一. 大流量的互联网项目
1.项目背景
索尔老师之前负责的一个项目,业务背景是这样的。城市的基础设施建设是每个城市和地区都会涉及到的,如何在基建工地中实现人性化管理,是当前项目的主要诉求。该项目要实现如下目标:
工地工人的智慧考勤;
考勤机通过面容做人脸识别就能打卡,工人不需要脱手套按指纹,甚至不需要卸下口罩;
工地安全检测;
检测某一个区域没有戴安全帽的工人,可以快速触发总控台,提醒管理员监管;
工地机器的工作情况;
统计工地机器是否正在工作及已经连续工作时长,用于检测机器是否在安全时间内使用。
从上述项目背景中我们就能看出,每一个功能的实现都需要硬件设备来实现:比如人脸识别考勤机来实现智慧打卡,带有人体识别功能的摄像头来捕捉没有戴安全帽的人员,传感器设备来统计机器是否正在工作。

除了工地项目外,还有另一种很有意思的应用场景,就是统计商场、超市的热门门店。大家肯定很好奇,这是怎么实现的?——对!也是通过摄像头。摄像头采集进入商场的人员,不用采集到脸,只需要根据人体的形态、衣服颜色、身高等特征值来标识一个主体。根据人体识别算法,统计哪些类型的人,在什么时间段,去了哪些门店。如果特征值足够匹配,甚至还能统计出性别和老幼。这个应用场景是不是非常有意思?其实,很多城市已经在用这一套系统。甚至还有更有意思的应用场景,物联网早已深入生活,而IOT的项目中的流量数据是非常大的。
索尔为什么要说这些呢?你有没有发现,其实这些都跟硬件设备有关。如果索尔老师所在的公司是一个硬件厂商,或者是一个小B中间商,索尔就需要知道我买的这些设备,是否都能够正常工作。如果能有一个类似于下面这样的数据大屏,那是不是更加完美呢?我们就是这么干的。
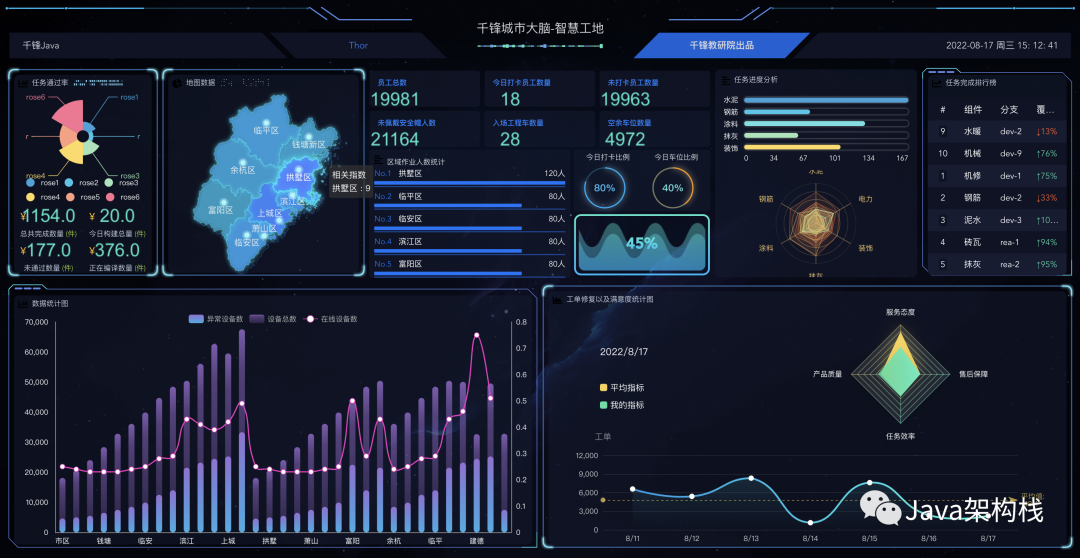
问题来了,设备的心跳数据该多久上报一次?上报时间间隔的不同会对整个系统造成怎样的影响?心跳数据怎么判断设备是否正常?会有多少的心跳数据?
2.设备上报心跳的时间间隔
设备的上报心跳动作其实是一个很简单的逻辑,就是上报将自己的设备key,和当前时间封装成一个http请求消息,发送给平台。
根据当时硬件部门的设定,不同设备的约定不同,每个设备大致会在2秒到5秒之间向平台发送一次心跳。
3.如何通过心跳计算出当前时间段设备是否正常
根据目前的情况,平台收到的设备的心跳信息可以通过这张表体现出来:
| 列名 | 类型 | 注释 |
| DEVICE_KEY |
varchar(32) |
设备id |
| LAST_ACTIVE_TIME |
datetime |
最后活跃时间 |
这个表就是用来记录当前设备的最后活跃时间。那么问题来了,该怎么统计当前时间段的正常设备和异常设备?多久没有上报心跳的设备会被判定为异常设备呢?
