week还有一些遗留问题 一起来看一下
工作量证明 Proof of work
区块链其实就是一个基于互联网去中心化的账本,每个区块相当于一页账本,它记录了交易内容。因为比特币是一个去中心账本,会引发记账一致性问题。一致性问题就是所有的区块,记账内容可能不一样。
在比特币系统中,每一个节点都要保存一份完整交易信息。但是应为每个节点的环境不同,会接受到不一样的信息,如果同时记账,会导致账本不一致。因此我们需要找出一个代表帮我们记账,然后内容分享给其他节点,比特币中通过竞争记账的方法解决记账系统的一致性问题。
在比特币系统中,大约每10分钟进行一轮算力竞赛,竞赛的胜利者,就获得一次记账的权力,并向其他节点同步新增账本信息。因此在比特币中,中本聪设定了只要完成记账的节点给予一定的比特币作为奖励,因此大家把记账形象的称为“挖矿”。
那么怎么判断竞争胜利(记账成功)呢? 中本聪采用了一个PoW(工作量证明)算法来进行判断。工作量证明,顾名思义就是提供一个工作多少的证明。那么这个证明是怎么来的呢?
说工作量证明怎么来之前我们先说下Hash算法,Hash算法有一个特性:通过hash加密的文本或文件,哪怕只有一个字节改变,Hash的值就完全不相同。在区块链中,需要找出一个Nonce,Nonce的值和区块上的信息拼接后进行hash计算,当hash值满足给定条件,第一个找出nonce的节点获得记账权。这个找Nonce值计算Hash值的过程就是工作,找到满足条件的Nonce值就是证明。
举个例子 ,假设我们区块上的信息是 blockchain ,我们要找出一个Nonce随机数和blockchain拼接,最后计算的Hash值结果以6个0开头,率先找到随机数的节点就获得此次记账的唯一记账权。
具体细节请看下方视频讲解 生动且形象
工作量证明 - 如何证明你的工作很卖力_哔哩哔哩_bilibili
数字签名 Digital Signatures
基本概念:
私钥:只有自己知道的钥匙。
公钥:与自己私钥配对的可以公开给别人的钥匙叫公钥。
用私钥加密的数据只能用公钥解密,用公钥加密的数据只能用私钥解密。
数字签名:
作用:(数字签名的作用是验证文件是否被恶意修改过)
先对要发送的文件用hash算法生成极小的一段话,这段话叫做message digest(消息摘要)。然后对消息摘要用私钥加密后生成的文件就叫数字签名。
具体流程:
1、发送者将编辑好的文档(后称为‘原始文件’),通过哈希算法生成一个只包含一两行数据的报文,这个报文称为“消息摘要”(由于哈希算法是不可逆的,所以通过消息摘要无法还原原始文件内容);
2、发送者通过软件用自己的私钥给“消息摘要”加密,生成的结果就是数字签名。(注意不是给源文件加密,是对消息摘要也就是哈希结果进行加密)
3、发送者把原始文件和数字签名打包发给接收者。 接收者收到数据后,按照如下方法验证文件是不是发送者本人编辑的原始文件
1、用发送者的公钥解密数字签名,得到的结果是“消息摘要”(此步骤如果成功,能确定文件的发送方确实是发送者本人,因为数字签名是通过私钥加密的,他的私钥只有他自己知道,别人无法伪造,公钥是对外公开的,所有人都可以知道)
2、对于收到的文件使用与发送者相同的哈希算法生成一个只包含一两行文本的数据报文,也就是“消息摘要”;
3、对比1、2两步得到的“消息摘要”是否是完全一样,如果完全一样,说明该文档是原始文档。
数字签名这么麻烦为什么要使用它呢?考虑一下,这种情况,你从网上下了一个播放器软件,但是安装后才发现他不是播放器,是一个病毒。在软件行业中这种冒名顶替的事常有发生,通过数字签名可以确保你下载的软件确实是你需要的软件,而不是病毒,或者被人修改过的软件。这也就是微软为什么给自己的软件提供SHA1值的原因。
具体可以看下方视频讲解 生动且形象
智能合约 Smart Contracts
“智能合约” 是:一种计算机协议,是以数字方式促进、验证或执行合同的谈判或履行。智能合同允许在没有第三方的情况下进行可信的交易。“智能合约”是区块链的核心技术之一。
“智能合约”就好比生活中常见的自动售货机,它也是一个智能合约系统,用户选择商品,完成支付后,售货机自动吐出商品(你完全不需要考虑是否需要担保,因为这是系统自动设定好的程序);再比如信用卡自动还款也是一个智能合约,设置好自动还款方式以后,到期自动扣款。
再举个例子:
假设你从我这里租了一套公寓。你可以通过区块链,用加密货币支付。您会收到一份包含在我们虚拟合同中的收据;我给你可以进入这个房间的数字密码钥匙,钥匙会在指定日期前到你手中。如果密钥未按时寄出,则区块链将释放退款。如果我在租车日期之前寄出钥匙,该功能将在日期到来时将其释放给您和我。系统工作在If-Then的前提下,由数百人见证,因此您可以完全放心的进行这次交易中。(如果我把钥匙给你,你就一定会给我钱。如果你发送一定数量的比特币,你就会收到钥匙。过了时间文件就会自动取消,由于所有参与者都能看到这次交易的信息,所以我们任何一方都不能在对方不知情的情况下对代码进行修改)
具体可以看下方视频讲解 生动且形象
以上几个问题为week1的遗留问题,接下来我们进入week2的复习
Lecture 02
问题的引出
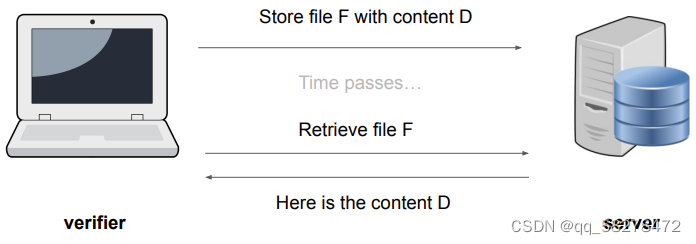
如上所示,客户端想要在服务器上存储一个名为F的文件,该文件的内容是D。
当过了一段时间之后,用户检索文件F,当然服务器就会返回给用户文件F中对应的内容。
What if server is corrupted and returns D’ != D?
