摘要
K-means算法是一种基于划分的经典聚类算法。由于该算法具有操作简单、高效性和较好伸缩性等优点而被得到广泛使用。然而该算法却存在着一些缺陷:聚类结果对聚类中心点的初始选择和用户输入的k值具有敏感性和依赖性,并容易受孤立点的影响,形成局部最优解的局面。本文主要针对K-means算法中易受孤立点的影响及对用户输入的k值依赖,对数据的初始化过程进行了改进:提出了基于网格化预处理数据算法,将数据集中的孤立点区分出来并滤除,避免了对聚类过程的干扰,并分别进行了实验验证了其可行性和有效性。
1 K-means算法的介绍
1.1 算法基本简介
聚类是无监督学习方法中重要的方法之一,是发现事物之间内在联系的重要方法。聚类分析将要分析的数据对象划分成若干类,使得同一类性质特征的差别尽可能小,而不同类内的数据对象的性质特征差别尽可能地大。而K-means算法是一个基于划分地且应用非常广泛地聚类算法,其基本原理是基于迭代来不断修正所选质心的位置。
1.2 算法的基本原理
K-means算法的基本思想很简单,即对于给定的样本集,按照样本之间的距离大小,将样本集划分为k个簇,让簇内的点尽量紧密的连接在一起,而让簇间距离尽量的大。
该算法首先在n个数据对象中随机选择k个数据对象作为k个类的初始聚类中心点(质心),然后将集合中的每个数据对象划分到距其最近的类中心所属的类,这样就形成了k个初始的聚类分布。对初次划分完的每一个类按照一定的规则(例如某种距离的度量方法)重新计算其类中心点,如果重新计算出的类中心与上个过程中的类中心点有所不同,那么将再次对数据进行重新分配,如此反复迭代,直至所有中心点位置不再发生变换,或中心点的位置小于某个阈值,则认为此时所有数据对象已被成功分类,此时准则函数收敛,算法终止。
1.3 算法的基本步骤与流程
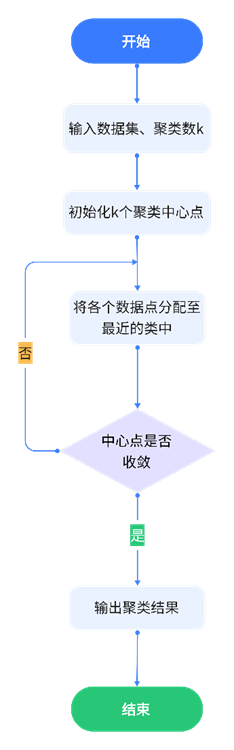
K-means算法的基本步骤如下:
Step1 从初始的数据集合X中随机选择k个初始聚类中心点c1,c2……ck作为参照。
Step2 以c1,c2……ck为初始参照点,依据以下原则对X进行初步划分:若 d i e ( x i , c e ) < d i f ( x j , c f ) d_{ie}(x_i,c_e)<d_{if}(x_j,c_f) die(xi,ce)<dif(xj,cf) , j=(1,2……k) , e≠f , i=(1,2,……k),则将xi划分到ce中,否则将xi划分到cf中。
