Linux-进程调度简介
前言
Linux内核版本:2.6.26。
进程的区分
交互式进程:这些进程常常与用户进程交互。因此,需要很多的时间等待用户的输入。当接受到输入后,进程必须被很快唤醒,否则用户会发现系统反应迟钝。典型的交互式程序有:shell命令行、文本编辑程序及图形应用程序。
批处理进程:这些进程不必与用户进行交互,因此经常在后台运行。
实时进程:这些程序有很强的调度需要。这些进程绝不会被低优先级的程序阻塞。它们有一个短的响应时间,更重要的是,响应时间的变化应该很小。例如:从物理传感器上收集数据的程序。
Linux中进程调度的类型
//include/linux/sched.h
/*
* Scheduling policies
*/
#define SCHED_NORMAL 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#define SCHED_BATCH 3
/* SCHED_ISO: reserved but not implemented yet */
#define SCHED_IDLE 5
- SCHED_FIFO:先进先出的实时进程。当调度程序把CPU分给进程的时候,他把该进程的进程描述符保存在运行队列链表的当前位置。如果没有其他可运行的更高优先级的实时进程,那么该进程就继续使用CPU,想用多久用多久,即使还有其他具有相同优先级的实时进程处于可运行状态。
- SCHED_RR:时间片轮转的实时进程。当调度程序把CPU分配给进程的时候,他把该进程的描述符放在运行队列链表的末尾。这种策略保证对所有具有相同优先级的SCHED_RR实时进程公平的分配CPU时间。同一优先级的SCHED_RR实时进程具有相同的运行时间,当SCHED_RR进程时间片耗尽的时候,在同一优先级的其他实时进程轮流调度。
- SCHED_NORMAL:普通的分时进程。并且采用的调度算法是完全公平调度算法,简称CFS。
- SCHED_BATCH:针对批处理进程的调度,适合那些非交互性且对 cpu 使用密集的进程
- SCHED_IDLE:适用于优先级较低的后台进程
注:每个进程的调度策略保存在进程描述符 task_struct 中的 policy 字段。
Linux 支持两种类型的进程调度,三种常见的调度策略。即实时进程采用 SCHED_FIFO 和 SCHED_RR 调度策略,普通进程采用 SCHED_NORMAL 策略。
进程调度
Linux在2.6.23之后的版本中使用“完全公平调度算法”,简称CFS,并代替了O(I)调度算法。Linux进程调度中有两个重要概念,优先级和时间片。
进程优先级
调度算法中最基本的一类就是基于优先级调度。通常的做法是优先级高的先运行,低的后运行,相同优先级的进程按轮转方式进行调度调度。(其并未被Linux系统完全采用)
Linux中采用了两种不同的优先级范围。第一种为nice优先级,适用于普通进程。还有一种是实时优先级,适用于实时进程。这两种优先级处于互不相交的范畴。
