LinkedList的全面说明:
(1)LinkedList底层实现了双向链表和双端队列特点
(2)可以添加任意元素(元素可以重复),包括null.
(3)线程不安全,没有实现同步
LinkedList的底层操作机制:
双向链表的创建:
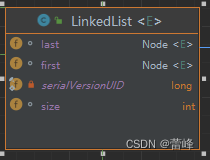
(1)LinkedList底层维护了一个双向链表
size记录了这个链表里面有多少个元素。
(2)LinkedList中维护了两个属性first和last分别指向首节点和尾节点
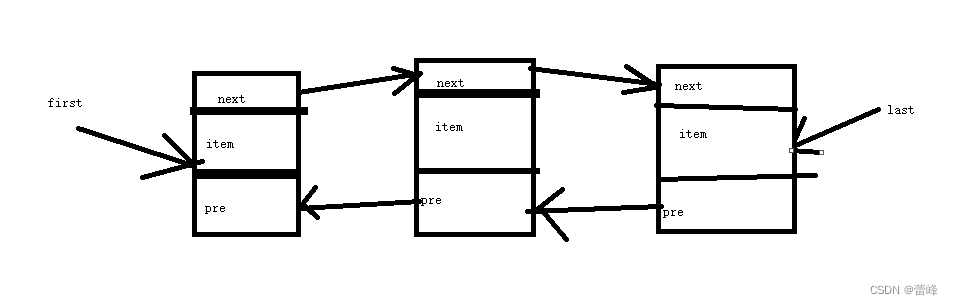
相当于底层维护了一个链表,链表存在三个元素。它的属性first直接指向了我们维护的链表的第一个元素,last属性指向链表最后的。而链表所存有的对象的属性为node。Node为内部类
(3)每个节点(Node对象),里面又维护了prev、next、item三个属性,其中通过prev指向前一个,通过next指向后一个节点,最终实现双向链表
(4)所以LinkedList的元素的添加和删除,不是通过数组完成的,相对来说效率较高。进行删除元素时,我们只需要让所删除的后一个节点的prev指向所删除元素的前面元素的prev的节点,让所删除的前一个节点的next指向删除元素的后一个节点的next。
(5)模拟一个简单的双向链表
我们通过代码来实现双向链表:
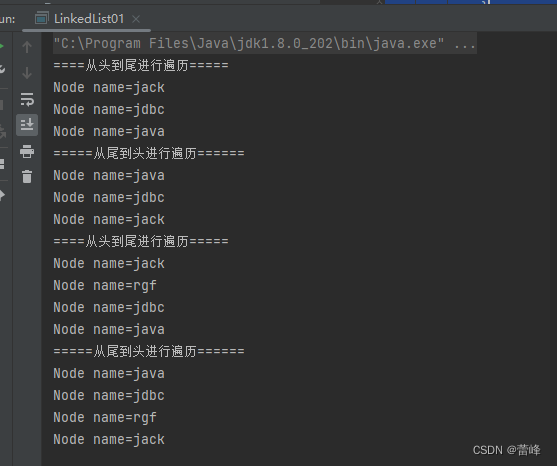
package com.rgf.list; @SuppressWarnings({"all"}) public class LinkedList01 { public static void main(String[] args) { //模拟一个简单的双向链表: Node jack = new Node("jack"); Node jdbc = new Node("jdbc"); Node java = new Node("java"); //连接三个结点,形成双向链表 //实现jack-->jdbc-->java jack.next = jdbc; jdbc.next = java; //实现java-->jdbc-->jack java.pre = jdbc; jdbc.pre = jack; System.out.println("====从头到尾进行遍历====="); Node first = jack; //first引用指向jack,就是双向链表的头结点 Node last = java; //让last引用指向java,就是双向链表的尾结点 //演示,从头到尾进行遍历: while (true) { if (first == null) { break; } //输出first 信息 System.out.println(first); first = first.next; } System.out.println("=====从尾到头进行遍历======"); //演示,从尾到头进行遍历: while (true) { if (last == null) { break; } //输出last信息 System.out.println(last); last = last.pre; } //演示:链表的添加对象/数据,是多么的方便 //要求:在jack和jdbc之间插入一个对象,叫rgf //1.