
3月3日-3月5日,第12届PostgreSQL中国技术大会在杭州举行。本次大会以“突破•进化•共赢——安全可靠,共建与机遇”为主题,以线上+线上结合的方式,邀请了PG领域众多行业大咖、学术精英及技术专家,共同探讨数据库未来的发展动态、技术突破、实践案例和生态合作等话题。
HashData作为国内领先的PG技术栈实践者和重要的社区贡献者,受邀参加本次大会。来自HashData的技术专家团队,为观众呈现了云数仓发展趋势、向量化与并行化实践等精彩演讲。
在本次大会上,HashData云数仓凭借高性能、高可用、弹性伸缩、高性价比等诸多优势,在众多数据库产品中脱颖而出,荣膺“第12届PostgreSQL中国技术大会数据库最佳产品奖”。

图:HashData联合创始人马涛
数据仓库云服务的再演进
强大的功能、友好的运维要求和丰富的生态使得PostgreSQL广受欢迎。然而随着云计算的快速兴起,用户对基于云原生架构的数据仓库需求引领了行业新一代技术栈的发展。
在《数据仓库云服务的再演进》的主题演讲中,HashData联合创始人马涛从DWaaS(数据仓库即服务)技术演进、架构升级等角度阐述了云数仓未来技术发展趋势。
在马涛看来,与传统数仓相比,云数仓在搭建、使用、扩容、运维等成本方面有着显著的优势,“传统数仓用户完成扩容或者迁移,通常需要两三周的时间”。

在这样的背景下,DWaaS成为当下数仓领域的热门话题。马涛认为DWaaS应该具备配置和管理工作更简单、迅速的加载和使用数据、完善的生态系统、支持多元化数据的处理、强一致的数据管理机制、多种计算任务需求等特性。同时,还能够提供高可用系统和数据保护系统,按实际使用计费,满足用户对云计算弹性计费的预期。
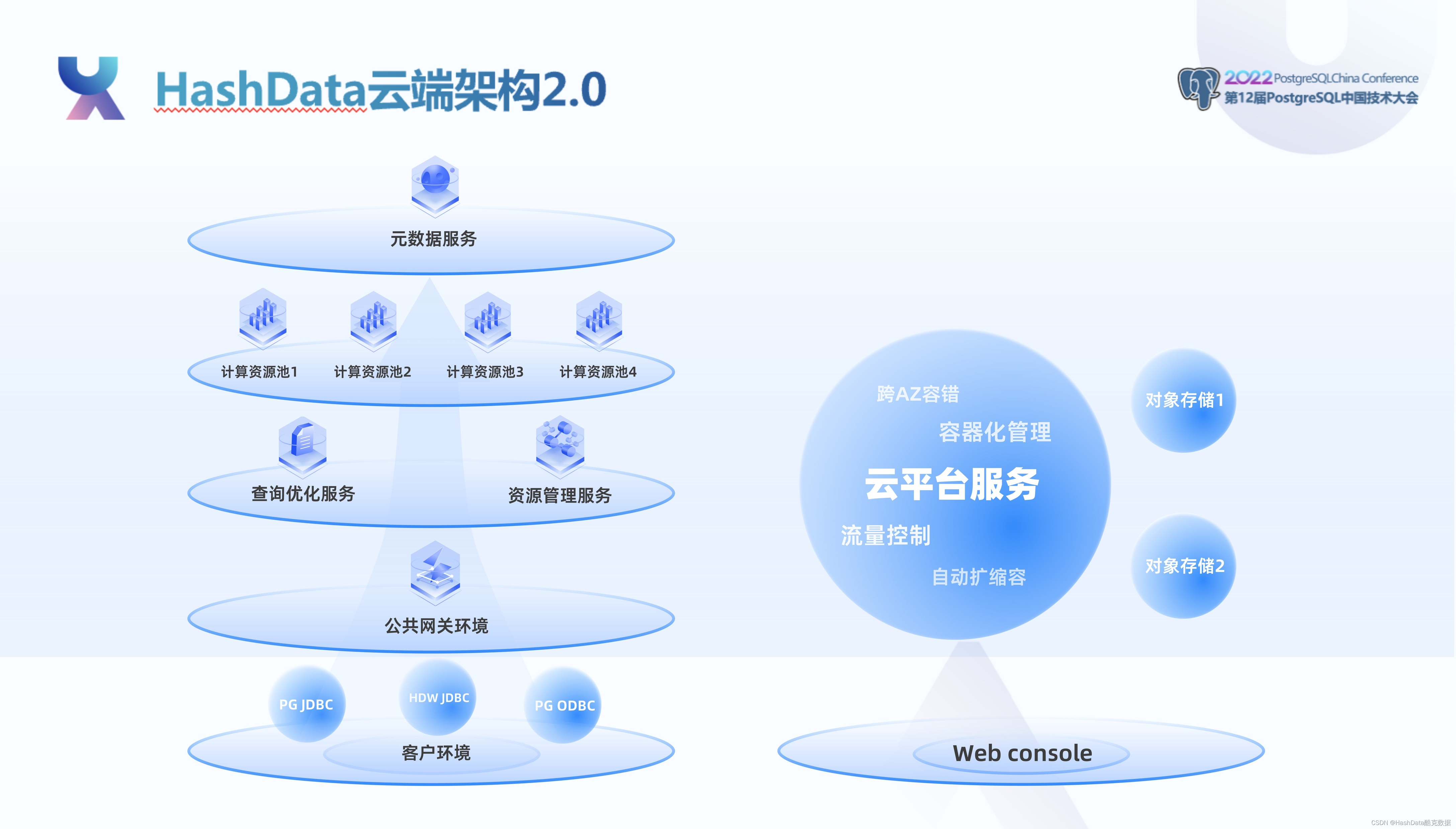
基于过去服务众多大型企业客户所积累的丰富实践经验,HashData提出了云端架构2.0的概念。与上一代云原生架构相比,HashData云端架构2.0在资源管理、查询优化、容器化服务等方面实现了全方位提升。
马涛认为,容器化服务已经成为公有云基础设施。数据库内核模块的容器化,能够充分发挥容器化技术的优势,更快地创建和启动模块,从公司内部研发测试到客户环境,都将会产生巨大的变革。HashData云端架构2.0将以容器化技术为基石,为客户带来更好的使用体验。
在网关服务方面,HashData云端架构2.0兼容PostgreSQL二进制协议,无缝与libpq/PostgreSQL JDBC等组件兼容;支持更多安全配置的HashData企业认证授权服务;支持通过SQL语句管理整个云服务;支持切换不同计算集群,更加高效地利用硬件资源,更容易实现负载均衡。
在查询优化服务/资源管理服务方面,HashData云端架构2.0中查询优化器和作业资源管理服务进一步实现无状态化,提升这两个模块在业务运行中的容错度,减少故障引起的业务中断和资源浪费。优化服务能够按照实际数据存储信息、动态执行采样,以及进行智能查询计划缓存;作业资源管理服务能够实现全局资源调度、全局资源监控和作业调度。通过将模块拆分成独立服务,有助于提高硬件的资源利用效率。
在计算服务方面,HashData云端架构2.0支持计算集群的自动启动/自动停止功能、增强无状态计算服务节点的可靠性、支持基于负载的自动扩缩容,引入了基于Arrow的向量化执行引擎,增强了对象存储文件的缓存系统。
马涛介绍,经过实际测试,原本客户从注册到实现数据库可用需要数分钟的时间,而基于HashData云端架构2.0容器化平台改造之后,整个的操作过程只需要大约10秒钟即可完成。
“从用户的实际使用需求出发,我们希望尽可能地降低用户搭建和使用数仓的时间和成本”,马涛说,HashData致力于降低数据分析的门槛,“让用户专注于核心数据分析上,而不是应对大量的配置以及管理工作。”
Cloudberry向量化与并行化实践
在“国产信创及数据库迁移”技术专场上,HashData内核工程师宋东晓分享了Cloudberry向量化与并行化实践。
近年来,随着海量数据的积累,数据分析的需求进一步提升。PostgreSQL作为一个有着悠久历史的开源数据库,其稳定性和灵活性得到广泛认可,很多企业也选择PG作为单机底层架构,来构建大型分布式系统。
传统数据库执行查询计划通常采用火山模型的方式,存在重复性执行多、反序列化代价高、数据局部性差等缺陷。如今,随着云计算技术的蓬勃发展,经典的SQL计算引擎逐渐成为数据库系统的性能瓶颈,尤其是对于涉及到大量计算的OLAP场景。
对于像HashData这样采用云架构的数据仓库而言,向量化可以通过提升单节点的执行能力,使整个集群的运算性能得到大幅度提升。
宋东晓介绍,HashData在实现向量化的过程中,采用了Apache软件基金会开源项目Apache Arrow。Arrow定义了标准的方式来表示可有效处理的内存数据,同时支持多种流行的编程语言,包括 Java、C、C++ 和 Python等。