nice值
nice值优先级,它的变化范围为-20~19,默认值为0,越大的nice值意味着更低的优先级。相比于高nice值(低优先级),低nice值(高优先级)的进程可以获得更多的处理器时间。在Linux中,nice值代表时间片的比例。
下图中NI这一列代表的就是nice值:
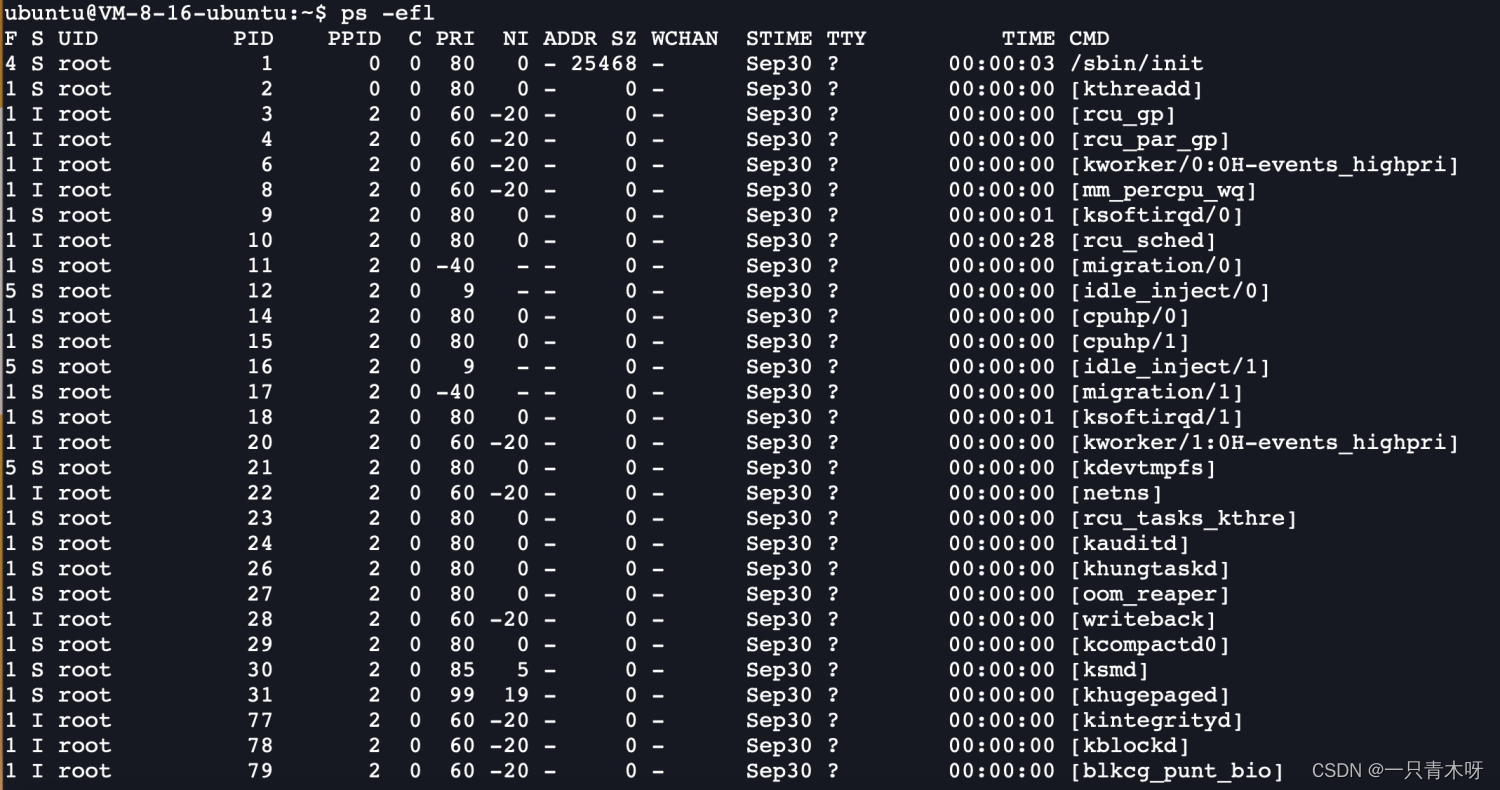
实时优先级
实时优先级默认情况下它的变化范围是0~99。余nice值相反,越高的实时优先级数值意味着进程的优先级越高,任何实时进程的优先级都高于普通进程。
下图中PTPRIO这一列代表的就是实时进程的值:
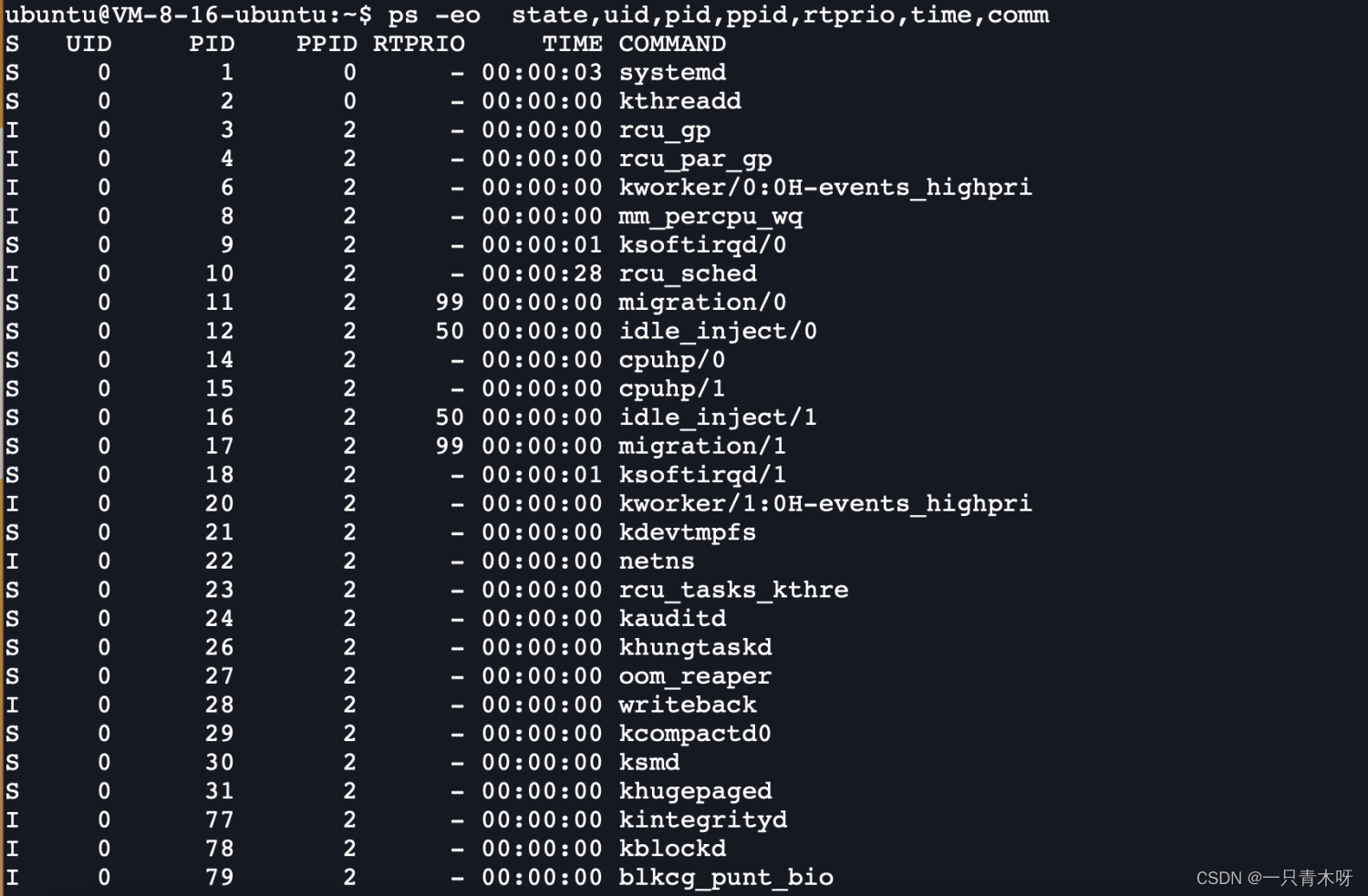
其中“-”表示此进程不是实时进程。
时间片
时间片是一个数值,它表明进程在被抢占前所能持续运行的时间。
在Linux中,CFS调度器并没有完全分配时间片到进程,它是将处理器的使用比例分配给了进程。
抢占
Linux系统是抢占式的。当一个进程进入可运行态,他就被准许投入运行。在Linux的CFS调度器中,其抢占时机取决于新的可运行程序消耗了多少处理器使用比。如果消耗的使用比比挡前的进程小,则新进程立刻投入运行,抢占当前进程。否则,将推迟运行。
调度器类
内核引入调度类(struct sched_class)说明了调度器应该具有哪些功能。内核中每种调度策略都有该调度类的一个实例。(比如:基于公平调度类为:fair_sched_class,基于实时进程的调度类实例为:rt_sched_class),该实例也是针对每种调度策略的具体实现。调度类封装了不同调度策略的具体实现,屏蔽了各种调度策略的细节实现。
调度器核心函数 schedule() 只需要调用调度类中的接口,完成进程的调度,完全不需要考虑调度策略的具体实现。调度类连接了调度函数和具体的调度策略。
CFS公平调度
完全公平调度(CFS)是一个基于普通进程的调度器类,在Linux称为SCHED_NORMAL,CFS算法实现定义在文件kernel/sched_fair.c中。
- CFS的出发点基于一个简单的理念:进程调度的效果应如同系统具备一个理想中的完美多任务处理器。例如,在优先级相同的情况下,有10个进程,每个进程都可以获得1/10的处理器时间。
- CFS的具体做法:允许每一个进程运行一段时间、循环轮转、选择运行最小的进程作为下一个进程。
- CFS在所有可运行进程总数基础上计算出一个进程应该运行多久,而不是依靠nice值来计算时间片。
- nice值在CFS中被作为进程获得处理器运行比的权重:越高的nice值(越低的优先级),获得更低的处理器使用权重;相反越低的nice值(越高的优先级)的进程获得更高的处理器使用权重。
- CFS引入每个进程获得的时间片底线,这个底线称之为最小粒度,默认情况下这个值是1ms。
- 任何进程所获得的处理器时间是由它自己和其它所有可运行进程nice值的相对差值决定的。并且nice值对时间片的作用是几何加权。
Linux调度的实现
