目录
1.2这里会发现在协议这边又做了一次封装头部原因和再flannel模式中封装解封装有一个密切的关系,原因如下:
一.迭代过程:
传统运维---》集群化---》分布式、高可用、高性能(集群)---》虚拟化---》全虚拟方案---》半虚拟方案---》KVM EXSI viturlbox---》虚拟化产品 Vmware workstation vsphere-容器---》容器引擎---》docker enqine podman引擎
资源管理器---》docker k8s mesoss(iaas层)
集成化管理---》gitops devops CI/CD
资源整合---》自动化的k8s部分+人工智能+大数据+云原生的“产品-go”
二.资源管理器:
1.k8s概述
k8s首先是对集群化的容器进行批管理(增、删、改、查)
2.k8s基础概念
前提:k8s视一切可以管理的对象为“资源“,哪怕该服务不是k8s内部的,如果想作为k8s的常规组件来使用,k8也提供了API给我们来自行定义“控制器”(汇聚插件)
k8s也是一个大的生态圈
(1.)pod资源
最小的资源单位
pod几种容器:3种
- init容器:初始化容器环境
- pause容器:pod内提供network nmespace和存储卷的共享
- 业务容器:支持业务运行(跑业务的)
pod内网络使用什么模式
内localhost和外containter
(2)service资源
提供服务发现支持(有点像docker-p/-P)
service几种模式:
- NodePort
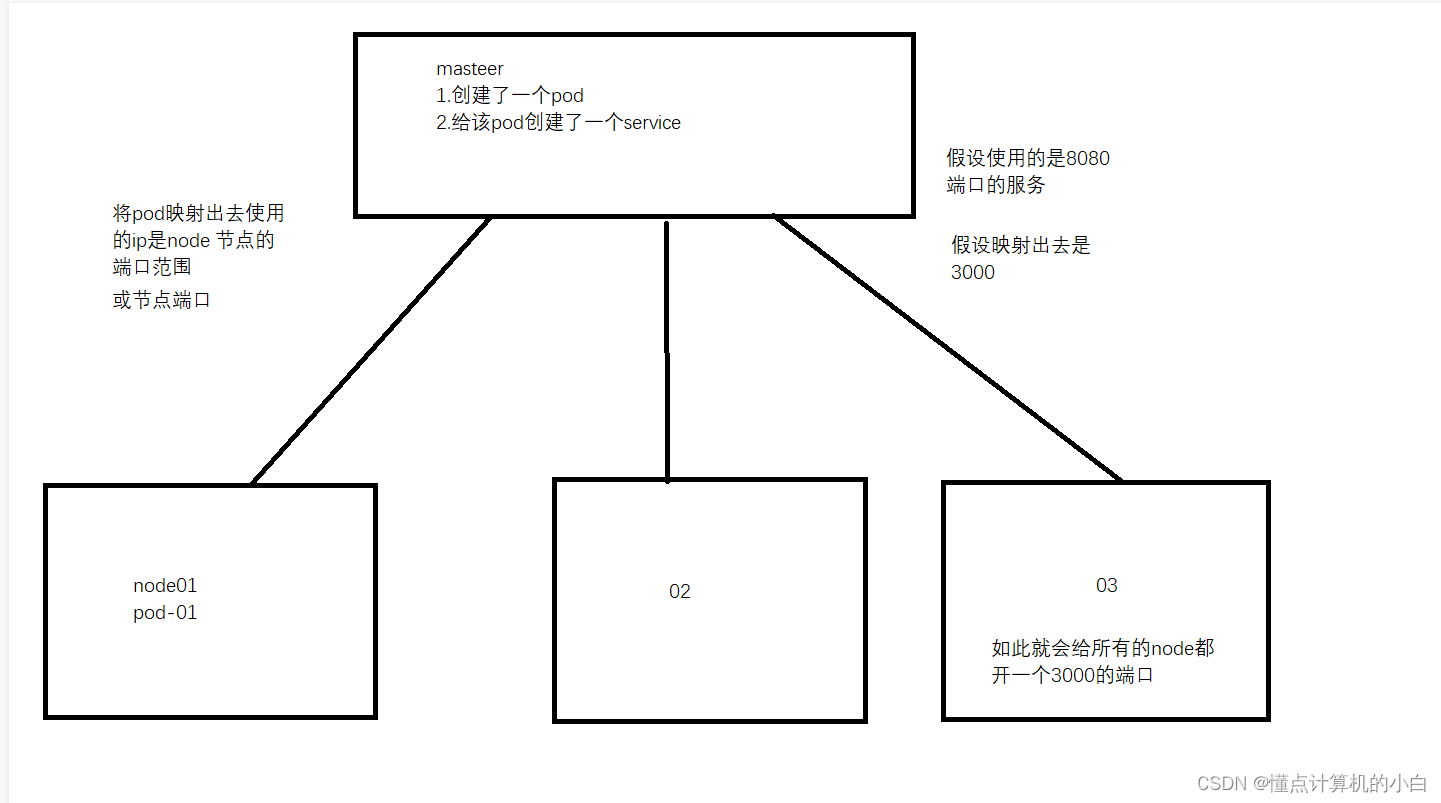
如上图他会给每一个node都映射上一个3000端口,为的是让所有端口都占用此端口。
2.cluster IP
k8s默认就是扁平化的网络即默认就是一个局域网,节点与节点之间访问默认就是使用是该模式
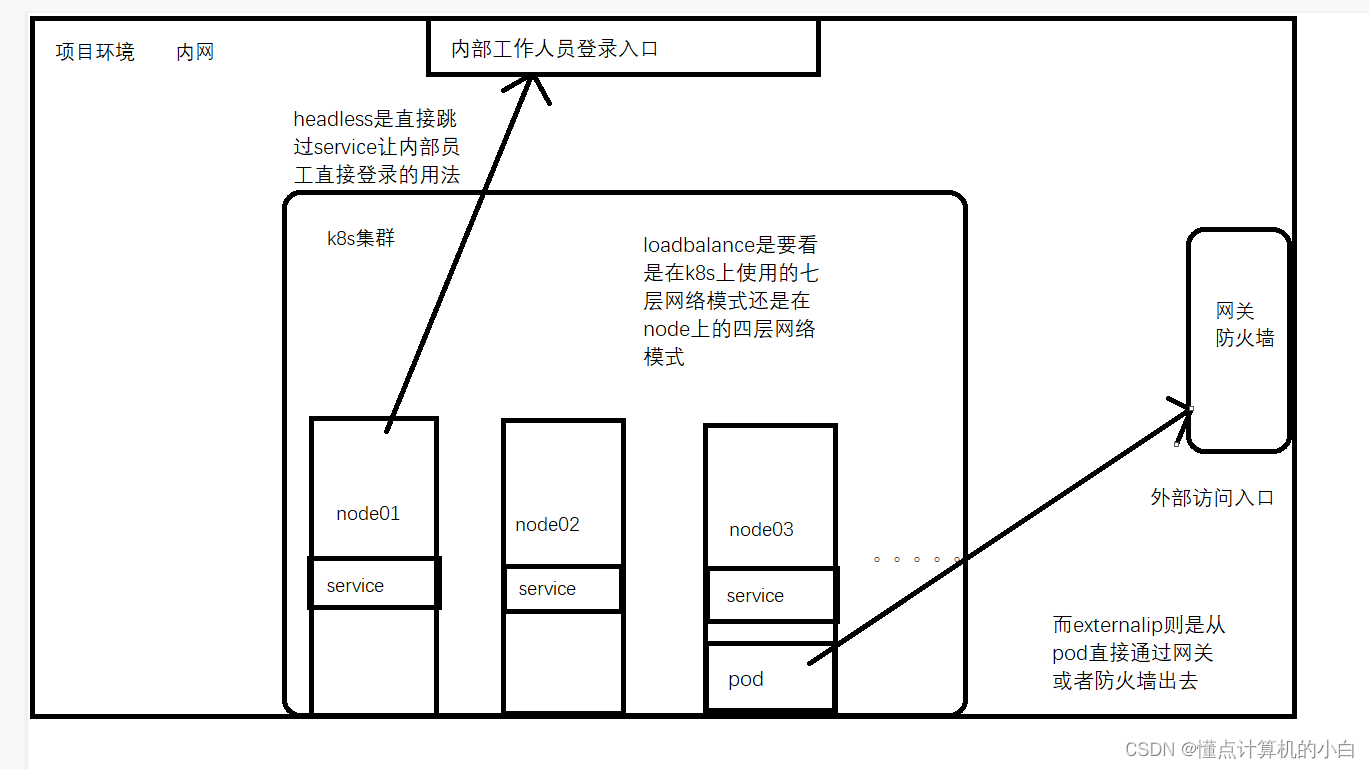
3.headless
也被称为无头网络模式
4.loadbalance
其最主要的是需要分清楚使用的四层还是七层即使用的软件还是硬件
5.ExternalIP (overlay)
(3)yml文件
k8s资源管理器管理器种资源的“配置文件“叫法:资源清单
(4)控制器
管理pod
期望值/yuqizhi
管理pod资源(维护pod状态),包含在那个/维护用户的期望值/预期值
- replicaset 维护pod副本数量和pod状态的
- deployment无状态服务 无特殊状态,无独立状态的应用
- statefulset 有状态服务 有独立状态---》mysql0pod
- job 一次性任务
- Cronjob 周期性任务
- ingress L7层的流量管理、LB服务(http/https)
- daemonSet 所有节点运行同一类pod 每一个节点跑一个指定的pod资源
- PV PVC 动态存储
(5)存储
静态存储 volumes
动态存储 (1.保障容灾性2.为有状态应用提供存储持久化支持)PV PVC(Ceph+nfs)