Step3 根据公式xi划分到 c i = 1 n i ∑ x ∈ w i x c_i=\frac {1}{n_i} ∑_{x∈w_i}x ci=ni1∑x∈wix
Step4 如果对于任意的i∈{1,2,……k}, ci都能够成立,则算法终止,当前形成的ci代表最终形成的类簇。否则返回step2.一般情况下为了使step4的结束条件不能满足而无法离开循环的情况,通常会在算法中预先设置一个最大迭代循环次数或设置一个最小距离差作为阈值
Step5 输出最终聚类的结果
1.4 K-means算法的优缺点分析
优点:
① K-means算法在处理大量数据时效率相对于其他聚类算法较高,而且可以处理数值型之外的文本和图像特征的相关数据。在类间差距较大时效果很好
②对于数值形式的数据集,其几何意义和统计意义非常直观,聚类结果较好。
③对数据集形状是凸性的数据较敏感,能有效的得出分类的结果。
④由于K-means算法的迭代原因,因此如果初始中心点的选择已经很接近最终的最优结果,那么相对算法的时间消耗将会减少。
缺点:
① K-means算法中聚类个数k需要人工给定,这导致k值设定难以确定,我们只能通过不断测试调参才可能得到一个较好的分类结果。
② 聚类结果容易陷入局部最优的局面。K-means算法在聚类过程中使用误差平方和准则函数作为聚类的目标函数,且始终使误差平方和趋于减小,这有可能导致最终的收敛结果局限于局部最小值而不是全局最小值。
③ 聚类的结果受到孤立点的影响较大,因为准则函数是与各个数据点与当前中心点的距离有关,因此当出现孤立点时(尤其是随机中心点被设置在孤立点上时),会导致下一轮聚类中心迭代计算中的新聚类中心远离数据密集区域,导致较差的聚类结果。
④ K个中心点初始值的设定对最后的聚类结果会产生影响。
2.K-means算法的样例测试部分
2.1样例与数据集介绍
以下测试的数据集主要来源于
https://people.sc.fsu.edu/~jburkardt/datasets/spaeth/spaeth.html
网站所发布的公用数据集,并在其基础上手动添加了部分孤立点,最终所得的实验样例数据分布分别如下图:
