
大家好!我是保护小周ღ,本期为大家带来的是 Java的基本数据类型,内容会与C语言的基本数据类型进行基本的比较,数据类型提示,整型提升,以及简单了解 String 类型 ,进一步感受Java 的安全性。
C语言混不下去了,面向对象的编程太爽了~
目录

一、常量
常量就是在程序运行期间,不能被修改,固定不变的量叫常量。
相较于C 语言来讲,Java 的基本数据类型多了个字符串类型,还是一个byte 类型,属于整型数据,后面再给大家介绍。
字面常量的分类:
1. 字符串常量:由""括起来的,比如“12345”、“Hello World!”、“你好”。
2. 整形常量:程序中直接写的数字没有小数点,比如:100、1000
3. 浮点数常量:程序中直接写的小数,比如:3.14、0.49
4. 字符常量:由 单引号 括起来的当个字符,比如:‘A’、‘1’
5. 布尔常量:只有两种true和false
6. 空常量:null
这里浅提一手 null ,NULL 在C语言中,一般是给指针类型的变量赋值的,代表存储的地址为空,Java 当中没有指针类型,但是有引用,同样可以存储地址,但是不能对地址进行操作。
其余数据类型且听我慢慢道来……
二、基本数据类型
Java 的基本数据类型有 八种:
2.1 整型
int 整型
首先当然是介绍我们最最最常用的 int 啦
public class Main {
public static void main(String[] args) {
int a=10; //定义了一个整型数据 a 并初始化为10
System.out.println(a);
System.out.println(Integer.MAX_VALUE);
System.out.println(Integer.MIN_VALUE);
}
}
Java 当中 整型数据默认是有符号(signed)的,没有无符号(unsigned)之分(java ,没有所谓的无符号和有符号位的概念)其次在给变量设置初始值时,不能超过该数据类型的表示范围,否则就会造成溢出,编译器会报错,变量在使用之前也必须赋初值,这些在 Java中都是错误。Integer 这个是 int的包装类,可以理解为将一些功能集成在一起,
其中MAX_VALUE 就是输出 int 类型的最大值,MIN_VALUE 就是输出 最小值
 所以一个 int 类型的数据 取值范围为 [-2^31, 2^31 -1] ;
所以一个 int 类型的数据 取值范围为 [-2^31, 2^31 -1] ;
long 长整型
public static void main(String[] args) {
int a = 10;
long b = 20;
long c = 30L;
}为了区分 int 和 long 类型,一般是在初始化的时候在数值后面加 大写的L ,小写的也可,但是小写的不易区分, 不加L的话 20 默认是整型数据(int )但是这没有错,后面讲。
C 语言的long 类型具体占几个字节没有固定的说法 ,即 long >= int ,在 vs 2019 集成开发环境32位环境下 long 占4个字节, 有些编译器可能是8个字节,但是在 64 位环境下就是 8 个字节,Java中就没有计较这么多, 不管操作系统是多少位,平台是多少位 都没有关系,long 类型就是8个字节,取值范围就是[-2^63 , 2^63 - 1];
short 短整型
public static void main(String[] args) {
short a = 10;
//short 类型的取值范围
System.out.println(Short.MAX_VALUE);
System.out.println(Short.MIN_VALUE);
}
short 在 Java 中占2个字节 ,数值的表示范围 [-2^15,2^15-1] , 这个类型用的少,还有大家有没有注意一个点,上面说过 , 在初始化的时候,初始化的值(常量)默认是整型4个字节, 那编译器为啥不报错呢,原因是编译器会帮我们检查如果 常量值的范围在该类型数值的表示范围内就不会报错,如果是一个 整型int 类型给低字节的变量赋值那编译肯定是不被允许的,报错除非 像 C 语言那样(类型)变量, 强制类型转换,但是会对被转数值的变量值精度造成损失 , 比如人家存了 4 个字节的二进制位 , 你把他强转为 short 类型, 就只剩下 16 个二进制位描述数据,哪能一样嘛。
byte 字节型
public static void main(String[] args) {
byte a = 10;
byte b = 20;
// byte 类型数值的取值范围
System.out.println(Byte.MAX_VALUE);
System.out.println(Byte.MIN_VALUE);
} byte 类型 是C语言没有的一个类型,只有一个字节,额,取值范围如图所示,有一点比较值得注意。
byte 类型 是C语言没有的一个类型,只有一个字节,额,取值范围如图所示,有一点比较值得注意。

