看到今年Pulsar 峰会上挺多人分享负载均衡的内容,这里也整理分享一下相关的内容。
实践中,我们都会
关闭 auto bundle split,保证系统稳定
Pulsar bundle split 是一个比较耗费资源的操作,会造成连接到这个 bundle 上的所有 producer/consumer/reader 连接断开并重连。一般情况下,触发 auto bundle split 的原因是这个 bundle 的压力比较大,需要切分成两个 bundle,将流量分摊到其他 broker,来降低这个 bundle 的压力。
当触发 auto bundle split 时 broker 负载比较高,关闭这个 bundle 上的 producer/consumer/reader,连接就会变慢,并且 bundle split 的耗时也挺长,就很容易造成 client 端(producer/consumer/reader)连接超时而失败,触发 client 端自动重连,造成 Pulsar/Pulsar client 不稳定。
对于生产环境,我们的建议是:预先为每个 namespace 分配好 bundle 数,并关闭 auto bundle split 功能。如果在运行过程中发现某个 bundle 压力过大,可以在流量低峰期进行手动 bundle split,降低对 client 端的影响。
关于预先分配的 bundle 数量不宜太大,bundle 数太多会给 ZooKeeper 造成比较大的压力,因为每一个 bundle 都要定期向 ZooKeeper 汇报自身的统计数据。
bundle数目的选择--单个分区topic包含的所有分区研究