就比如说你存到百度网盘上一个文件,过一段时间你要去你的网盘找这个文件,但是如果这个时候网盘把你的内容篡改了咋办(正常情况是不会的,但是如何保证你存档的内容,过很长时间不被篡改呢)
由此引出这堂课要学的内容
方法一 利用哈希
你把源文件进行一次hash 得到hash(D), 然后你需要把这个结果一直一直的保存,然后你把这个文件上传服务器帮你存着,等你需要的时候,你把这个文件D‘下载下来,然后在做一次hash得到hash(D'),如果和你之前记得值能对上,那就说明人家服务器没有篡改你的文件。反之就是修改了。
方法二 利用数字签名
1 你把源文件上传之前,先用算法产生一对私钥公钥,用私钥对你的文件进行签名σ
2 把你的文件和你的签名一起上传到服务器
此时服务器储存着你的文件F,F对应的数据D,以及你上传的数字签名σ
一段时间过去了....
你上你的网盘去下载你之前传的文件D'以及你上传的签名σ’
此时我们采用验证算法输入D’,σ‘,以及公钥,如果验证算法是True就说明我们的文件和签名都没被篡改。
但是要验证这两种情况下的证明,客户端必须下载整个文件,因此引出今天的重头戏了Merkle Trees
默尔克树 哈希树 Merkle Trees
Merkle Tree,通常也被称作hash Tree,顾名思义,就是存储hash值的一棵树。Merkle树的叶子是数据块(例如,文件或者文件的集合)的hash值。非叶节点是其对应子节点串联字符串的hash。
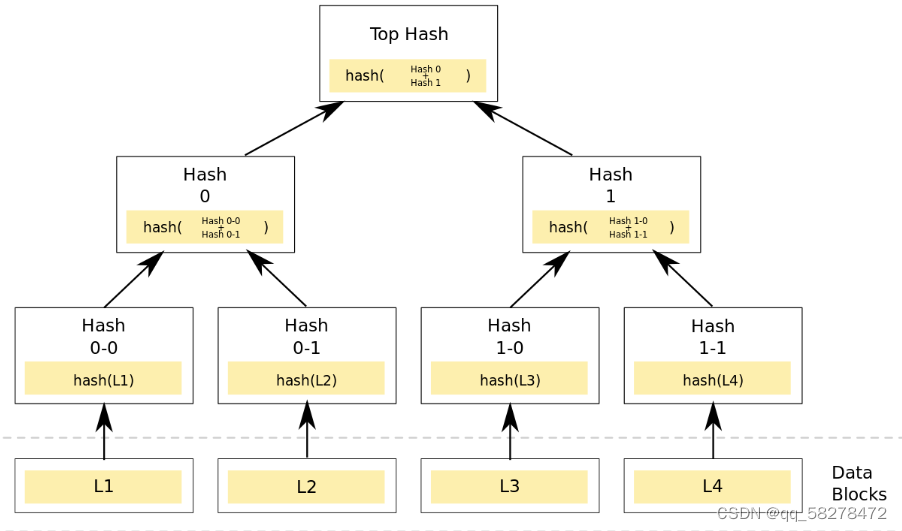
在最底层,我们把数据分成小的数据块,有相应地哈希和它对应。但是往上走,并不是直接去运算根哈希,而是把相邻的两个哈希结果合并成一个字符串,然后运算这个字符串的哈希,这样每两个哈希就结婚生子,得到了一个”子哈希“。于是往上推,依然是一样的方式,可以得到数目更少的新一级哈希,最终必然形成一棵倒挂的树,到了树根的这个位置,这一代就剩下一个根哈希了,我们把它叫做 Merkle Root。
如何理解Merkle树中的节点?
叶节点:在二叉树中,没有子节点的节点称为叶节点,这是初始节点,对于一个区块而言,每一笔交易数据,进行哈希运算后,得到的哈希值就是叶节点。
中间节点:子节点两两匹配,子节点哈希值合并成新的字符串,对合并结果再次进行哈希运算,得到的哈希值,就是对应的中间节点,这是过程节点。
根节点:有且只有一个,叫Merkle Root,这是终止节点。
将文件分割成若干个小块,并使用加密哈希函数对每个块进行哈希。之后将它们组合成二叉树,之后的父节点存储其子节点的字符串的散列 具体可以看下方视频讲解 生动且形象
梅克尔树 - 发现数据篡改的有效手段_哔哩哔哩_bilibili
这就是方法三:利用Merkle树
client客户端这边只需要存放Merkle树的根即可,当server给我们文件的时候我们只需要获取server文件构成的Merkle树的根即可。然后比较存放之前文件的根和server返回给我的根,如果两个根一模一样说明文件没有被篡改,如果两个根不一样,那么就说明文件的内容有被篡改。
用这种方式我们不需要获取整个文件,我们要获取多少文件呢?
