目录
一、音视频基本原理
1、音视频的主要处理过程:
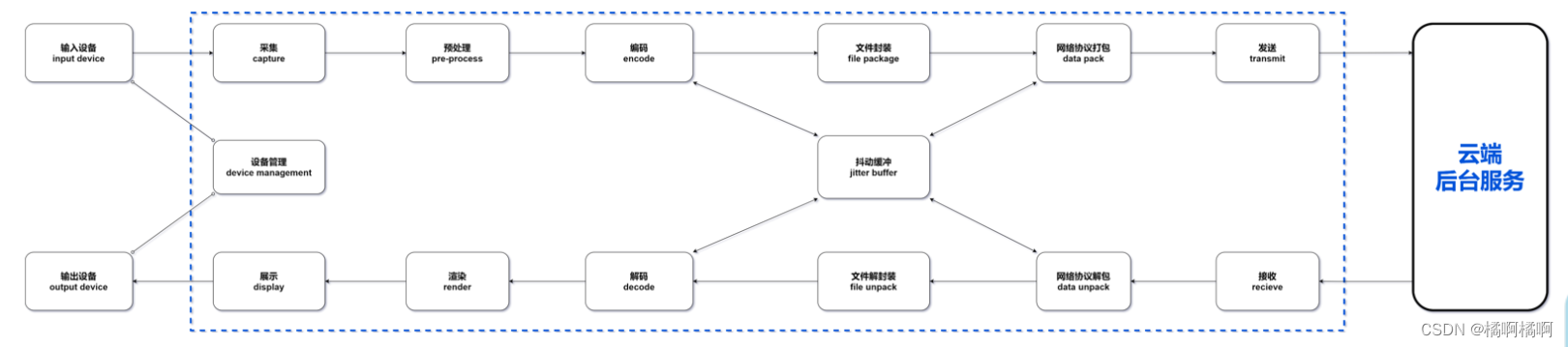
[1]. 采集。比如从客户端的摄像头、麦克风和本地原始文件等,获得基础的音视频数据;
[2]. 预处理。在这个阶段其实就是对音视频进行修剪操作,毕竟收集到的原始数据,不一定是想要在最后呈现的效果,因此在这里可能会进行美颜、裁剪、AI识别处理、声音A3处理等;
[3]. 编码。在经过预处理或者没处理过的原始文件,一般都会比较大,不适合进行传输,这个时候就需要进行压缩、转码之类的操作,减 少文件提交,然后再进行传输,执行编码的工具叫编码器,压缩数据的算法叫做编码格式;
[4]. 解码。压缩数据传输完之后,就需要解码成原始文件一样的数据才能使用,用来解码的工具就是解码器了,不过通常编码器和解码器 是一块的,统称为编解码器codec;
[5]. 渲染与展示。接收到原始数据文件之后,就可以通过硬件或者软件进行渲染与展示了,硬件例如显示器、音响等,软件有 SurfaceView;
[6]. 文件封装/解封装。其实从采集开始,音频和视频都是分开进行处理的,但是在进行传输的时候,我们需要同一套音频文件是在一块 的,所以需要进行一次文件封装。存放音视频的容器叫封装容器,文件类型叫封装格式;
[7]. 网络协议打包/解包。音视频文件在网络中传输的时候,一般都会有一个特定的协议,也就是流媒体协议。网络协议会将音视频数据文 件打包成协议包,通过网络协议端口发送出去,接收方接收到网络包之后,要通过网络协议解开协议包,才能获得音视频数据文件;
[8].抖动缓冲区(JitterBuffer)。网络抖动就是实际发(收)的数据没有发(收),判断是否抖动就是看丢包率是否增加、 往返时延 (RTT)是否增加、发送速率是否降低。 JitterBuffer就是为了减少网络抖动给音视频传输带来的影响而产生的,JitterBuffer是传输过程中的一个缓冲区,连接着解码器和网络协议
栈。JitterBuffer会有意地延迟音视频传输时间,将数据先缓存在缓冲区中,并且也会将之前缓存的数据发送到接收端,可以理解成我们在网上 看电视的时候的视频缓存,这样的话,即使出现了偶尔的网络抖动,也不会影响到用户的体验。
2、音视频主要参数及格式
视频参数:
- 1. 分辨率:视频面积大小(像素px)
- 2. 帧率:每秒的帧数量fps
- 3. 码率:每秒的数据量bps(b = bit)
音频参数:
- 1. 采样率:每秒采集的音频点数量Hz
- 2. 声道数:同时采集声音的通道数量,常见有单声道和立体声道
- 3. 位宽:也叫采样位宽,指保存单个声音样本点的比特位数,通常是16bit
- 4. 比特率:也称位率, 指每秒传送的比特 (bit) 数, 单位为 bps
- 5. 计算公式为: 比特率 = 采样频率 * 采样位数 * 声道数
原始数据格式:
- 视频:YUV、RGB
