前言
读者先别怪我起这么抽象装杯的文章标题,主要是前面可能因为标题缘故本文好几次没审核通过(悲)所以只能用这么抽象的标题了
事情发展是这样的
朋友发来消息说他之前加了个时不时发聊天记录的 学习资料群 ,但里面扫二维码能看的 学习视频 但是总是过阵子就看不了;
所以来问我看能不能把学习视频下载下来,给他平日复习。
开始操作
通过聊天记录里的 学习视频的二维码 ,拿到网址
http://cos.ap-chengdu.myqcxxx.com/xxxxxxxx/xxxxd/xxxxxxxxxxxxxxxxx003.html
有的网站视频右键点击就有下载选项,或者找到源码后找视频接口就直接能下载资源
简单找了下,网页的界面和没有相关下载选项,右键点击没反应,也并不能打开管理开发工具看源码
使用IDM(InternetDownloadManager)或者其他诸类下载工具都无法正常下载视频
好的,有点技术含量了
先BP抓个包看看有没什么关键请求和报文
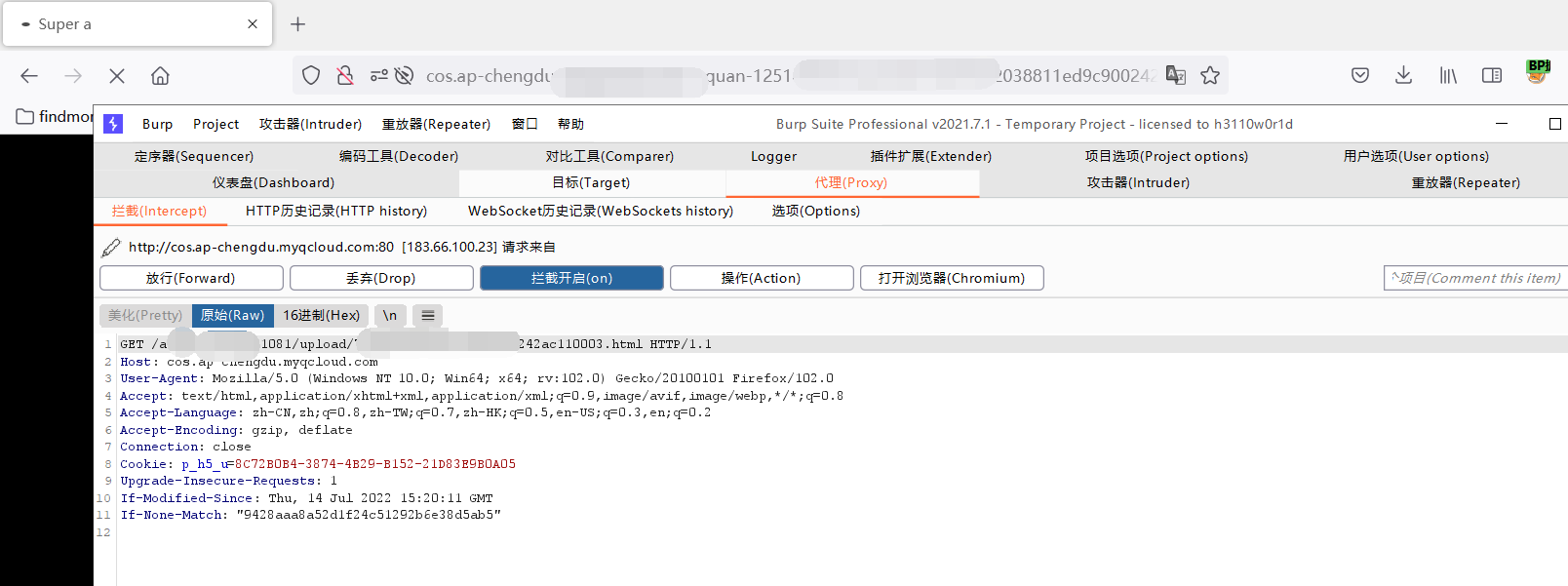
嗯…没有什么关键接口或者请求信息
