Redis 的过期策略以及内存淘汰机制详解
1. Redis 的过期策略
Redis 在存储数据时,如果指定了过期时间,缓存数据到了过期时间就会失效,那么 Redis 是如何处理这些失效的缓存数据呢?这就用到了 Redis 的过期策略 - 定期删除 + 惰性删除。下面我们带着问题一起来学习 Redis 的过期策略。
1.1 如何设置 key 的过期时间?
- Redis 在指定 expire 时间后自动移除给定的键
设置 key 秒级精度的过期时间
EXPIRE key seconds
# 设置 key 毫秒级精度的过期时间
PEXPIRE key milliseconds
- Redis 在指定 unix 时间来临之后自动移除给定的键
设置 key 秒级精度的过期时间戳(unix timestamp)
EXPIREAT key seconds_timestamp
# 设置 key 毫秒级精度的过期时间戳(unix timestamp) 以毫秒计
PEXPIREAT key milliseconds_timestamp
1.2 key 设置且到了过期时间后,该 key 保存的数据还占据内存么?
当 key 过期后,该 key 保存的数据还是会占据内存的。
因为每当我们设置一个 key 的过期时间时,Redis 会将该键带上过期时间存放到一个过期字典中。当 key 过期后,如果没有触发 Redis 的删除策略的话,过期后的数据依然会保存在内存中的,这时候即便这个 key 已经过期,我们还是能够获取到这个 key 的数据。
1.3 Redis 如何删除过期的数据
Redis 使用:“定期删除 + 惰性删除” 策略删除过期数据。
1.3.1 定期删除
Redis 默认每隔 100ms 就随机抽取部分设置了过期时间的 key,检测这些 key 是否过期,如果过期了就将其删除。
- 100ms 是怎么来的?
定期任务是 Redis 服务正常运行的保障,它的执行频率由 hz 参数的值指定,默认为10,即每秒执行10次。
hz 10
5.0 之前的 Redis 版本,hz 参数一旦设定之后就是固定的了。hz 默认是 10。这也是官方建议的配置。如果改大,表示在 Redis 空闲时会用更多的 CPU 去执行这些任务。官方并不建议这样做。但是,如果连接数特别多,在这种情况下应该给与更多的 CPU 时间执行后台任务。
Redis 5.0之后,有了 dynamic-hz 参数,默认就是打开。当连接数很多时,自动加倍 hz,以便处理更多的连接。
dynamic-hz yes
- 为什么是随机抽取部分 key,而不是全部 key?
因为如果 Redis 里面有大量 key 都设置了过期时间,全部都去检测一遍的话 CPU 负载就会很高,会浪费大量的时间在检测上面,甚至直接导致 Redis 挂掉。所有只会抽取一部分而不会全部检查。
随机抽取部分检测,部分是多少?是由 redis.conf 文件中的 maxmemory-samples 属性决定的,默认为 5。
# The default of 5 produces good enough results. 10 Approximates very closely
# true LRU but costs more CPU. 3 is faster but not very accurate.
#
# maxmemory-samples 5
正因为定期删除只是随机抽取部分 key 来检测,这样的话就会出现大量已经过期的 key 并没有被删除,这就是为什么有时候大量的 key 明明已经过了失效时间,但是 Redis 的内存还是被大量占用的原因 ,为了解决这个问题,Redis 又引入了"惰性删除策略"。
1.3.2 惰性删除
惰性删除不是去主动删除,而是在你要获取某个 key 的时候,Redis 会先去检测一下这个 key 是否已经过期,如果没有过期则返回给你,如果已经过期了,那么 Redis 会删除这个 key,不会返回给你。
“定期删除 + 惰性删除” 就能保证过期的 key 最终一定会被删掉 ,但是只能保证最终一定会被删除,要是定期删除遗漏的大量过期 key,我们在很长的一段时间内也没有再访问这些 key,那么这些过期 key 不就一直会存在于内存中吗?不就会一直占着我们的内存吗?这样不还是会导致 Redis 内存耗尽吗?由于存在这样的问题,所以 Redis 又引入了"内存淘汰机制"来解决。
