目 录
1 设计任务
1.1项目开发背景与意义
1.1.1 项目开发背景
1.1.2 项目设计意义
1.2 开发环境工具介绍
1.2.1 IDEA开发环境介绍
1.2.2 flume介绍
1.2.3 Sqoop介绍
1.2.4 Spark介绍
1.2.5 VS Code开发工具简介
1.2.6 Hive介绍
1.2.7 HDHS模块介绍
1.2.8 Vue介绍
1.2.9 ECharts介绍
1.2.10 Mysql介绍
1.3开发环境准备
1.3.1 数据采集环境准备
1.3.2 数据清洗环境准备
1.3.3数据可视化环境准备
2 项目需求分析
2.1 可行性分析
2.1.1 端口日志数据采集可行性分析
2.1.2 技术可行性分析
2.2 代码实现功能分析
2.2.1 数据采集功能
2.2.2 数据清洗功能
2.2.3 数据可视化功能
3 数据采集实现
3.1 工业数据监听与采集
3.2 HDFS数据转存到MYSQL
4 数据处理实现
4.1 数据清洗
4.1.1源数据层(ODS)
4.1.2 数据仓库层(DW)
4.2 数据挖掘
4.2.1 特征工程
4.3机器学习
4.3.1 随机森林报警预测
5 数据可视化实现与分析
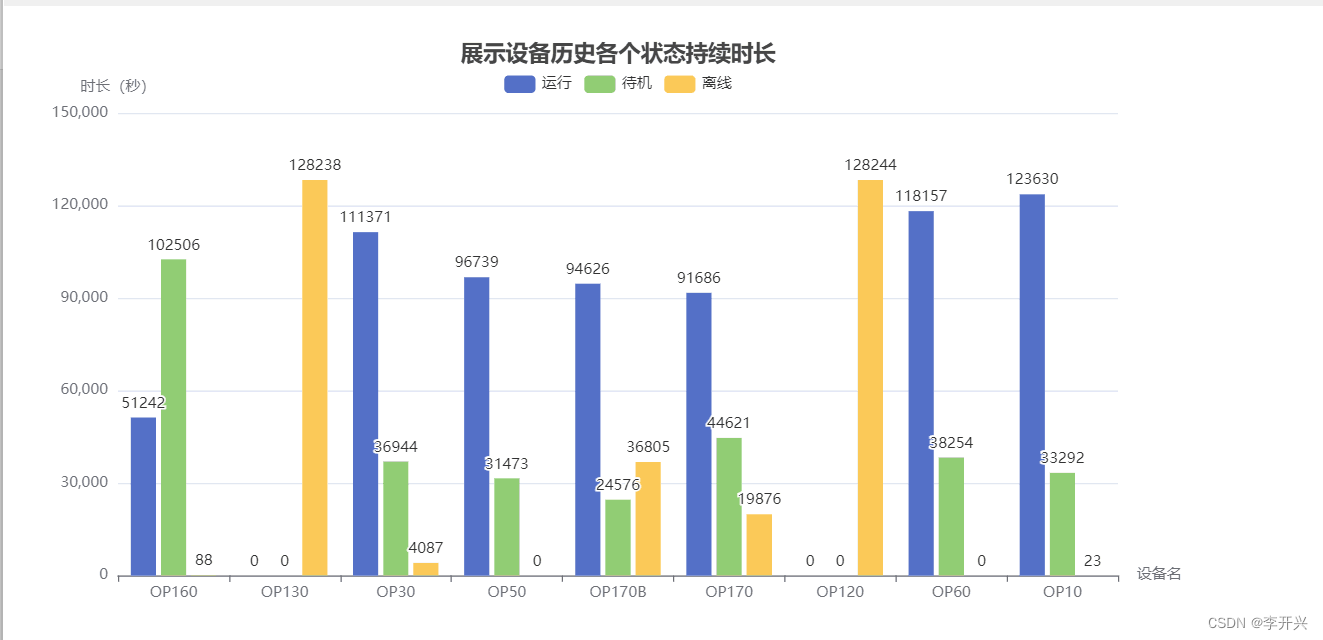
5.1 设备历史各个状态持续时长柱状图
5.2各设备PM2.5浓度变化折线图
5.3 设备日均产量和所在车间日均产量折线柱状图
5.4 OP170B设备每天各状态时长饼图
5.5 环境湿度变化散点图
5.6 每日各设备产量条形图
6 总结与展望
6.1作品特点
6.2收获与体会
6.3问题与展望
1 设计任务
1.1项目开发背景与意义
1.1.1 项目开发背景
工业互联网是工业全要素、全产业链、全价值链的全面连接,是人、机、物、工厂互联互通的新型工业生产制造服务体系,是互联网从消费领域向生产领域、从虚拟经济向实体经济拓展的核心载体,是建设现代化经济体系、实现高质量发展和塑造全球产业竞争力的关键支撑。加快发展工业互联网产业,不仅是各国顺应产业发展大势,抢占产业未来制高点的战略选择,也是我国推动制造业质量变革、效率变革和动力变革,实现高质量发展的客观要求。
1.1.2 项目设计意义
本项目是利用Flume收集工业日志数据,通过spark对获取的数据进行处理清洗,数据采集的目的在于获取可靠信息,然后在可靠信息的基础上做出恰当的决策。没有所谓“正确的决策”,只有基于当时当地所获取信息的恰当决策。这就需要认真地收集真实有效的数据,并且运用恰当的分析方法从中提炼出可信的信息。在所收集到的工业数据中有空值、重复值、不规范字符等“脏”数据,对其要进行清洗转换处理,才能对这些数据进行使用。在进行机器学习之前我们要对数据进行预处理,留下有效的特征列,若特征列较多且较冗余我们可以对其进行降维,归一化等操作。通过spark内置的机器学习库对其进行操作。最后通过可视化的手段将数字以可视化的形式展示出来。
1.2 开发环境工具介绍
本项目主要是基于IDEA的开发,使用flume实时监听数据,并把监听到的数据存储到hdfs上,通过sqoop将hdfs中的数据转存到mysql中并使用spark整合hive对获取到的数据进行清洗,挖掘以及机器学习,最后将清洗完的数据通过VSCode工具使用vue和echarts进行可视化展示
1.2.1 IDEA开发环境介绍
IDEA是一个专门针对ava的集成开发工具(IDE), 由Java语言编写。所以,需要有JRE运行环境并配置好环境变量。它可以极大地提升我们的开发效率。可以自动编译,检查错误。在公司中,使用的就是IDEA进行开发。 集成开发环境(IDE,Integrated Development Environment )是用于提供程序开发环境的应用程序,一般包括代码编辑器、编译器、调试器和图形用户界面等工具。
