常见Base64问题及Base64转换工具类
1 Base64常见问题
1.1 base64字符串过长
Idea报:字符串过长
将编译器改为eclipse即可
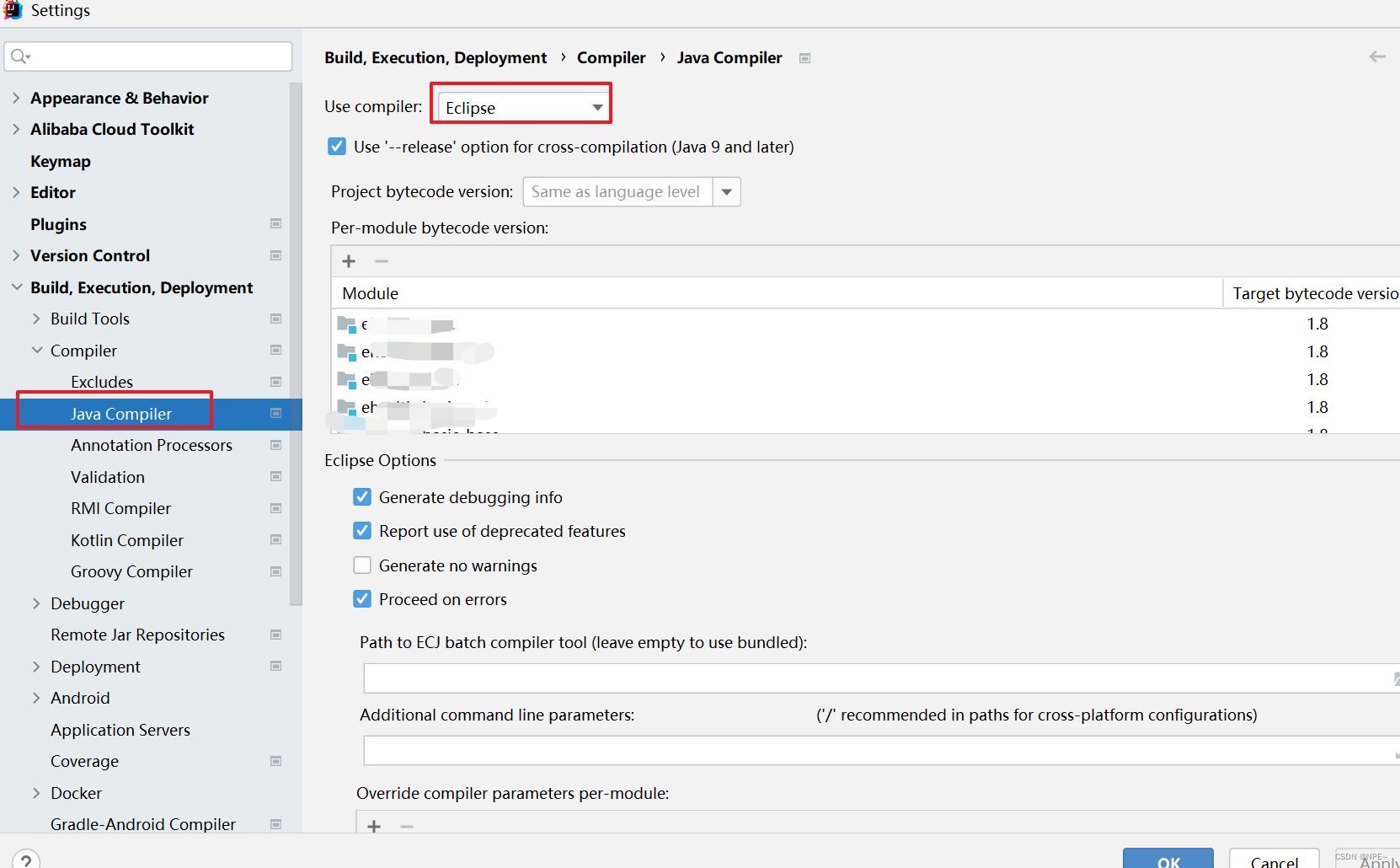
注意:使用Eclipse的compiler无法再使用lombok插件,会报错
2 Base64转换工具类
2.1 Base64pdf转为Base64png【转换问题】
将base64编码后的pdf转为base64编码后的png
/**
* base64 pdf转换为 base64的png格式
* @param base64Pdf
* @param format [png]
* @return
* @throws IOException
*/
public static String base64PDF2PNG(String base64Pdf, String format) throws IOException {
String resultBase64 = "";
//这个base64是pdf的base64
if (StringUtils.isEmpty(base64Pdf)) {
return resultBase64;
}
PDDocument pdDocument = null;
Base64Decoder decoder = new Base64Decoder();
try {
// Base64解码
byte[] pdf_bytes = decoder.decode(base64Pdf);
PDDocument doc = Loader.loadPDF(pdf_bytes);
int size = doc.getNumberOfPages();
/*图像合并使用的参数*/
//定义宽度
int width = 0;
// 保存一张图片中的RGB数据
int[] singleImgRGB;
// 定义高度,后面用于叠加
int shiftHeight = 0;
//保存每张图片的像素值
BufferedImage imageResult = null;
// 利用PdfBox生成图像
pdDocument = doc;
PDFRenderer renderer = new PDFRenderer(pdDocument);
/*根据总页数, 按照50页生成一张长图片的逻辑, 进行拆分*/
// 每50页转成1张图片
int pageLength = size; //有多少转多少
// 总计循环的次数
int totalCount = pdDocument.getNumberOfPages() / pageLength + 1;
for (int m = 0; m < totalCount; m++) {
for (int i = 0; i < pageLength; i++) {
int pageIndex = i + (m * pageLength);
if (pageIndex == pdDocument.getNumberOfPages()) {
break;
}
// 96为图片的dpi,dpi越大,则图片越清晰,图片越大,转换耗费的时间也越多
BufferedImage image = renderer.renderImageWithDPI(pageIndex, 150, ImageType.RGB);
int imageHeight = image.getHeight();
int imageWidth = image.getWidth();
if (i == 0) {
//计算高度和偏移量
//使用第一张图片宽度;
width = imageWidth;
// 保存每页图片的像素值
// 加个判断:如果m次循环后所剩的图片总数小于pageLength,则图片高度按剩余的张数绘制,否则会出现长图片下面全是黑色的情况
if ((pdDocument.getNumberOfPages() - m * pageLength) < pageLength) {
