get();
if (pipe != NULL) {
pipe->setAvgFrames((mScreenState & 1) ?
(pipe->maxFrames() * 7) / 8 : mNormalFrameCount * 2);
}
}
ssize_t framesWritten = mNormalSink->write((char *)mSinkBuffer + offset, count);
ATRACE_END();
if (framesWritten > 0) {
bytesWritten = framesWritten * mFrameSize;
#ifdef TEE_SINK
mTee.write((char *)mSinkBuffer + offset, framesWritten);
#endif
} else {
bytesWritten = framesWritten;
}
// otherwise use the HAL / AudioStreamOut directly
} else {
// Direct output and offload threads
if (mUseAsyncWrite) {
ALOGW_IF(mWriteAckSequence & 1, "threadLoop_write(): out of sequence write request");
mWriteAckSequence += 2;
mWriteAckSequence |= 1;
ALOG_ASSERT(mCallbackThread != 0);
mCallbackThread->setWriteBlocked(mWriteAckSequence);
}
// FIXME We should have an implementation of timestamps for direct output threads.
// They are used e.g for multichannel PCM playback over HDMI. mSinkBuffer写入了音频数据,这里往mOutput写入
bytesWritten = mOutput->write((char *)mSinkBuffer + offset, mBytesRemaining);
if (mUseAsyncWrite &&
((bytesWritten < 0) || (bytesWritten == (ssize_t)mBytesRemaining))) {
// do not wait for async callback in case of error of full write
mWriteAckSequence &= ~1;
ALOG_ASSERT(mCallbackThread != 0);
mCallbackThread->setWriteBlocked(mWriteAckSequence);
}
}
mNumWrites++;
mInWrite = false;
mStandby = false;
return bytesWritten;
}
音频数据已经写到mSinkBuffer中去了,这里就会开始讲数据写往HAL了;对于PlaybackThread来说,数据有可能往mOutput、mPipeSink和mNormalSink这三个输出,其中前面mOutput是共享内存来实现写到HAL,mPipeSink则是管道写入数据,mNormalSink是根据业务选择前面两个变量来作为自己。
这里我们分析mOutput共享内存业务写入即可
向HAL层写入音频数据
通过audio open output业务一文可以得知,mOutput变量的类型是AudioStreamOut类型,其往下层持有的引用类型如下图:

而业务逻辑依次是:
AudioStreamOut.write() -> StreamOutHalHidl.write();直接看第二个处理函数:
status_t StreamOutHalHidl::write(const void *buffer, size_t bytes, size_t *written) {
......
status_t status;
//mDataMQ共享内存
if (!mDataMQ) {
//获取缓存区大小
size_t bufferSize;
if ((status = getCachedBufferSize(&bufferSize)) != OK) {
return status;
}
if (bytes > bufferSize) bufferSize = bytes;
//申请内存
if ((status = prepareForWriting(bufferSize)) != OK) {
return status;
}
}
//执行写入HAL数据
status = callWriterThread(
WriteCommand::WRITE, "write", static_cast<const uint8_t*>(buffer), bytes,
[&] (const WriteStatus& writeStatus) {
*written = writeStatus.reply.written;
// Diagnostics of the cause of b/35813113.
ALOGE_IF(*written > bytes,
"hal reports more bytes written than asked for: %lld > %lld",
(long long)*written, (long long)bytes);
});
mStreamPowerLog.log(buffer, *written);
return status;
}
status_t StreamOutHalHidl::callWriterThread(
WriteCommand cmd, const char* cmdName,
const uint8_t* data, size_t dataSize, StreamOutHalHidl::WriterCallback callback) {
//写入命令CMD
if (!mCommandMQ->write(&cmd)) {
ALOGE("command message queue write failed for \"%s\"", cmdName);
return -EAGAIN;
}
if (data != nullptr) {
size_t availableToWrite = mDataMQ->availableToWrite();
if (dataSize > availableToWrite) {
ALOGW("truncating write data from %lld to %lld due to insufficient data queue space",
(long long)dataSize, (long long)availableToWrite);
dataSize = availableToWrite;
}
//向共享内存写入数据daya
if (!mDataMQ->write(data, dataSize)) {
ALOGE("data message queue write failed for \"%s\"", cmdName);
}
}
mEfGroup->wake(static_cast<uint32_t>(MessageQueueFlagBits::NOT_EMPTY));
......
