文章目录
第十章 对象和类
10.1 过程性编程与面向对象编程
如果采用过程性编程方法,首先考虑要遵循的步骤,然后考虑如何表示这些数据;
如果采用OOP方法,首先要考虑的是数据,不仅要考虑如何表示数据,还要考虑如何使用数据。从用户的角度考虑对象——描述对象所需的数据以及描述用户与数据交互所需的操作。完成对接口的描述后,需要确定如何实现接口和数据存储。最后,使用新的设计方案创建出程序。
10.2 C++中的类
类是一种将抽象转换为用户定义类型的C++工具,它将数据表示和操纵数据的方法组合成一个整洁的包。
类的组成:
- 类声明:以数据成员的方式描述数据部分,以成员函数(被称为方法)的方式描述公有接口。
- 类方法定义:描述如何实现类成员函数。
接口是一个共享框架,供两个系统交互时使用。对于类,我们说公共接口,在这里,公众(public)是使用类的程序,交互系统由类对象组成,而接口由编写类的人提供的方法组成。接口让程序员能够编写与类对象交互的代码,从而让程序能够使用类对象。然而,要使用某个类,必须了解其公共接口;要编写类,必须创建其公共接口。
防止程序直接访问数据被称为数据隐藏。类设计尽可能将公有接口与实现细节分开。公有接口表示设计的抽
象组件。将实现细节放在一起并将它们与抽象分开被称为封装。数据隐藏(将数据放在类的私有部分中)是一种封装,将实现的细节隐藏在私有部分中,也是一种封装。封装的另一个例子是,将类函数定义和类声明放在不同的文件中。
控制对成员的访问:公有还是私有?
类对象的默认访问控制:private。类和结构的唯一区别是结构的默认访问类型是public,而类为private。
10.3 实现类成员函数
类成员函数相较于普通函数的两个特殊的特征:
- 使用作用域运算符解析::来指出函数所属的类;
- 类方法可以访问类的private组件;
内联方法
其定义位于类声明中的函数都将自动成为内联函数。但是,如果愿意,也可以在类声明之外定义成员函数,并使其成为内联函数。内联函数的特殊规则要求在每个使用它们的文件中都对其进行定义。确保内联定义对多文件程序中的所有文件都可用的、最简便的方法是:将内联定义放在定义类的头文件中。
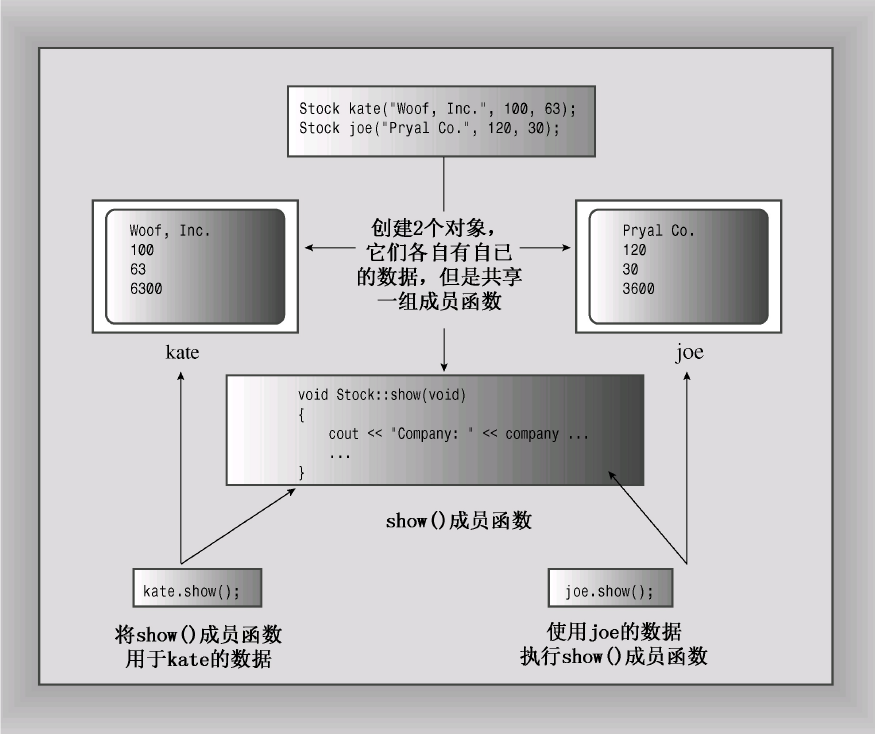
所创建的每个新对象都有自己的存储空间,用于存储其内部变量和类成员;但同一个类的所有对象共享同一组类方法,即每种方法只有一个副本。例如,假设kate和joe都是Stock对象,则kate.shares将占据一个内存块,而joe.shares占用另一个内存块,但kate.show( )和joe.show( )都调用同一个方法,也就是说,它们将执行同一个代码块,只是将这些代码用于不同的数据。在OOP中,调用成员函数被称为发送消息,因此将同样的消息发送给两个不同的对象将调用同一个方法,但该方法被用于两个不同的对象。
客户/服务器模型
OOP程序员常依照客户/服务器模型来讨论程序设计。在这个概念中,客户是使用类的程序。类声明(包括类方法)构成了服务器,它是程序可以使用的资源。客户只能通过以公有方式定义的接口使用服务器,这意味着客户(客户程序员)唯一的责任是了解该接口。服务器(服务器设计人员)的责任是确保服务器根据该接口可靠并准确地执行。服务器设计人员只能修改类设计的实现细节,而不能修改接口。这样程序员独立地对客户和服务器进行改
进,对服务器的修改不会客户的行为造成意外的影响。
构造函数
Stock *pstock = new Stock("Electroshock Games",18,19.0);
这条语句创建一个Stock对象,将其初始化为参数提供的值,并将该对象的地址赋给pstock指针。在这种情况下,对象没有名称,但可以使用指针来管理该对象。构造函数被用来创建对象,而不能通过对象来调用构造函数。
当且仅当没有定义任何构造函数时,编译器才会提供默认构造函数。为类定义了构造函数后,程序员就必须为它提供默认构造函数。如果提供了非默认构造函数,但没有提供默认构造函数,则下面的声明将出错:
Stock stock1;
这样做的原因可能是想禁止创建未初始化的对象。然而,如果要创建对象,而不显式地初始化,则必须定义一个不接受任何参数的默认构造函数。定义默认构造函数的方式有两种。一种是给已有构造函数的所有参数提供默认值:
Stock(const string & co = "Error", int n = 0 , double pr = 0.0);
另一种方式是通过函数重载来定义另一个构造函数——一个没有参数的构造函数:
Stock();
由于只能有一个默认构造函数,因此不要同时采用这两种方式。实际上,通常应初始化所有的对象,以确保所有成员一开始就有已知的合理值。因此,用户定义的默认构造函数通常给所有成员提供隐式初始值。在设计类时,通常应提供对所有类成员做隐式初始化的默认构造函数。
隐式地调用默认构造函数时,不要使用圆括号:
Stock f1();//f1()是一个返回Stock对象的函数。
Stock f2;//调用默认构造函数。
析构函数
对象过期时,程序将自动调用一个特殊的成员函数:析构函数。析构函数完成清理工作。如果构造函数使用new来分配内存,则析构函数将可以使用delete来释放这些内存;如果构造函数中没有使用new,则只需让编译器生成一个什么都不要做的隐式构造函数即可。
什么时候应调用析构函数呢?这由编译器决定。如果创建的是静态存储类对象,则其析构函数将在程序结束
时自动被调用。如果创建的是自动存储类对象(就像前面的示例中那样),则其析构函数将在程序执行完代码块时(该对象是在其中定义的)自动被调用。如果对象是通过new创建的,则它将驻留在栈内存或自由存储区中,当使用delete来释放内存时,其析构函数将自动被调用。最后,程序可以创建临时对象来完成特定的操作,在这种情况下,程序将在结束对该对象的使用时自动调用其析构函数。
如果程序员没有提供析构函数,编译器将隐式地声明一个默认析构函数。
构造函数不仅仅可用于初始化新对象。例如:
stock1 = Stock("Nifty Foods",10,50);
stock1对象已经存在,因此这条语句不是对stock1进行初始化,而是将新值赋给它。这是通过让构造程序创建一个新的、临时的对象,然后将其内容复制给stock1来实现的。随后程序调用析构函数,以删除该临时对象。
如果既可以通过初始化,也可以通过赋值来设置对象的值,则应采用初始化方式。通常这种方式的效率更高。
const成员函数
将const用于函数括号的后面将保证函数不会修改调用对象:但是这样将不能使用this来修改对象的值。
void stock::show() const;
以这种方式声明和定义的类函数被称为const成员函数。就像应尽可能将const引用和指针用作函数形参一样,只要类方法不修改调用对象,就应将其声明为const。
对象数组
Stock mystuff[4];
const int SIZE = 4;
Stock stocks[SIZE]={
Stock("Nano",12,24),
Stock("Boffo",200,23),
Stock("Na",12,24),
Stock("Bo",200,23)
}//第一个调用默认构造函数,第二个调用显式构造函数。
因此,要创建类对象数组,则这个类必须有默认构造函数。
作用域为类的常量
有时候,使符号常量的作用域为类很有用。
class Bakeery{
private :
const int SIZE =2;
double cost[SIZE];
...
}
但这是行不通的,因为声明类只是描述了对象的形式,并没有创建对象。因此,在创建对象前,将没有用于存储值的空间,然而,有两种方式可以实现这个目标,并且效果相同。
第一种方式是在类中声明一个枚举。在类声明中声明的枚举的作用域为整个类,因此可以用枚举为整型常量提供作用域为整个类的符号名称:
class Bakery{
private:
enum{Months = 2};
double cost[Months];
...
}
注意,用这种方式声明枚举并不会创建类数据成员。也就是说,所有对象中都不包含枚举。
C++提供了另一种在类中定义常量的方式——使用关键字static:
class Bakery{
private:
static const int Months = 2;
double cost[Months];
...