先创建一个Node结点,name叫rgf Node rgf = new Node("rgf"); //下面就把smith加入到双向链表了 jack.next = rgf; rgf.next = jdbc; jdbc.pre = rgf; rgf.pre = jack; System.out.println("====从头到尾进行遍历====="); //让first再次指向第一个人 first = jack; //first引用指向jack,就是双向链表的头结点 last = java; //让last引用指向java,就是双向链表的尾结点 //演示,从头到尾进行遍历: while (true) { if (first == null) { break; } //输出first 信息 System.out.println(first); first = first.next; } System.out.println("=====从尾到头进行遍历======"); //演示,从尾到头进行遍历: while (true) { if (last == null) { break; } //输出last信息 System.out.println(last); last = last.pre; } } //定义一个Node类,Node对象,Node表示双向链表的一个结点 static class Node { public Object item; //真正存放数据的地方 public Node next; //指向后一个结点 public Node pre; //指向前一个结点 public Node(Object name) { this.item = name; } @Override public String toString() { return "Node name=" + item; } } }运行界面如下所示:
LinkedList底层源码分析:
LinkedList的增删改查案例:
LinkedList.add的实现代码区如下所示:
LinkedList.add的实现代码区如下所示:
package com.rgf.list; import java.util.LinkedList; public class LinkedListCRUD { public static void main(String[] args) { LinkedList linkedList = new LinkedList(); linkedList.add(1); System.out.println("linkedList="+linkedList); } }之后,我们进行debug:
点进去之后如下所示:当前只是做了一个初始化:
这时我们进行LinkedList的界面查看如下所示:‘
之后进入之后我们先进行装箱:
之后退出来再进入如下所示:
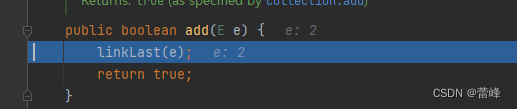
我们进入了add方法,调用了linkLast,我们只有一个结点,即头结点和尾节点都指向同一个结点。
我们再进行下一步,进入如下所示:
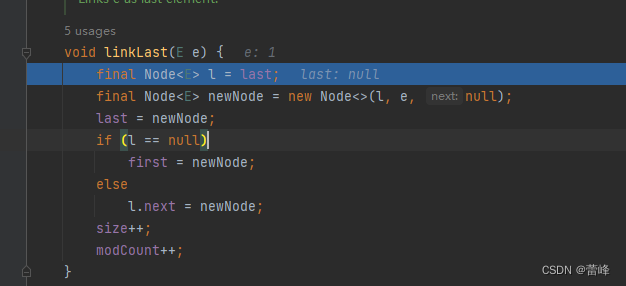
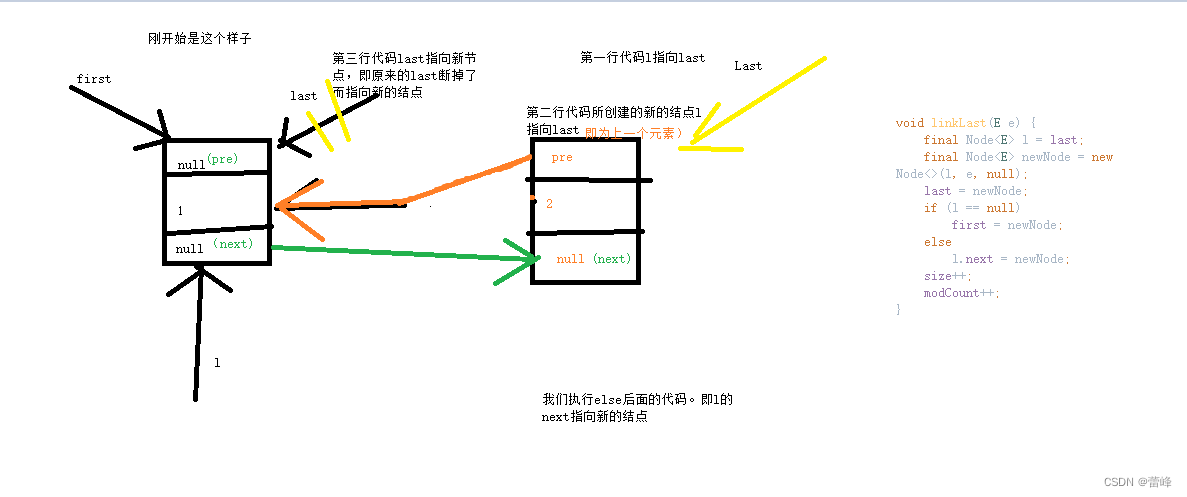
void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; }