不推荐开启bundle拆分的功能,也就是创建namespace的时候就要确定bundle的数目。那么该如何确定bundle的数目呢?
根据一致性hash算法,显然bundles数目越多越有利于负载均衡,但是bundles数目太大,也会有不好的一面。

pulsar在实现负载均衡算法的时候,会搜集性能指标,如msg/sec、avg latency之类的,这些是以bundle level来统计的,如果bundle数目过多,则会增大计算metrics的开销,而且这些metrics存储在ZK metadata store上,也会增大存储和network io开销。
因此,不能太多bundles,那有没有一个规则来指导设置bundles数目呢?
分析:
·提高性能方面:pulsar设计分区topic是为了让同一个topic下的不同分区分别由不同broker服务,这样一个客户端同时由多个bundle来服务,从而提高单个topic的吞吐量,但是如果多个分区被分配到同一个bundle,那么这几个分区就只能由同一个broker来服务,也就没法达到预期的效果。
·负载均衡方面:提高bundles数目,显然是可以提高负载均衡的效果的,但是设置到多高的值才能说是收益大于成本呢?单个分区topic,如果使用round-robin的路由模式,则该topic下的每个分区的流量是均匀的,则如果该topic每个分区都分配到不同的bundle, 再由一个理想的shedding算法使得这些bundle均匀地分配到brokers上,则brokers的负载就能达到理想的负载均衡状态。可见,bundles数目设置的上限值应该是大概率使得不同分区分配到不同bundle,再往高了取其实就没有收益了,而且一般也没必要取到这个上限值。