}
主要就是通过mDataMQ写入data数据,那么mDataMQ哪里来的?实质就是在prepareForWriting函数中:
status_t StreamOutHalHidl::prepareForWriting(size_t bufferSize) {
std::unique_ptr<CommandMQ> tempCommandMQ;
std::unique_ptr<DataMQ> tempDataMQ;
std::unique_ptr<StatusMQ> tempStatusMQ;
Result retval;
pid_t halThreadPid, halThreadTid;
Return<void> ret = mStream->prepareForWriting(
1, bufferSize,
[&](Result r,
const CommandMQ::Descriptor& commandMQ,
const DataMQ::Descriptor& dataMQ,
const StatusMQ::Descriptor& statusMQ,
const ThreadInfo& halThreadInfo) {
retval = r;
if (retval == Result::OK) {
tempCommandMQ.reset(new CommandMQ(commandMQ));
tempDataMQ.reset(new DataMQ(dataMQ));
....
}
});
i
mCommandMQ = std::move(tempCommandMQ);
mDataMQ = std::move(tempDataMQ);
mStatusMQ = std::move(tempStatusMQ);
mWriterClient = gettid();
return OK;
}
最终会调用到hardware/interface/audio/core/all-version/default/StreamOut.cpp的prepareForWriting方法,当然是通过HIDL跨进程调用的,调用成功后返回dataMQ,赋值给mDataMQ用于数据写入;
Return<void> StreamOut::prepareForWriting(uint32_t frameSize, uint32_t framesCount,
prepareForWriting_cb _hidl_cb) {
.......
//创建共享内存
std::unique_ptr<DataMQ> tempDataMQ(new DataMQ(frameSize * framesCount, true /* EventFlag */));
......
// 创建线程,会读取从Framework层的音频写入数据
auto tempWriteThread =
std::make_unique<WriteThread>(&mStopWriteThread, mStream, tempCommandMQ.get(),
tempDataMQ.get(), tempStatusMQ.get(), tempElfGroup.get());
if (!tempWriteThread->init()) {
ALOGW("failed to start writer thread: %s", strerror(-status));
sendError(Result::INVALID_ARGUMENTS);
return Void();
}
status = tempWriteThread->run("writer", PRIORITY_URGENT_AUDIO);
mCommandMQ = std::move(tempCommandMQ);
mDataMQ = std::move(tempDataMQ);
.......
//回调到Framework层
_hidl_cb(Result::OK, *mCommandMQ->getDesc(), *mDataMQ->getDesc(), *mStatusMQ->getDesc(),
threadInfo);
return Void();
}
emplate <typename T, MQFlavor flavor>
MessageQueue<T, flavor>::MessageQueue(size_t numElementsInQueue, bool configureEventFlagWord) {
......
/*
*创建匿名共享内存
*/
int ashmemFd = ashmem_create_region("MessageQueue", kAshmemSizePageAligned);
ashmem_set_prot_region(ashmemFd, PROT_READ | PROT_WRITE);
/*
* The native handle will contain the fds to be mapped.
*/
native_handle_t* mqHandle =
native_handle_create(1 /* numFds */, 0 /* numInts */);
if (mqHandle == nullptr) {
return;
}
mqHandle->data[0] = ashmemFd;
mDesc = std::unique_ptr<Descriptor>(new (std::nothrow) Descriptor(kQueueSizeBytes,
mqHandle,
sizeof(T),
configureEventFlagWord));
if (mDesc == nullptr) {
return;
}
initMemory(true);
}
到这里就知道在HAL层创建匿名共享内存,传递到Framework层的StreamHalHidl中write时候的写入即可;创建共享内存的时候顺带创建了一个WriteThread线程,用于读取音频数据;总结如下图:

HAL层读取音频数据
通过上小节的总结图,可以得知HAL层开启了WriteThread线程,不难猜到这个线程里面就会读取音频数据,看下线程的threadloop函数:
bool WriteThread::threadLoop() {
while (!std::atomic_load_explicit(mStop, std::memory_order_acquire)) {
uint32_t efState = 0;
mEfGroup->wait(static_cast<uint32_t>(MessageQueueFlagBits::NOT_EMPTY), &efState);
if (!(efState & static_cast<uint32_t>(MessageQueueFlagBits::NOT_EMPTY))) {
continue; // Nothing to do.
