本文依赖于 Fabian Bosler 编写的代码:
用 Python 抓取图像
我只是修改了 Bosler 的代码,以便更轻松地为多个搜索词提取图像。
完整代码可以在该系列的 Github 存储库中找到:
deep_arcane -- scrap.py
魔术符号
正如我在之前的文章中提到的,我需要大量的魔法符号图像来训练深度卷积生成对抗网络 (DCGAN)。幸运的是,我很早就找到了 Bosler 的文章。
为了获取我的图像,我使用 Chrome 浏览器、Chromedriver、Selenium 和 Python 脚本从 Google 的图像搜索中慢慢抓取图像。抓取被限制在接近人类的速度,但允许自动收集大量图像。
关于这个过程,我会附和 Bosler,我绝不是法律专家。我不是律师,我所说的任何内容都不应被视为法律建议。我只是互联网上的黑客。 然而,据我所知,抓取 SERP(搜索引擎结果页面)并不违法,至少不是供个人使用。但是使用 Google 的图像搜索自动抓取图像违反了他们的服务条款 ( ToS)。复制此项目需要您自担风险。我知道当我调整我的脚本以更快地搜索时谷歌禁止了我的 IP。我很高兴这是暂时的。
Bosler 的修改脚本
该脚本会自动搜索图像并收集其基础 URL。搜索后,它使用 Pythonrequests库将所有图像下载到以搜索词命名的文件夹中。
以下是我对 Bosler 的原始脚本所做的修改:
添加了搜索词循环。这允许脚本继续运行超过一个搜索词。
脚本在遇到“显示更多结果”时卡住了,我已经解决了这个问题。
结果保存在与搜索项关联的目录中。如果脚本被中断并重新运行,它会查看首先创建的目录,并将这些目录从搜索项中删除。
我添加了超时功能;感谢Stack Overflow上的一位用户。
我参数化了每个搜索词要查找的图像数量、睡眠时间和超时。
代码:库
您将需要安装 Chromedriver 和 Selenium——这在原始文章中有很好的解释。
用 Python 抓取图像
您还需要安装Pillow——一个用于管理图像的 Python 库。
你可以安装它:
pip install pillow
安装所有需要的库后,下面的代码块应该可以正确执行:
import os
import time
import io
import hashlib
import signal
from glob import glob
import requests
from PIL import Image
from selenium import webdriver
如果您有任何问题,请重新阅读原始文章设置说明或随时在下面的评论中提问。
代码:参数
我在脚本中添加了一些参数以方便使用。
number_of_images = 400
GET_IMAGE_TIMEOUT = 2
SLEEP_BETWEEN_INTERACTIONS = 0.1
SLEEP_BEFORE_MORE = 5
IMAGE_QUALITY = 85
output_path = "/path/to/your/image/directory"
告诉脚本每个number_of_images搜索词要搜索多少张图片。如果脚本在到达 之前用完图像number_of_images,它将跳到下一个学期。
GET_IMAGE_TIMEOUT确定脚本在跳到下一个图像 URL 之前应等待响应的时间。
SLEEP_BETWEEN_INTERACTIONS是脚本在检查下一个图像的 URL 之前应该延迟多长时间。从理论上讲,这可以设置得较低,因为我认为它不会向谷歌提出任何要求。但我不确定,请自行承担调整风险。
SLEEP_BEFORE_MORE是在单击“显示更多结果”按钮之前脚本应等待的时间。这不应设置为低于您可以物理搜索的值。您的 IP 将被禁止。我的是。
代码:搜索词
这就是魔法发生的地方。该search_terms数组应包括您认为会获得您所定位的图像种类的任何术语。
以下是我用来收集魔法符号图像的确切术语集:
search_terms = [
"black and white magic symbol icon",
"black and white arcane symbol icon",
"black and white mystical symbol",
"black and white useful magic symbols icon",
"black and white ancient magic sybol icon",
"black and white key of solomn symbol icon",
"black and white historic magic symbol icon",
"black and white symbols of demons icon",
"black and white magic symbols from book of enoch",
"black and white historical magic symbols icons",
"black and white witchcraft magic symbols icons",
"black and white occult symbols icons",
"black and white rare magic occult symbols icons",
"black and white rare medieval occult symbols icons",
"black and white alchemical symbols icons",
"black and white demonology symbols icons",
"black and white magic language symbols icon",
"black and white magic words symbols glyphs",
"black and white sorcerer symbols",
"black and white magic symbols of power",
"occult religious symbols from old books",
"conjuring symbols",
"magic wards",
"esoteric magic symbols",
"demon summing symbols",
"demon banishing symbols",
"esoteric magic sigils",
"esoteric occult sigils",
"ancient cult symbols",
"gypsy occult symbols",
"Feri Tradition symbols",
"Quimbanda symbols",
"Nagualism symbols",
"Pow-wowing symbols",
"Onmyodo symbols",
"Ku magical symbols",
"Seidhr And Galdr magical symbols",
"Greco-Roman magic symbols",
"Levant magic symbols",
"Book of the Dead magic symbols",
"kali magic symbols",
]
在搜索之前,脚本会检查图像输出目录以确定是否已经为特定术语收集了图像。如果有,脚本将从搜索中排除该术语。这是我的“be cool”代码的一部分。我们不需要两次下载一堆图像。