即,我们目标是想尽量让不同分区分进不同的bundle里,对应概率模型:把k个球随机均匀放进m个桶里(pulsar中的分配不是随机的,是对通过hash来分配的,这里做近似)
则k个球都放进不同的桶的概率为
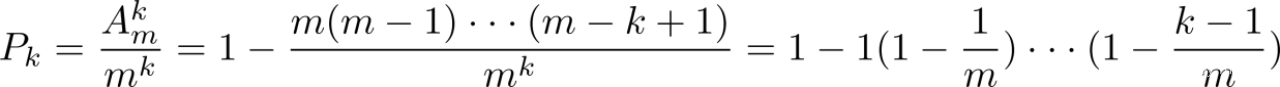
由
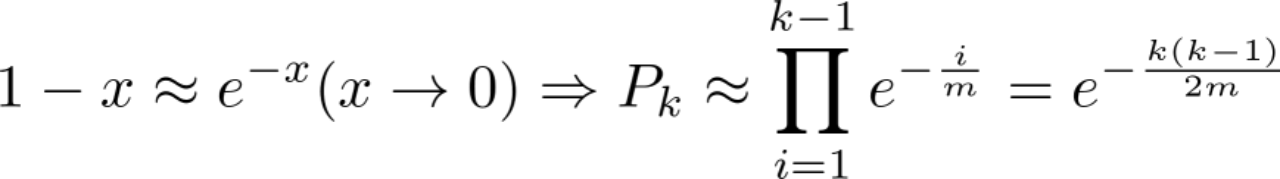
令Pk=1/t,则
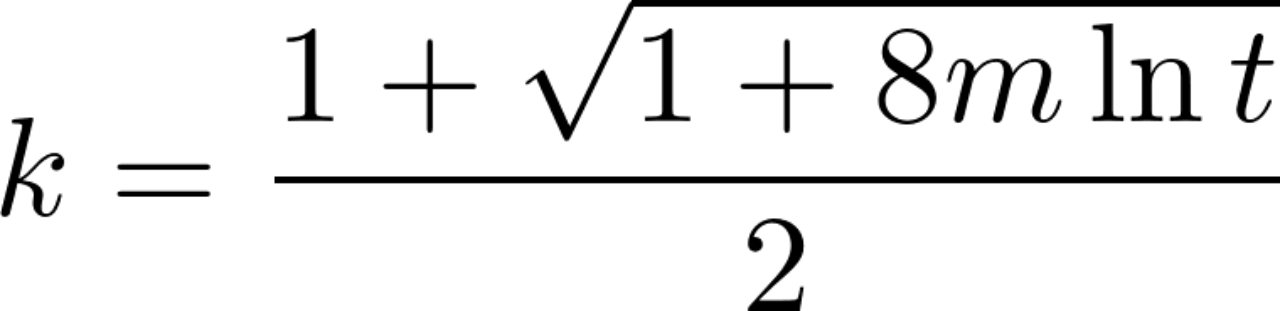
令t=2,m=500,则k≈26,即当集群的bundles总数为500时,一个分区数为26的分区topic,它的所有分区分配到不同的bundle的概率为1/2,也即至少有一个分区与另一个分区放到同一个bundle的概率为1/2,肯定足够的。
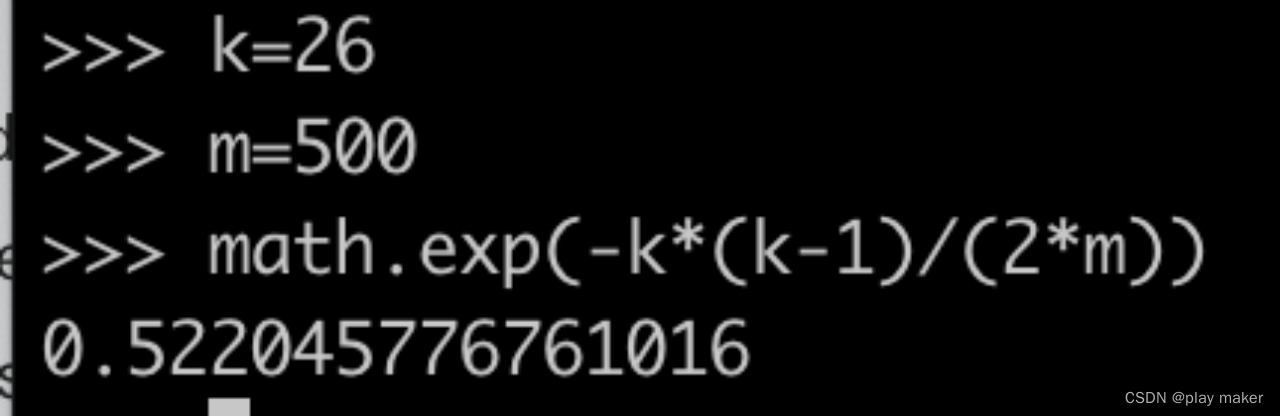
上面是,对单个分区topic包含的所有分区的分布情况进行研究,我们尽量避免多个分区分配到同一个bundle上。下面我们研究整个namespace的所有topic分区的分布情况,因为如果不同bundle上承载的分区数目差距过大,则可能造成超大、超小bundle情况的出现。
bundle数目的选择--整个namespace的所有topic分区
超大、超小bundle的出现会严重影响负载均衡管理器的工作。如下例,假设shedding算法确定要卸载100M流量,算法如果从大到小挑选bundle(一般都是这样的)。