Linux 支持两种类型的进程调度,三种常见的调度策略。即实时进程采用 SCHED_FIFO 和 SCHED_RR 调度策略,普通进程采用 SCHED_NORMAL 策略。
并且在采用 SCHED_NORMAL 策略时,使用了完全公平调度算法(CFS),CSF其相关的代码在
kernel/sched_fair.c中。
时间记账
在CFS中,需要确保每个进程只在公平分配给他的时间内运行。那么就需要记录其时间。
在task_struct中使用一个叫se的变量表示记录调度器相关信息,如下:
//include/linux/sched.h
struct task_struct {
......
struct sched_entity se;
......
};
调度器实体结构如下:
struct sched_entity {
struct load_weight load; /* for load-balancing */
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 last_wakeup;
u64 avg_overlap;
#ifdef CONFIG_SCHEDSTATS
u64 wait_start;
u64 wait_max;
u64 wait_count;
u64 wait_sum;
······
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
struct cfs_rq *my_q;
#endif
};
其中vruntime变量存放进程的虚拟运行时间。以ns为单位。
在kernel/sched_fair.c中使用update_curr()完成了记账的功能。并且update_curr()函数,由系统定时器周期性的调用,无论进程在什么状态。根据这种方式,vruntime可以准确的给定进程的运行时间,并且可知道谁应该是下一个被运行的进程。
进程选择
- 当CFS需要选择下一个运行进程的时候,他会挑选一个具有最小vruntime的进程。
- CFS只用红黑树(rbtree)来组织可运行进程队列,并利用其快速找到最小vruntime的进程。
- CFS快速找到最小vruntime的进程:它对应的便是树中最左侧的叶子结点。由kernel/sched_fair.c中的__pick_next_entity()函数完成。该函数的返回值就是CFS调度的下一个运行的进程。
调度器入口
调度器主要入口点函数是schedule(),该函数定义在include/linux/sched.h中:
/*
* schedule() is the main scheduler function.
*/
asmlinkage void __sched schedule(void)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq *rq;
int cpu;
need_resched:
//禁止内核抢占