下面的代码获取我们输出路径中的所有目录,然后根据目录名称重建搜索词(即,它将“_”替换为“”s。)
dirs = glob(output_path + "*")
dirs = [dir.split("/")[-1].replace("_", " ") for dir in dirs]
search_terms = [term for term in search_terms if term not in dirs]
代码:Chromedriver
在启动脚本之前,我们必须启动 Chromedriver 会话。请注意,您必须将chromedriver可执行文件放入PATH变量中列出的文件夹中,以便 Selenium 找到它。
对于 MacOS 用户,手动设置 Chromedriver 以使用 Selenium 有点困难。但是,使用自制软件可以很容易地做到这一点。
brew install chromedriver
如果一切设置正确,执行以下代码将打开 Chrome 浏览器并调出 Google 搜索页面。
wd = webdriver.Chrome()
wd.get("https://google.com")
代码:Chrome 超时
下面的超时类是我从Stack Overflow 的 Thomas Ahle那里借来的。GET这是为下载图像的请求创建超时的肮脏方式。没有它,脚本可能会卡在无响应的图像下载上。
class timeout:
def __init__(self, seconds=1, error_message="Timeout"):
self.seconds = seconds
self.error_message = error_message
def handle_timeout(self, signum, frame):
raise TimeoutError(self.error_message)
def __enter__(self):
signal.signal(signal.SIGALRM, self.handle_timeout)
signal.alarm(self.seconds)
def __exit__(self, type, value, traceback):
signal.alarm(0)
代码:获取图像
我希望我说清楚,下面的代码不是我写的;我刚刚擦亮了它。我将提供一个简短的解释,但请参阅 Bosler 的文章以获取更多信息。
本质上,脚本:
创建与数组中的搜索词相对应的目录。
它将搜索词传递给fetch_image_urls(),此函数驱动 Chrome 会话。该脚本在 Google 中导航以查找与搜索词相关的图像。它将图像链接存储在列表中。在搜索完所有图像或到达 后,num_of_images它返回一个res包含所有图像 URL 的列表 ( )。
图片 URL 列表被传递给persist_image(),然后将每张图片下载到相应的文件夹中。
它会针对每个搜索词重复步骤 1-3。
我添加了额外的评论作为指南:
def fetch_image_urls(
query: str,
max_links_to_fetch: int,
wd: webdriver,
sleep_between_interactions: int = 1,
):
def scroll_to_end(wd):
wd.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(sleep_between_interactions)
# Build the Google Query.
search_url = "https://www.google.com/search?safe=off&site=&tbm=isch&source=hp&q={q}&oq={q}&gs_l=img"
# load the page
wd.get(search_url.format(q=query))
# Declared as a set, to prevent duplicates.
image_urls = set()
image_count = 0
results_start = 0
while image_count < max_links_to_fetch:
scroll_to_end(wd)
# Get all image thumbnail results
thumbnail_results = wd.find_elements_by_css_selector("img.Q4LuWd")
number_results = len(thumbnail_results)
print(
f"Found: {number_results} search results. Extracting links from {results_start}:{number_results}"
)
# Loop through image thumbnail identified
for img in thumbnail_results[results_start:number_results]:
# Try to click every thumbnail such that we can get the real image behind it.
try:
img.click()
time.sleep(sleep_between_interactions)
except Exception:
continue
# Extract image urls
actual_images = wd.find_elements_by_css_selector("img.n3VNCb")
for actual_image in actual_images:
if actual_image.get_attribute(
"src"
) and "http" in actual_image.get_attribute("src"):
image_urls.add(actual_image.get_attribute("src"))
image_count = len(image_urls)
# If the number images found exceeds our `num_of_images`, end the seaerch.
if len(image_urls) >= max_links_to_fetch:
print(f"Found: {len(image_urls)} image links, done!")
break
else:
# If we haven't found all the images we want, let's look for more.
print("Found:", len(image_urls), "image links, looking for more ...")
time.sleep(SLEEP_BEFORE_MORE)
# Check for button signifying no more images.
not_what_you_want_button = ""
try:
not_what_you_want_button = wd.find_element_by_css_selector(".r0zKGf")
except:
pass
# If there are no more images return.
if not_what_you_want_button:
print("No more images available.")
