上节课我们一起学习了Combiner的理论知识,这节课我们来一起学习一下倒排索引,那么首先我们来了解一下什么是倒排索引,如下图所示,我们可以看到表中有单词ID,单词还有倒排列表,倒排列表存放的是某个单词在第几篇文章中出现的次数,比如谷歌这个单词在第一篇文章中出现了1次,第二篇文章中出现了1次,第三篇文章中出现了2次,第四、第五篇文章各出现1次。那么倒排索引的用处是什么呢?我们以搜索引擎为例,像百度、谷歌这样大的搜索引擎商家,每天面对的数据量是百亿、千亿甚至更多,如此庞大的数据量,如何保证用户搜索时的快捷高效?这就用到倒排索引了,我们知道用户搜索东西的时候是通过输入关键词来搜索的,百度、谷歌是有自己的关键词列表的,它们先通过MapReduce建立起一个倒排索引列表,每个关键词在哪些文章中出现过以及出现过几次都可以在倒排索引列表快速找到,如此一来当用户搜索的时候便不用再去所有的文章中挨个查找了,直接便可以定位到相关的文章,这就极大的提高了查询效率,提升客户满意度。

接下来我们一起来做个倒排索引的简单的例子,假如我们现在有3个txt文件,里面存放的内容如下图所示,单词与单词之间是以一个空格分隔的。

那么根据上图的三个文件,我们想要的结果如下:
hello a.txt->3 b.txt->2 c.txt->2
tom a.txt->1 b.txt->2 c.txt->2
jerry a.txt->1
kitty a.txt->1 b.txt->1
想要得到上面的结果,一个MapReduce无法完成,我们可以通过两个MapReduce来完成也可以在Map和Reduce之间加一个Combiner做中间处理来完成,上节课我们刚学了Combiner的理论,这节我们便使用Combiner来处理。我们要想得到最终的结果,从正面推不好推,我们可以倒着推,我们以"hello"来推,最后一个Reducer输出的形式是:context.write("hello","a.txt->3 b.txt->2 c.txt->2");,那么传给Reducer的数据形式是:<"hello",{"a.txt->3","b.txt->2","c.txt->2"}>,进而我们知道mapper输出的形式是:context.write("hello","a.txt->3");context.write("hello","b.txt->2");context.write("hello","c.txt->2");。那么第一个reducer输出的形式便是:context.write("hello","a.txt->3");context.write("hello","b.txt->2");context.write("hello","c.txt->2");第一个mapper的输出就应该是context.write("hello->a.txt","1");context.write("hello->a.txt","1");context.write("hello->a.txt","1");。
通过上面的倒推过程,我们基本上知道该怎么做了,现在就通过程序来实现。关于如何创建一个Maven工程并如何配置pom.xml等内容大家可以参考:http://blog.csdn.net/u012453843/article/details/52600313这篇博客来学习。由于我们是在前面几节课的基础上学习的,我就在一个已有的sortdatacount工程下写我们的代码了。如下所示
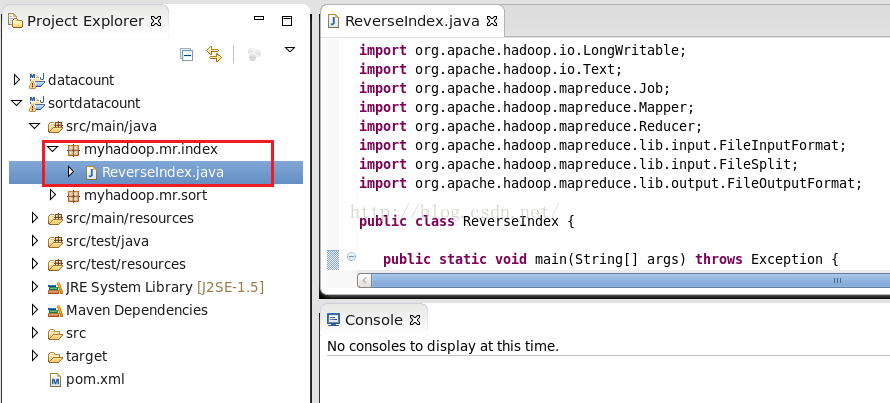
我们只需要完成一个类ReverseIndex.java即可,现在我把这个类的代码粘贴出来,如下所示
package myhadoop.mr.index;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ReverseIndex {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(ReverseIndex.class);
//将Mapper类设置到Job当中
job.setMapperClass(ReverseIndexMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
//将Combiner类设置到Job当中
job.setCombinerClass(ReverseIndexCombiner.class);
//将Reducer类设置到Job当中