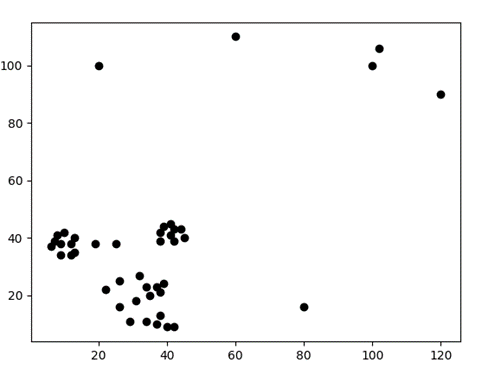
Test1:共43个数据点(如图2)
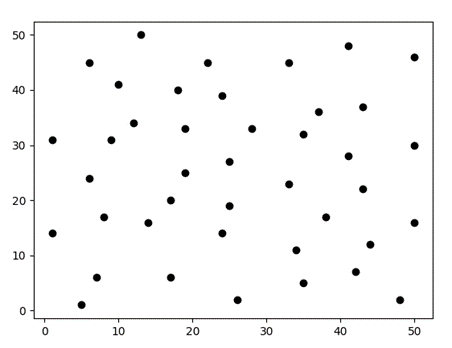
Test2:共41个数据点(如图3)
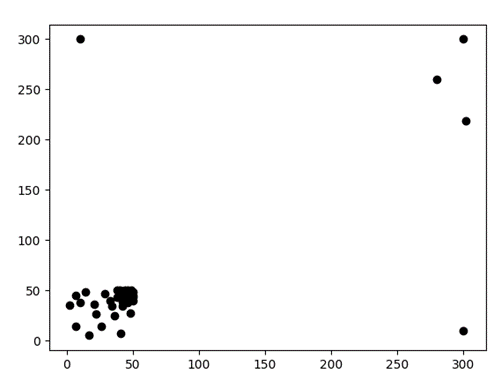
Test3:共49个数据点(如图4)
Test4:共769个数据点(如图5,图6)
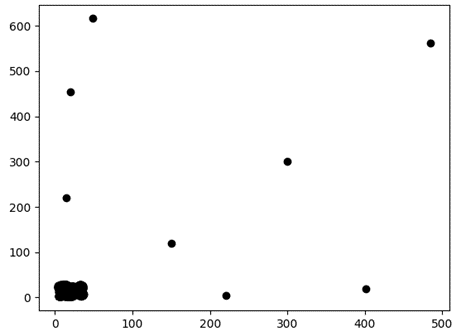
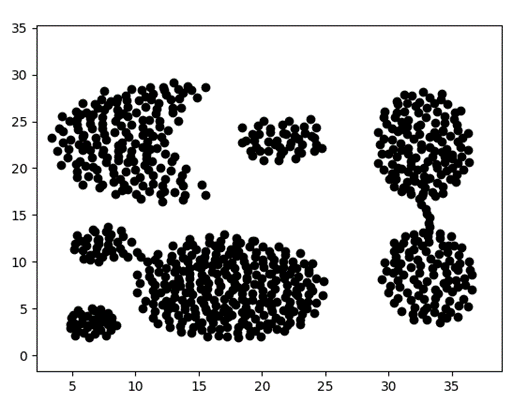
其中3535区间的数据分布如下
Test5:共2007个数据点(如图7,图8)
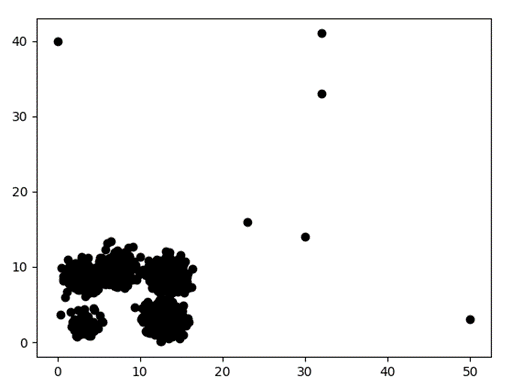
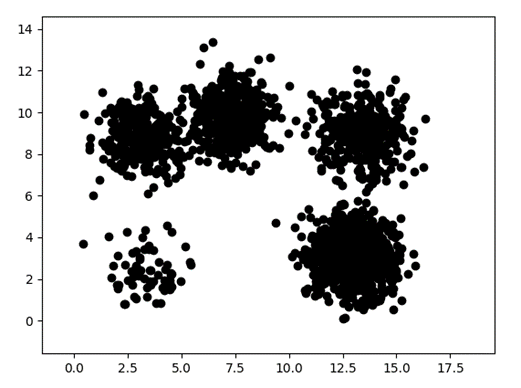
2020部分数据分布如下:
2.2 样例测试
对K-means算法的输入设置以下参数:聚类个数k和数据集。
聚类个数k=4,测试聚类结果如下
Test1:
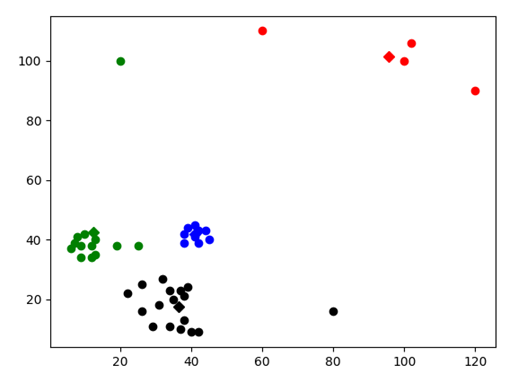
Test2:
图表 10
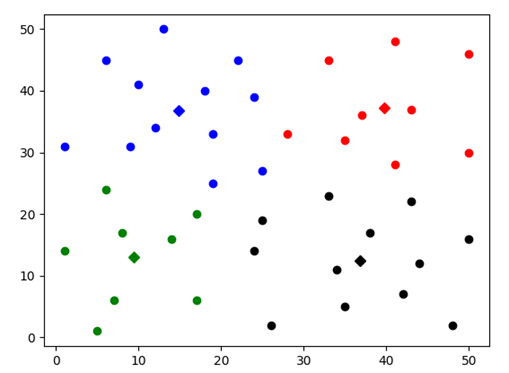
Test3:
图表 11
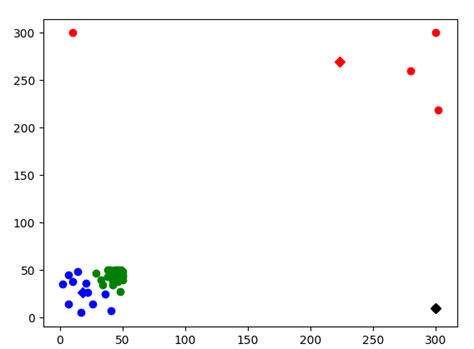
Test4:
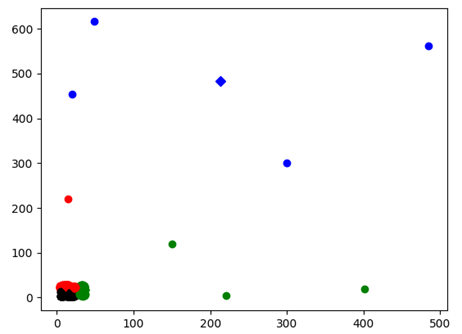
图表 12
其中35*35区间的数据聚类结果如下:
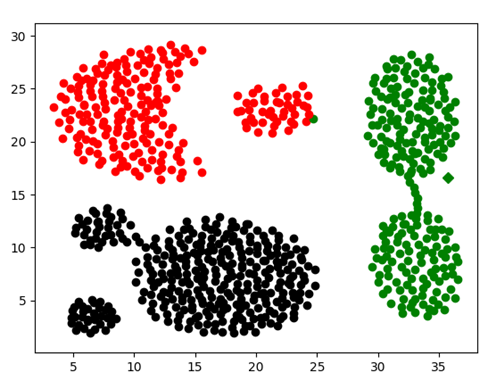
图表 13
3.K-means算法的改进
3.1 孤立点对K-means算法的影响
在数据集中,孤立点是指严重偏离数据密集区域并且不输入任何一类的数据,也称为噪声数据。孤立点的存在严重影响K-means算法的聚类结果质量。此外,由于原始的K-means算法是基于初始中心点的随机选择上实现的,所以初始中心点有可能会选到孤立点,这不仅会增加算法迭代次数,影响运算时间,还会导致较差的聚类结果。因此,提出的改进方法是通过网格化方法对数据进行预处理,而预处理的目标是从数据集中挑选出所有的孤立点,并将其删除或单独归为一类,从而去除孤立点对其他密集数据部分聚类效果的影响。