preempt_disable();
cpu = smp_processor_id();
//获取当前CPU对应的就绪队列
rq = cpu_rq(cpu);
rcu_qsctr_inc(cpu);
prev = rq->curr;
//获取当前进程的切换次数
switch_count = &prev->nivcsw;
release_kernel_lock(prev);
need_resched_nonpreemptible:
schedule_debug(prev);
hrtick_clear(rq);
/*
* Do the rq-clock update outside the rq lock:
*/
local_irq_disable();
//更新就绪队列上的时钟
update_rq_clock(rq);
spin_lock(&rq->lock);
//清除当前进程prev的重新调度标志
clear_tsk_need_resched(prev);
if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {
if (unlikely(signal_pending_state(prev->state, prev)))
prev->state = TASK_RUNNING;
else
//将当前进程从就绪队列中删除
deactivate_task(rq, prev, 1);
switch_count = &prev->nvcsw;
}
#ifdef CONFIG_SMP
if (prev->sched_class->pre_schedule)
prev->sched_class->pre_schedule(rq, prev);
#endif
if (unlikely(!rq->nr_running))
idle_balance(cpu, rq);
//将当前进程重新放入就绪队列
prev->sched_class->put_prev_task(rq, prev);
/*以优先级为序,从高到低,依次检查每个调度类,并从最高优先级的调度类中选组最高优先级的进程运行*/
next = pick_next_task(rq, prev);
if (likely(prev != next)) {
sched_info_switch(prev, next);
rq->nr_switches++;
rq->curr = next;
++*switch_count;
//进行 prev 和 next 两个进程的切换。具体的切换代码与体系架构有关,在 switch_to() 中通过一段汇编代码实现。
context_switch(rq, prev, next); /* unlocks the rq */
/*
* the context switch might have flipped the stack from under
* us, hence refresh the local variables.
