/************************引用类型数组
c#解释
什么叫引用类型数组?
基本类型数组的元素中放的都是基本数据类型(int等)。
引用类型数组的元素中放的是从基本类型构造而来的类和其他复杂数据类型的地址。
两种类型数组的图解
基本类型数组:arr是引用,放在栈内存中,new的部分属于对象,在堆内存中。arr里存的是对象的地址。
引用类型数组:
第一句话:stus是引用类型数组的变量(简称引用),存在栈内存,里面放的是对象实体的地址,new Student[3]在堆内存建立了一个Student[]数组对象实体,内部的元素都是存放的一个Student对象的引用,也就是对象的地址。
第二句话:在此之前仅仅是建立的一个由Student对象的引用所组成的数组,这些引用并没有指向某个地址,值为空,第二句话是在新建了一个Student对象,并把它的地址赋给stus[0]。
引用类型数组的赋值:
类似基本类型数组的赋值方法,只是代码较多,看起来有些复杂
//第一种:先定义数组,然后分别赋值
Student[] stus = new Student[3]; //创建Student数组对象
stus[0] = new Student("zhangsan",25,"LF"); //创建Student对象
stus[1] = new Student("lisi",26,"JMS");
stus[2] = new Student("wangwu",27,"SD");
System.out.println(stus[0].name); //输出第1个学生的名字
stus[1].age = 22; //给第2个学生的年龄赋值为22
stus[2].sayHi(); //第3个学生和大家问好
//第二种方法,声明的同时并赋值,注意中间是逗号
Student[] stus = new Student[]{
new Student("zhangsan",25,"LF"),
new Student("lisi",26,"JMS"),
new Student("wangwu",27,"SD")
};
/*********************************************指针数组
c++数组指针和指针数组
说明:int (*p)[4] 和 int *p[4](数组指针和指针数组),如果你是一个初学者,也许当你看到这两个名词的时候,已经懵了。其实,只要你理解了其中的含义.这两个名词对你来说会相当简单并且很有趣,下面,我们就来深入探讨一下究竟什么是数组指针,什么是指针数组。
一.指针数组
1.前面我们已经学过数组了,比如说要创建一个一维整型数组,该怎么创建呢?应该是这样的:int arr[N];其中,arr是数组名,即变量名,N是你所创建的这个数组中的元素个数,而前面的int则是这些元素的类型。所以其实可以将它读作整型变量数组。那万一你所创建的数组元素不是整型和浮点型这些基本类型,而是一个指针类型呢?这就是指针数组了。
2.指针数组,首先它也是一个数组,只不过这个数组中的元素的类型为指针类型,举个例子:double *arr[4],这是一个指针数组,包含四个元素,其中每个元素都是double*类型的,简单来说,它就是一个用来存储指针的数组。用一个图来说明这个指针数组的内存布局:
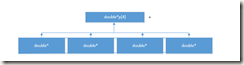
3.既然指针数组是一个数组,那么它就应该有数组所应具有的一些特点。举个例子,对于double* p[4],p+1加的是数组的步长,即一个double*的大小,四个字节(注意:在32位机中,所有指针的大小都为4个字节)。而如果对数组名p进行取地址后,则&p+1加的是sizeof(p),即4*4 = 16个字节,即&p+1就跨过了整个数组。
示例:

1 #include<stdio.h>
2 int main()
3 {
4 double *p[4] = {NULL};
5 printf("p = %p\t",p);
6 printf("p+1 = %p\n",p+1);
7 printf("&p = %p\t",&p);
8 printf("&p+1 = %p\n",&p+1);
9 return 0;
10 }

程序运行结果:

二.数组指针
1.指针相信大家都比较熟悉了,比如:int *p定义了一个指针p,该指针指向一个整型数据单元,如果对该指针执行加1操作,则加的是4个字节;又如char *q定义了一个指针q,该指针指向一个字符型的数据单元,如果对该指针执行加1操作,则实际上加的是1(个字节)。那么问题来了,万一要定义一个指针,它所指向的数据单元为一个一维数组怎么办呢?对他执行加1操作又能得到什么呢?这就是数组指针了。
2.数组指针,首先得明白它是一个指针,只不过这个指针指向的数据单元为一个数组,举个例子,现在有一个一维数组int arr[4];现在要定义一个数组指针来指向它,按照一般指针的理解,应该是这样的,int[4]* p;表示定义一个指针p,而该指针的类型为int[4]*型的,但这在编译器中是会报错的,没什么理由,语法规定。实际上对这个数组指针的定义应该是这样的:int (*p)[4] = arr;说实话,这样看着,笔者觉得挺别扭的,不过没办法,编译器就只认这个写法,不过这完全不影响我们按照第一种写法去理解数组指针的本质。
3.上面已经说了,数组指针实质就是一个指针,只不过其指向的类型与基本类型不同罢了。对于基本类型的指针,执行加1加的是指针指向数据类型的字节数,那么对于数组指针呢?显然加1加的也是指针指向数据类型的字节数,那么数组指针指向数据类型的大小怎么判断呢?举个例子:int(*p)[4],下面将通过一张内存数据图对此进行阐述:
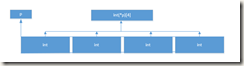
如图:该指针里面存的是一个数组的首地址,只不过该指针的类型为int[4] *型,这就导致了该指针的步长为4*4 = 16个字节,所以对该指针执行加一操作,实际上加的是16个字节,即整个数组的大小。

1 #include<stdio.h>
2 int main()
3 {
4 int arr[4];
5 int (*p)[4] = (int(*)[4])arr;
6 printf("%p\t",p);
7 printf("%p\n",p+1);
8 return 0;
9 }

程序运行结果:

4.数组指针与二维数组的关系是什么呢?首先要知道,二维数组 int arr[m][n] 可以想象成是具有m行,n列的一个数组矩阵,也可以想象成是有m个一维数组,其中每个一维数组里面又有n个int型的元素.那么是否可以用一个类型为int[n] *型的指针指向该二维数组来实现行间跳转访问呢?答案是肯定的!就拿上面例子来说,假如有一个二维数组int arr[m][n],则可以定义一个数组指针为:int (*p)[n] = arr(这里最好强转一下),然后用p对数组进行访问,由以上可讲可知,这里的p+1加的是n*4个字节,即加的是二维数组每行的字节数。
示例:

1 #include<stdio.h>
2 int main()
3 {
4 int arr[3][4];
5 int (*p)[4] = (int(*)[4])arr;
6 printf("%p\t",p);
7 printf("%p\n",p+1);
8 return 0;
9 }
10
程序运行结果:

注意:二维数组的存储在内存中实际上是线性存储的,可以说任何数据在内存上的存储都是线性存储的,但这并不影响我们用二维的思维去理解它。
三.下面是一个数组指针当做二维数组名访问数组的示例,只是为了巩固与拓展一下以上,对于二维数组名的具体使用方式,在下次更新(后天)会详细介绍。这里就简单介绍一下,当把二维数组名赋给一个指针数组后,例如如下示例,则该指针就拥有了二维数组名访问二维数组的方式,比如在这里,p代表数组的首地址,由于其拥有了二维数组名的特性,则**p就是二维数组里的第一个元素,而*(*(p+i)+j)是二维数组第i行第j列的元素。
示例:
1 #include<stdio.h>
2 int main()
3 {
4 int arr[3][4];
5 int count = 0;
6 for(int i = 0;i<3;i++)
7 for(int j = 0;j<4;j++)
8 arr[i][j] = count++;
9 for(int i = 0;i<3;i++)
10 {
11 for(int j = 0;j<4;j++)
12 printf("%2d ",arr[i][j]);
13 putchar(10);
14 }
15 int (*p)[4] = (int(*)[4])arr;
16 for(int i = 0;i<3;i++)
17 {
18 for(int j = 0;j<4;j++)
19 printf("%2d ",*(*(p+i)+j));
20 putchar(10);
21 }
22 return 0;
23 }