接下来,看一个例子:

这个例子是,用户把文件等分成了8分,并且把这个文件存到了server上,用户保留了源文件这8块构成Merkle树的树根,一段时间过去了,用户像server请求第5块数据内容,我们把源文件第5块的内容记为e,把一段时间后server返回的第五块内容记为E,我们的目的就是要验证E是否等于e。
这个很好判断,只需要看E构成的Merkle树树根和之前的Merkle树树根是否一样就可以,我们要做到这个事情只有E是不够的,之有E无法算出树根。
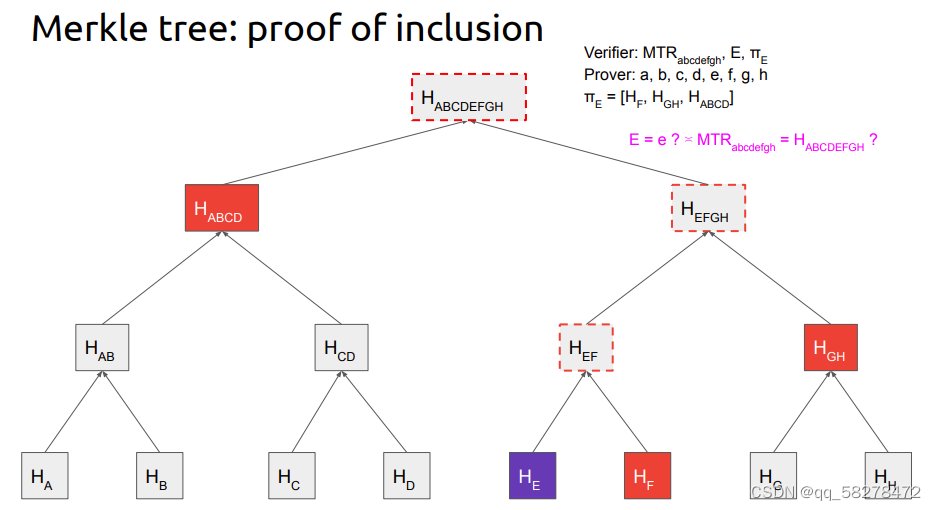
有了E我们可以算出来hash(E),如果想知道根的hash值,我们就要像Server请求Hash(F)的值,知道了Hash(F)我们就可以计算出Hash(EF)的值,这个值直接计算就好不需要server提供,接下来我们要像server获取Hash(GH)值,与Hash(EF)的值一起hash求出Hash(EFGH),此时还需要像server请求Hash(ABCD),此时就可以和Hash(EFGH)一起计算出根的值了。回顾此过程我们只像Server获取了Hash(F),Hash(GH),Hash(ABCD),并没有获取整个文件就可以看E是否被修改。由此可以看出该方法的复杂度为O(log2D) (D为块的数量,本例子中分成了8块,D为8)。
利用Merkle树存储集合(set)而不是列表(list)
Set(集):集合中的对象不按特定方式排序,并且没有重复对象。它的有些实现类能对集合中的对象按特定方式排序。
List(列表):集合中的对象按索引位置排序,可以有重复对象,允许按照对象在集合中的索引位置检索对象。
利用Merkle树存储集合(set)存在一些问题,集合(set)中的对象不按特定方式排序,因此任意两个元素位置发生了变化就会导致Merkle树树根发生变化,就没办法验证集合set中的元素是否被篡改。
老师提出了一种对策,就是把set中的元素进行排序,如果这样做,就可以得到一个很好的列表list
至于按什么进行排序不重要,只要有顺序,把这个顺序固定住就行,这样就和list一样都有顺序了。
如何证明一个元素不在set里?
set里面的元素都是已经排序好的了,假设我们有1234568这几个元素,我们想证明6不在set里面,首先要找到这个元素6最邻近的两个数,一个比他大一个比他小,那这里就是找到5和8,找到之后我们还需要证明5和8是两个邻居在Merkle树里挨着就行。

Trie树 (字典树)
什么是Trie树
Trie树,即字典树,又称单词查找树或键树,是一种树形结构。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是最大限度地减少无谓的字符串比较,查询效率比较高。
Trie的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
它有3个基本性质:
-
根节点不包含字符,除根节点外每一个节点都只包含一个字符。
-
从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
-