很奇怪啊, 报错了,10 ,20 都是在byte 数值的取值范围内,哪怕他们相加的结果30也在范围内,怎么就错了呢,这里就涉及到一个知识点,整型提升,不足4个字节的数据在进行运算的时候会进行整型提升,a 跟 b 就是int 类型 了, 那将两个 int 类型的数据运算后的结果给到一个 byte 字节型变量 ,那肯定装不下的嘞,还有一点就是,不足4个字节的整型 在打印时也会提升至4字节打印。
这样就没有任何问题啦,

用 short 类型也会报错,咱就是说 >= int 才可以。


那如果是说这样:
public static void main(String[] args) {
int a = 10;
int b = 10;
long sum = a+b;
System.out.println(sum);
}这就不是整型提升了, 这个叫类型提升, 在运算时int 会提升至long 类型参与运算,没有任何问题。
C语言 整型提升规则:一般用于不足整型(4个字节)的数据,有符号位根据符号位,高位补齐,无符号位,直接高位补0。
Java 安全性好,很多你没注意到的地方,集成开发环境都能很好的帮你找出来,即使是这样,我们还是要避免这些不应该的错误,养成良好的编程习惯。
高字节类型(强制类型转换)为低字节类型,就会发生截断,保留低位,舍去高位,如果不是强转是自己的疏忽造成的原因Java编译就通过不了。
1. 不同类型的数据混合运算, 范围小的会提升成范围大的.
2. 对于 short, byte 这种比 4 个字节小的类型, 会先提升成 4 个字节的 int , 再运算.
2.2 浮点型
Java 的浮点型数据存储遵循 IEEE 754 标准(和C语言一样)


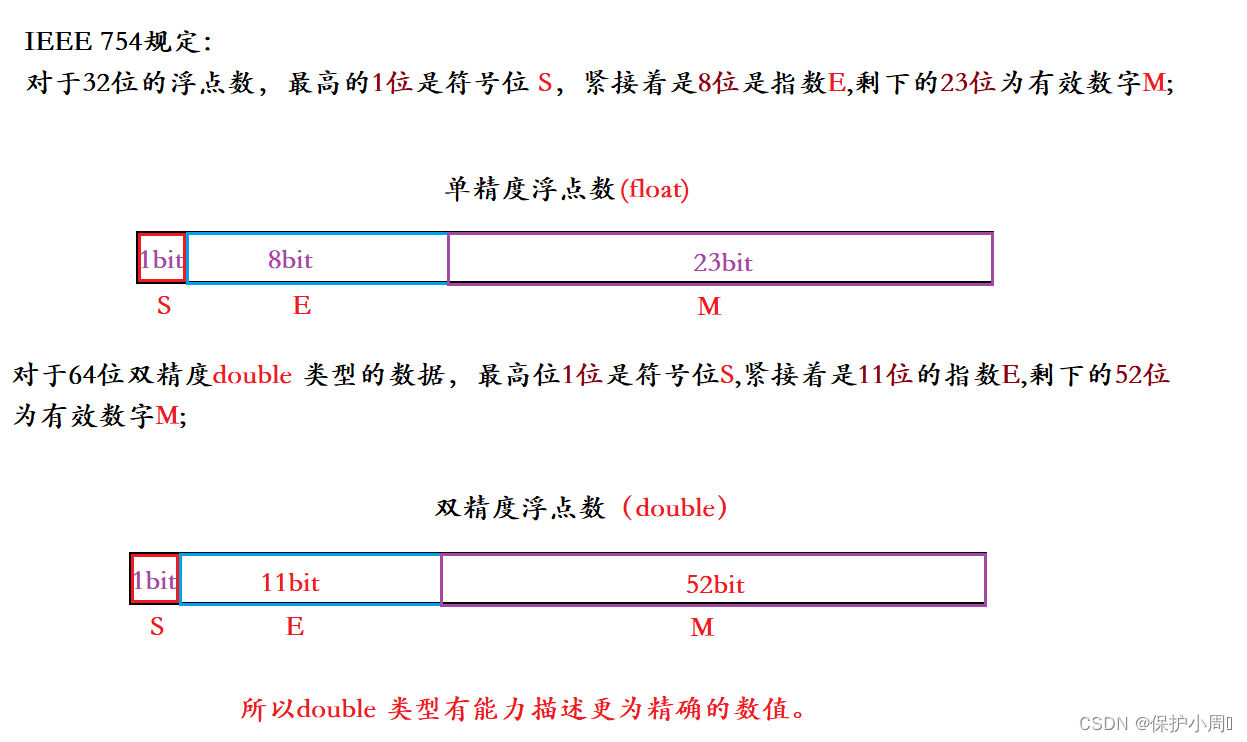
这个起一个了解的目的,Java 当中可以不关注这些东西。
double 双精度 和 float 单精度
double 在Java 中占8 个字节,且所有小数默认是double 类型,使用的最多的是 double ,

