一种用于处理不同类型概念漂移的混合算法
算法简介
随着在传感器网络,银行和通信等领域广泛应用数据流挖掘技术,越来越多在线处理数据流的算法也应运而生。本文我要介绍的这个算法名为The Accuracy Updated Ensemble Algorithm。关于这个算法的论文:Reacting to Different Types of Concept Drift: The Accuracy Updated Ensemble Algorithm 是由Pznan University of Technology 的一位博士生和他的导师一起提出来发表在IEEE Trans的。而这篇论文的主要贡献就是提出了一种新的数据流分类器,旨在处理不同类型的概念漂移。
数据流与概念漂移
在这之前我们提到了数据流与概念漂移。那么究竟它们究竟是什么呢?研究它们又有什么意义呢?
接下来我就用我粗浅的见识来简单介绍一下这两个概念吧。
1.数据流
百度上对数据流的介绍是这样的:数据流(data stream)是一组有序,有起点和终点的字节的数据序列。包括输入流和输出流。数据流最初是通信领域使用的概念,代表传输中所使用的信息的数字编码信号序列。这个概念最初在1998年由Henzinge提出,他将数据流定义为“只能以事先规定好的顺序被读取一次的数据的一个序列”。
举个简单的例子,大家都知道这段时间网络上仍然发生着大量的电信诈骗事件,如果我们能够用一种方法可以实时准确在互联网上分辨出诈骗信息,将它屏蔽并交给警察叔叔,那么是不是很有意义呢?正如刚才所说,那些此时此刻正在发送的一封一封的短信就是我们的数据流,一个短信就是一个数据(简称样本)。这样可以理解了吧?
2.概念漂移
概念漂移是由英文concept drift直译过来的。它是机器学习领域重要的问题之一,也是数据挖掘工作中的一个巨大的阻碍。网上的翻译都直接用这个作为例句(哈哈):
Concept drift is a big obstacle in the field of mining stream data.
简单地说就是我们在用数据训练我们的分类器时,随着时间的推移,数据的分布发生了改变,这种改变就叫做概念漂移,随之而来的严重后果就是之前训练的模型就不再适用于处理当前数据了。
再用刚刚电信诈骗来举例:本来今天一上午到晚上,骗子们偷懒都没有发一封诈骗短信,而到了晚上他们突然想到再不“工作”,第二天就没饭吃了,于是开始陆陆续续向外发短信,而我们的算法在经过了一个白天的大量正常短信的训练,这突然遇到了一封诈骗短信,就突然没有反应过来,直到诈骗短信越来越多,它才慢慢反应过来,这是不是已经为时已晚了呢?这就是机器学习呀…而我们的工作就是尽可能让这种算法在实时处理大量正常短信中夹杂着生活极度不规律的“骗子”发的诈骗短信反应再快一点,准确度(简称精度)更高一点。
关于概念漂移,我想不久我会专门写一篇关于概念漂移的全面总结性文章,这么简单的介绍一个如此复杂的东西,心里总有点过意不去~
概念漂移的几种不同类型
概念漂移可以从很多角度进行细分,如果按变化速度来的话,可以分为四类:
- 突变型(sudden)概念漂移 ,发生迅速且不可逆;
- 渐变型(incremental gradual)概念漂移,incremental和gradual都是强调改变发生的缓慢,incremental强调值的随时间改变,gradual则是数据分布的改变;
- 临时型(recurring)概念漂移,recurring则是一种temporary(临时性)的改变,在短时间内会恢复成之前的状态。这是一种不规则的反复变化;