我们刚开始所存入的值为1,此时last为null,我们继续往下走的时候,所存放数据的地方,l为空,e=1,next也为空,此时我们的新节点里面有前面为null,存放的值为1,后面的next也为null。last指向这个新节点:newNode,进入if语句后,l为空,所以first也指向newNode,所以这个时候,这个结点,三个(last、first、newNode)都指向他。
我们发现此时的为:
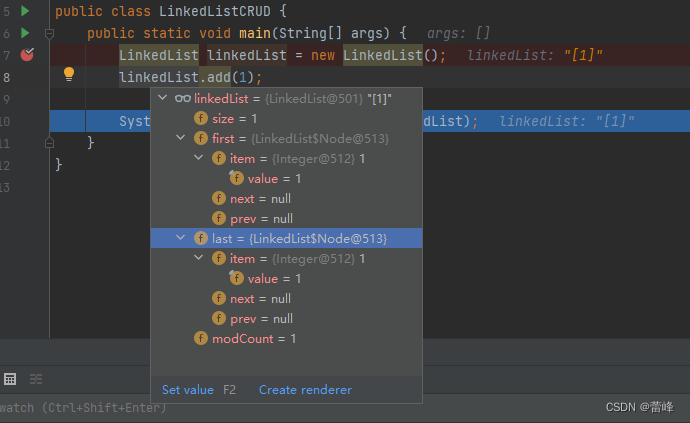
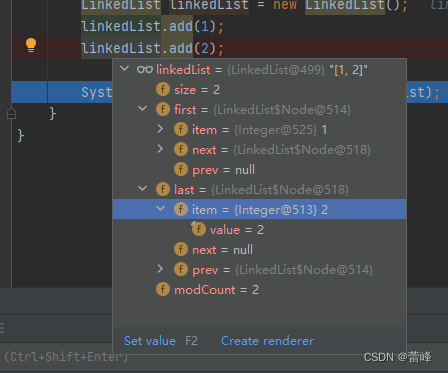
我们全部运行完毕之后,点进去如下所示:
我们发现first和last的地址都是513。
我们再此基础上进行添加一行代码,如下所示:
package com.rgf.list; import java.util.LinkedList; public class LinkedListCRUD { public static void main(String[] args) { LinkedList linkedList = new LinkedList(); linkedList.add(1); linkedList.add(2); System.out.println("linkedList="+linkedList); } }我们进行查看源码如下所示:
我们发现还是要调用linkLast(e),我们继续进行下一步:
我们进行理解如下所示:
我们运行完毕之后如下所示:


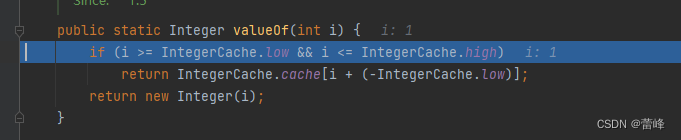



LinkedList删除结点的代码演示如下所示:
remove有三种删除方式:remove(),默认为删除第一个。尾入头出
remove(int index)最其中最复杂的,因为他为删除中间的结点比较麻烦
remove(Object o)对链表里面的某一个对象进行比较,然后删除指定的对象。
我们进行代码设计如下所示:
package com.rgf.list; import java.util.LinkedList; public class LinkedListCRUD { public static void main(String[] args) { LinkedList linkedList = new LinkedList(); linkedList.add(1); linkedList.add(2); System.out.println("linkedList="+linkedList); //演示删除结点的源码 linkedList.remove(); //这里默认删除的为第一个 System.out.println("linkedList="+linkedList); } }我们下来进行debug的进行判断:
我们进入remove进行查看:
我们再进行下一步进入源码:
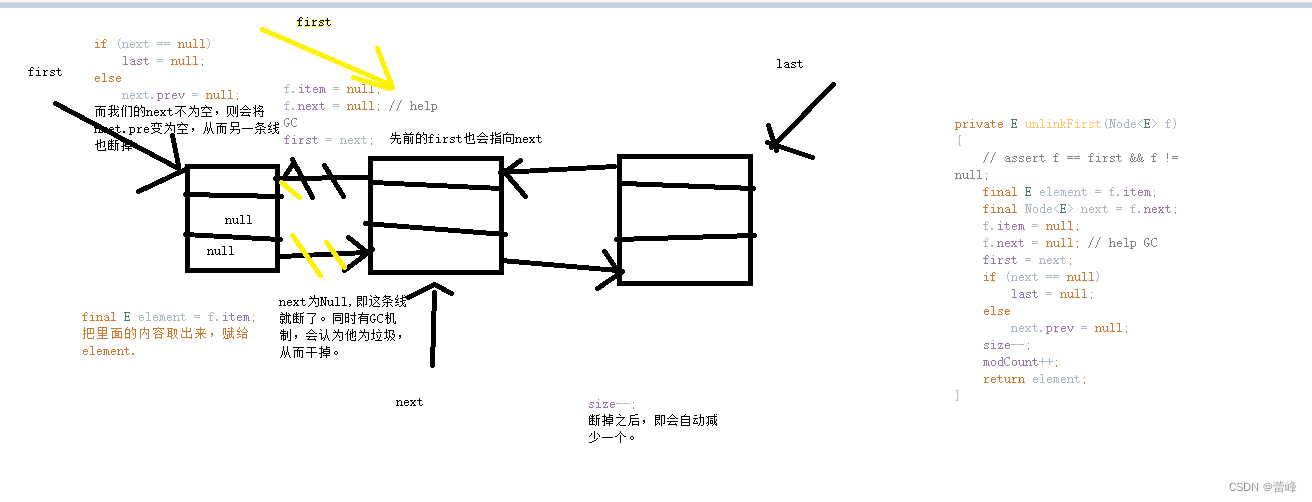
public E removeFirst() { final Node<E> f = first; if (f == null) throw new NoSuchElementException(); return unlinkFirst(f); }我们发现此时f指向first,指向我们双向列表的第一个结点。而f是不等于空的,防止我们再删除的时候是删除一个空链表的。否则会抛出异常的。
我们真正是靠如下方法进行删除的:
private E unlinkFirst(Node<E> f) { // assert f == first && f != null; final E element = f.item; final Node<E> next = f.next; f.item = null; f.next = null; // help GC first = next; if (next == null) last = null; else next.prev = null; size--; modCount++; return element; }我们进行理解如下所示:

LinkedList修改结点的代码演示如下所示:
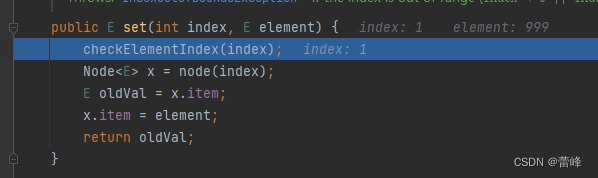
linkedList.set(1,999); System.out.println("linkedList="+linkedList);我们进行打开断点如下所示:
我们先进行自由装箱:
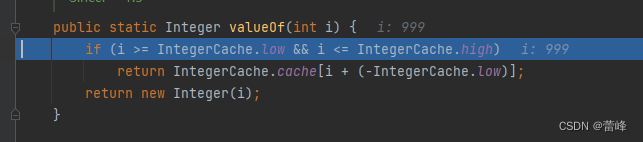
我们退出继续进行下一步,我们进入set的方法:
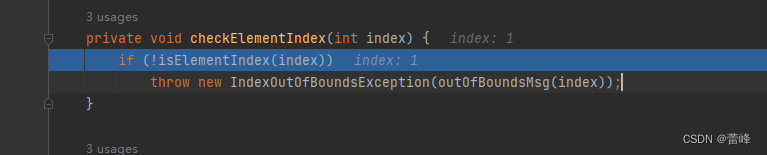
我们进入checkElementIndex方法,点击下一步之后如下所示:
我们进入如下所示:
判断完毕之后我们进入下一行代码:
Node<E> x = node(index);我们继续进行下一步,之后我们点击进入真实的判断方法:
Node<E> node(int index) { // assert isElementIndex(index); if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }

LinkedList删除结点的代码演示如下所示:
//演示得到某个结点的源码 //get(1)是得到双向链表的第二个对象 Object o = linkedList.get(1); System.out.println(o);我们进入get方法源码如下所示:
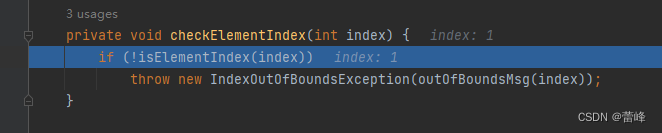
之后我们进行判断checkElementIndex:
我们再进入isElementIndex方法:
返回之后,我们进入改行代码:
继续进行下一步之后如下所示:
Node<E> node(int index) { // assert isElementIndex(index); if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }



我们下来进行ArrayList与LinkedList的比较:
| 底层结构 | 增删的效率 | 改查的效率 | |
| ArrayList | 可变数组 | 较低 数组扩容 |
较高 |
| LinkedList | 双向链表 | 较高,通过链表追加 | 较低 |
如何选择ArrayList和LinkedList:
(1)如果我们改查的操作多,选择ArrayList
(2)如果我们增删的操作多,选择LinkedList
(3)一般来说,在程序中,80%-90%都是查询,因此大部分情况下会选择ArrayList
(4)在一个项目中,根据业务灵活选择,也可能这样,一个模块使用的是ArrayList,另一个模块使用的是LinkedList.,也就是说,要根据业务来进行合理选择。