蛮智能的,会把后面的小数去掉。
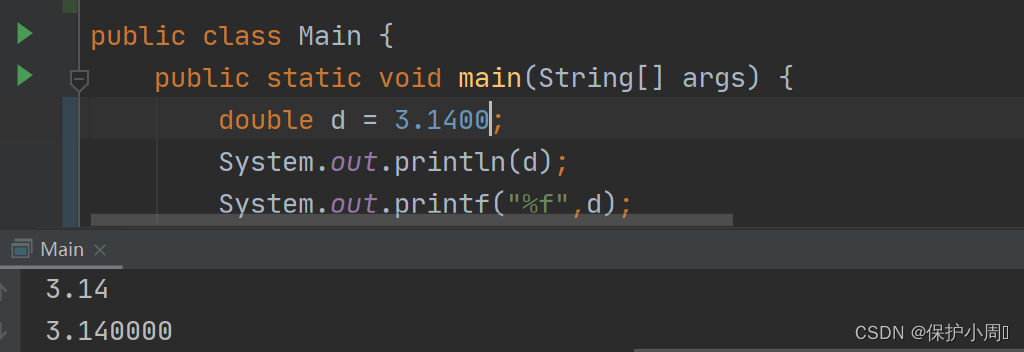
用 C语言的输出格式也是没有问题的,想保留几位的话就 + %. 小数位数 f ,printf() 格式化输出也是可以的 Java 保留了这种输出方式。
在Java 中 int数据 除以 int 数据 的值仍然是 int(会直接舍弃小数部分),跟C语言一样的规则,整数乘除小数的结果是小数。