2. Redis 的内存淘汰机制
2.1 Redis 最大内存淘汰机制有哪些?
-
volatile-lru:当内存不足执行写入操作时,在设
置了过期时间的键空间中,移除最近最少(最长时间)使用的 key。 -
allkeys-lru:当内存不足执行写入操作时,在
整个键空间中,移除最近最少(最长时间)使用的 key。(这个是最常用的) -
volatile-lfu:当内存不足执行写入操作时,在
设置了过期时间的键空间中,移除最不经常(最少次)使用的key。 -
allkeys-lfu:当内存不足执行写入操作时,在
整个键空间中,移除最不经常(最少次)使用的key。 -
volatile-random -> 当内存不足执行写入操作时,在
设置了过期时间的键空间中,随机移除某个 key。 -
allkeys-random -> 当内存不足执行写入操作时,在
整个键空间中,随机移除某个 key。 -
volatile-ttl -> 当内存不足执行写入操作时,在
设置了过期时间的键空间中,优先移除过期时间最早(剩余存活时间最短)的 key。 -
noeviction:不删除任何 key, 只是在内存不足写操作时返回一个错误。(默认选项,一般不会选用)
2.2 如何设置 Redis 最大内存?
redis.conf 配置文件中的 maxmemory 属性限定了 Redis 最大内存使用量,当占用内存大于 maxmemory 的配置值时会执行内存淘汰机制。
# maxmemory <bytes>
当达到设置的内存使用限制时,Redis 将根据选择的内存淘汰机制(maxmemory-policy)删除 key。
2.3 如何设置 Redis 内存淘汰机制?
内存淘汰机制由 redis.conf 配置文件中的 maxmemory-policy 属性设置,没有配置时默认为 noeviction:不删除任何 策略
# maxmemory-policy noeviction
3. LRU 和 LFU 算法
3.1 概念
3.1.1 LRU(Least Recently Used)算法
LRU:最近最少使用淘汰算法(Least Recently Used)。LRU 是淘汰最近最久未使用的数据。
3.1.2 LFU(Least Frequently Used)算法
LFU:最不经常使用淘汰算法(Least Frequently Used)。LFU是淘汰一段时间内,使用次数最少的数据。
3.2 区别
LRU 关键是看最后一次被使用到发生替换的时间长短,时间越长,就会被淘汰;而 LFU 关键是看一定时间段内被使用的频率(次数),使用频率越低,就会被淘汰。
LRU 算法适合:较大的文件比如游戏客户端(最近加载的地图文件);
LFU 算法适合:较小的文件和教零碎的文件比如系统文件、应用程序文件。
LRU 消耗 CPU 资源较少,LFU 消耗 CPU 资源较多。
3.3 实现
3.3.1 LRU
这里用 leetcode 中一道面试题:LRU 缓存 来设计和构建一个 “最近最少使用” 缓存。
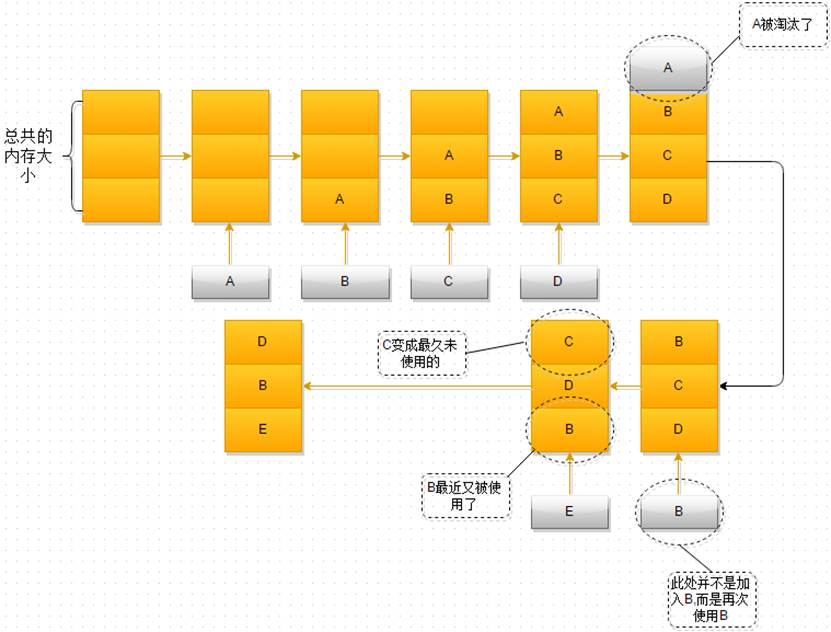
-
关键实现:
-
LRUCache(int capacity):容量,大于容量选择最久未使用资源淘汰。 -
get(key):如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。 -
put(key, value):如果密钥不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。
-
public class LRUCache {
private class Node{
Node prev;
Node next;
int key;
int value;
public Node(int key, int value) {
this.key = key;
this.value = value;
this.prev = null;
this.next = null;
}
}
private int capacity;
private HashMap<Integer, Node> hs = new HashMap<Integer, Node>();
private Node head = new Node(-1, -1);
private Node tail = new Node(-1, -1);
// @param capacity, an integer
public LRUCache(int capacity) {
// write your code here
this.capacity = capacity;
tail.prev = head;