imageResult = new BufferedImage(width, imageHeight * (pdDocument.getNumberOfPages() - m * pageLength), BufferedImage.TYPE_INT_RGB);
} else {
imageResult = new BufferedImage(width, imageHeight * pageLength, BufferedImage.TYPE_INT_RGB);
}
} else {
// 将高度不断累加
shiftHeight += imageHeight;
}
singleImgRGB = image.getRGB(0, 0, width, imageHeight, null, 0, width);
imageResult.setRGB(0, shiftHeight, width, imageHeight, singleImgRGB, 0, width);
}
// 这个很重要,下面会有说明
shiftHeight = 0;
}
pdDocument.close();
ByteArrayOutputStream baos = new ByteArrayOutputStream();//io流
ImageIO.write(imageResult, format, baos);//写入流中
byte[] jpg_Bytes = baos.toByteArray();//转换成字节
BASE64Encoder encoder = new BASE64Encoder();
resultBase64 = encoder.encodeBuffer(jpg_Bytes).trim();//转换成base64串
resultBase64 = resultBase64.replaceAll("\n", "").replaceAll("\r", "");//删除 \r\n
baos.close();
doc.close();
return resultBase64;
} catch (IOException e) {
e.printStackTrace();
} finally {
if (pdDocument != null) {
pdDocument.close();
}
}
return resultBase64;
}
对应pom依赖:
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-tools</artifactId>
<version>3.0.0-RC1</version>
</dependency>
Bug:如果遇到base64编码之后发现生成的png图片中缺少对应的中文字体,则可能是因为对应服务器上没有相应的字体导致。
① 可以下载pdbox的源码,然后修改里面的FontMapperImpl,编译打包之后重新替换为新的类。
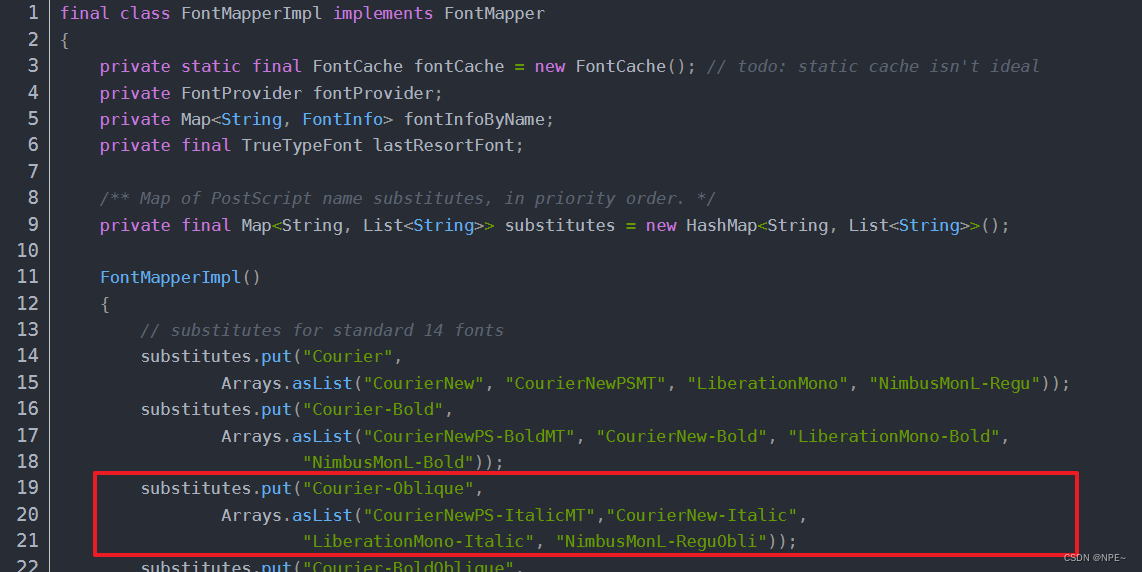
直接在substitutes中增加映射字体对应的映射字体即可,如:STSong-Light->STFangsong。
然后使用maven编译打包,并且使用编译后的jar包
按照说明 在.\pdfbox 文件夹下 运行 mvn clean install
- 但是会运行 test,我这里会报错 所以我关闭了测试 mvn clean install -DskipTests
②或者可以直接在对应的服务器上下载对应的字体。
# linux上下载对应字体【如:宋体】
#新建目录newFont以存放新字体
mkdir /usr/share/fonts/chinese/
#上传或者拷贝当前目录下的字体到/usr/share/fonts/chinese中
# 建立字体缓存
cd /usr/share/fonts/chinese/
mkfontscale; mkfontdir; fc-cache -fv
注意事项:更新字体缓存重启java应用依旧失败报错,删除/root目录下的.pdfbox.cache文件,重启应用后OK(此问题PDFBOX2.0.4版本会出现)