每个节点的所有子节点包含的字符都不相同。
● Initialize: Start with empty root(初始化就记住根节点是空的不存东西)
● Supports two operations: add and query (支持两种操作添加和查询)
● add adds a string to the set(添加就是添加新的string进来)
● query checks if a string is in the set (true/false) (查询就是看某个字符串在不在我字典树里)
大部分情况下trie树存放的是字符串
添加add
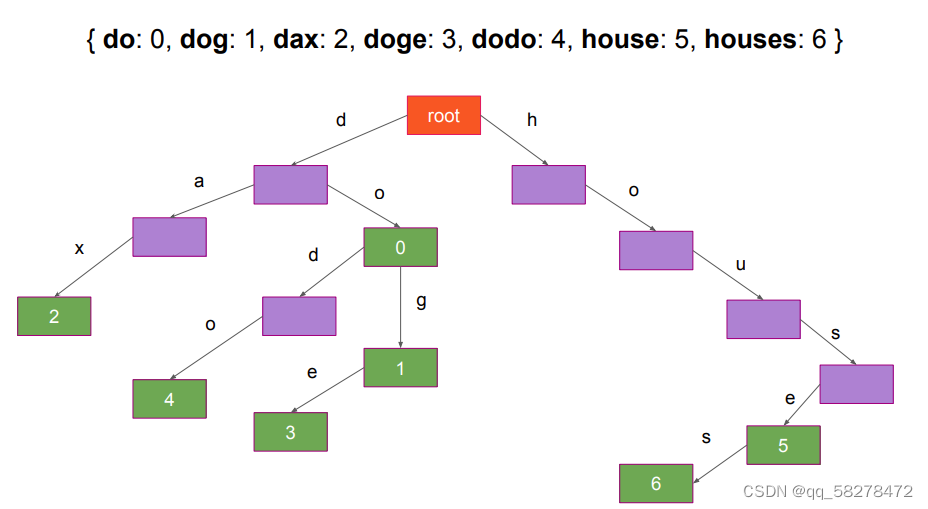
Tries: add(string)
● Start at root (从根开始加)
● Split string into characters (把字符串要分成一个一个字符apple分成‘a','p','p','l','e')
● For every character, follow an edge labelled by that character(按着边去找字符)
● If edge does not exist, create it (有这个字符的边就往下走看下一个字符,没有就自己创建一个边)
● Mark the node you arrive at(标记一下,最后到达的点,老师用绿色框标记了)
具体看下这个例子,一看就会
查询query
● Start at root (从根节点开始查)
● Split string into characters(也是把要查的字符串转字符)
● For every character, follow an edge labelled by that character (沿着每个字符找边)
● If edge does not exist, return false (如果哪个字符的边没有,直接返回false)
● When you arrive at a node and your string is consumed, check if node is marked(最后还要检查一下是不是被标记)
○ If it is marked, return yes (and marked value) (标记的话才能说明有)
○ Otherwise, return no
上述的Trie树有些冗余,因此可以将某些节点进行合并,具体直接看图就明白了。
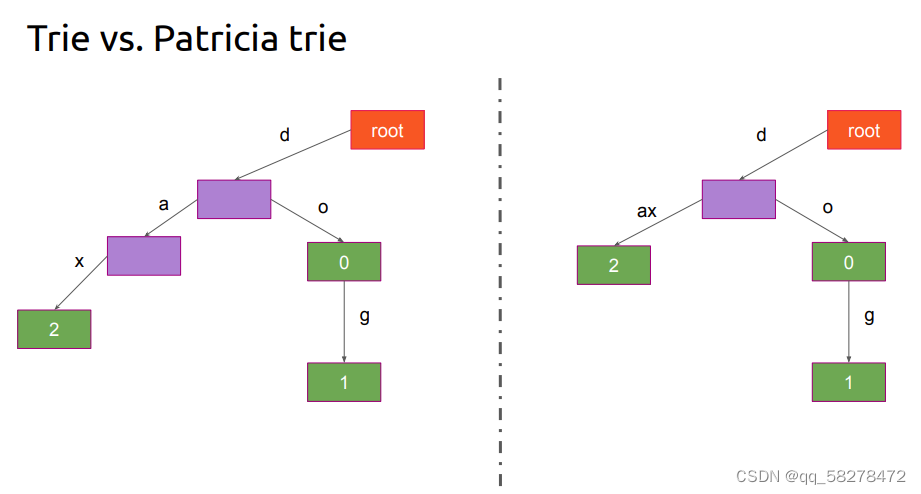
上图经过合并之后结果如下:

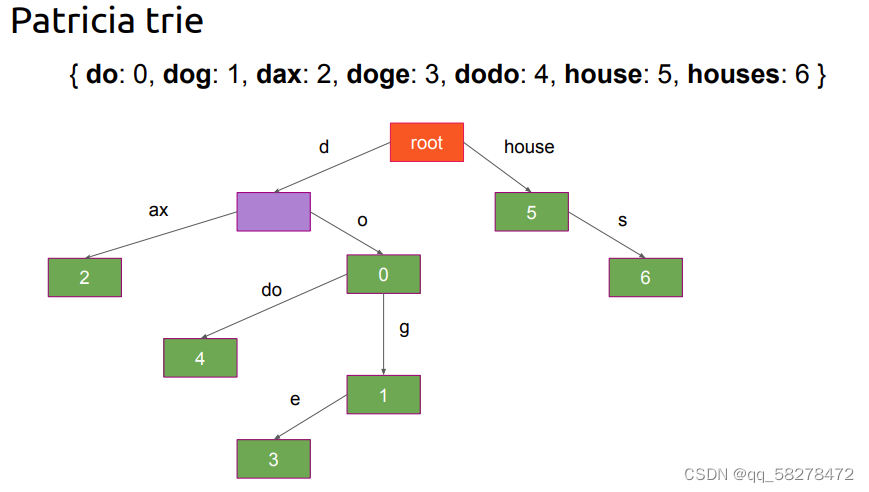
Merkle Patricia Tree(梅克尔帕特里夏树)
Merkle Patricia Tree(又称为Merkle Patricia Trie)是一种经过改良的、融合了默克尔树和前缀树(字典树)两种树结构优点的数据结构,是以太坊中用来组织管理账户数据、生成交易集合哈希的重要数据结构。是以太坊中的一种加密认证的数据结构。
以太坊是什么?与比特币的关系是什么?区别是什么?