job.setReducerClass(ReverseIndexReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//等待执行结束
job.waitForCompletion(true);
}
public static class ReverseIndexMapper extends Mapper<LongWritable, Text, Text, Text>{
private Text k=new Text();
private Text v=new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line=value.toString();
String[] words=line.split(" ");
//我们怎么知道文件在什么位置呢?其实我们可以通过context来获取到
FileSplit fileSplit=(FileSplit) context.getInputSplit();
//文件所在的位置
String path=fileSplit.getPath().toString();
//我们这个例子比较简单只有3个文件,还都在同一个目录下,path目录是带着hdfs路径前缀的
//为了与我们最终的想要的结果完全一致,我们把路径进行截取,我们a.txt,b.txt,c.txt有个
//共同的特点就是长度都是5,因此我们只需要截取路径最后5个字符就可以了。
String filepath=path.substring(path.length()-5);
for(String word:words){
k.set(word+"->"+filepath);
v.set("1");
context.write(k, v);
}
}
}
public static class ReverseIndexCombiner extends Reducer<Text, Text, Text, Text>{
private Text k=new Text();
private Text v=new Text();
@Override
protected void reduce(Text key, Iterable<Text> values,Context context)
throws IOException, InterruptedException {
String line=key.toString();
String[] wordAndPath=line.split("->");
int sum=0;
for(Text t : values){
sum+=Integer.parseInt(t.toString());
}
k.set(wordAndPath[0]);
v.set(wordAndPath[1]+"->"+sum);
context.write(k, v);
}
}
public static class ReverseIndexReducer extends Reducer<Text, Text, Text, Text>{
private Text v=new Text();
@Override
protected void reduce(Text key, Iterable<Text> values,Context context)
throws IOException, InterruptedException {
StringBuilder builder=new StringBuilder();
for(Text t:values){
builder.append(t+"\t");
}
v.set(builder.toString());
context.write(key, v);
}
}
}
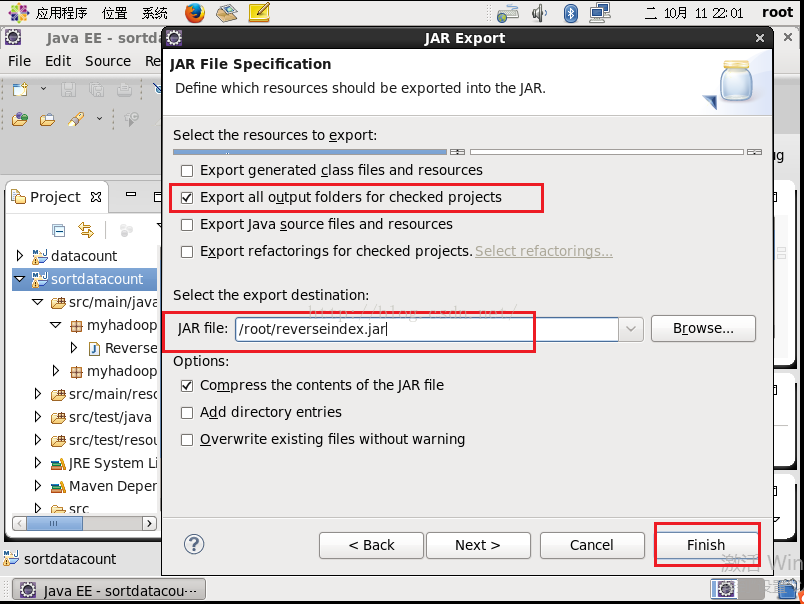
写完了代码,现在我们导出这个工程,关于具体导出的过程大家可以参考:http://blog.csdn.net/u012453843/article/details/52600313这篇博文进行学习,下面这张图是导出的最后一步,我们勾选第二个复选框,JAR file我们写上/root/reverseindex.jar,然后点击"Finish"。
导出成功后,我们到root根目录下看一下是否有我们刚才所取的名为reverseindex.jar,如下图所示,发现确实有的。