心跳、服务发现。对!你也发现了,它们好像在描述同一件事情。在这里,索尔老师参考了微服务中注册中心对于服务剔除的方案。比如Nacos的服务健康检查机制:
Nacos Server会开启一个定时任务用来检查注册服务实例的健康情况,对于超过15秒没有收到客户端心跳的实例会将它的健康属性置为false,如果某个实例超过30秒没有收到心跳,则直接剔除该实例。
索尔开启了一个每隔30秒定时任务,去设备心跳表中统计今日上报心跳的设备数量,具体的sql操作如下:
select count(device_key) from tb_device
where last_active_time >= '2023-10-10 00:00:00' and ast_active_time <= '2023-10-10 23:59:59'针对于这条sql,有同学会问,为什么不直接用日期函数:
select count(device_key) from tb_device
where date(last_active_time) = '2023-10-10'因为性能,使用函数会导致索引失效,关于SQL优化这一块的内容,大家可以在索尔老师的MySQL优化专题里进行学习。

我们可以将统计到的数据,维护在redis中。也就是说,redis中维护了今日正常设备的总数,这个数据每30秒更新一次。
4.并发量的产生
在上一章节中我们提到,任何一个设备,都会上报其心跳到平台,而且每个设备会每隔2到5秒左右上报一次心跳,我们试算下:
一台设备:每隔3秒上报一次;
三十万台设备:每隔3秒会上报30万次;
平台:每秒接收到10万次访问,每天将会收到将近百亿的消息。
可以推算出,一个平台基本上每秒都会收到大约10万次访问。这样的并发量不算大,但也不能说少,而且这样每秒10万的请求是持续的,这10万的请求每秒都会来,不间断的来,此时考验后端接口的时刻就到了。
5.业务如何处理
后端接口做到高性能、高可用设计,我们会在之后的专题去讲,这里先聊一下接口收到数据后,该如何处理。
很显然,接口收到设备上报的心跳数据后,要把数据落到数据库里。这就是具体业务要做的事,很简单,只要落到数据库里就可以。
二. 待解决的核心业务逻辑
1.项目模块
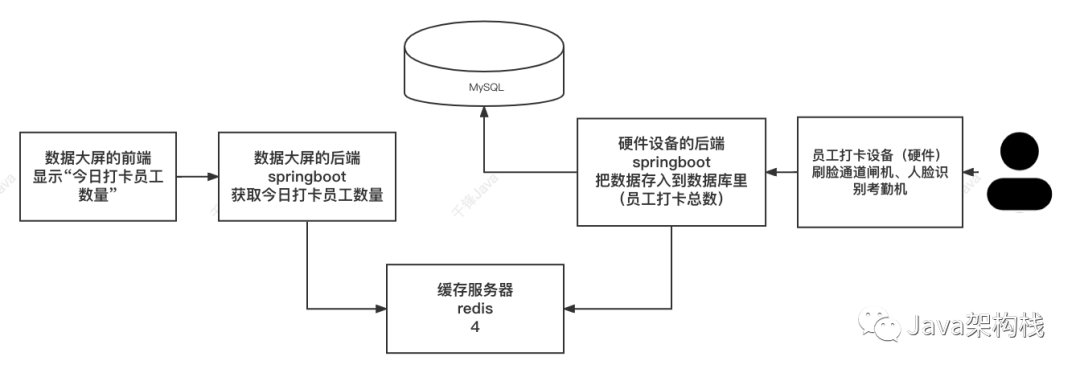
整个项目分成了以下几个子项目:
数据大屏前端项目
数据大屏后端项目
硬件后端项目
硬件设备
Redis缓存服务器
MySQL关系型数据库
这些项目之间有着重要的联系,这样的联系可以总结为两点:一是数据大屏的后端为数据大屏的前端提供数据,二是硬件设备的后端供硬件设备访问实现数据交互。
那么问题来了,以第一点为例,后端和前端的数据交互方式是什么样?