以太坊是一个可编程、可视化、更易用的区块链,它允许任何人编写智能合约和发行代币。就像比特币一样,以太坊是去中心化的,由全网共同记账,账本公开透明且不可窜改。与比特币不同的是,以太坊是可编程的区块链,它提供了一套图灵完备的脚本语言,因此,开发人员可以直接用C语言等高级语言编程,转换成汇编语言,大大降低了区块链应用的开发难度。类似于安卓系统,提供了非常丰富的API 和接口,让用户可以开发出各种APP。从诞生到现在,有200多个以太坊应用诞生,俄罗斯银行也与以太坊基金会达成合作,截止目前(2018年1月)以太坊市值仅次于比特币排行第2位
如果说比特币是区块链1.0时代的王者,那么以太坊就是区块链2.0的开创者。
举个不恰相当的例子,比特币就好比老式的手机,不能安装第三方应用;以太坊就好比现在的安卓系统,用户可以根据以太坊网络开发各种去中心化应用程序。
以太坊(ETH)与比特币,这两者背后区块链系统的方向完全不同。比特币的定位就是单纯的数字货币,可以被认为是一种点对点的电子现金。它是为了取代法币、解决金融危机而诞生,主要应用于付款和价值转移。所以比特币背后的整个区块链网络方向都是以货币为主,解决交易、支付问题。而ETH则不同,它虽然也是数字货币,具备一定的交易属性,但是ETH背后的以太坊区块链网络定位是世界级的通用计算平台,它只是借用比特币中的区块链技术,以此为基础,朝着偏向于互联网的操作系统级应用方面发展。大家可以通过以太坊创建智能合约和构建去中心化应用程序。主要解决了信任、安全等问题。所以以太坊不是单纯的是数字货币,更像是一个互联网的操作系统平台,不仅具备交易资产的属性,还有它的服务价值。
在比特币区块链网络中,起到数据维护作用的共识机制是PoW机制,即工作量证明机制。它的工作原理是,大家一起参与,谁处理得最快最好,谁就能获得记录数据的权力,进而获得比特币奖励。因为比特币的应用方向是货币,使用场景是没有中心化机构参与的点对点支付与交易,所以,比特币就强烈地需要去中心化与安全这两个属性,而PoW机制虽然处理交易的速度过慢,而且需要花费大量的资源,但是安全性和去中心化程度极高,故此与比特币契合。而以太坊所采用的是PoS共识机制,即权益证明机制,它的工作原理是,大家一起参与,谁持有的以太币多,谁就越容易获得记录数据的权力,进而获得ETH奖励。以太坊的应用方向是操作系统,它是想让大家在它的系统上部署智能合约、开发去中心化应用。以太坊虽然也需要去中心化的属性,但是比起比特币,它更需要高效率与低成本,不然你平台数据处理的效率过慢,手续费还高,谁愿意在你的平台上开发?所以,以太坊就采用了PoS机制,PoS的去中心化性虽然没PoW机制强,但是效率更快,处理数据也不需要花费非常大的资源。
Merkle Patricia Tree