}
if (!mCommandMQ->read(&mStatus.replyTo)) {
continue; // Nothing to do.
}
switch (mStatus.replyTo) {
//应用层传递的是WRITE
case IStreamOut::WriteCommand::WRITE:
doWrite();
break;
case IStreamOut::WriteCommand::GET_PRESENTATION_POSITION:
doGetPresentationPosition();
break;
case IStreamOut::WriteCommand::GET_LATENCY:
doGetLatency();
break;
default:
ALOGE("Unknown write thread command code %d", mStatus.replyTo);
mStatus.retval = Result::NOT_SUPPORTED;
break;
}
.....
}
return false;
}
void WriteThread::doWrite() {
const size_t availToRead = mDataMQ->availableToRead();
mStatus.retval = Result::OK;
mStatus.reply.written = 0;
//从mDataMQ共享内存读取数据,这里还只是HAL层的外部HIDL处
if (mDataMQ->read(&mBuffer[0], availToRead)) {
//转手在写入HAL层,这个mStream是通过hal的adev_open_output_stream获得的
ssize_t writeResult = mStream->write(mStream, &mBuffer[0], availToRead);
if (writeResult >= 0) {
mStatus.reply.written = writeResult;
} else {
mStatus.retval = Stream::analyzeStatus("write", writeResult);
}
}
}
到上面的代码,已经从HIDL的服务端读取出了音频数据buffer,转手用mStream写入HAL层;mStream是什么?
HAL层音频数据写入Kernel驱动
接上头,mStream实质是一个audio_stream_out类型,由于HAL层不同的产商实现不一样,这里基于Qcom高通来分析;代码位于/harware/qcom/audio/目录下,audio_hw.c定义了HAL的设备函数节点;并且在adev_open_output_stream函数中创建了audio_stream_out类型,并配置了流支持的方法,大致如下:
static int adev_open_output_stream(struct audio_hw_device *dev,
audio_io_handle_t handle,
audio_devices_t devices,
audio_output_flags_t flags,
struct audio_config *config,
struct audio_stream_out **stream_out,
const char *address __unused)
{
struct audio_device *adev = (struct audio_device *)dev;
struct stream_out *out;
int i, ret = 0;
bool is_hdmi = devices & AUDIO_DEVICE_OUT_AUX_DIGITAL;
bool is_usb_dev = audio_is_usb_out_device(devices) &&
(devices != AUDIO_DEVICE_OUT_USB_ACCESSORY);
bool force_haptic_path =
property_get_bool("vendor.audio.test_haptic", false);
if (is_usb_dev && !is_usb_ready(adev, true /* is_playback */)) {
return -ENOSYS;
}
*stream_out = NULL;
out = (struct stream_out *)calloc(1, sizeof(struct stream_out));
......
out->stream.set_callback = out_set_callback;
out->stream.pause = out_pause;
out->stream.resume = out_resume;
out->stream.drain = out_drain;
out->stream.flush = out_flush;
out->stream.write = out_write;
......
*stream_out = &out->stream;
}
后续流程相对复杂,主要就是open打开/dev/snd/pcmCXDX驱动设备,在ioctl向设备里面写入buffer数据;写入函数位于/hardware/qcom/aduio/legacy/libalsa-intf/alsa_pcm.c里面pcm_write函数,将会涉及到音频数据的写入驱动;这部分是高通对ALSA框架的封装,其他厂商大致也是这个路径,ALSA是linux下的高级音频架构框架,Android系统裁剪使用tinyalsa,更多alsa知识课参考ALSA介绍
到这里audio数据传递大致就分析完了,但是其中还有很多知识点未涉及,比如音频如何混音、offload回放线程如何处理音频数据、ALSA如何播放音频数据等等,这些知识等待后续有时间在一一展开!