3.2 网格化的概念
为了较为直观的表示数据间的相关性关系,所有数据采用欧式距离进行相关性度量。首先对邻近网格进行定义。
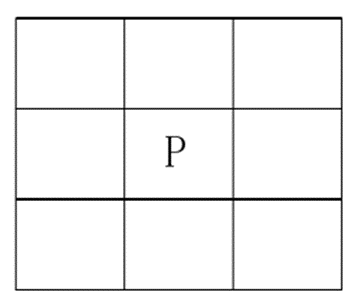
图表 14
设G (i)表示第i个网格中数据样本点的数量,网格表示的数据区间左开右闭,依据坐标轴增大的方向来划分网格线上样本数据点的网格归属问题。即d_l∈(w,v], d_l表示数据样本点di在第l维上的数据分量,w和v表示l维向量划分好后任意两个网格的边界值。因此每个数据点都会落在唯一一个网格区间内,所以可以将每个网格中的数据点进行分类。
3.3 数据点分类
所有落在网格中的数据点可按以下方式进行分类
设n为密集阈值,即规定某网格中的数据点数量如果超过n,则认为该网格中所有数据点均为密集数据点
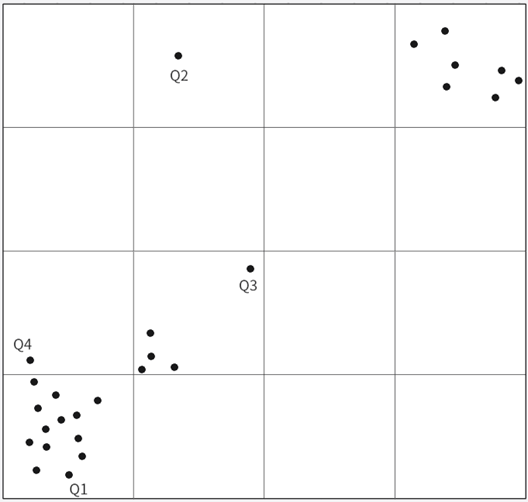
图表 15
密集数据点:若第i个网格中的数据样本点数量G(i)>n 则认为该网格中的所有数据点均为密集数据点,如Q1。
孤立点:若第i个网格中的数据样本数0<G(i) ≤n,但所在网格中实际存在的不属于任何一个数据样本类的孤立点,如Q2、Q3。
伪孤立点:若第i个网格中的数据样本数G(i)=1,但该点实际上属于某个数据样本类,如Q4。
3.4 基于网格的孤立点算法的基本原理
首先,需要确定网格的大小,由于我们希望每个网格中的数据点都恰好各成一类,因此就需要使得网格的数量应与聚类数k应尽可能接近但要大于k,因此在二维情况下可得
( t − 1 ) 2 ≤ k < t 2 (t-1)^2≤k<t^2 (t−1)2≤k<t2
n维情况下有
( t − 1 ) n ≤ k < t n (t-1)^n≤k<t^n (t−1)n≤k<tn
解的的t即为某一维度上的网格数
确定网格数后,根据各个维度上的最大值最小值确定数据分布的矩形框,并按网格数对矩形框进行均等划分。
网格划分完成后,按照3.3中数据点的分类方法,选择出所有不满足密集数据点的数据,并按算法中设定的距离方法判断该点是否为孤立点,以欧式距离为例,对于以上的数据点,对其相邻的密集点网格中的所有数据点进行遍历,找到距该数据点最近的数据点,并计算其之间的距离,若大于二分之一的网格对角线长,即
