万纳链(Venachain)是万向区块链基于PlatONE底层开源平台,针对企业级客户和开发者在数字化转型过程中的实际需求,推出的自主可控的高性能联盟链,已通过中国电子标准化研究院的功能与性能双项测试。依托万向区块链丰富的技术与生态资源,万纳链具备出色的关联技术耦合能力,通过与隐私计算、物联网、知识图谱等技术融合,引航分布式认知技术的创新和实践。同时,结合团队出色的机制设计能力,万纳链旨在为实体经济的数字化转型打造可信数字底座,为企业级客户和开发者提供隐私安全、性能优越、一键部署、功能丰富的综合解决方案。
我们将通过一系列技术科普文章,帮助大家了解万纳链的技术特点和操作方法。今天我们一起来了解万纳链的存储插件化系统。
本文作者:万向区块链通用架构技术部 曾梦露
引言
区块链,尤其是联盟链,可用于不同的业务场景。对于不同的应用场景,区块链对数据的存储与读取的需求也不尽相同。例如有些联盟区块链用于数据存证,对区块链数据写入的性能要求较高;而有的联盟区块链用于供应链物流流转对账,对数据的读取与查询的均衡性能要求较高。
因此,万纳链提出并采用了存储插件化系统方案,旨在通过存储引擎插件化的方式,为万纳链灵活赋能多种存储方式,针对不同的应用场景,按需满足业务的高性能数据读写需求。通过存储插件化系统可提高万纳链的存储弹性与可扩展性,从而实现区块链数据存储的高效管理。
设计方案
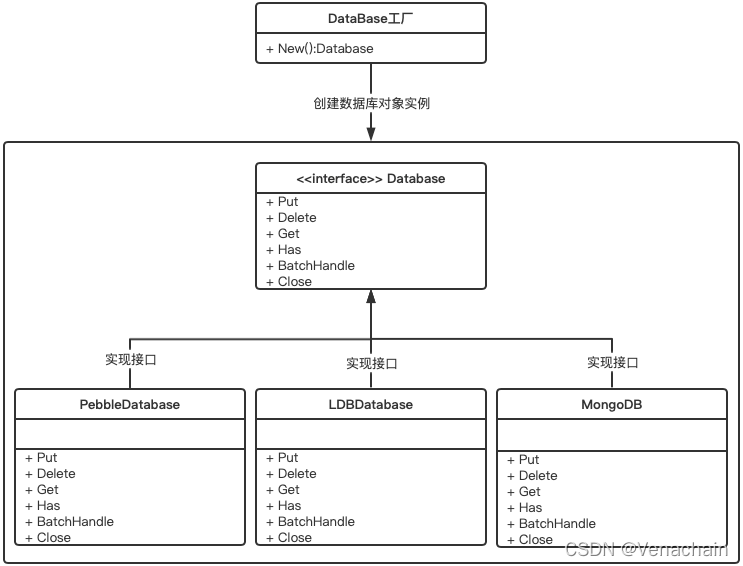
图 1: 万纳链存储插件化系统方案
图 1 展示了万纳链存储插件化系统方案。该方案采用工厂模式,定义了通用的存储引擎接口Database,存储引擎需实现该接口中定义的方法。在区块链节点启动时,DataBase工厂通过读取配置参数中的存储引擎类型,调用New方法创建对应的存储引擎。并且,万纳链支持同一条链上的不同节点采用不同的存储引擎。目前万纳链支持的存储引擎有LevelDB, PebbleDB, MongoDB, 后续将支持更多SQL数据库等。

图2 :LSM结构数据存储模型(参考来源LINK)
PebbleDB实现原理与LevelDB类似,均采用了基于日志结构合并树(log-structured merge tree, LSM)的一种分层数据组织模型,如图 2所示。LSM树采用减少随机写次数的策略,使得数据库具有较高的写性能。具体的,对于每次写入操作,首先将其顺序写入日志文件(Write Ahead Log)和插入内存(MemTable)。当内存中的数据达到一定的阈值时,再将异步将数据写入磁盘文件中。PebbleDB与LevelDB的不同之处在于细节的实现上,PebbleDB在LevelDB的基础上进一步实现优化,提升了读写性能。例如,PebbleDB优化了内部Key的数据结构,减少了内部的Key的多次重复解码;当批量写入的数据过大(例如超过1GB数据)时,PebbleDB会跳过将数据写入MemTable的过程,采用一种flushableBatch的数据结构,避免在添加大数据时消耗过多内存,而导致程序被内核杀死;此外PebbleDB可根据实际情况动态调整数据刷新速率与压缩速率,减少用户读写操作的延迟峰值,等等。
MongoDB介于关系数据库和非关系数据库之间,是非关系型数据库中功能最丰富的。它支持的bson格式可以存储较为复杂的数据类型,可以增强区块链中存储的数据的可读性;同时,MongoDB支持丰富的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,对比KV类型数据库,MongoDB为区块链的数据的查询与读取提供了极大的便利性。
总结
目前已有的区块链通常仅提供单一的数据库存储解决方案,或同一条链中的区块链节点的存储引擎必须保持相同,并不能很好的针对不同应用场景提供高性能的数据存储、查询等服务。万纳链存储插件化系统方案,支持LevelDB、PebbleDB、MongoDB等数据存储引擎,有效的解决了上述问题,可以为不同的业务应用场景打造合适的高性能存储方案,提供更优的区块链性能。