- 音频:PCM
编码格式:
- 视频:H.264(也叫AVG)、H.265
- 音频:AAC、HE-AAC、Opus
封装格式:
- MP4,MOV,FLV,RM,RMVB,AVI
更多编码与格式相关的可看这篇:音视频编码格式与封装格式_橘啊橘啊的博客-CSDN博客
3、流媒体协议
通常音视频数据体积比较大,所以在网络传输过程中都是连续不断的多媒体流量,在网络中传输音视频数据的技术叫流媒体技术,传输使 用的协议就是流媒体协议。
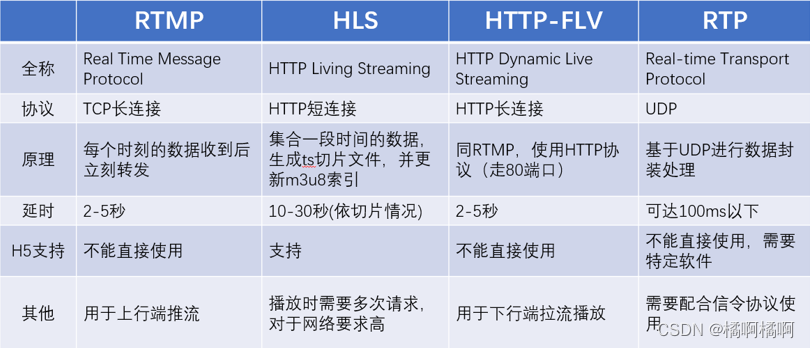
通常使用的流媒体协议有以下几种:
[1]. RTMP:基于TCP七层协议,性价比高,是目前直播推流的标准使用协议;
[2]. HTTP-FLV:基于TCP,使用HTTP传输FLV流,分发性能强,适用于CDN分发;
[3]. HLS:基于TCP,被HTML5写入标准支持,延时大,但是兼容H5;
[4]. RTP:基于UDP四层协议,定义简单且性能好,但是需要额外的信令协议。
除了以上四种之外,有些厂商还会有自己的协议已达到特定的传输目的。
四种流媒体协议对比:
二、音视频视频质量标准
直播功能的测试,不仅要保障基本的业务功能需求,关注音视频质量也是必不可少的。通过对流畅度、清晰度、音质、稳定性和流量消耗等进行专项测试,不断优化各项质量指标,从而提高音视频通话质量。
1.视频质量标准评估(此处只列出常规的几个):
1、首屏耗时
第一次点击播放后,肉眼看到画面所等待的时间。技术上指播放器解码第一帧渲染显示画面所花的耗时。
通常说的 “秒开”,指点击播放后,一秒内即可看到播放画面。首屏打开越快,说明用户体验越好。
2、清晰度
清晰度受视频分辨率和码率影响较大,发送码率越大且分辨率越高,则视频清晰度越好。
需要注意的是:分辨率码率太高,会导致运营成本太高,用户端加载的速度也比较慢。分辨率码率偏低,则容易出现不清晰的问题,影响
用户体验。
3、帧率
由于人类眼睛的特殊生理结构,如果所看画面帧率高于16的时候,就会认为是连贯的,因此帧率建议不低于16帧。而帧率低于5帧时,人
眼能明显感觉到画面不连贯,产生卡的感觉。
帧率对视频质量的影响远远大于分辨率和QP。QP:量化参数,反映了空间细节压缩情况。值越小,量化越精细,图像质量越高,产生的
码流也越长。
4、卡顿(流畅度)
指视频播放过程中出现画面滞帧,让人们明显感觉到“卡”。单位时间内的播放卡顿次数统计称之为卡顿率。
流畅度一般以卡顿率来反映,卡顿的信息主要包含卡顿次数与卡顿时间;直播场景业界通常的卡顿定义是帧渲染间隔大于1s则为卡顿发
生;但通过主观实验,一般这个值达到200ms,观众即可感受到卡顿。
5、稳定性
在各种损伤变化场景下,连续长时间直播未出现花屏、黑屏、自动中断等现象。
6、延迟
延迟是数据从信息源发送到目的地所需的时间。延迟越低,则用户体验越好。
2.音频质量标准评估
1、采样率