对于 float 类型来讲,这是一种错误……

你会觉得,e 其实是怎么回事呢,就上面说过啦,是 小数数值默认是 double 类型, 把 8个字节的数据给 4个字节得 float 装 ,可不报错嘛,是除非是强制类型转换,但会丢失精度,所以对 float 变量进行初始化的时候,初始化数值加 f 即可(大小写都行,通常是小写 f)。
2.3 char 字符型
public static void main(String[] args) {
char ch1 = 'a'; // 单个字符也是两个字节
char ch2 = '符'; //注意千万别使用引号“ ”,引号代表是字符串类型
System.out.println(ch1);
System.out.println(ch2);
} Java 的 char 类型 占2个字节,且没有负数,为什么呢,C语言中的 char 占1 个字节,使用的是 ASCLL 码字符集表示字符, 所以一个字节就可以了, Java 中采用的是 Unicode 编码表示字符,所以 Java 中的 char 类型有能力描述更多的字符,包括中文。
Java 的 char 类型 占2个字节,且没有负数,为什么呢,C语言中的 char 占1 个字节,使用的是 ASCLL 码字符集表示字符, 所以一个字节就可以了, Java 中采用的是 Unicode 编码表示字符,所以 Java 中的 char 类型有能力描述更多的字符,包括中文。
char的包装类型为Character
Unicode 字符集
Unicode( 统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的 二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
Unicode与ASCII一样也是一种字符编码方法,它占用两个字节(0000H—FFFFH),容纳65536 个字符,这完全可以容纳全世界所有语言文字的编码。在Unicode 里,所有的字符都按一个字符来处理, 它们都有一个唯一的Unicode 码。Unicode只是一个编码规范,目前实际实现的unicode编码只要有三种:UTF-8, UCS-2 和 UTF-16
如果把各种文字编码形容为各地的语言,那么 Unicode 编码就是世界各国通用的语言,在这种语言环境下,就不会有语言的编码冲突,Unicode 就是将世界上所有的文字用2 个字节 统一进行编码,所以他也被称之为 “万国码”
2.4 布尔型
布尔类型常用来表示真假,boolean 类型的变量只有两种取值, true 表示真, false 表示假,Java 的 boolean 类型和 int 不能相互转换, 不像 C 语言中 0 为假 ,非0 为真 ,boolean 只有 true 和 false ,不存在 0 为 假,1 为真的说法。

Java 中的条件只能是 布尔表达式 即 表达式结果只能是 布尔类型,
在Java 当中 真只有 true 假只有 false

Java规范中并没有明确规定 boolean 占几个字节,也没有专门用来处理boolean的字节码指令,在
Oracle公司的虚拟机实现中,boolean占1个字节。
三、String 字符串类型
Java 有属于单独的字符串类型,注意:String 字符串类型,不属于基本数据类型,属于引用数据类型,这里先给大家简单的介绍一手,关于字符串类型的详细内容后期再给大家详细讲解。

Java 输出的时候 输出项可以拼接,使用 + 有一点需要注意,当输出项出现 字符串时,
任何类型的数据 和 字符串拼接,结果就是字符串举个例子:

大家可以看到无论是字符串常量还是字符串变量,只要输出语句里出现了,所有的都变成了字符串,表达式也无法计算,那怎么解决呢?

因为程序是从左往右执行的,所以我们可以把需要运算的表达式放最左边,最后再拼接字符串,但这样终究不是我们想要的效果,如果想把字符串放最左边,又想让 表达式计算,该怎么办呢?
 改变他的优先级,加() 将需要计算的表达式括起来,所以就会先计算,后拼接为字符串。
改变他的优先级,加() 将需要计算的表达式括起来,所以就会先计算,后拼接为字符串。
不知道大家有没有想过一个问题,就是,一个整型数据,或者是浮点型 数据等,怎么转换为字符串, 又或者怎么把字符串转换为 对应的数据类型,这个需要使用对应类型的 “包装类",后期再详细给大家介绍。

字符串 转某个类型,前提是 该字符串, 能转,不要太离谱:

至此,初始Java 的基本数据类型 内容博主已经分享完了,希望对大家有所帮助,如有不妥之处欢迎批评指正。

本期收录于博主的专栏——JavaSE,适用于编程初学者,感兴趣的朋友们可以订阅,查看其它“JavaSE基础知识”。
感谢每一个观看本篇文章的朋友,更多精彩敬请期待:保护小周ღ *★,°*:.☆( ̄▽ ̄)/$:*.°★*
文章存在借鉴,如有侵权请联系修改删除!