Merkle Patricia Tree 融合了默克尔树和前缀树(字典树)两种树结构优点,有默克尔树优点可以验证完整性,看数据是否被篡改,而且还有前缀树(字典树)的优点,看某个元素是不是在或者是不是不在,还可以add,query。
节点类型
叶节点:表示为 [ key,value ] 的一个键值对。key是16进制编码出来的字符串,value是RLP编码的数据;

扩展节点:也是 [ key,value ] 的一个键值对,但是这里的value是其他节点的hash值,通过hash链接到其他节点
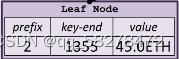
分支节点:因为MPT树中的key被编码成一种特殊的16进制的表示,再加上最后的value,所以分支节点是一个长度为17的数组。
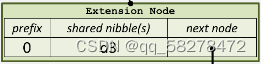
【prefix】prefix是一个4bit的数值,用来区分扩展节点和叶子节点。因为扩展节点和叶子节点的数据结构类似,所以需要进行区分。其中第三位为节点标记,如果是0则表示Extension Node,如果是1则表示leaf Node。
深度解读ppt中的图,小黄带你读懂它 非常简单 借用了知乎一位大佬做的图
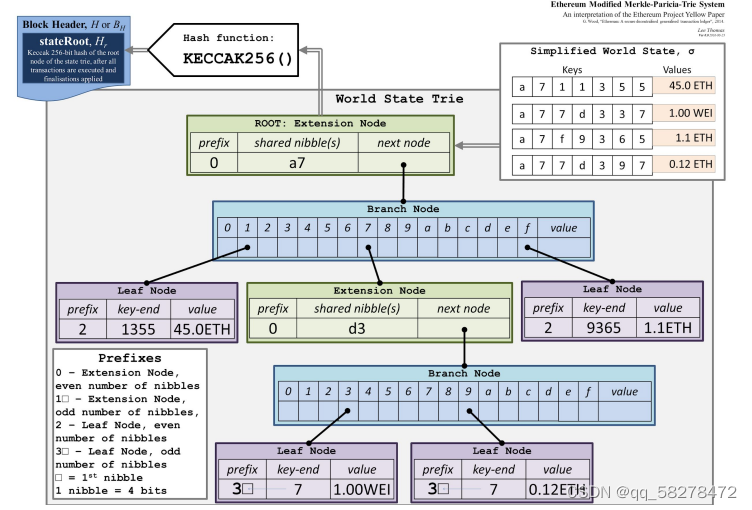
这是一个非常经典的图,好多教程都有这个图,我们一起看一下这个图。图的
右上角是我们要存入的数据有key还有对应的values
key | values ---------------------- a711355 | 45.0 ETH a77d337 | 1.00 WEI a7f9365 | 1.1 ETH a77d397 | 0.12 ETH
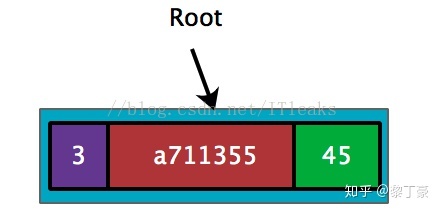
插入第一个<a711355, 45>,由于只有一个key,直接用leaf node既可表示
接着插入a77d337,由于和a711355共享前缀’a7’,因而可以创建’a7’扩展节点。
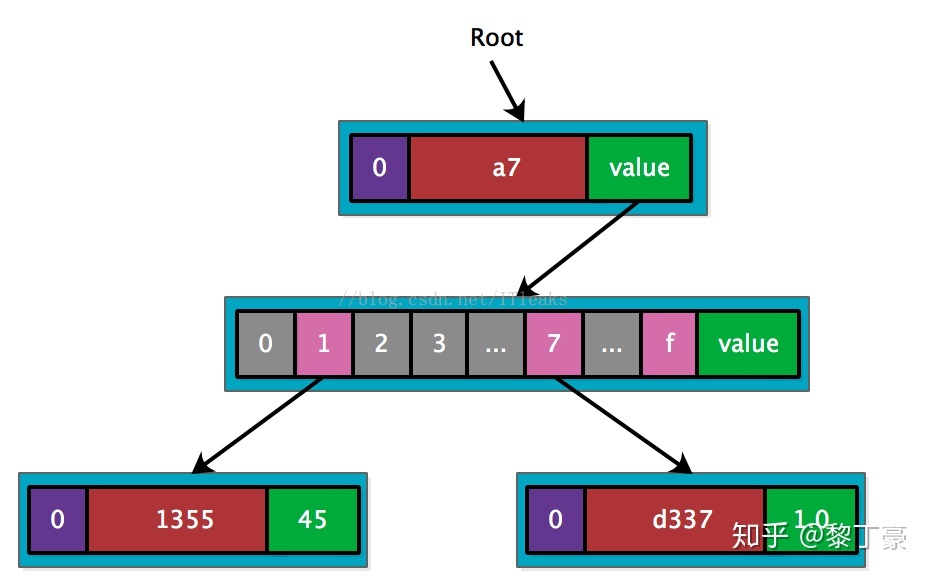
接着插入a7f9365,也是共享’a7’,只需新增一个leaf node.
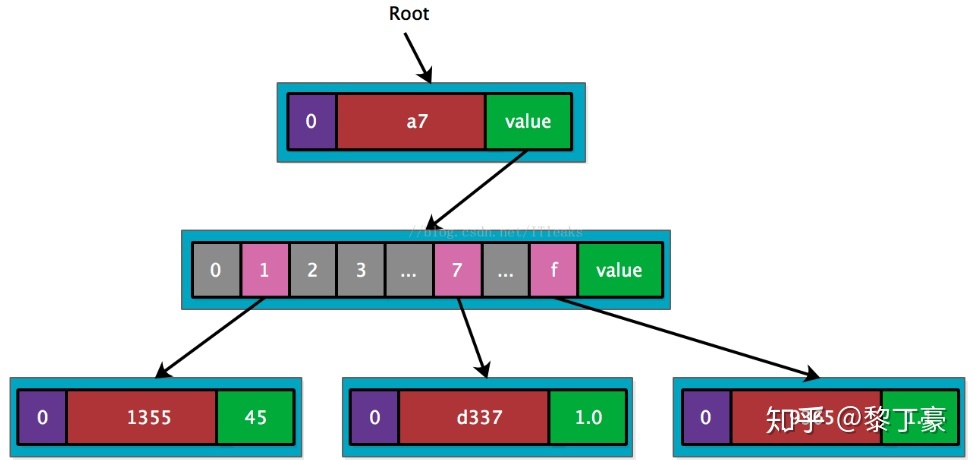
最后插入a77d397,这个key和a77d337共享’a7’+’d3’,因而再需要创建一个’d3’扩展节点
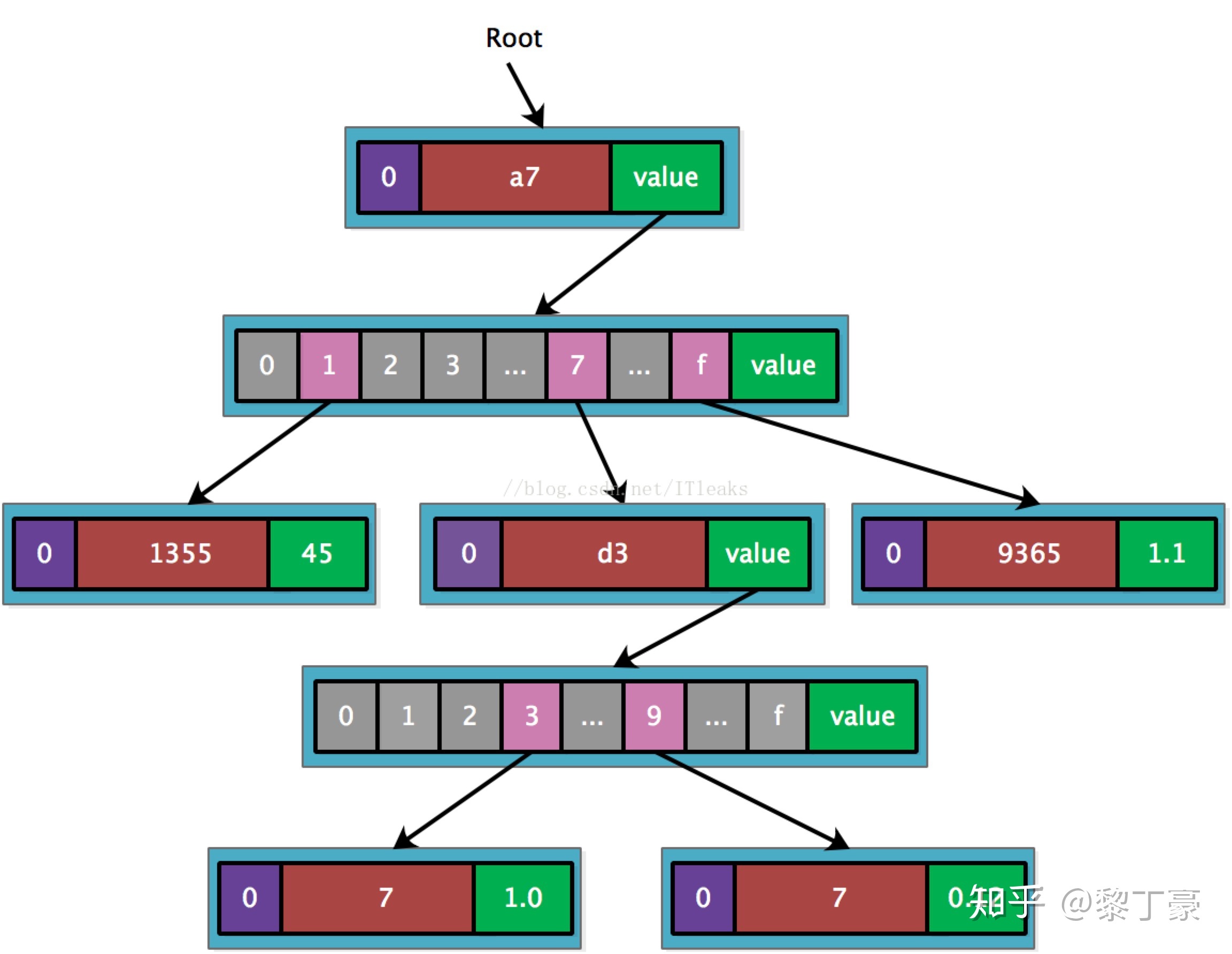
将叶子节点和最后的short node合并到一个节点了,事实上源码实现需要再深一层,最后一层的叶子节点只有数据
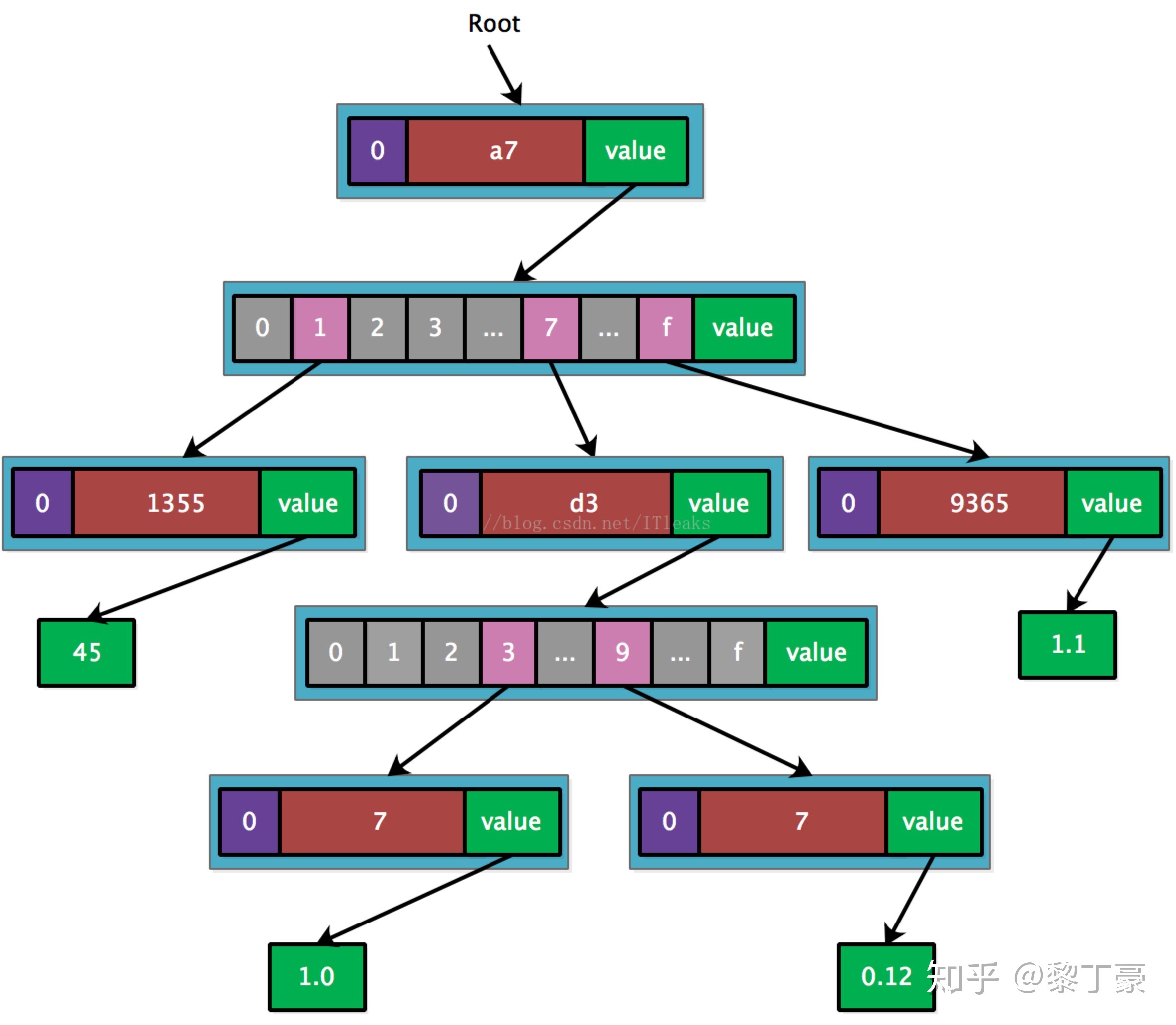
我的理解就是如果key有重合的了就需要一个extension,之后的那一位key肯定不一样,所以就需要一个branch。