( x a − x b ) 2 + ( y a − y b ) 2 < L 2 \sqrt{(x_a-x_b)^2+(y_a-y_b)^2 }<\frac L2 (xa−xb)2+(ya−yb)2<2L
则认为该点为孤立点,反之则认为是数据密集点。此处仅对相邻的密集点网格进行遍历的原因是防止两个孤立点间距离太近相互依赖从而都不被判定为孤立点。
将孤立点存入容器中并从当前数据集中删除。根据清除孤立点后的数据重新划定矩形和网格,重复以上过程,直至找不到新的孤立点,此时预处理算法结束。
3.5 数据网格化预处理算法步骤及流程
输入:数据集D,聚类数量k,密集阈值m
Step1 根据式
( t − 1 ) 2 ≤ k < t 2 (t-1)^2≤k<t^2 (t−1)2≤k<t2
求出t,并设置一个存储容器v和计数器c
Step2 输入样本数据并根据数据极值确定生成矩形区域
Step3 将矩形区域划分为t^2形式的网格
Step4 在画好的网格中进行孤立点检测,首先按照一定的顺序搜寻G(i) ≤m的网格,然后将该网格中的所有样本数据和邻近的密集点网格中的样本数据做欧式距离运算,若该类网格中存在与待检测数据点距离之间满足
( x a − x b ) 2 + ( y a − y b ) 2 < L / 2 \sqrt{(x_a-x_b)^2+(y_a-y_b)^2}<L/2 (xa−xb)2+(ya−yb)2<L/2
那么判定该数据点不是孤立点,反之则将该数据点存入容器v并将其从当前数据集中删除,同时计数器c加一。
Step5 将本次处理结束后的c与上一轮的c进行比较,若发生变化,则返回step2,若不发生变化。则进入step6
Step6 将检测到的所有孤立点进行保存,并从原数据集中剔除,数据预处理结束。
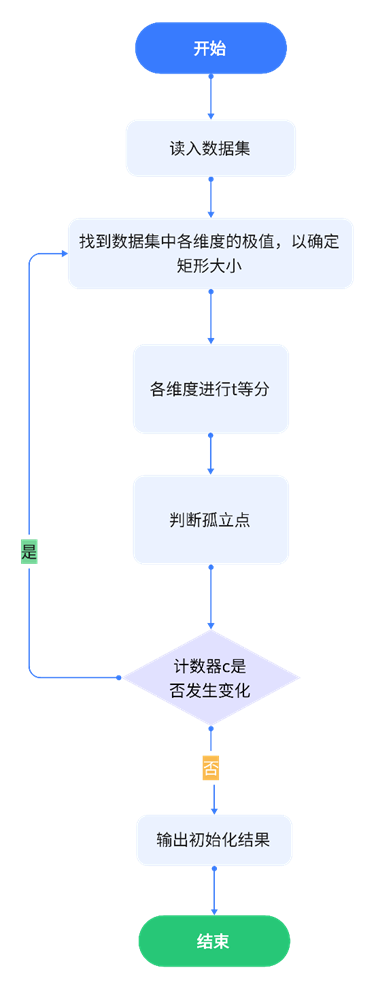
图 16 预处理算法流程图
4 算法结果测试及性能比较
4.1 聚类结果测试
现对经过预处理后的去除孤立点的数据进行Kmeans聚类,其中被标记出的孤立点用黑色五角星进行标识,设置的输入参数如下:聚类数k,数据集,密度阈值m
令k=4,m=4,对2.1中的数据进行测试,聚类结果如下
Test1
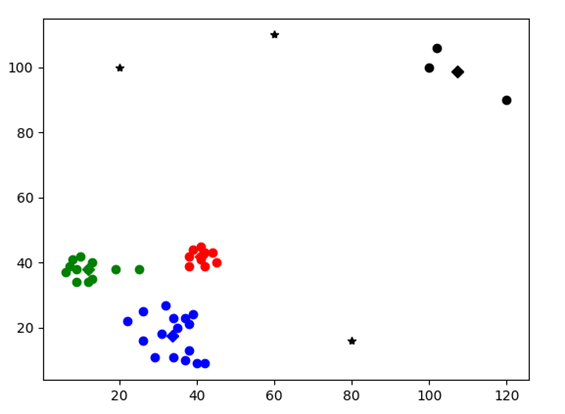