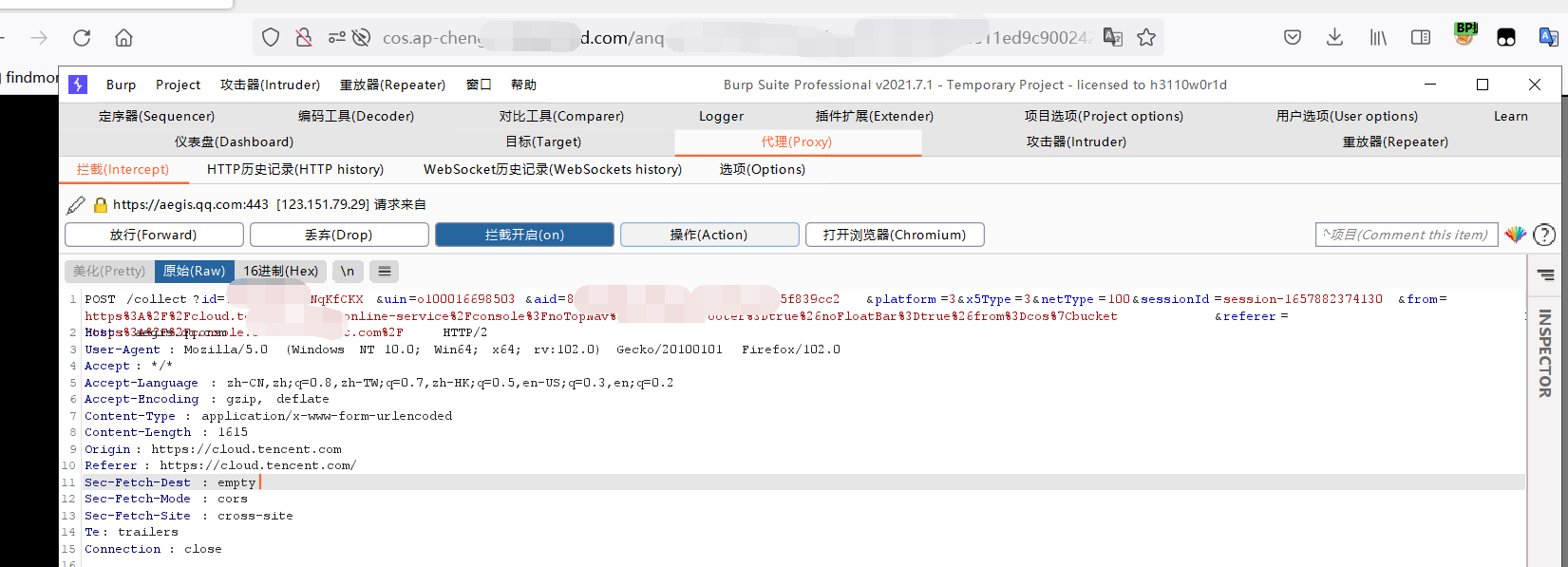
换思路
算了,换个思路,先拿到最基础的网页源码分析看看再想思路
小爬一下,拿个网页源码
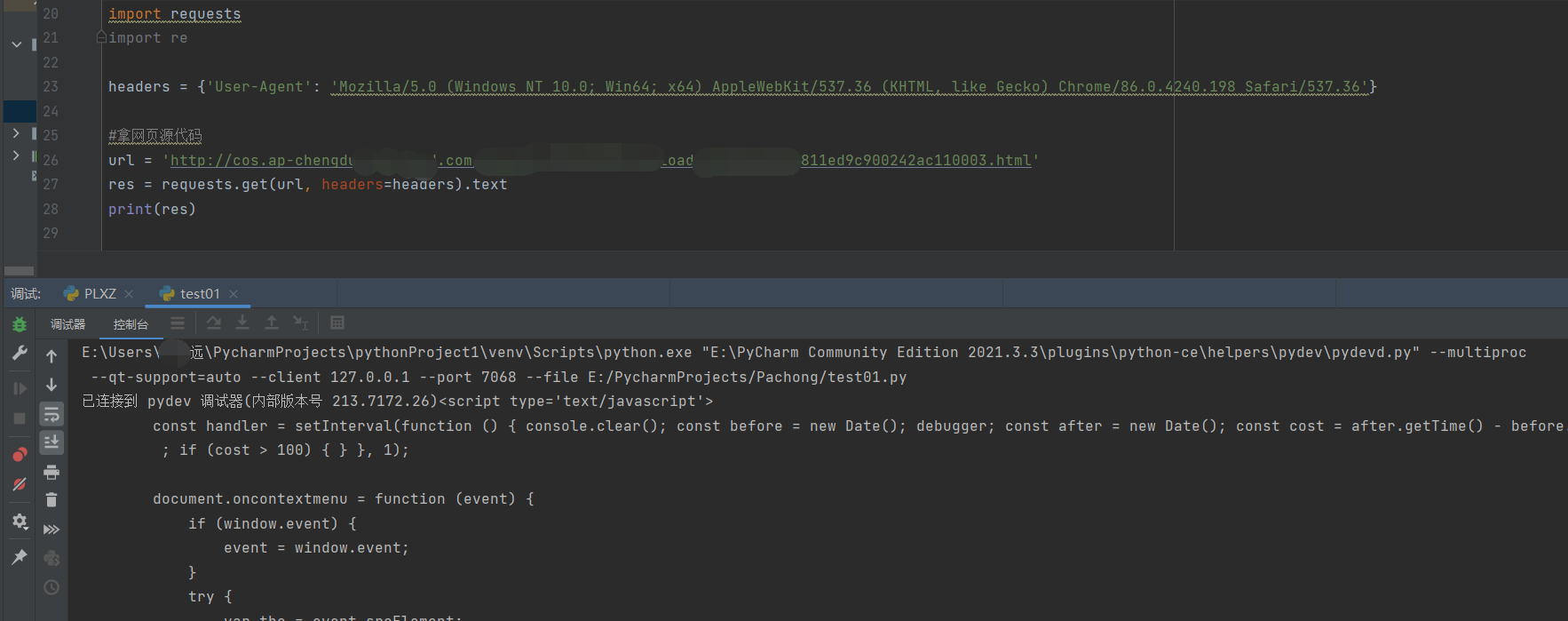
拿到后开始分析
很基本的页面渲染…
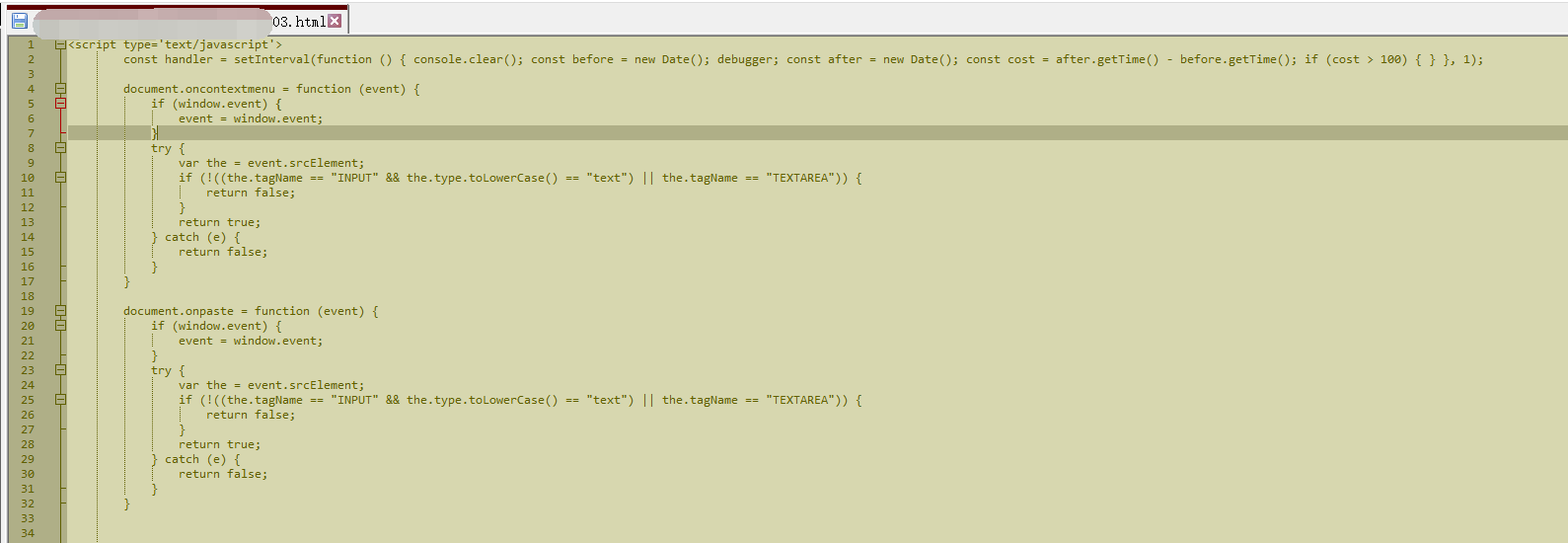
收到的请求和判断
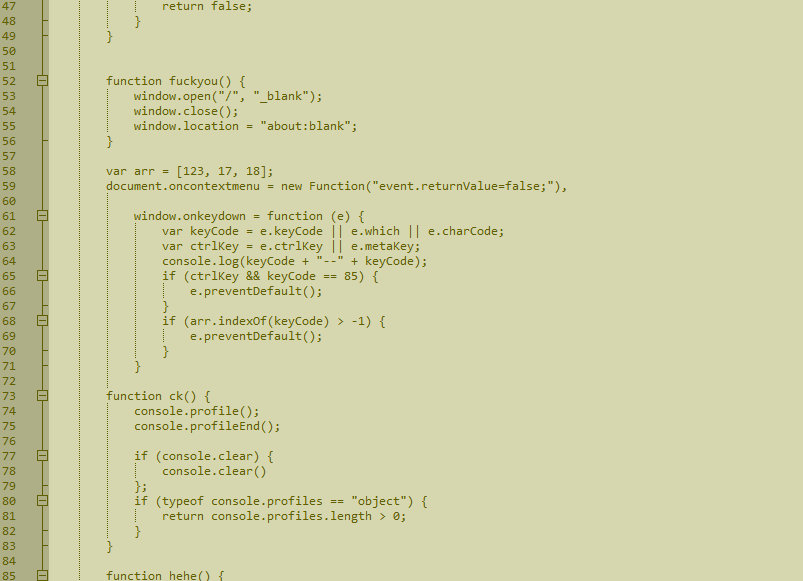