OLAP场景普遍采用列式存储。列存数据的高压缩比不仅节约了存储空间,同时在向量化运算过程中也有着天然的性能优势。
HashData即将发布的Cloudberry产品,采用了向量化执行插件,功能更独立,工程管理更方便,实现在不影响PG功能的基础上,加速数据分析性能。同时,Cloudberry全面集成了PG14.4内核,在数据库层面做了多处优化,尤其在并行化处理能力方面实现了大幅提升。

宋东晓认为,向量化的关键在于尽可能地减少公共流程的调用次数,从而降低整体的函数调用,同时也可以更好地利用数据局部性优势来提升cache命中率,并且可以利用SIMD指令做进一步加速。
此外,Cloudberry基于Arrow和其子项目Gandiva实现了一个既可以支持普通列式运算也可以支持JIT式的表达式计算框架。
在并行化方面,Cloudberry借鉴了PG14.4内核中的共享内存技术,通过让每一个执行器的运算节点在共享内存里竞争资源来自动获得负载平衡,从而实现启动多个进程,成倍降低运算时间。
HashData荣获“数据库最佳产品奖”
中国技术大会作为PostgreSQL技术领域的年度盛事,至今已经成功举办12届,也见证了PG开源生态在中国的建立、发展和成熟。
HashData作为一款100%兼容PostgreSQL生态的数据仓库,连续多年参加PostgreSQL中国技术大会,同时一直以来以代码贡献、社区共建等方式积极参与PostgreSQL社区的发展壮大。为表彰企业创新成就,激发创新精神,大会特别设立颁奖环节,授予HashData“数据库最佳产品奖”。

HashData融合了传统数据库和云计算技术优势,兼容PostgreSQL和Greenplum Database生态,生于云上,长于云上,助力企业在云计算时代下的数字化转型。
凭借领先的技术架构和丰富的实践经验,HashData目前已在金融、政务、能源、交通、互联网等行业实现大规模商用部署。
未来,HashData将持续专注于PG领域技术创新,积极拓展生态合作伙伴,为国产数据库生态的繁荣与发展添砖加瓦。期待更多朋友与我们一道,为打造领先的基础软件不断努力!