图表 17
Test2
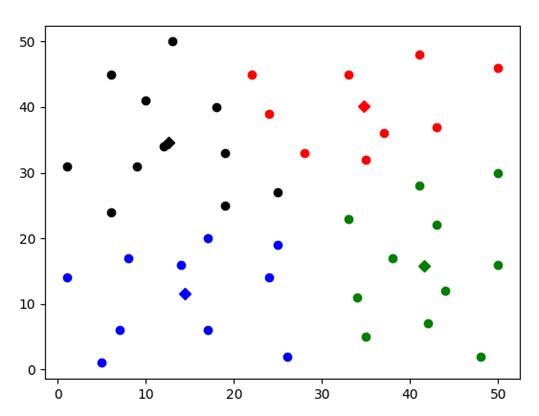
图表 18
Test3
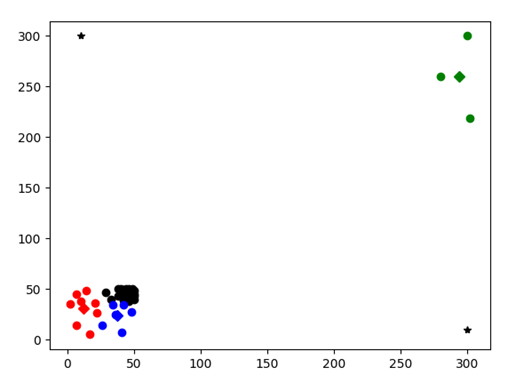
图表 19
Test4
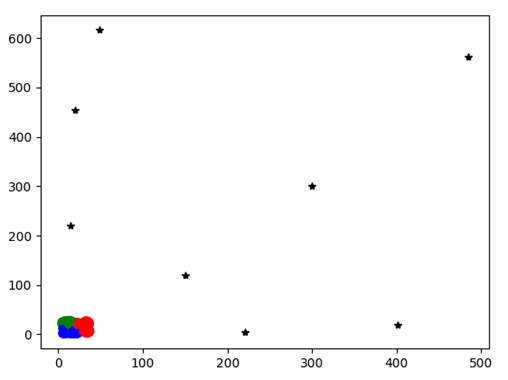
图表 20
30*30部分数据分布
图表 21
由上测试可知,经过孤立点去除后的数据聚类可以保证整体数据聚类的正确性。
4.2 DBI参数
戴维森堡丁指数(DBI),又称为分类适确性指标,是由戴维斯和唐纳德提出的一种评估聚类算法优劣的指标。
DBI参数综合考虑了类内样本相似度以及类间样本差异度 ,其值越小表征聚类有效性越高 ,假设我们有m个序列,将这些序列通过算法聚为n类,使用 DBI 聚类效果评价方法。具体定义如下:
D B I = 1 N ∑ i = 1 N max j ≠ i S i ‾ + S j ‾ ∣ ∣ w i − w j ∣ ∣ 2 DBI=\frac 1N ∑_{i=1}^{N}{\max_{j\ne i}}{\frac {\overline {S_i}+ \overline{S_j}}{||w_i-w_j||_2}} DBI=N1i=1∑Nj=imax∣∣wi−wj∣∣2Si+Sj
式中:DBI表示DBI指标值, S i S_i Si为第i类样本到其中心的平均欧氏距离 ‖ w i − w j ‖ 2 ‖w_i-w_j ‖_2 ‖wi−wj‖2为第i类和第j类的中心欧氏距离。
DBI表征的是类内距离和类间距离之比,其值越小,则其有效性越好。
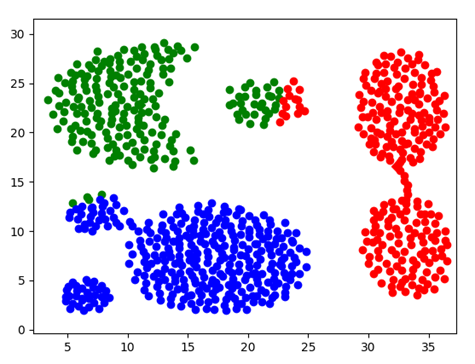
由于数据量问题,下面将针对test3和test4的数据对DBI参数进行测试。设置分类数k分别为为3,12和3,30,密集阈值m为4,结果如下
Test3(49个数据点)
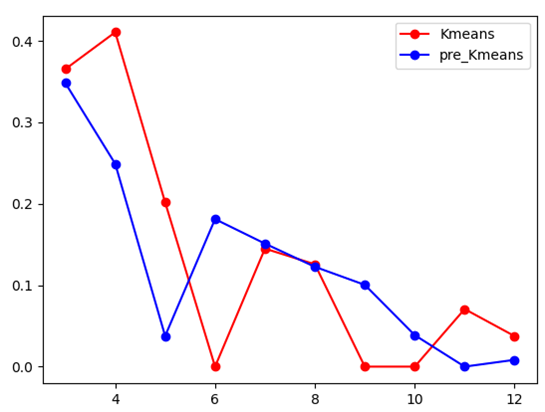
图表 22
Test4(769个数据点)
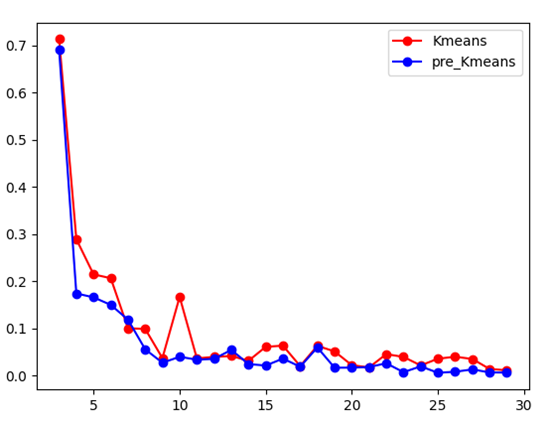
