文章目录
随着多种技术引擎的迭代,也产生了多个高性能的列式存储格式,例如RCFile、ORC、Parquet等。
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目。
列式存储和行式存储相比有哪些优势呢?
1,可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量。
2,压缩编码可以降低磁盘存储空间。
由于同一列的数据类型是一样的,可以使用更高效的压缩编码(例如Run Length Encoding和Delta Encoding)进一步节约存储空间。
3,只读取需要的列,支持向量运算,能够获取更好的扫描性能。
当时Twitter的日增数据量达到压缩之后的100TB+,存储在HDFS上,工程师会使用多种计算框架(例如MapReduce, Hive, Pig等)对这些数据做分析和挖掘;日志结构是复杂的嵌套数据类型,例如一个典型的日志的schema有87列,嵌套了7层。所以需要设计一种列式存储格式,既能支持关系型数据(简单数据类型),又能支持复杂的嵌套类型的数据,同时能够适配多种数据处理框架。
4,对嵌套数据结构的读取优势。
关系型数据的列式存储,可以将每一列的值直接排列下来,不用引入其他的概念,也不会丢失数据。关系型数据的列式存储比较好理解,而嵌套类型数据的列存储则会遇到一些麻烦。如下图所示,我们把嵌套数据类型的一行叫做一个记录(record),嵌套数据类型的特点是一个record中的column除了可以是Int, Long, String这样的原语(primitive)类型以外,还可以是List, Map, Set这样的复杂类型。在行式存储中一行的多列是连续的写在一起的,在列式存储中数据按列分开存储,例如可以只读取A.B.C这一列的数据而不去读A.E和A.B.D
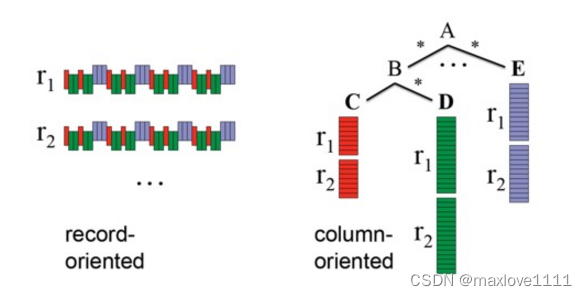
Parquet的文件结构
Parquet文件是以二进制方式存储的,是不可以直接读取和修改的,Parquet文件是自解析的,文件中包括该文件的数据和元数据。
在HDFS文件系统和Parquet文件中存在如下几个概念:
HDFS块(Block):它是HDFS上的最小的副本单位,HDFS会把一个Block存储在本地的一个文件并且维护分散在不同的机器上的多个副本,通常情况下一个Block的大小为256M、512M等。
HDFS文件(File):一个HDFS的文件,包括数据和元数据,数据分散存储在多个Block中。
行组(Row Group):按照行将数据物理上划分为多个单元,每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,Parquet读写的时候会将整个行组缓存在内存中,所以如果每一个行组的大小是由内存大的小决定的。
列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。不同的列块可能使用不同的算法进行压缩。
页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
通常情况下,在存储Parquet数据的时候会按照HDFS的Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。Parquet文件的格式如下图所示。
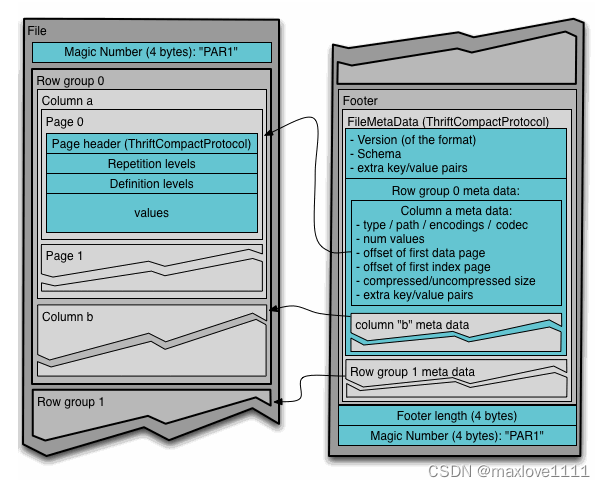
上图展示了一个Parquet文件的结构,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length存储了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和当前文件的Schema信息。
除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。
数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页,但是在后面的版本中增加。