hive出现报错
Error: Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask (state=08S01,code=2)
整理了网上找到的一些解决方法,希望对大家有所帮助:
方法一:
在运行sql命令前运行以下命令
set hive.support.concurrency=false;
方法二:
yarn资源不足,修改hadoop配置文件yarn-site.xml,参数不固定
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
<description>default value is 1024</description>
</property>
方法三:
修改配置文件yarn-site.xml ,参数不固定
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024m</value>
</property>
方法四:
数据量太大,内存溢出,在运行sql命令前设置参数,参数不固定,根据自身需要修改
# map阶段内存不足
set mapreduce.map.memory.mb=10150;
set mapreduce.map.java.opts=-Xmx6144m;
# reduce阶段内存不足
set mapreduce.reduce.memory.mb=10150;
set mapreduce.reduce.java.opts=-Xmx8120m;
方法五:
各个节点时间不同步
# 查看集群时间
date
# 同步时间
ntpdate cn.pool.ntp.org
# 或者使用这一条指令
ntpdate -u ntp.api.bz
方法六:
hadoop版本与hive版本不兼容,建议查一下兼容表确认。
方法七:
修改配置文件yarn-site.xml
#Yarn可使用的物理内存总量,该值不能大于节点的内存
yarn.nodemanager.resource.memory-mb
#单个任务可申请的物理内存
yarn.scheduler.maximum-allocation-mb