2.前后端交互方式
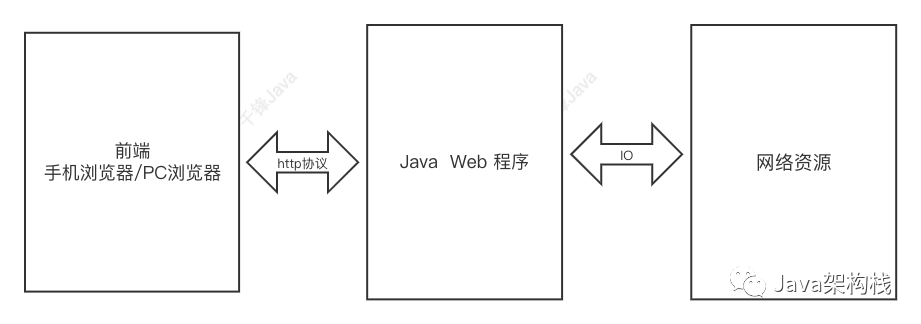
“前端”的概念可以是多种终端的浏览器。部署在web服务器上的Java Web应用程序(即“后端”)提供了供http协议访问的web接口,也就是程序的调用入口。前端通过http协议访问后端的web接口,实现数据的交互。比如前端通过http协议访问后端获取网络资源的web接口,后端通过io流的方式获得网络资源并使用http协议返回给前端。这就是一个完整的前后端交互过程。
3.核心业务
硬件如何访问到Java程序;
硬件也可以通过http协议来访问到java的web接口;
数据存到哪;
打卡机等硬件生成员工的打卡数据,将数据发送给后端Java程序,Java程序将数据保存到MySQL数据库中。但这还不够,因为数据大屏的前端也需要获得数据,于是需要让数据大屏的后端去数据库获取数据;
优化点在哪里。
很显然,设备的数据量非常大,势必给数据库造成过大的压力。优化点就在于如何让数据库更轻松一些。使用在处理能力上面非常优秀的Redis缓存数据库,解决数据库的压力。此时,与硬件对应的后端java程序将数据存入到redis中,数据大屏的后端程序从redis中取出数据,展示在数据大屏前端项目中。
三. 核心业务代码
1.供硬件访问的后端Java程序
1.1 Controller
/**
* @author Thor
* @公众号 Java架构栈
*/
@RestController
@RequestMapping("/device")
public class DeviceController {
@Autowired
private DeviceService deviceService;
@PostMapping("/mark")
public ResultModel mark(@RequestBody Worker worker){
if(Objects.isNull(worker) || Objects.isNull(worker.getId())){
return ResultModel.error();
}
return deviceService.mark(worker);
}
}1.2 service
/**
* @author Thor
* @公众号 Java架构栈
*/
@Service
public class DeviceServiceImpl implements DeviceService {
@Autowired
private StringRedisTemplate redisTemplate;
/**
* 拿到数据,存入到redis中:让打卡的员工总数+1
* @param worker
* @return
*/
@Override
public ResultModel mark(Worker worker) {
//TODO 把打卡信息存入到数据库中
//将redis中的打卡员工总数+1
try {
redisTemplate.opsForValue().increment("worker:total");
} catch (Exception e) {
e.printStackTrace();
ResultModel.error();
}
return ResultModel.success();
}
}2.数据大屏前端访问后端接口