head.next = tail;
}
// @return an integer
public int get(int key) {
// write your code here
if( !hs.containsKey(key)) {
return -1;
}
// remove current
Node current = hs.get(key);
current.prev.next = current.next;
current.next.prev = current.prev;
// move current to tail
move_to_tail(current);
return hs.get(key).value;
}
// @param key, an integer
// @param value, an integer
// @return nothing
public void set(int key, int value) {
// write your code here
if( get(key) != -1) {
hs.get(key).value = value;
return;
}
if (hs.size() == capacity) {
hs.remove(head.next.key);
head.next = head.next.next;
head.next.prev = head;
}
Node insert = new Node(key, value);
hs.put(key, insert);
move_to_tail(insert);
}
private void move_to_tail(Node current) {
current.prev = tail.prev;
tail.prev = current;
current.prev.next = current;
current.next = tail;
}
public static void main(String[] as) throws Exception {
LRUCache cache = new LRUCache(3);
cache.set(2, 2);
cache.set(1, 1);
System.out.println(cache.get(2));
System.out.println(cache.get(1));
System.out.println(cache.get(2));
cache.set(3, 3);
cache.set(4, 4);
System.out.println(cache.get(3));
System.out.println(cache.get(2));
System.out.println(cache.get(1));
System.out.println(cache.get(4));
}
}
3.3.2 LFU
这里用 leetcode 中一道面试题:最不经常使用 LFU 缓存 算法设计并实现数据结构。
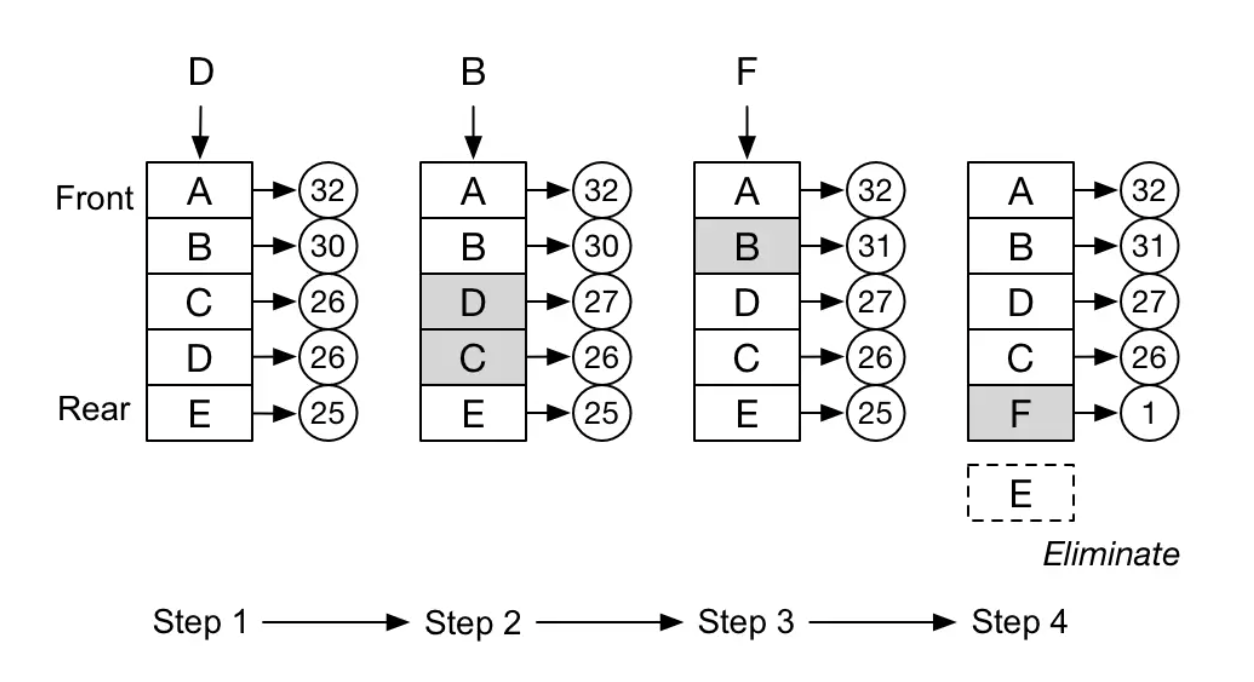
-
关键实现
-
LFUCache(int capacity)- 用数据结构的容量 capacity 初始化对象。 -
int get(int key)- 如果键 key 存在于缓存中,则获取键的值,否则返回 -1 。 -
void put(int key, int value)- 如果键 key 已存在,则变更其值;如果键不存在,请插入键值对。当缓存达到其容量 capacity 时,则应该在插入新项之前,移除最不经常使用的项。在此问题中,当存在平局(即两个或更多个键具有相同使用频率)时,应该去除 最近最久未使用 的键。
-
public class LFUCache {
private static final int DEFAULT_MAX_SIZE = 3;
private int capacity = DEFAULT_MAX_SIZE;
//保存缓存的访问频率和时间
private final Map<Integer, HitRate> cache = new HashMap<Integer, HitRate>();
//保存缓存的KV
private final Map<Integer, Integer> KV = new HashMap<Integer, Integer>();
// @param capacity, an integer
public LFUCache(int capacity) {
this.capacity = capacity;
}
// @param key, an integer