直播场景和连麦场景下,音频采样率大于16k。
根据采样定律,最小采样率是最高可采样频率的2倍,也就是说16kHz可以采样的声音频率范围是8kHz以下。根据频率表人声频率基本都
在8kHz以下,特别是语音频率基本都是1kHz以下。因此16kHz的采样率完全足够。
2、音质客观评分
此处介绍一种质量评估算法。POLQA (感知客观语音质量评估),是一种全参考(FR)算法,可对与原始信号相关的降级或处理过的语音
信号进行评级。它将参考信号(讲话者侧)的每个样本与劣化信号(收听者侧)的每个相应样本进行比较。两个信号之间的感知差异被评
为差异。
POLQA 结果主要是模型平均意见得分(MOS),涵盖从 1(差)到 5(优秀)的范围。
3、音画同步
由于播放器在处理音视频的时候是分开进行解码渲染的,要做到音画同步则要给音画添加上时间戳(PTS)的概念,时间相近的音频帧和视频
帧,我们就认定为是同步的两个帧。
一般音视频同步的做法有三种:视频同步到音频、音频同步到视频、音视频同步的外部时钟。
简单的测试方法就是观看直播过程中,主观判断视频画面中主播口型跟声音是否对得上
4、连麦-噪声抑制
噪声抑制技术用于消除背景噪声,改善语音信号的信噪比和可懂度,让人和机器听得更清楚。
5、连麦-回声抵消
主播和观众连麦模式下,单讲和双讲时,说话方听到的回声较小,不会影响交流。
单讲:观众端开启扬声器,主播端说话,主观听是否有自己的回声;反过来观众端说话,听是否有回声。
双讲:双方都开启扬声器,并同时说话,主观听是否有回声,或声音断续有剪切。
三、直播测试一些关注点
1、直播间角色
每一个业务场景,都要通过不同的角色进行分析。最基本的角色有:主播、连麦者、观众,可能还有其他角色。在设计用例、执行测试的
过程中,都要从不同的角色进行测试和验证,保证各个视角功能正常。
2、异常场景
直播中主要的异常场景有:申请连麦异常、同意连麦异常、上麦异常、下麦异常、多次上下麦异常、网络切换导致的异常、直播中登录态
踢出导致的异常等。
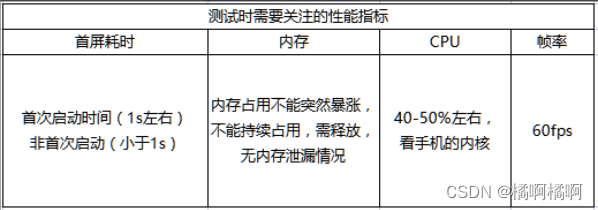
3、性能测试指标数据获取
直播的性能测试场景有:连续长时间开播、重复开播关播、开启美颜直播、赠送礼物等
可通过使用xcode\android studio等分析观察指标数据,也可通过安卓测试工具-性能监控/iOS太极-更多-性能监测打开相应指标开关,
或通过打印日志确定当前数值。
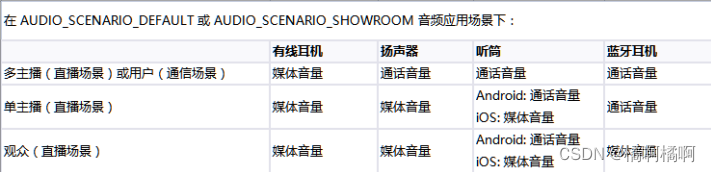
4、媒体音量与通话音量
通话音量指的是进行语音、视频通话时的音量;媒体音量指的是播放背景音乐、视频、音效的音量。通话音量和媒体音量彼此独立,一个
的设置不会影响到另一个。两者的差异:

SDK 使用的音量类型受音频路由、频道场景、用户角色和音频应用场景影响,所以在测试的过程中,需要从用户体验出发,考虑各个不同的方面声音的播放