有点用的
终于找到有点用的东西了
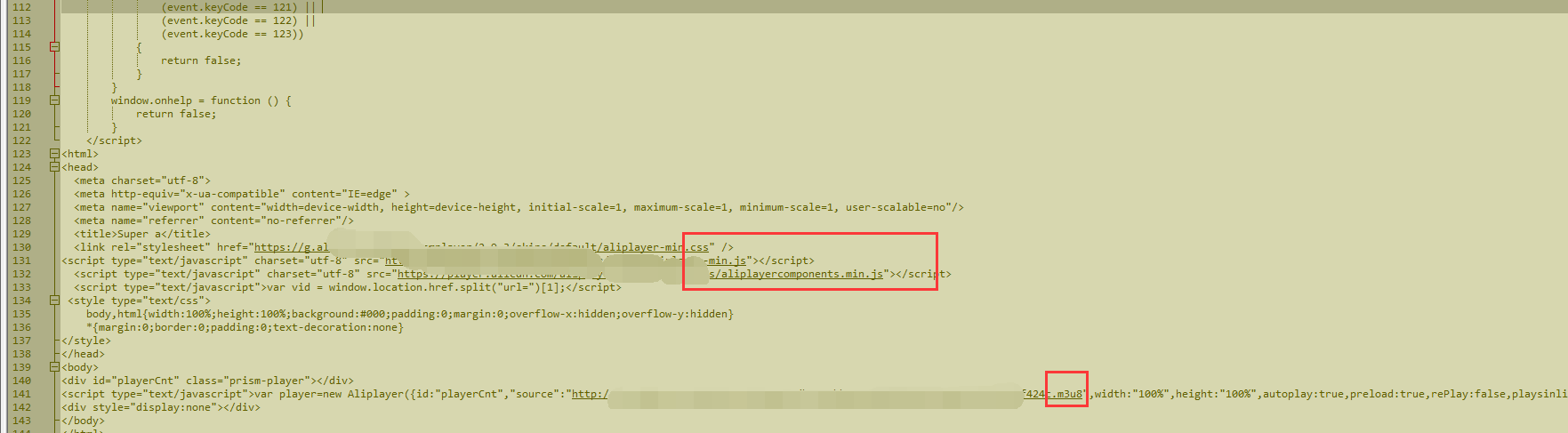
这里看到几个.css和.js的渲染文件,先不要理它,应该是下面这个m3u8的链接导入的视频
印象里记得m3u8是把视频源文件切片后放在服务器上然后分段请求加载出的视频格式(
先下载m3u8文件后
文本格式打开看看
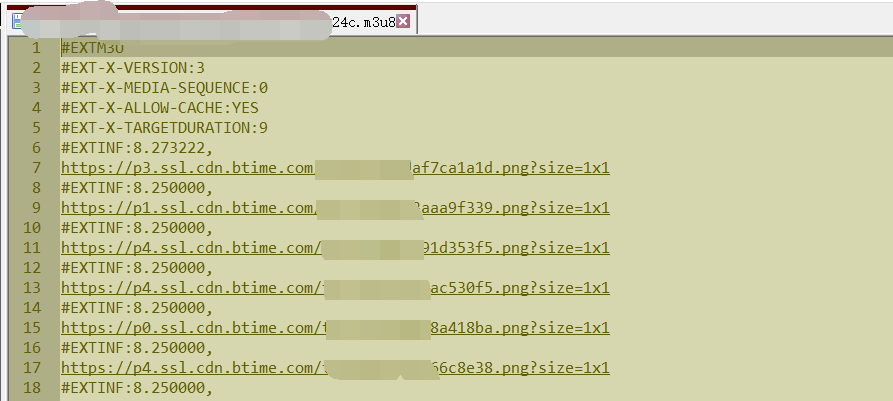
好消息:经典的m3u8格式,很明显没有KEY值加密,起码处理起来方便点,主要切片就一百来行链接