方法八:
分区数量太多
# 是否允许动态分区
hive.exec.dynamic.partition=true;
# 允许最大的动态分区
hive.exec.max.dynamic.partitions=1000;
# 单个节点允许最大分区
hive.exec.max.dynamic.partitions.pernode=100;
方法九:
关闭自动装载
set hive.auto.convert.join= false;
方法十:
hive启动堆栈内存不足
修改配置文件hadoop-env.sh
扫描二维码关注公众号,回复:
14662550 查看本文章

export HADOOP_CLIENT_OPTS="-Xmx2048m $HADOOP_CLIENT_OPTS"
hive下的bin目录下的配置文件hive-config.sh
export HADOOP_HEAPSIZE=${HADOOP_HEAPSIZE:-2048}
方法十一:
hive执行内存不足
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.dynamic.partition=true;
set hive.exec.parallel=true;
set hive.support.concurrency=false;
set mapreduce.map.memory.mb=4128;
方法十二:
关闭集群,重启虚拟机。
我的修改经历:
运行hive程序后出现报错,先去查看了hive的日志
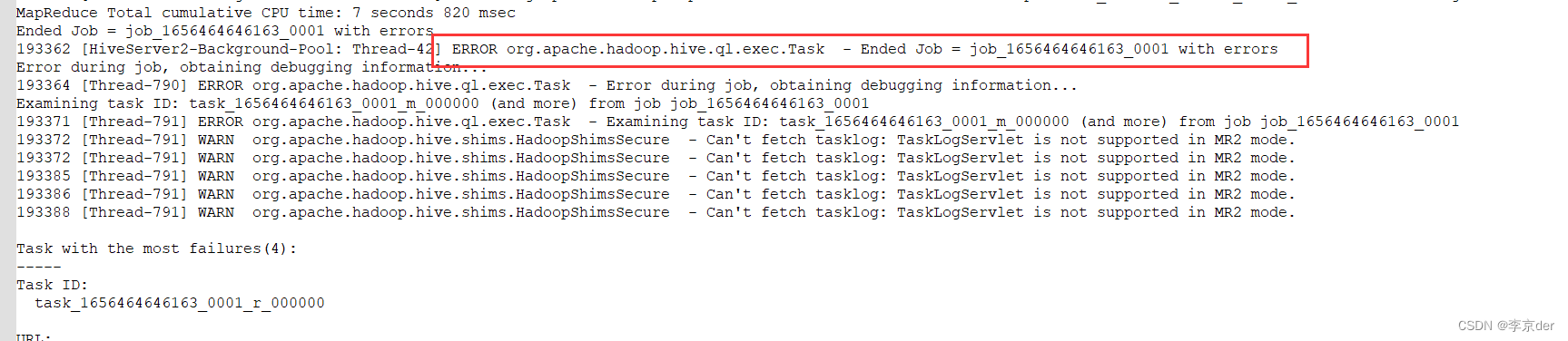
貌似是这个地方出了问题,然后又到ui界面查看job_1656464646163_0001进程
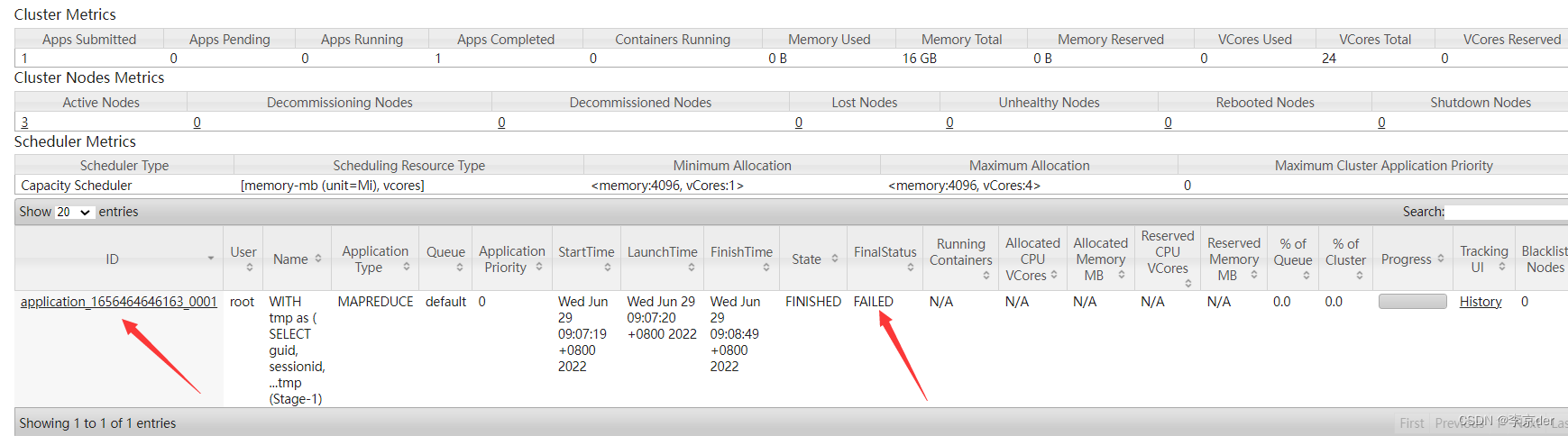
查看他的日志,发现了新问题
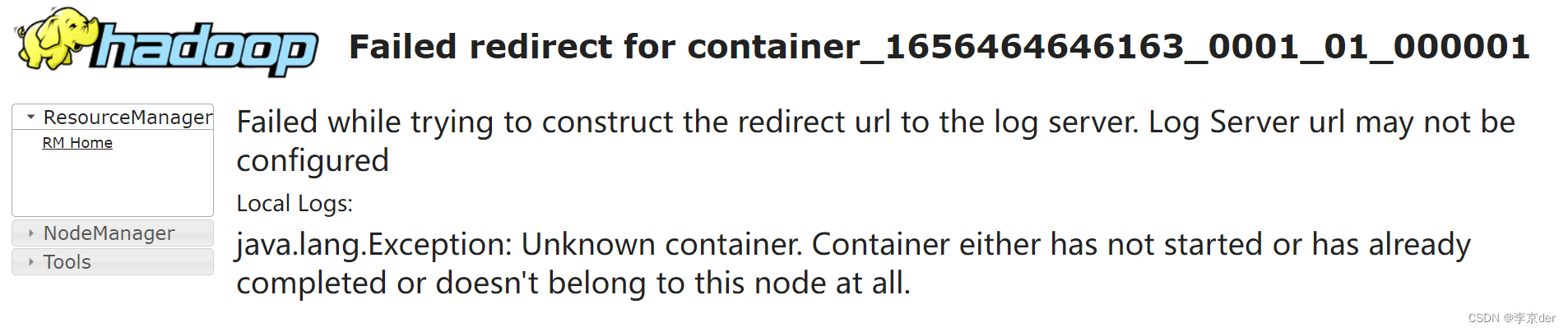
想到了利用命令行查看日志错误
yarn logs -applicationId application_1656464646163_0002
发现问题