*/
cpu = smp_processor_id();
rq = cpu_rq(cpu);
} else
spin_unlock_irq(&rq->lock);
hrtick_set(rq);
if (unlikely(reacquire_kernel_lock(current) < 0))
goto need_resched_nonpreemptible;
preempt_enable_no_resched();
if (unlikely(test_thread_flag(TIF_NEED_RESCHED)))
goto need_resched;
}
主要的函数见注释。
进程的睡眠和唤醒
休眠(被阻塞)的进程处于一个特殊的不可执行状态。
进程的休眠有很多种原因,但内核的操作都相同:
睡眠:进程把自己标记成休眠状态,从可执行的红黑树中移出,放入等待队列,然后调用schedule()选择和调用下一个进程。
唤醒:进程被设置成可执行状态,然后从等待队列中移动到可执行队列中。
上下文切换
上下文切换就是从一个可执行进程切换到另一个可执行进程。由context_switch()函数负责处理,定义在include/linux/sched.h中。
/*
* context_switch - switch to the new MM and the new
* thread's register state.
*/
static inline void
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next)
{
struct mm_struct *mm, *oldmm;
prepare_task_switch(rq, prev, next);
mm = next->mm;
oldmm = prev->active_mm;
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
arch_enter_lazy_cpu_mode();
if (unlikely(!mm)) {
next->active_mm = oldmm;
atomic_inc(&oldmm->mm_count);
enter_lazy_tlb(oldmm, next);
} else
switch_mm(oldmm, mm, next);
if (unlikely(!prev->mm)) {
prev->active_mm = NULL;
rq->prev_mm = oldmm;
}
/*
* Since the runqueue lock will be released by the next
* task (which is an invalid locking op but in the case
* of the scheduler it's an obvious special-case), so we
* do an early lockdep release here:
*/
#ifndef __ARCH_WANT_UNLOCKED_CTXSW
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
#endif
/* Here we just switch the register state and the stack. */
switch_to(prev, next, prev);
barrier();
/*
* this_rq must be evaluated again because prev may have moved
* CPUs since it called schedule(), thus the 'rq' on its stack
* frame will be invalid.
*/
finish_task_switch(this_rq(), prev);
}
- switch_mm()函数负责把虚拟内存从上一个进程映射切换到新进程中。
- switch_to()函数负责从上一个进程的处理器状态切换到新进程的处理器状态(包括保存、恢复栈信息和寄存器信息、其他信息等)。
内核提供了一个need_resched标志来表明是否需要重新执行一次调度。need_resched标志在thread_info结构体中,用一个特别的标志变量中的一位来表示。
抢占
抢占分为用户抢占和内核抢占。
用户抢占
- 内核即将返回用户空间时,如果need_resched标志被设置,会导致schedule()函数被调用,此时就会发生用户抢占。
- 用户抢占在以下情况时产生:
一、从系统调用返回用户空间
二、从中断处理程序返回用户空间时
内核抢占
在Linux中,系统完整的支持内核抢占。只要重新调度是安全的,内核就可以在任何时间抢占执行的任务。
什么时候重新调度是安全的?
只要没有持有锁,内核就可以执行抢占。锁是非抢占区域的标志。
内核中每个进程的thread_info中preempt_count计数器用来支持内核抢占。该计数器初始值为0,当使用锁的时候加1,释放锁的时候减1,当数值为0的时候,内核就可以进行抢占。
内核抢占会发生在:
中断处理程序正在执行,并且返回内核空间之前。
内核代码再一次具有可抢占性的时候。
内核中显示的调用schedule函数。
内核中的任务阻塞。
文章内容参考《内核设计与实现》第三版、深入了解Linux内核第三版。