其中经过孤立点预处理的Kmeans聚类以蓝色进行表示,而未处理的Kmeans聚类以红色进行表示,由上图可知,在数据量较大时,经过孤立点去除后的Kmeans算法,在聚类效果上要好于未经处理的Kmeans算法。而在总体数据量不大时,对孤立点的预处理在聚类效果上并不是完全优于未处理的Kmeans算法,因此,对孤立点的预处理在对较大数据量时有一定优化效果。
4.3 时间性能
4.3.1 数据集说明
在时间性能的比较上,由于Kmeans算法的迭代次数与初始随机选定的中心点有很大关系,这导致了Kmeans算法的最后收敛中心的位置和用时实际上是不稳定的。因此采用一个五聚簇数据集test5(2007个数据点)。且当五个簇被正确分开时,才认为此次聚类是有效的,此时的所用时间才具有参考价值。
4.3.2 时间度量结果
聚类类数k=5
未采用孤立点预处理的Kmeans算法聚类结果图如下:
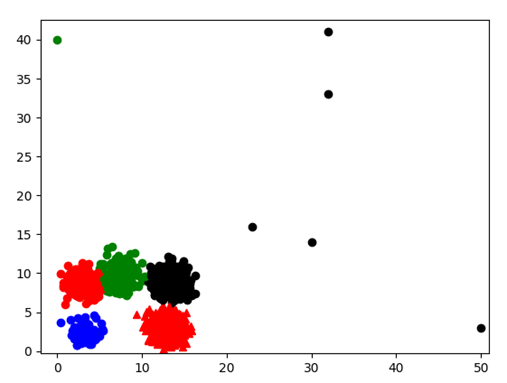
图表 23
20*20部分数据分布如下:
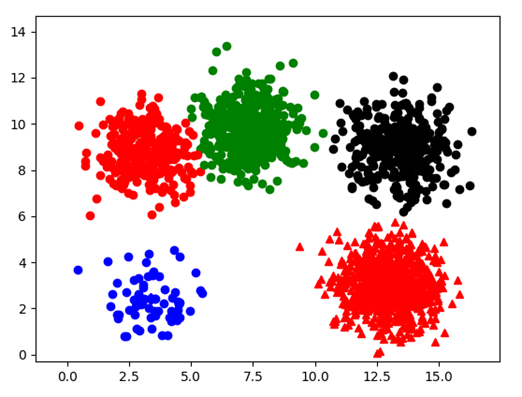
图表 24
用时:405ms
预期簇数k=5,密集阈值m=3
采用孤立点预处理的Kmeans算法聚类结果图如下:
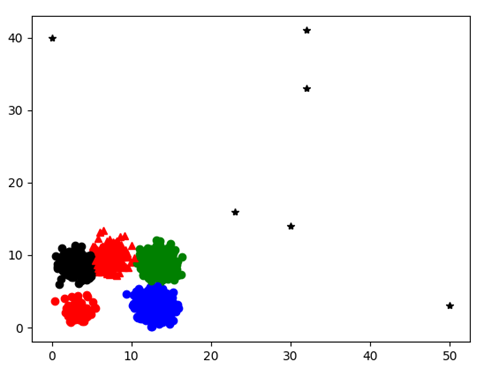
图表 25
20*20部分数据分布如下:
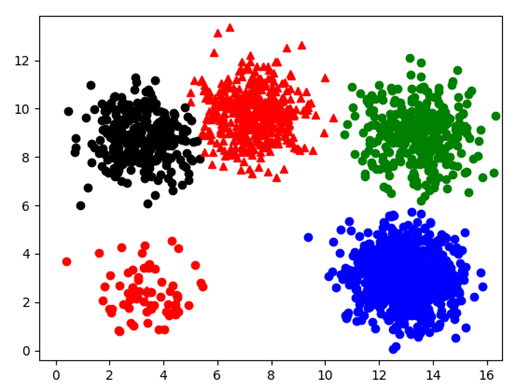
图表 26
用时:379ms
由上可得采用预处理方法的Kmeans算法比不进行处理的Kmeans算法速度稍快但相差不大。
5讨论及改进
5.1 实验结果分析
由如上实验可知,在小规模数据的聚类结果上,预处理算法在滤除孤立点后聚类所得得到的聚类结果与原Kmeans算法所得结果相差不大,但在数据量增大或孤立点的干扰作用增强的情况下,预处理算法可以滤除孤立点,从而增强聚类有效性(实验中表征为DBI减小)。
对于时间性能的分析结果上,改进后和改进前的运行时间相差并不大,这种情况的原因可能是数据集规模太小或是初始选点造成迭代次数的不稳定造成的,可以在聚类质量相近的情况下(使用带标签的数据集或针对DBI等评价参数进行衡量)多次测试来得到一个较稳定的用时结果。
此外,以预见的是,虽然对孤立点进行预处理会占用一部分时间,但针对数据规模较大的数据集或是孤立点干扰严重的数据集,提前处理孤立点可以有效的避免初始中心点落在孤立点上,从而减小迭代次数和改善中心点收敛位置,从而提高之后聚类的运算速度和质量。