在执行这个程序之前,我们需要把数据上传到hdfs系统上,首先我们先把a.txt,b.txt,c.txt从Windows系统上传到虚拟机root根目录下,可以通过Filezilla工具来上传,如果不知道怎么使用FileZilla,大家可以参考:http://blog.csdn.net/u012453843/article/details/52422736这篇博文进行学习。上传到root根目录后,我们去root根目录查看一下是否真的已经有了,如下图所示,发现确实已经有a.txt,b.txt,c.txt三个文件了。

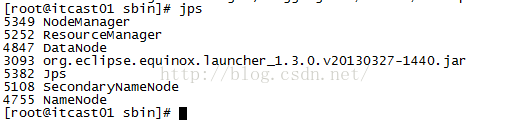
接着我们再把这三个文件上传到hdfs系统上,在上传之前需要先检查hdfs和yarn是否都已经启动起来了,如果没有启动的话,需要先启动它们,关于它们的启动大家可以参考:http://blog.csdn.net/u012453843/article/details/52433457这篇博客进行学习。当我们使用命令jps后如果可以看到NodeManager、ResourceManager、DataNode、SecondaryNameNode、NameNode说明所有的进程都正常启动起来了。如下图所示。
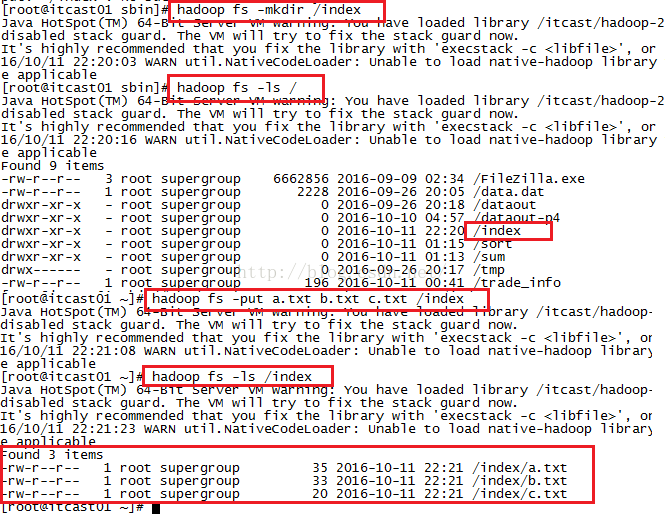
现在我们开始将a.txt,b.txt,c.txt文件上传到hdfs系统根目录下的index文件夹下,在上传之前我们需要现在hdfs系统根目录下新建一个index文件夹,使用命令:hadoop fs -mkdir /index
创建成功后,我们通过命令hadoop fs -ls /来查看一下hdfs系统根目录下是否有index文件,发现确实是有的,然后开始上传文件,我们三个文件一起上传,使用命令:hadoop fs -put a.txt b.txt c.txt /index来实现上传,上传完后我们进入到hdfs系统的index目录下,看看是否有我们刚才上传的文件,发现是有的,如下图所示。
准备好了一切,我们开始执行jar,命令是:hadoop jar reverseindex.jar myhadoop.mr.index.ReverseIndex /index /reverseindex,执行成功之后我们看看reverseindex目录下生成了哪些文件,发现有两个文件,其中part-r-00000文件便是生成的结果文件,我们使用命令:hadoop fs -cat /reverseindex/part-r-00000来查看文件的内容,发现里面确实是我们想要看到的结果,如下图所示。

好了,至此我们本小节课便一起学习完了。