- 如果出现超大bundle 200M,则卸载它很有可能导致新的owner broker超载。
- 如果bundle的流量大小排序情况为 90 1 1 1 1 1 0.1 0.1 0.1 0.1 ... ,则会导致算法需要卸载很多超小bundle的问题,而这对负载均衡几乎没有收益。
当然,上面两个问题,都可以尝试在shedding算法里尝试处理应对,但是,如果集群bundle流量分布状况是均匀的话,也就没必要设计更麻烦的算法来解决了。
要避免超大、超小bundle的出现,则bundle数目不需要过多,也不能过少。比如说,
- 10000个topic分区的namespace,仅有10个bundles,任一bundle的体积都过大。
- 100个topic分区的namespace,有200个bundles,则肯定会有很多bundle没有流量,成为超小bundle。



方差的意义为:将m个球投入n个格子,格子里的球数与平均球数的差距的平方的期望。取平方根则大致可表示不同格子里的球数差距的期望。要精准表示不同格子里的球数差距的期望,得求如下公式:
![]()
可见,如果namespace下topic分区为bundle数目的100倍的情况下,不同bundle之间的topic分区数目差距就开始明显有差距了。
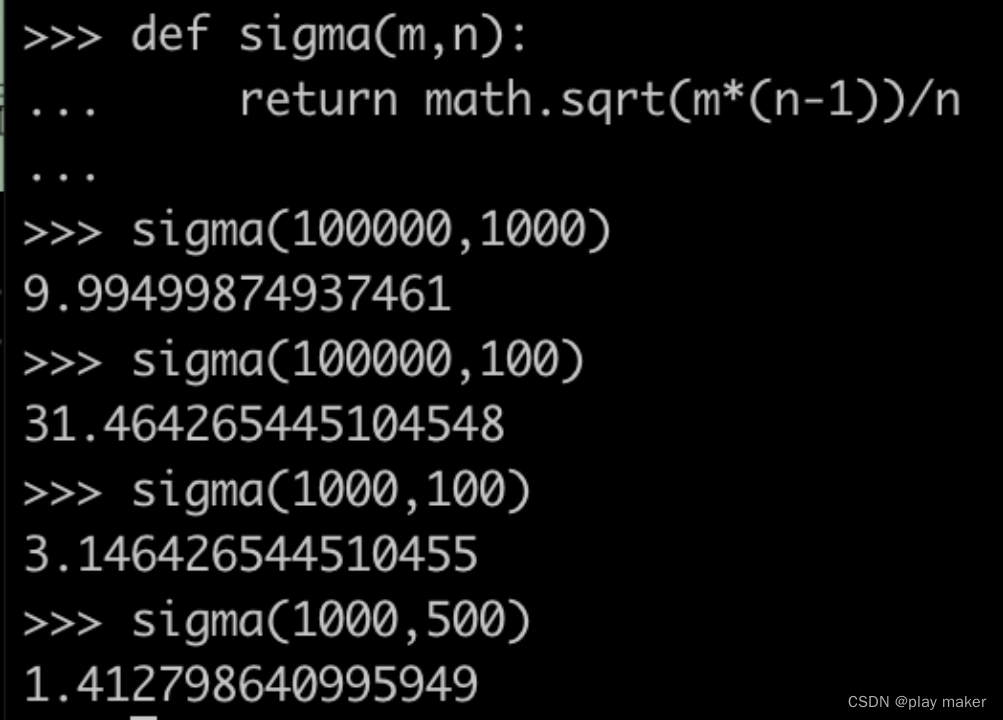
看到峰会上有人推荐一个经验值:topic分区数是bundle数目的20倍,根据我们前面的研究,可以分析出这个经验值的效果:
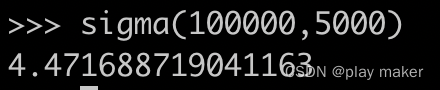