5.2 思考与实现过程中出现的问题
基于网格的预处理方法中,网格的作用是为可能的孤立点提供了筛选的区间,使得判断孤立点时只需要与周边网格内的点进行比较即可,此外网格的对角线长表征了该算法对两个数据点的关联关系的判别准则,即与网格对角线长二分之一作为比较,从而判断该点是不是孤立点,因此在不断删减孤立点的迭代过程中,实际上迭代的部分就是网格的尺寸,因为每次删减过程都会导致整个数据集的极值发生变化,从而导致网格尺寸发生变化,这是一个使得对角线长逐渐减小的过程,使得在迭代中对孤立点的要求发生变化,从而逐步排除掉孤立点。
在实现算法的过程中,在相邻网格的遍历问题上,原文提到的遍历过程是只要是相邻网格内的数据点,都要参与遍历过程,但是实际上,这种遍历方法很容易造成两个孤立点之间相互干扰,从而造成都不能被去除,因此,我考虑在遍历时,只遍历相邻的密集点网格,对于非密集点的网格直接跳过即可,这样就可以只判别待检测点与密集数据之间是否存在联系,从而判断是否属于孤立点。
此外,对于类似test2这种分散的比较均匀数据,通过去除孤立点的方法并没有较好的提升效果,因为在比对中发现此类数据集在预处理时并没有孤立点可以删除,导致改进后聚类效果与改进前一致。
5.3 进一步的改进方向
①输入的参数如聚类个数k和密集阈值m需要用户进行给定而不能根据数据分布自行决定,因此应考虑找到密集阈值的最优值或确定密集阈值的函数关系
预处理算法中判断两个数据点是否有关联的准则是其距离是否小于当前网格对角线长的二分之一,但是这一准则没有理论进行支撑,可以对数据点间的关联准则进行优化
基于同样的原因,对孤立点预处理只对以欧氏距离为距离准则的数据有效,将判别方法扩展到其他距离上也可以视为未来改进的方向之一。
代码实现
https://github.com/myveibae/pre_Kmeans
参考文献及网站:
[1]刘凤芹. K-means聚类算法改进研究[D]. 山东师范大学.
https://blog.csdn.net/SeafyLiang/article/details/123102324
https://people.sc.fsu.edu/~jburkardt/datasets/spaeth/spaeth.html