区块链中的认证数据
每个区块引用前一个区块,该引用通过它的前一个块的hash结果,这个链表称为区块链。
区块链,在网络中的那个形象,就是一个一个的数据包,被像糖葫芦一样串在一起。但是,网络中有非常多的数据包,你必须通过数据包的某种形象信息,找到上一个数据包是谁?而且要保证,他们有唯一对应的关系。
这里的关键在于。后一个区块中,会包含前一个区块的信息。怎样包含?把所有的区块交易信息,通过哈希运算,得到一个哈希值。然后把这个哈希值,放到第二个区块之中。
然后,再把第二个区块的所有信息,与这个哈希值,再计算,放到第三个区块当中,以此类推,这样这个哈希值就像基因一样。一直随着区块,放入下一个区块中。
区块的构成
区块头和区块主体
区块头:包含nonce(ctr)、data(x)、reference(s)也是区块头的三元素
第一、父区块哈希值的数据。reference(s)这个就是存了父区块的哈希值,类似指针,把区块都连接起来。
第二、挖矿难度值、区块时间戳以及Nonce。这一组数据记录与挖矿有关的内容。nonce(ctr)
第三、Merkle树根。这是个神奇的东西,可以先理解为描述区块中所有交易的数据 data(x)
data存什么取决于你做什么:在比特币中,你存储交易,你开始融资交易,你存储账户之间的支付。在以太坊中,它存储有关帐户、合同或程序的信息。
在比特币中,检查一个区块是否有效的一种方法是检查它是否满足一个工作量证明方程。
区块链的第一个区块称为创世区块,区块链仅仅是开始区块链的人说,ok,这是一个创世区块。开始在此基础上创建区块。
中本聪提出了UTXO,一种基于交易的记账方式。刚才讲的,支付宝、微信那种记账方式,是基于账户的记账方式。仍然举这个例子,通过使用UTXO记账方式。比如,你有10元钱,花了5块钱,出来一个“之前剩余10元,现在剩余5元”的UTXO账单;然后收到3元钱,又出来一个“上次剩余5元,现在剩余8元”;... ... 以此类推。那么这种模式下,即使你之前的账单丢失了,也能知道当前的余额。并且与基于账户的记账方式相比,在计算复杂度、存储空间等方面,都很占优势。UTXO的本质其实是一种流水记账,会把交易的过程记录下来。这种模型的好处在于,每次交易过程都被记录很清楚,可以追溯每笔资金的源头。
后边老师就是提出了一些问题,要在之后讲解。。。。。
The bitcoin network
● All bitcoin nodes connect to a common p2p network 点对点的,节点是平等的
● Each node runs (code that implements) the Bitcoin protocol 每个节点都遵循相同协议
● Open source code 开源
● Each node connects to its (network) neighbours 这些节点不会连接到网络中的每一台计算机,每个节点连接着一些邻居,一小部分邻居。