setData(){
const { workerTotal } = this
var vm = this;
this.axios({
method:'get',
url:'http://localhost:9001/worker/total'
}).then(function(response){
var data = response.data;
if(data.code==1000){
console.log(data.data);
vm.workerTotal.number[0] = data.data;
}
})
this.workerTotal.number[0] = vm.workerTotal.number[0];
this.workerTotal = { ...this.workerTotal }
}前端使用VUE的axios来发送http请求,访问后端接口,并实时展示在DataV前端数据大屏框架的翻牌器组件中。
3.数据大屏后端提供数据的接口
3.1 Controller
/**
* @author Thor
* @公众号 Java架构栈
*/
@RestController
@RequestMapping("/worker")
@CrossOrigin
public class ViewController {
@Autowired
private ViewService viewService;
@GetMapping("/total")
public ResultModel getTotal(){
return viewService.getTotal();
}
}3.2 service
/**
* @author Thor
* @公众号 Java架构栈
*/
@Service
public class ViewServiceImpl implements ViewService {
@Autowired
private StringRedisTemplate redisTemplate;
/**
* 从redis中获得打卡总数的数据
* @return
*/
@Override
public ResultModel<Integer> getTotal() {
String result = redisTemplate.opsForValue().get("worker:total");
return ResultModel.success(Integer.parseInt(result));
}
}四. 前后端联调及测试
1.使用Postman测试后端硬件打卡接口
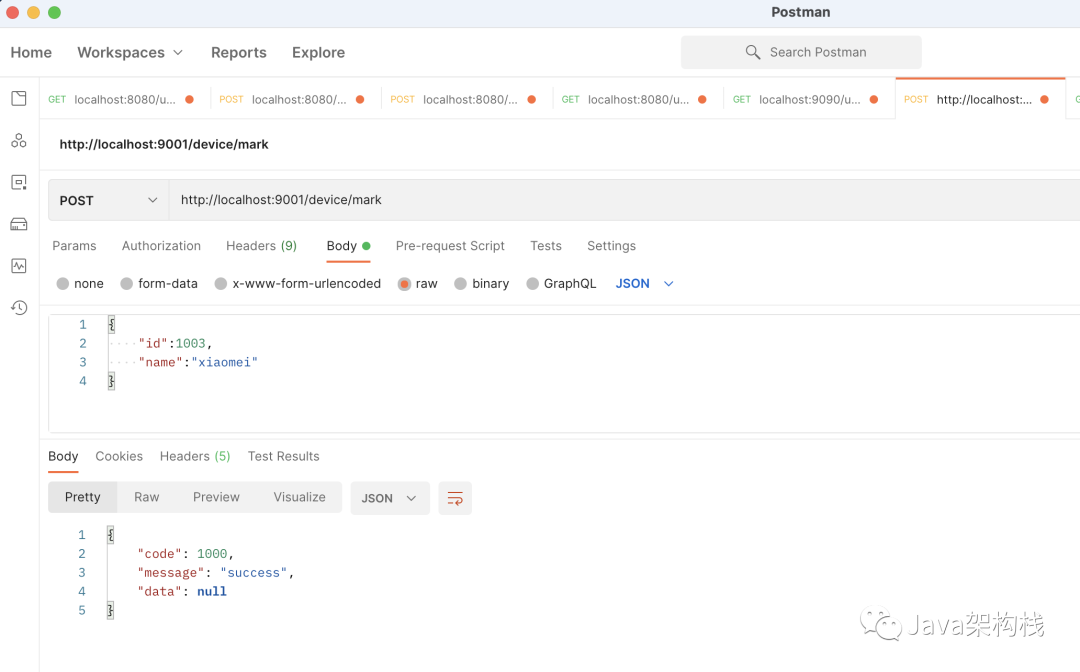
模拟使用id是1003,姓名是xiaoming的用户进行打卡,并返回打卡成功。
2.使用Postman测试后端获得打卡数据接口
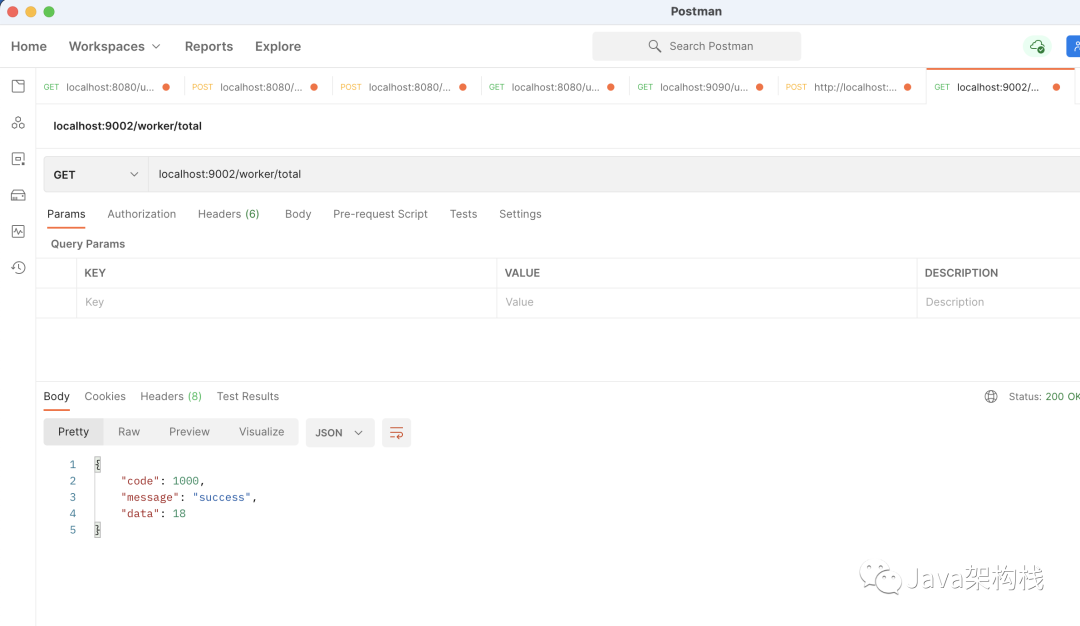
访问后端获得打卡总数的接口,获得的打卡总数为18。
3.启动前端项目获得打卡总数
在项目路径中使用cnpm install 安装vue项目需要的依赖;
在项目路径中使用npm run serve 启动项目;
获得页面数据。
以上内容就是索尔为大家分享的亿级流量互联网项目构建思路,不知道你现在是不是得到了一些启发呢?在我们的线下课程里,这个智慧工地的项目会有详细的讲解哦,欢迎你来学习。