- 稀罕型(blip)概念漂移,通常又将这种情况被视为anomaly或者outlier(异常);
- 噪音型(noise)概念漂移 这一种随机的改变也被视为噪音的一种,往往需要剔除;
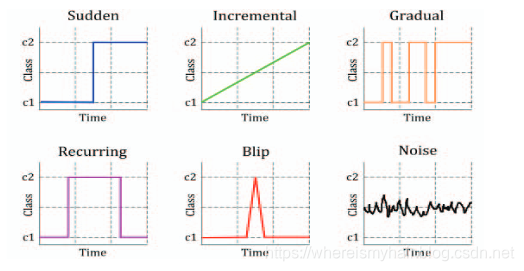
来源:A Review on Real Time Data Stream Classification and Adapting To Various Concept Drift Scenarios
如果按照数据的概率分布的角度来分析,又可分为:
- 真实漂移(real drift):先验概率
 发生了变化,且是独立于
发生了变化,且是独立于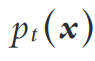 表面的变化。由于条件概率发生改变,决策超平面发生位移。
表面的变化。由于条件概率发生改变,决策超平面发生位移。 - 虚拟漂移(virtual drift):数据x的分布不会影响决策超平面的变化。
- 类先验(class prior): 它会影响类间的不平衡比率,即可以交换少数类和多数类的概率。
详情请见Learning in Nonstationary Environments: A Survey
当前主流的几种处理概念漂移的方法与不足
- 滑动窗口法( sliding window approaches)
- 新的在线算法(new online algorithms)
- 特殊检测技术(special detection tech-niques)
- 自适应集合( adaptive ensembles)
以上几种方法的系统性评述同样的我将放在另一篇文章里单独介绍,要知道的是它们都需要做一下改进才能适应不断变化的环境。
在本文中,作者主要关注自适应集合这一主题,它从基于有固定大小块的数据流中顺序生成组件分类器。在这样的集合中,当新块到达时,评估现有的组件分类器并更新它们的组合权重。从最近的块中学习的新分类器将添加到集合中,并且根据评估的结果去除最弱的分类器。此外,应用标准的静态学习算法(例如C4.5)来从给定块中生成分类器。SEA算法是第一个这样的自适应集合,紧接着是精确加权集合算法AWE,它也是目前这种类型中最具代表性的方法。
固定大小的数据块内发生概念漂移时,基于块的集成可能不会对变化作出充分反应。特别是,对于突然漂移,它们可能反应太慢,因为过时的块产生的分类器仍然是有效的组件,即使它们具有不准确的权重。这种情况与怎么样适当调整数据块大小有关。使用小尺寸块可以部分地帮助对突然变化做出反应,但这样做会在稳定期间损害集合的性能并增加计算成本。令有研究表明基于块的集合对其他类型漂移也会发生不好反应。另一方面,在线增量集合,例如在线或利用套袋,对突然漂移的反应更快,但没有利用周期性加权机制,不足以为逐渐变化提供足够的反应。此外,增量集合的通常比基于块的方法有更高的计算成本。所以,如果将这两种方法结合在一起,那么可能对问题的解决有很好的帮助哦~于是就有了这个 AUE2 算法
Algorithm AUE2

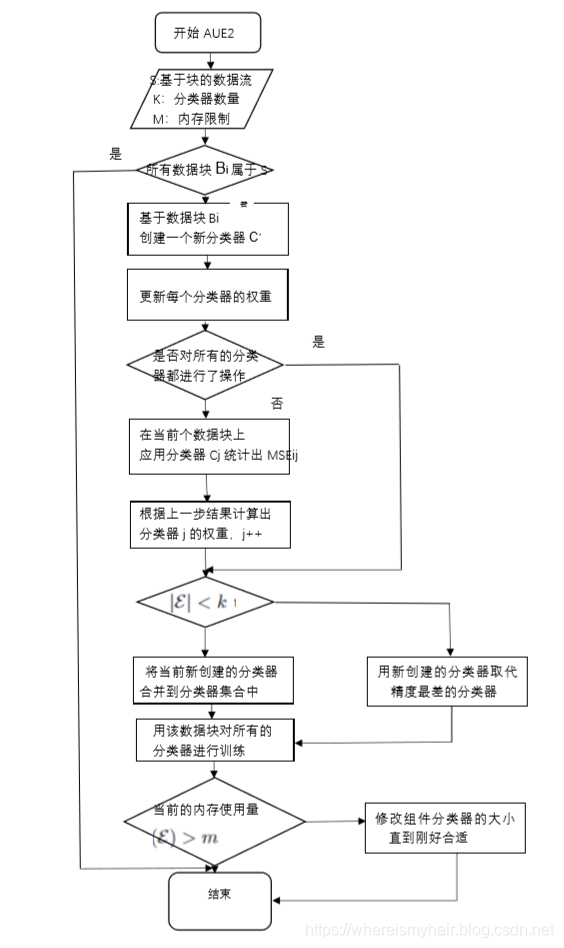
小结
实验研究表明,AUE2可以在具有不同漂移类型的环境中以及在静态环境中提供高分类精度。AUE2在所有测试算法中提供了最佳的平均分类准确度,同时证明比其他集合方法(例如利用套袋或Hoeffding选项树)更少的内存消耗。具体的实验分析,感兴趣者详情请见作者的论文~