}
这将创建一个名为Months的常量,该常量将与其他静态变量存储在一起,而不是存储在对象中。因此,只有一个Months常量,被所有Bakery对象共享。
作用域内枚举
传统的枚举存在一些问题,其中之一是两个枚举定义中的枚举量可能发生冲突:
enum egg {Small , Medium , Large , Jumbo};
enum t_shirt {Small , Medium , Large , Jumbo};
这将无法通过编译,因为egg Small和t_shirt Small位于相同的作用域内,它们将发生冲突。为避免这种问题,C++11提供了一种新枚举,其枚举量的作用域为类。这种枚举的声明类似于下面这样:
enum class egg {Small , Medium , Large , Jumbo};
enum class t_shirt {Small , Medium , Large , Jumbo};
也可使用关键字struct代替class。无论使用哪种方式,都需要使用枚举名来限定枚举量:
egg choice = egg::Large;
t_shirt Floyd = t_shirt::Large;
在有些情况下,常规枚举将自动转换为整型,但作用域内枚举不能隐式地转换为整型,必须显式转换:
enum egg {Small , Medium , Large , Jumbo};
enum class t_shirt {Small , Medium , Large , Jumbo};
egg one = Small;
t_shirt two = t_shirt::Small;
int king = one;//OK
int ring = two;//NOK
默认情况下,C++11作用域内枚举的底层类型为int。也可以显式的改动底层类型:
enum class : short pizza {Small,Medium};
:short将底层类型指定为short,但指定的底层类型必须为整型。
10.4 抽象数据类型(abstract datatype,ADT)
顾名思义,ADT以通用的方式描述数据类型,而没有引入语言或实现细节。例如,通过使用栈,可以以这样的方式存储数据,即总是从堆顶添加或删除数据。例如,C++程序使用栈来管理自动变量。当新的自动变量被生成后,它们被添加到堆顶;消亡时,从栈中删除它们。
下面简要地介绍一下栈的特征。首先,栈存储了多个数据项(该特征使得栈成为一个容器——一种更为通用的抽象);其次,栈由可对它执行的操作来描述:
- 可创建空栈。
- 可将数据项添加到堆顶(压入)。
- 可从栈顶删除数据项(弹出)。
- 可查看栈否填满。
- 可查看栈是否为空。
可以将上述描述转换为一个类声明,其中公有成员函数提供了表示栈操作的接口,而私有数据成员负责存储栈数据。类概念非常适合于ADT方法。比如我们定义一个栈类,这个类不是根据特定的类型来定义栈,而是根据通用的Item类型来描述。在这个例子中,头文件使用typedef用Item代替unsigned long。如果需要double栈或结构类型的栈,则只需修改typedef语句,而类声明和方法定义保持不变。
typedef unsigned long Item;
10.5 总结
面向对象编程强调的是程序如何表示数据。使用OOP方法解决编程问题的第一步是根据它与程序之间的接口来描述数据,从而指定如何使用数据。然后,设计一个类来实现该接口。一般来说,私有数据成员存储信息,公有成员函数(又称为方法)提供访问数据的唯一途径。类将数据和方法组合成一个单元,其私有性实现数据隐藏。
通常,将类声明分成两部分组成,这两部分通常保存在不同的文件中。类声明(包括由函数原型表示的方法)应放到头文件中。定义成员函数的源代码放在方法文件中。这样便将接口描述与实现细节分开了。从理论上说,只需知道公有接口就可以使用类。当然,可以查看实现方法(除非只提供了编译形式),但程序不应依赖于其实现细节,如知道某个值被存储为int。只要程序和类只通过定义接口的方法进行通信,程序员就可以随意地对任何部分做独立的改进,而不必担心这样做会导致意外的不良影响。
类是用户定义的类型,对象是类的实例。这意味着对象是这种类型的变量,例如由new按类描述分配的内存。C++试图让用户定义的类型尽可能与标准类型类似,因此可以声明对象、指向对象的指针和对象数组。可以按值传递对象、将对象作为函数返回值、将一个对象赋给同类型的另一个对象。如果提供了构造函数,则在创建对象时,可以初始化对象。如果提供了析构函数方法,则在对象消亡后,程序将执行该函数。
每个对象都存储自己的数据,而共享类方法。如果mr_object是对象名,try_me( )是成员函数,则可以使用成员运算符句点调用成员函数:mr_object.try_me( )。在OOP中,这种函数调用被称为将try_me消息发送mr_object对象。在try_me( )方法中引用类数据成员时,将使用mr_object对象相应的数据成员。同样,函数调用i_object.try_me( )将访问i_object对象的数据成员。
如果希望成员函数对多个对象进行操作,可以将额外的对象作为参数传递给它。如果方法需要显式地引用调用它的对象,则可以使用this指针。由于this指针被设置为调用对象的地址,因此*this是该对象的别名。
类很适合用于描述ADT。公有成员函数接口提供了ADT描述的服务,类的私有部分和类方法的代码提供了实现,这些实现对类的客户隐藏。