(仔细一看)
坏消息:这怎么TM不仅不是按文件尾字节顺序排布,而且还TM是.png格式(看样子还要处理…)
回忆一下
印象里记得一般m3u8是切片为几百上千个.ts的视频格式,然后每段链接加载播放
(商业模式m3u8视频的话在头文件会有KEY值的加密处理,这也是一些大视频网站的处理方法)
这里应该是前端源码里接受到加载的.png图片,然后改后缀为.ts或者其他播放格式片段加载播放
吐槽一下就一个学习资料的资源,干嘛要搞的这么麻烦…你老老实实向别人家一样
别人家的文章
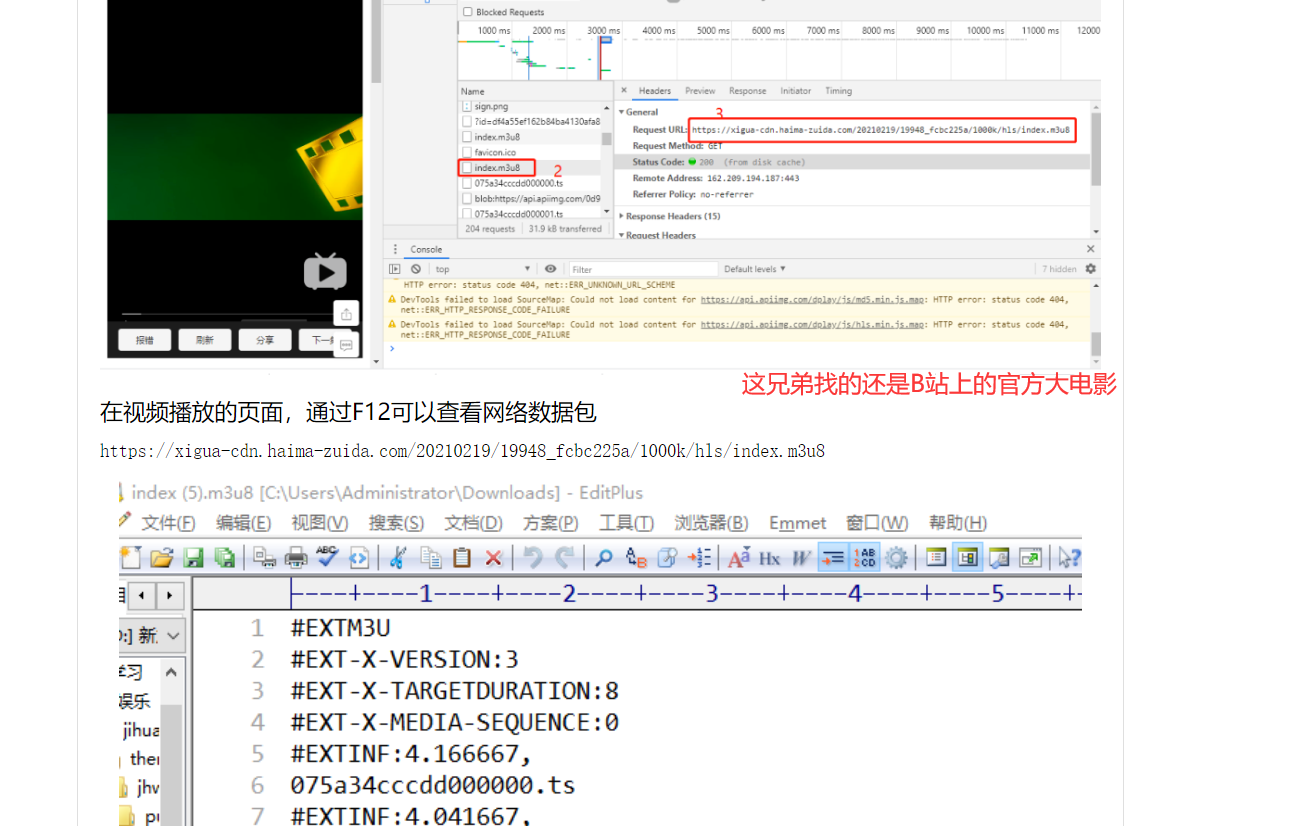
别人爬取和下载B站m3u8格式大电影的文章分析
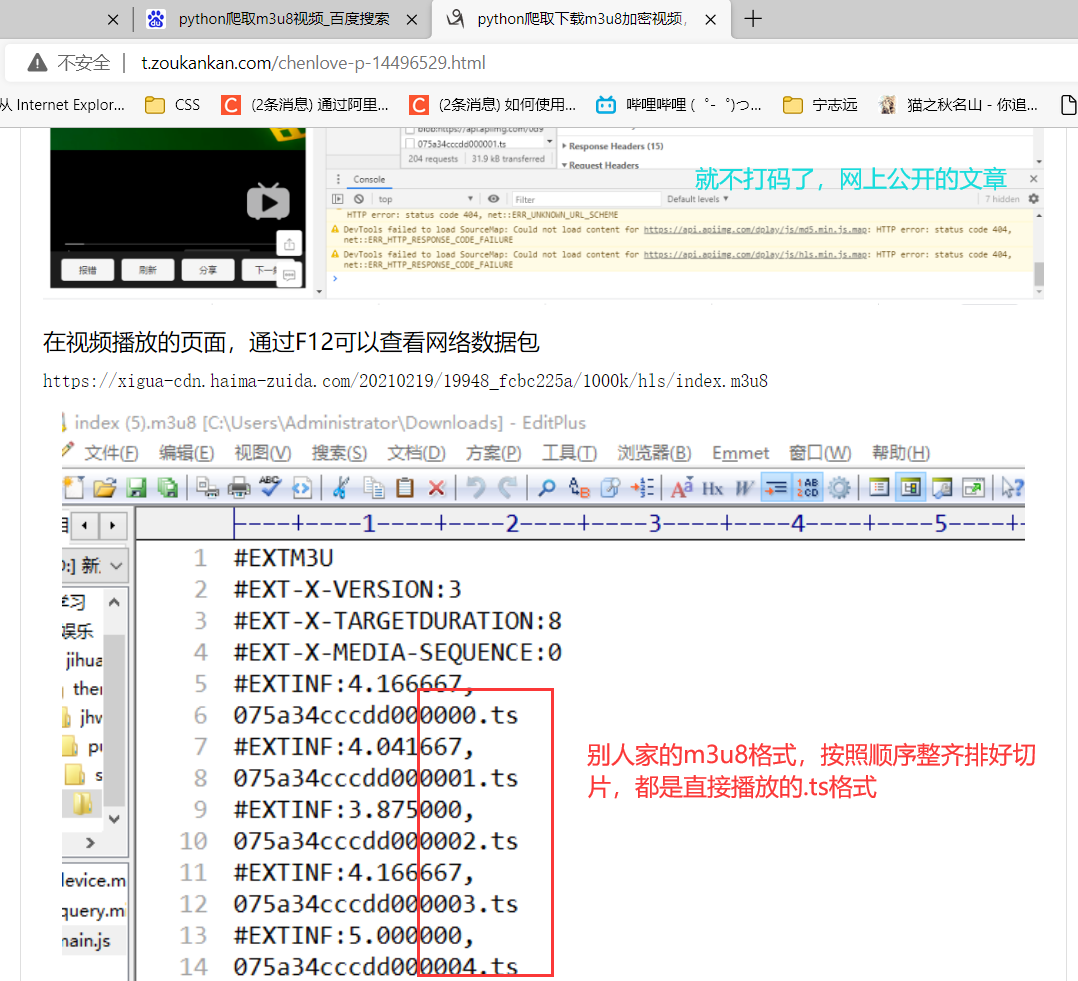
本文这里操作的学习资料的学习视频
(本文操作就是搞的这里面扫二维码图片看的学习视频)搞到的m3u8,
一没按照.ts格式,二没按照顺序,你一个学习资料网站至于搞得比人家B站视频资源还麻烦嘛…
分析完毕,开始划重点
感受一下这种文件的魅力(
现在思路已经清晰了.png
接下来处理过程就明朗了.png
先把m3u8里下载链接批量提取.png
把这几百个切片链接先批量下载.png
再批量改文件后缀为.ts
再按照m3u8文件提取所有不规则链接文件的【顺序】.png
然后改切片的文件名为0001,0002,0003…顺序.png
然后用ffmpeg或者moviepy或者其他工具合并就行.png
后续
后续所有脚本和处理都做好了;
为了避免文章过长先写到这里,之后再把后面的处理流程作为(二)的文章传上来。