// @param value, an integer
// @return nothing
public void set(int key, int value) {
Integer v = KV.get(key);
if (v == null) {
if (cache.size() == capacity) {
Integer k = getKickedKey();
KV.remove(k);
cache.remove(k);
}
cache.put(key, new HitRate(key, 1, System.nanoTime()));
} else {
//若是key相同只增加频率,更新时间,并不进行置换
HitRate hitRate = cache.get(key);
hitRate.hitCount += 1;
hitRate.lastTime = System.nanoTime();
}
KV.put(key, value);
}
public int get(int key) {
Integer v = KV.get(key);
if (v != null) {
HitRate hitRate = cache.get(key);
hitRate.hitCount += 1;
hitRate.lastTime = System.nanoTime();
return v;
}
return -1;
}
// @return 要被置换的key
private Integer getKickedKey() {
HitRate min = Collections.min(cache.values());
return min.key;
}
class HitRate implements Comparable<HitRate> {
Integer key;
Integer hitCount; // 命中次数
Long lastTime; // 上次命中时间
public HitRate(Integer key, Integer hitCount, Long lastTime) {
this.key = key;
this.hitCount = hitCount;
this.lastTime = lastTime;
}
public int compareTo(HitRate o) {
int hr = hitCount.compareTo(o.hitCount);
return hr != 0 ? hr : lastTime.compareTo(o.lastTime);
}
}
public static void main(String[] as) throws Exception {
LFUCache cache = new LFUCache(3);
cache.set(2, 2);
cache.set(1, 1);
System.out.println(cache.get(2));
System.out.println(cache.get(1));
System.out.println(cache.get(2));
cache.set(3, 3);
cache.set(4, 4);
System.out.println(cache.get(3));
System.out.println(cache.get(2));
System.out.println(cache.get(1));
System.out.println(cache.get(4));
}
}
4. 其他场景对过期 key 的处理
4.1 快照生成 RDB 文件时
过期的 key 不会被保存在 RDB 文件中。
4.2 服务重启载入 RDB 文件时
Master 载入 RDB 时,文件中的未过期的键会被正常载入,过期键则会被忽略。Slave 载入 RDB 时,文件中的所有键都会被载入,当主从同步时,再和 Master 保持一致。
4.3 AOF 文件写入时
因为 AOF 保存的是执行过的 Redis 命令,所以如果 Redis 还没有执行 del,AOF 文件中也不会保存 del 操作,当过期 key 被删除时,DEL 命令也会被同步到 AOF 文件中去。
4.4 重写 AOF 文件时
执行 BGREWRITEAOF 时 ,过期的 key 不会被记录到 AOF 文件中。
4.5 主从同步时
Master 删除 过期 Key 之后,会向所有 Slave 服务器发送一个 DEL 命令,Slave 收到通知之后,会删除这些 Key。
Slave 在读取过期键时,不会做判断删除操作,而是继续返回该键对应的值,只有当 Master 发送 DEL 通知,Slave 才会删除过期键,这是统一、中心化的键删除策略,保证主从服务器的数据一致性。