return image_urls
# If there is a "Load More" button, click it.
load_more_button = wd.find_element_by_css_selector(".mye4qd")
if load_more_button and not not_what_you_want_button:
wd.execute_script("document.querySelector('.mye4qd').click();")
# Move the result startpoint further down.
results_start = len(thumbnail_results)
return image_urls
def persist_image(folder_path: str, url: str):
try:
print("Getting image")
# Download the image. If timeout is exceeded, throw an error.
with timeout(GET_IMAGE_TIMEOUT):
image_content = requests.get(url).content
except Exception as e:
print(f"ERROR - Could not download {url} - {e}")
try:
# Convert the image into a bit stream, then save it.
image_file = io.BytesIO(image_content)
image = Image.open(image_file).convert("RGB")
# Create a unique filepath from the contents of the image.
file_path = os.path.join(
folder_path, hashlib.sha1(image_content).hexdigest()[:10] + ".jpg"
)
with open(file_path, "wb") as f:
image.save(f, .jpg", quality=IMAGE_QUALITY)
print(f"SUCCESS - saved {url} - as {file_path}")
except Exception as e:
print(f"ERROR - Could not save {url} - {e}")
def search_and_download(search_term: str, target_path=".https://ladvien.com/images/", number_images=5):
# Create a folder name.
target_folder = os.path.join(target_path, "_".join(search_term.lower().split(" ")))
# Create image folder if needed.
if not os.path.exists(target_folder):
os.makedirs(target_folder)
# Open Chrome
with webdriver.Chrome() as wd:
# Search for images URLs.
res = fetch_image_urls(
search_term,
number_images,
wd=wd,
sleep_between_interactions=SLEEP_BETWEEN_INTERACTIONS,
)
# Download the images.
if res is not None:
for elem in res:
persist_image(target_folder, elem)
else:
print(f"Failed to return links for term: {search_term}")
# Loop through all the search terms.
for term in search_terms:
search_and_download(term, output_path, number_of_images)
结果
抓取图像会产生大量垃圾图像(噪声)以及我理想的训练图像。
例如,在显示的所有图像中,我只想突出显示图像:
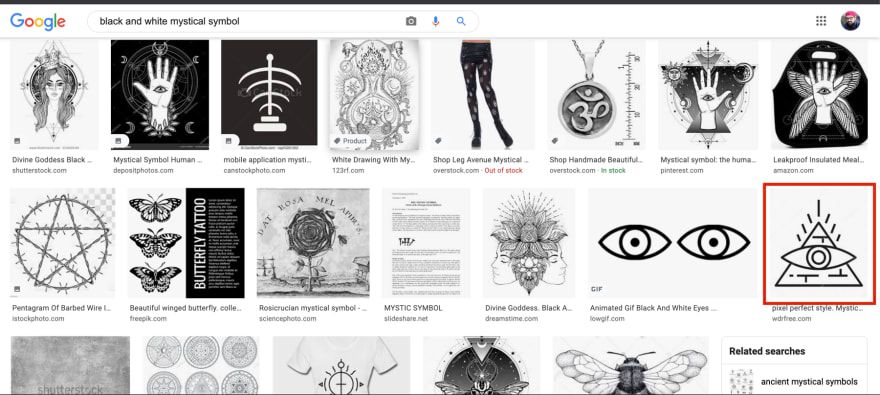
魔法符号训练数据收集噪声样本
还有一个问题是在一个图像中存储了很多魔法符号。这些“集合”图像需要进一步处理以提取所有符号。
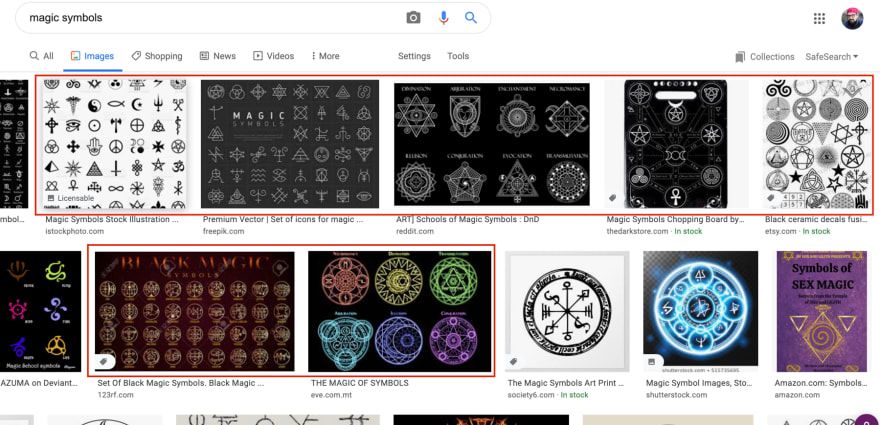
谷歌搜索结果中的魔术符号集合
然而,即使有一些粗糙的边缘,脚本肯定比手动下载我最终拥有的 10k 图像要好得多。