程序运行结果:
/******************************************************c++中的指针数组和数组指针
一、指针数组和数组指针的内存布局
初学者总是分不出指针数组与数组指针的区别。其实很好理解:
指针数组:首先它是一个数组,数组的元素都是指针,数组占多少个字节由数组本身决定。它是“储存指针的数组”的简称。
数组指针:首先它是一个指针,它指向一个数组。在32 位系统下永远是占4 个字节,至于它指向的数组占多少字节,不知道。它是“指向数组的指针”的简称。
下面到底哪个是数组指针,哪个是指针数组呢:
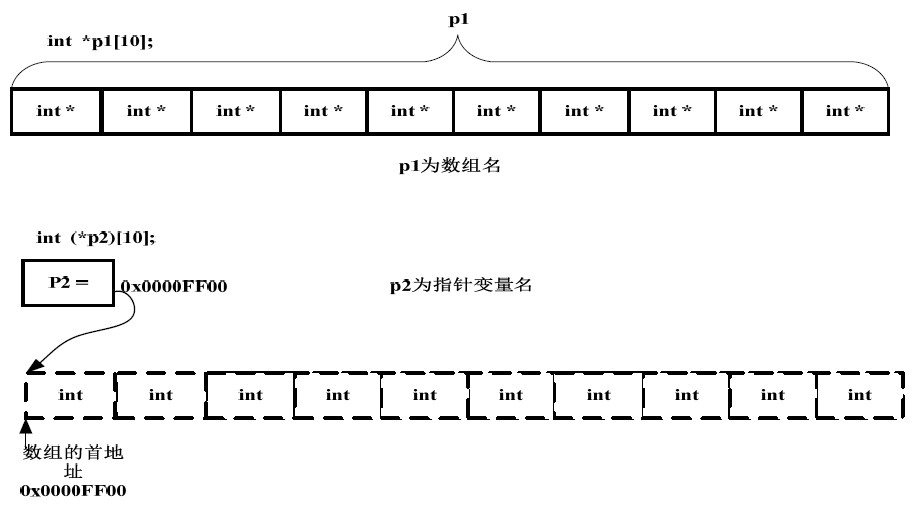
A)
int *p1[10];
B)
int (*p2)[10];
每次上课问这个问题,总有弄不清楚的。这里需要明白一个符号之间的优先级问题。
“[]”的优先级比“*”要高。p1 先与“[]”结合,构成一个数组的定义,数组名为p1,int *修饰的是数组的内容,即数组的每个元素。那现在我们清楚,这是一个数组,其包含10 个指向int 类型数据的指针,即指针数组。至于p2 就更好理解了,在这里“()”的优先级比“[]”高,“*”号和p2 构成一个指针的定义,指针变量名为p2,int 修饰的是数组的内容,即数组的每个元素。数组在这里并没有名字,是个匿名数组。那现在我们清楚p2 是一个指针,它指向一个包含10 个int 类型数据的数组,即数组指针。我们可以借助下面的图加深理解:
二、int (*)[10] p2-----也许应该这么定义数组指针
这里有个有意思的话题值得探讨一下:平时我们定义指针不都是在数据类型后面加上指针变量名么?这个指针p2 的定义怎么不是按照这个语法来定义的呢?也许我们应该这样来定义p2:
int (*)[10] p2;
int (*)[10]是指针类型,p2 是指针变量。这样看起来的确不错,不过就是样子有些别扭。其实数组指针的原型确实就是这样子的,只不过为了方便与好看把指针变量p2 前移了而已。你私下完全可以这么理解这点。虽然编译器不这么想。^_^
三、再论a 和&a 之间的区别
既然这样,那问题就来了。前面我们讲过a 和&a 之间的区别,现在再来看看下面的代码:
int main()
{
char a[5]={'A','B','C','D'};
char (*p3)[5] = &a;
char (*p4)[5] = a;
return 0;
}
上面对p3 和p4 的使用,哪个正确呢?p3+1 的值会是什么?p4+1 的值又会是什么?毫无疑问,p3 和p4 都是数组指针,指向的是整个数组。&a 是整个数组的首地址,a是数组首元素的首地址,其值相同但意义不同。在C 语言里,赋值符号“=”号两边的数据类型必须是相同的,如果不同需要显示或隐式的类型转换。p3 这个定义的“=”号两边的数据类型完全一致,而p4 这个定义的“=”号两边的数据类型就不一致了。左边的类型是指向整个数组的指针,右边的数据类型是指向单个字符的指针。在Visual C++6.0 上给出如下警告:
warning C4047: 'initializing' : 'char (*)[5]' differs in levels of indirection from 'char *'。
还好,这里虽然给出了警告,但由于&a 和a 的值一样,而变量作为右值时编译器只是取变量的值,所以运行并没有什么问题。不过我仍然警告你别这么用。
既然现在清楚了p3 和p4 都是指向整个数组的,那p3+1 和p4+1 的值就很好理解了。