(6)调度器scheduler
决定将pod运行在那个合适的节点
- 预选 先排除肯定不符合的,例如资源不够,该节点有污点,该节点禁止调度,该节点做了反亲和等等
- 优选 在剩余可用节点内,根据算法来进行各种类型的打分,分数高的,更优先被调度
(7)label标签
哟弄个与标记k8s种特定对象的一种资源
- label 可对资源“打上标记“
- 通过selector标签选择器,来将不同类型的资源,通过相同标签关联在一起(耦合/组合在一起)
(8)namespace
用户k8s种资源之间的隔离,主要为了便于管理
(9)安全
k8s集群中所有的资源,组件包括外部往内部访问,服务运行等等,均需要“安全“
- CA证书
- RBAC准入控制权管理
- 密钥,token形式等等
以上均为:加密安全
三.CNI插件
container network interface 容器网络接口---》为了让pod之间可以进行通讯(不同节点之间进行通讯)
CNI主要类型
1.flannel
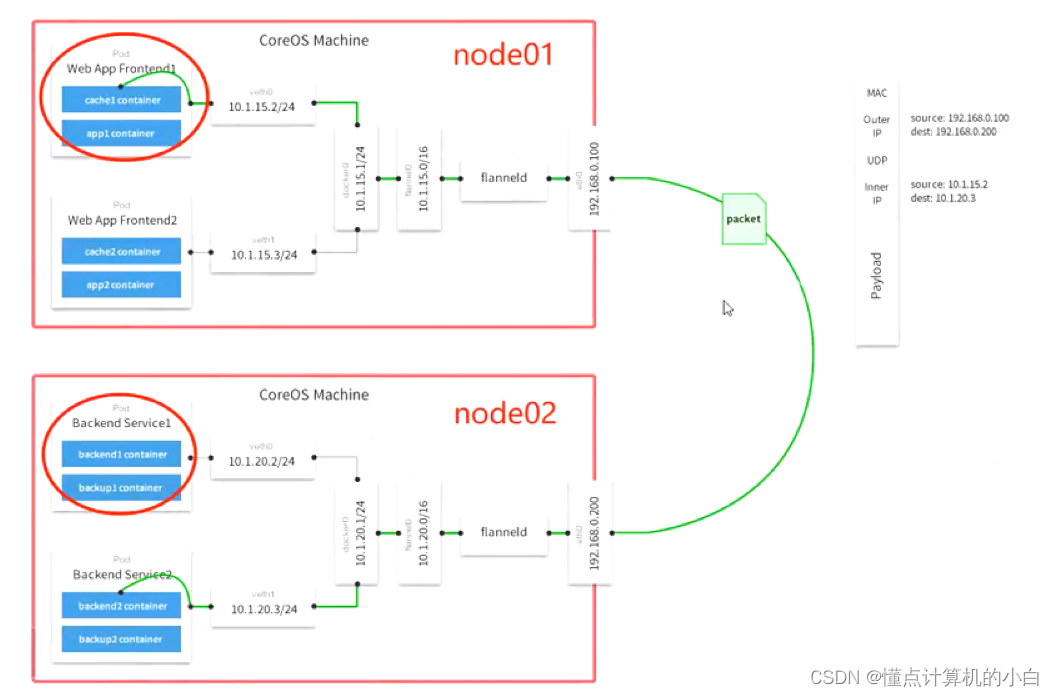
在该模式中pod-ip是如何被分配的
K8S集群中有一个核心组件是ETCDetcd是K8S的核心数据库,存储着K8S集群中的所有资源信息,包括Pod-ip地址的分配,也是由ETCD来定义的。每一个新建的pod都会收到一个新的ip来使用,有一个地址的范围,拿一个少一个,所以每个pod的ip地址是不会冲突的。不管如何都是通过veth对来和docker0网关相连,都是从容器之间出去,并不是pod,上图的10.1.15.0为flanel0在docker0网关和flanel0中会有一个钩子函数