1.2.2 flume介绍
Flume 是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来存储的工具/服务,或者数集中机制。flume具有高可用,分布式,配置工具,其设计的原理也是基于将数据流,如日志数据从各种网站服务器上汇集起来存储到HDFS,HBase等集中存储器中
1.2.3 Sqoop介绍
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。对于某些NoSQL数据库它也提供了连接器。Sqoop,类似于其他ETL工具,使用元数据模型来判断数据类型并在数据从数据源转移到Hadoop时确保类型安全的数据处理。Sqoop专为大数据批量传输设计,能够分割数据集并创建maptask任务来处理每个区块。
1.2.4 Spark介绍
Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。
1.2.5 VS Code开发工具简介
VS Code 的全称是 Visual Studio Code,是一款开源的、免费的、跨平台的、高性能的、轻量级的代码编辑器。它在性能、语言支持、开源社区方面,都做得很不错。 微软有两种软件:一种是 VS Code,一种是其他软件。IDE 与 编辑器的对比 IDE 和编辑器是有区别的:IDE(Integrated Development Environment,集成开发环境):对代码有较好的智能提示和相互跳转,同时侧重于工程项目,对项目的开发、调试工作有较好的图像化界面的支持。
1.2.6 Hive介绍
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析
1.2.7 HDHS模块介绍
Hadoop Distributed File System,简称 HDFS,是一个分布式文件系统。HDFS 有着高容错性(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS 放宽了(relax)POSIX 的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。HDFS 开始是为开源的 apache 项目 nutch 的基础结构而创建,HDFS 是 hadoop 项目的一部分,而 hadoop 又是 lucene 的一部分
1.2.8 Vue介绍
Vue是一套用于构建用户界面的渐进式的js框架,发布于2014年2月。与其它大型框架不同的是,Vue被设计为可以自底向上逐层应用。Vue的核心库只关注视图层,不仅易于上手,还便于与第三方库( 如: vue-router,vue-resource,vuex)或既有项目整合
1.2.9 ECharts介绍
ECharts是一个使用JavaScript实现的开源可视化库,ECharts具有丰富的可视化类型,提供直观,交互丰富,结合HTML网页设计,可高度个性化定制的数据可视化图表。不仅提供了常规的图型的绘制还支持图与图之间的混搭;多种数据格式无需转换直接使用,使用方法便捷,通过简单的设置encode属性就可以完成从数据到图形的映射,这种方式更符合可视化的直觉,而且多个组件能够共享一份数据;多维数据的支持及丰富的视觉编码手段;针对不同数据提供不同吸引眼球的特效。
1.2.10 Mysql介绍
MySQL 是最流行的数据库之一,是一个免费开源的关系型数据库管理系统,但也不意味着该数据库是完全免费的。MySQL 由瑞典 MySQL AB 公司开发,之后又卖给了Sun公司(一家伟大的,不可复制的,又感到无限惋惜的公司),目前属于 Oracle 公司。MySQL 适合中小型软件,被个人用户以及中小企业青睐。在web应用方面MySQL是最好的RDBMS关系数据管理系统软件之一。