● They continuously exchange data 它不断地与邻居交换数据
● Each node can freely enter the network – no permission needed! 随意加入
○ A “permissionless network”
● The adversarial assumption: There is no trust on the network! Each neighbour can lie. 网络上没有信任!
区块链实际上并没有消除信任,整个区块链系统所要做的就是减少系统中每个单个参与者所需要的信任量。区块链系统通过激励机制来保证每个参与者之间按照系统协议来合作,从而实现把信任分配给每个参与者。

比特币网络中一个节点之和几个节点连接,而不是所有节点连接,那如何发现其他节点呢?
● Each node stores a list of peers (by IP address)
● When Alice connects to Bob, Bob sends Alice his own known peers
● That way, Alice can learn about new peers
每个节点都存着自己的邻居节点,A向它邻居节点B发送连接请求,B就会把自己的邻居告诉A,这样A就能认识更多人了。
如果它有足够的连接,可以选择不连接其他人,但如果它只有一个或两个连接,它也可能选择尝试与新的同伴建立联系。
如果我是一个新加入者,我如何知道最初应该联系谁
这里你们老师没说太清楚,大概意思就是你的电脑可以从其他人的电脑中获得一些信息,比如社交互动,比如媒体媒介之类的,你可以连接到这些人,然后获取信息。大概就是你的电脑可以帮你获得。
类似广播的一个协议 The gossip protocol
● Alice generates some new data A产生了新数据
● Alice broadcasts data to its peers A要广播给它的邻居
● Each peer broadcasts this data to its peers 每个收到的邻居广播给他们的邻居
● If a peer has seen this data before, it ignores it 有了就忽略
● If this data is new, it broadcasts it to its peers 新的就广播
● That way, the data spreads like an epidemic, until the whole network learns it 最后整个网络都知道了
● This process is called diffuse