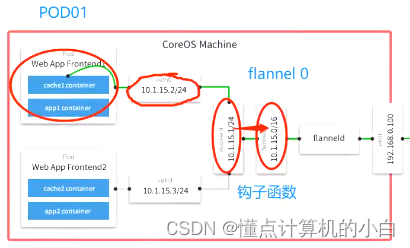
如果非同一网段之间通讯,flanel0就会通过钩子函数收到相关的地址,然后再给到自己的守护进程再给到自己的网卡即网关
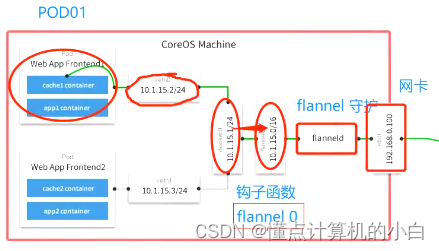
flannel0会读取ETCD中的路由信息即知道目的地址在哪。
最后flannel守护进程会做一层封装,默认的flannelcni模式是Vxlan
1.1 flannel几种模式:
1.Vxlan 2.gateway网关 3.UDP模式,此处使用的是Vxlan
此处flannel会进行不同的封装:(即Vxlan的作用)
数据包封装头部:
MAC头部IP头部协议上层数据
封装完成后的数据:
MAC
源MAC: node1 MAC
目标MAC: node2_ MAC
IP头部:
源lP: node1 IP
目标IP: node2_IPflanneld做了封装:协议:
UDP
Pod_lp头部
源IP: Pod01_IP目标lP: Pod02_IP
上层数据1.2这里会发现在协议这边又做了一次封装头部原因和再flannel模式中封装解封装有一个密切的关系,原因如下:
当相关的目的ip和原ip被钩子函数钩住让flannel0接受到之后,又会进行一次封装,封装内容即原podip和目的pod2的ip并且是再协议内容之后,然后通过网卡即网关进行发送,发送到目的pod之后就会进行解封装,当node02的ens33网卡接受到数据包之后先看mac头部,查看是否是找自己的,一看目标mac发现是找自己的,然后再看目标ip发现还是找自己的,一看是UDP协议,那么就知道需要通过UDP方式进行处理当将相关UDP协议的内容信息拿掉之后发现还封装了一层ip并且是podip并且是找自己pod02的,那么这里又会将已经拆封了的数据再一次封装起来通过flannel的守护进程发送给自己的flannel0,然后再将数据包给到相应的目的,这时候再给到docker0网关,此时的docker0当然知道继续会怎么走,这时候最后发送给相应的容器
1.3flannel面试题
vxlan (默状认)host-gatewayudp
flannel有几种模式几种模式有何区别,UDP和VXLAN有何区别:
1.我们只考虑用的是vxlan封装策略,因为flannel的特性之一也是主控的2.是数据传输和转发我们公司用的就是这个。我也改不了
2.calico
BGP IP-IP两种模式 IP-IP会稍多
calico主要的是路由策略
3.canal
主要的是策略与传输、转发封装
四.k8s工作原理
(引)k8s的核心组件有哪些,分别是什么功能
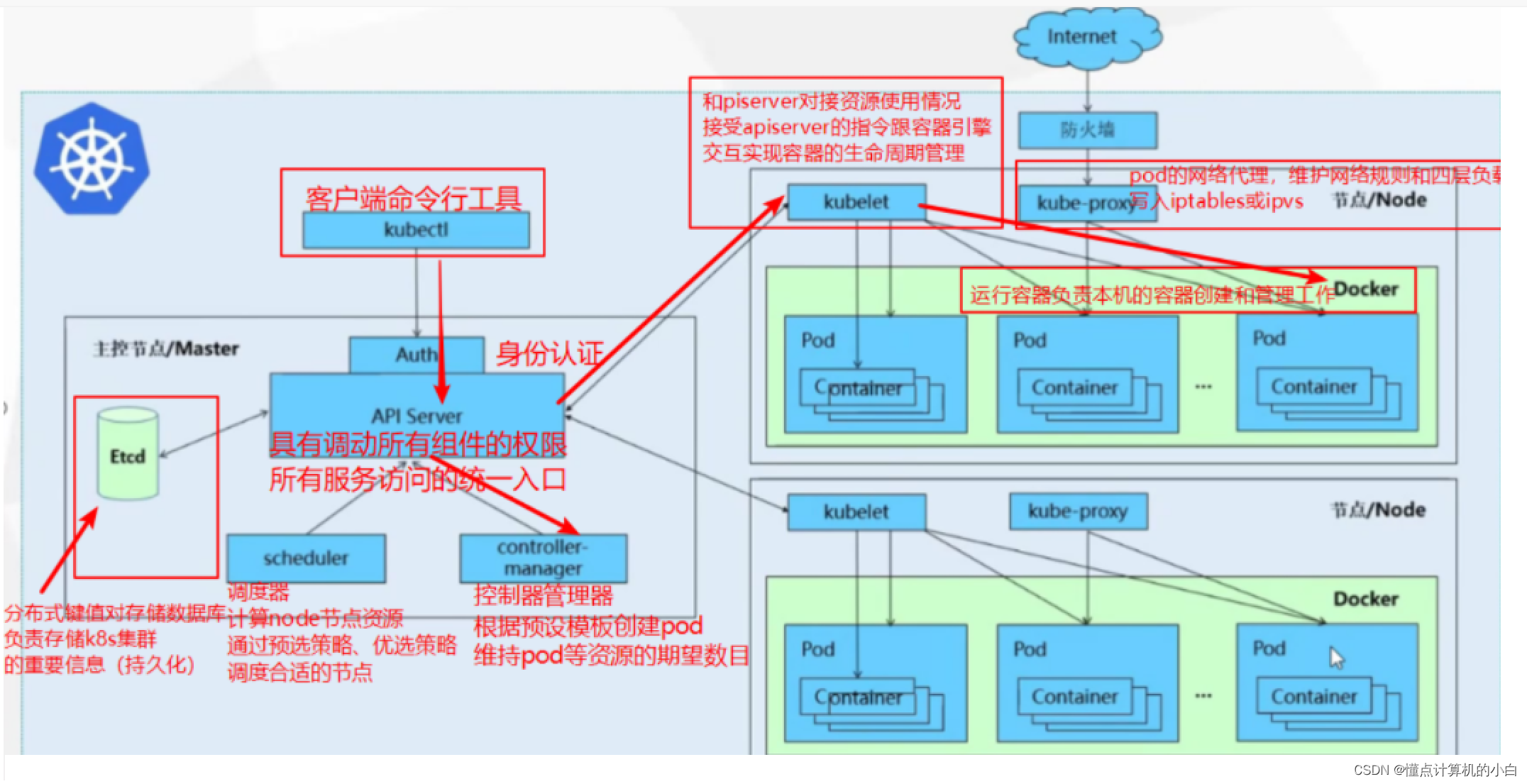
首先k8s是一个中心化集群包含master和node两种角色
1.master中包含那些组件?