即一个有100000分区的namespace,分配5000个bundles,则每个bundle上的分区数的期望为100000/5000=20,而大部分的bundle上的分区数处在[20-4.47168,20+4.47168]这个区间内,即最多与最少的差距是8个分区。
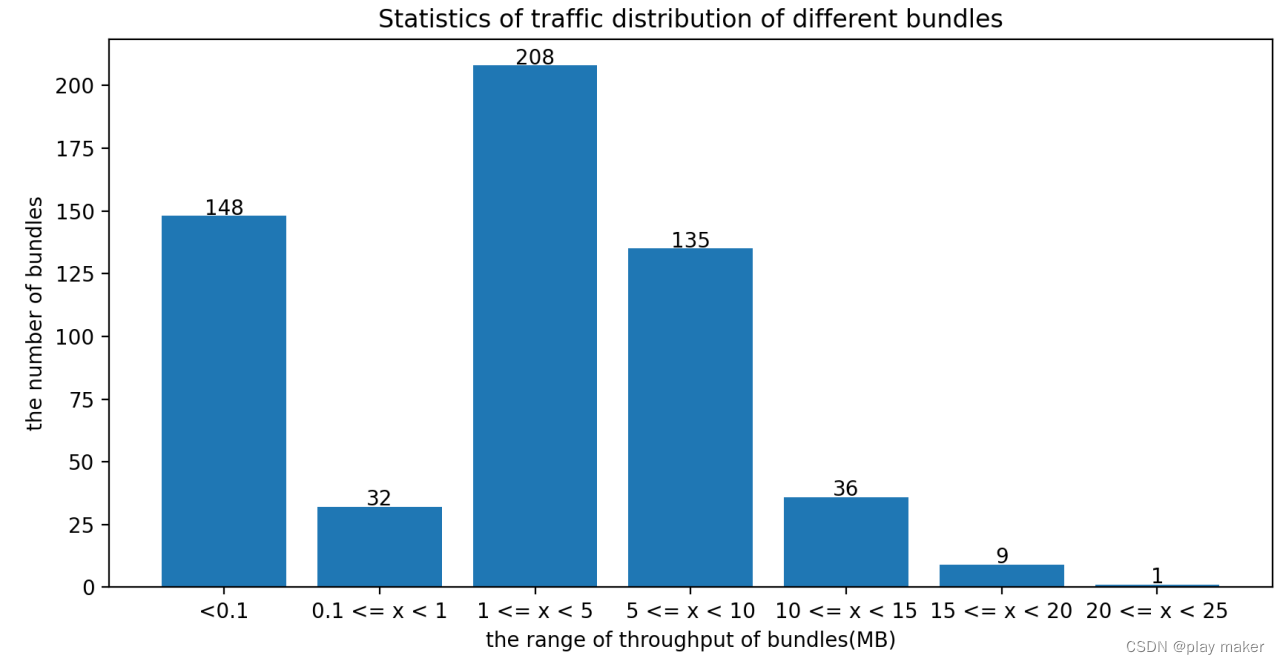
下面分析一个pulsar测试集群的数据,下图是测试集群的bundle流量分布图,可以看到bundle的流量大小集中分布在1-10M区间内,没有超大bundle的出现,但是有相当多的超小bundle,流量<0.1M,几乎可以认为是没有流量。
下图是集群某个namespcae下所有bundle服务topic个数的分布图
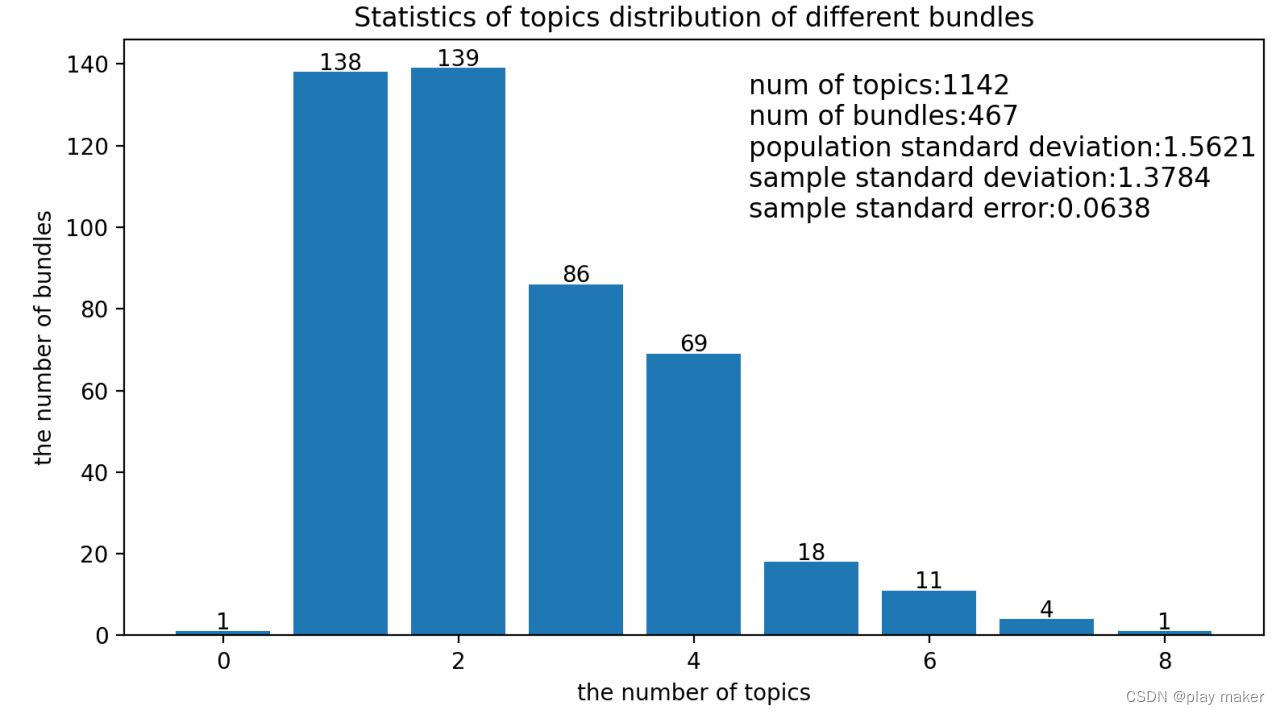
总共有1142个topic,467个bundles,按照前面的推导,期望为
![]()
样本标准差s=1.3784,而根据前面理论推导的标准差为1.5621,可以看到样本的标准差更小了,数据偏差更小了。数据集中在[2.4454-1.3784 , 2.4454+1.3784]=[1.067,3.8238]这个范围内,即绝大部分bundle上有1~4个topic。
因此,topic分配到bundle上是足够均匀了,但是由于不少topic本身没有流量,导致出现超小bundle的出现,这是无法避免的,是很常见的现象,因此我们需要在shedding算法处理好这些超小bundle即可。
而超大bundle的出现是可以避免地,我们要保证大流量的topic的分区数要足够多,避免出现超大分区的出现,从而导致超大bundle的出现。