但是如果修改一下代码,会有什么问题?p3+1 和p4+1 的值又是多少呢?
int main()
{
char a[5]={'A','B','C','D'};
char (*p3)[3] = &a;
char (*p4)[3] = a;
return 0;
}
甚至还可以把代码再修改:
int main()
{
char a[5]={'A','B','C','D'};
char (*p3)[10] = &a;
char (*p4)[10] = a;
return 0;
}
这个时候又会有什么样的问题?p3+1 和p4+1 的值又是多少?
上述几个问题,希望读者能仔细考虑考虑。
四、地址的强制转换
先看下面这个例子:
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
假设p 的值为0x100000。如下表表达式的值分别为多少?
p + 0x1 = 0x___ ?
(unsigned long)p + 0x1 = 0x___?
(unsigned int*)p + 0x1 = 0x___?
我相信会有很多人一开始没看明白这个问题是什么意思。其实我们再仔细看看,这个知识点似曾相识。一个指针变量与一个整数相加减,到底该怎么解析呢?
还记得前面我们的表达式“a+1”与“&a+1”之间的区别吗?其实这里也一样。指针变量与一个整数相加减并不是用指针变量里的地址直接加减这个整数。这个整数的单位不是byte 而是元素的个数。所以:p + 0x1 的值为0x100000+sizof(Test)*0x1。至于此结构体的大小为20byte,前面的章节已经详细讲解过。所以p +0x1 的值为:0x100014。
(unsigned long)p + 0x1 的值呢?这里涉及到强制转换,将指针变量p 保存的值强制转换成无符号的长整型数。任何数值一旦被强制转换,其类型就改变了。所以这个表达式其实就是一个无符号的长整型数加上另一个整数。所以其值为:0x100001。
(unsigned int*)p + 0x1 的值呢?这里的p 被强制转换成一个指向无符号整型的指针。所以其值为:0x100000+sizof(unsigned int)*0x1,等于0x100004。
上面这个问题似乎还没啥技术含量,下面就来个有技术含量的:在x86 系统下,其值为多少?
intmain()
{
int a[4]={1,2,3,4};
int *ptr1=(int *)(&a+1);
int *ptr2=(int *)((int)a+1);
printf("%x,%x",ptr1[-1],*ptr2);
return 0;
}
这是我讲课时一个学生问我的题,他在网上看到的,据说难倒了n 个人。我看题之后告诉他,这些人肯定不懂汇编,一个懂汇编的人,这种题实在是小case。下面就来分析分析这个问题:
根据上面的讲解,&a+1 与a+1 的区别已经清楚。
ptr1:将&a+1 的值强制转换成int*类型,赋值给int* 类型的变量ptr,ptr1 肯定指到数组a 的下一个int 类型数据了。ptr1[-1]被解析成*(ptr1-1),即ptr1 往后退4 个byte。所以其值为0x4。
ptr2:按照上面的讲解,(int)a+1 的值是元素a[0]的第二个字节的地址。然后把这个地址强制转换成int*类型的值赋给ptr2,也就是说*ptr2 的值应该为元素a[0]的第二个字节开始的连续4 个byte 的内容。
其内存布局如下图:

好,问题就来了,这连续4 个byte 里到底存了什么东西呢?也就是说元素a[0],a[1]里面的值到底怎么存储的。这就涉及到系统的大小端模式了,如果懂汇编的话,这根本就不是问题。既然不知道当前系统是什么模式,那就得想办法测试。大小端模式与测试的方法在第一章讲解union 关键字时已经详细讨论过了,请翻到彼处参看,这里就不再详述。我们可以用下面这个函数来测试当前系统的模式。
int checkSystem( )
{
union check
{
int i;
char ch;
} c;
c.i = 1;
return (c.ch ==1);
}
如果当前系统为大端模式这个函数返回0;如果为小端模式,函数返回1。也就是说如果此函数的返回值为1 的话,*ptr2 的值为0x2000000。如果此函数的返回值为0 的话,*ptr2 的值为0x100。
/********************************普通值类型数组
C++中数组定义及初始化
一、一维数组
-
- 静态 int array[100]; 定义了数组array,并未对数组进行初始化(栈中分配,系统自动释放)
- 静态 int array[100] = {1,2}; 定义并初始化了数组array(栈中分配,系统自动释放)
- 动态 int* array = new int[100]; delete []array; 分配了长度为100的数组array (堆中分配,需手动释放)
- 动态 int* array = new int[100](1,2); delete []array; 为长度为100的数组array初始化前两个元素(堆中分配,需手动释放)
二、二维数组
-
- 静态 int array[10][10]; 定义了数组,并未初始化
- 静态 int array[10][10] = { {1,1} , {2,2} }; 数组初始化了array[0][0,1]及array[1][0,1]
- 动态 int (*array)[n] = new int[m][n]; delete []array;
- 动态 int** array = new int*[m]; for(i) array[i] = new int[n]; for(i) delete []array[i]; delete []array; 多次析构
- 动态 int* array = new int[m][n]; delete []array; 数组按行存储
三、多维数组
int* array = new int[m][3][4]; 只有第一维可以是变量,其他维数必须是常量,否则会报错
delete []array; 必须进行内存释放,否则内存将泄漏
四、数组作为函数形参传递
-
- 一维数组传递:
- void func(int* array);
- void func(int array[]);
- 二维数组传递:
- void func(int** array);
- void func(int (*array)[n]);
- 一维数组传递:
数组名作为函数形参时,在函数体内,其失去了本身的内涵,仅仅只是一个指针,而且在其失去其内涵的同时,它还失去了其常量特性,可以作自增、自减等操作,可以被修改。
五、字符数组
char类型的数组被常委字符数组,在字符数组中最后一位为转移字符'\0'(也被成为空字符),该字符表示字符串已结束。在C++中定义了string类,在Visual C++中定义了Cstring类。
字符串中每一个字符占用一个字节,再加上最后一个空字符。如:
char array[10] = "cnblogs";
虽然只有7个字节,但是字符串长度为8个字节。
也可以不用定义字符串长度,如:
char array[] = "cnblogs";
/*****************************************结构体数组类型
结构体数组
struct 结构名 变量名[数组大小]
#include <iostream>
#include <Windows.h>
using namespace std;
struct student {
char name[32];
int age;
};
int main(void) {
//定义了一个结构体数组, 包含2个学生
struct student a[2];//此句直接在栈中创建了两个student类型的数据并分配了栈里的空间
//第一个学生赋值
a[0] = { "小黑", 18 };
//第二个学生赋值
strcpy_s(a[1].name, 5, "小白");
a[1].age = 19;
//数组方式访问
cout << "学生1姓名: " << a[0].name << "\t年龄: " << a[0].age << endl;
cout << "学生2姓名: " << a[1].name << "\t年龄: " << a[1].age << endl;
system("pause");
return 0;
}