创建pod的过程:
首先我们需要知道的是,在master中式不会创建pod的因为master中存放的只要核心组件,不能因为一些乱七八糟的事情来导致master压力过大,从而导致k8s集群架构反应缓慢或者崩溃。所以pod会创建在node节点上
kubectl即命令行,输入的命令,来定义一个pod即向k8s创建一个指令即我需要创建一个pod的指令,从kubectl进来之后因为k8s本身就有安全机制,所以会经过一个auth即权限认证,然后进入一个核心组件即APIserver,(etcd同样也是一个核心,相当于大脑和心脏,本质而言APIserver是一个监控,他负责整个k8s集群的调度和管理,(而etcd是存储整个集群架构的数据与信息,不管APIserver如何进行调度和管理最终都会把数据存放进etcd中,但是其他组件都没有权限去存入到etcd中所以只能通过APLserver来进行存储),因为pod会在node中创建,那么就需要来决定在哪个pod来创建,scheduler组件的功能就是用来做这个事情的,pod创建了之后就需要有人来维护和管理那么就需要controller manager来管理,控制和维护了,它的作用就是用来维护pod状态以及满足我们的这个期望值(期望pod的数量)相当于控制中心,所以当创建pod的请求通过AUTH进入到APIserver后就会借助这两者来进行创建,管理,维护动作,最后所有的动作信息全部汇总到APIserver。
上面所说的式master中所有组件的功能与流程,相信大家认真看的话会对master中所有的组件有一个很好的认知,接下来开始说明k8s是如何来完成在node1节点创建pod的。
上图只有唯二的连接线连接到APIserver即两个node节点的kubelet组件,每一个node节点都存在一个,它的作用就是下达指令是node节点上的总代理(节点管理,pod管理,容器健康检查以及资源监控),k8s会将控制器和调度器的资源给到kubelet,kubelet将会开始创建pod,之前说过Etcd会给每一个需要创建的pod一个ip且唯一这些信息都会通过APIserver给到kubelet,因为pod中存放的是容器,那么kubelet就会控制docker中的运行端口来创建对应的三种容器(如果不懂上面有总结)然后封装到一个pod里到此一个pod创建完毕,创建之后,它还会将所有的创建过程记录下来,然后将所有的创建过程返回给APIserver,APIserver会将该数据存放到ETCD中,至此,创建pod的过程结束
如上图还有一个kube-proxy组件,他的作用很简单就是用于做一个四层的负载均衡。
删除pod流程
当了解了创建过程后删除过程就简单很多了:
1).用户发出删除pod命令,此时pod被视为死亡状态,将pod标记为“Terminating”状态(这时候pod会有一个宽限时间30秒)
2).kubelet监控到pod对象为“Terminating”状态的同时启动pod关闭过程
3).endpoints控制器监控到pod对象关闭,将pod与service匹配的endpoints列表中删除,pod内对象的容器收到TERM信号
4).当一切准备完毕后,kubelet请求api server 将此pod资源宽限期设置为0从而完成删除操作
以上是一个简易版本足以。
本文总结了在k8s中所有组件,创建与删除的流程希望对你有帮助