这些概念根据之前博客给出的笔记进一步整理归纳
图像分类篇
最邻近分类器
最邻近分类器,即 Nearest Neighbor 分类器,其实这个分类器跟卷积神经网络没有任何关系,实际中也极少使用。
原理:Nearnest Neighbor 算法将会拿着测试图片和训练集中每一张图片去比较,然后将它认为最相似的那个训练集图片的标签赋给这张测试图片。
比较两张图片的时候,会用到两种距离的计算:
- L1距离:
- L2距离:
KNN 分类器
原理:找最相近的k个图片的标签,然后让他们针对测试图片进行投票,最后把票数最高的标签作为测试图片的预测
效果:从直观感受上可以看到,更高的k值可以让分类的效果更平滑,使得分类器对于异常值更有抵抗力。
当k = 1时,KNN分类器就是最邻近分类器
训练集:用来训练分类器的数据集合
验证集:从训练集中取出一部分数据用来调优,将其称之为验证集(validation set)
交叉验证:有时候训练集数量较小时,人们会使用交叉验证。举个例子,将训练集平均分成5份,其中4份用来训练,1份用来验证。然后我们循环取其中4份来训练,其中一份来验证,最后去所有5次验证结果的平均值作为算法验证结果。
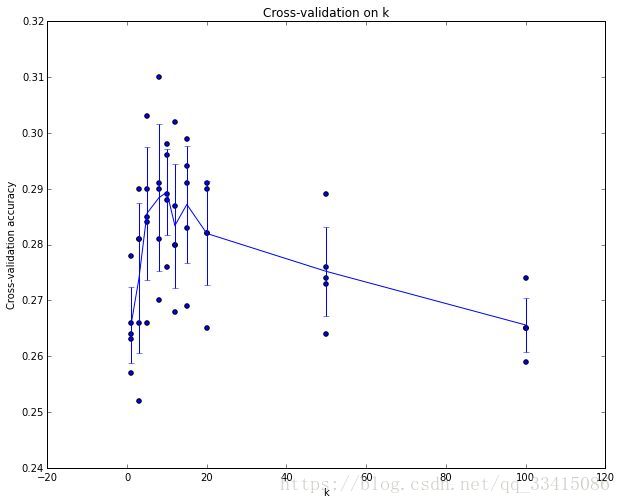
这里是5份交叉验证对k值调优。(横轴表示k值,纵轴表示准确率)针对每个k值,得到5个准确率结果,然后取其平均值,然后对不同k值的平均表现进行画线连接。然后取准确率最高的k值,即k = 7。
分类器的缺点:
- 分类器必须记住所有训练数据并将其存储起来,以便于未来测试数据用于比较。这在存储空间上是低效的,数据集的大小很容易就以GB计。
- 对一个测试图像进行分类,需要和所有训练图像做比较,算法计算资源耗费高。
线性分类篇
我们经常说图像是X维的,那这个维是怎么算的?用一个具体的例子来讲,假设有一个图像训练集 ,每个图像都有一个对应的分类标签 。我们有N个图像样例,每个图像的维度是D,共有K种不同的分类。
对于 CIFAR-10:
训练集有N = 50000个图像样例,每个图像有D = 32 * 32 * 3 = 3072个像素,而K = 10。原始图像像素到分类分值的映射为函数
最简单的线性映射为:
- 权重W:矩阵W的大小为[k * D],由数据训练得到
- 偏差b:b为大小为[k * 1]大小的列向量,由数据训练得到
- 输入 :每个图像的像素从原先的[32 * 32 * 3]拉伸为[3071 * 1]大小的向量,即拉伸为长度为D的列向量
- 输出:大小为[k * 1]的列向量,对应k个分类的得分
权重W的另一个解释:权重W的每一行对应着一个分类的模板(有时也看作原型)。一张图像对应不同分类的得分,是通过使用内积(也叫点积)来比较图像和模板,然后找到和哪个模板最相似。从这个角度来看,线性分类器就是在利用学习到的模板,针对图像做模板匹配。因此,对比KNN,我们没有使用所有的训练集的图像来比较,而是每个类别只用了一张图片(这张图片是我们学习到的,即大小为[D * 1]的模板,而不是训练集中的某一张),而且我们会使用(负)内积来计算向量间的距离,而不是使用L1或者L2距离。
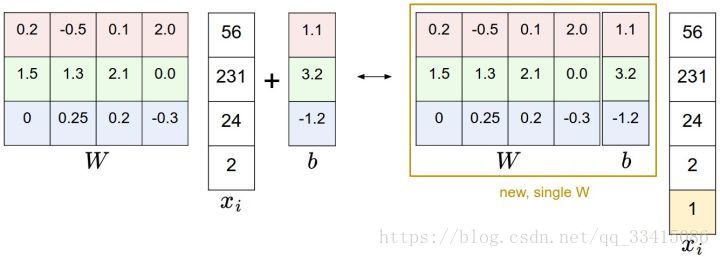
偏差和权重的合并技巧:
可以把权重W和偏差b放到同一个矩阵中,只需要
向量增加一个唯独,这个维度的数值是常量1,那么新的线性映射的公式变为:
还是以CIFAR-10为例,合并权重和偏差之后,
的大小变为[3073 * 1],W大小就是[10x3073]了,如下图所示:
图像数据预处理:
在上面的例子中,所有图像都是使用的原始像素值(从0到255)。在机器学习中,对于输入的特征做归一化(normalization)处理是常见的套路。而在图像分类的例子中,图像上的每个像素可以看做一个特征。在实践中,对每个特征减去平均值来中心化数据是非常重要的。在这些图片的例子中,该步骤意味着根据训练集中所有的图像计算出一个平均图像值,然后每个图像都减去这个平均值,这样图像的像素值就大约分布在[-127, 127]之间了。下一个常见步骤是,让所有数值分布的区间变为[-1, 1]。零均值的中心化是很重要的,等我们理解了梯度下降后再来详细解释。
损失函数:
我们使用损失函数(Loss Function)(也叫代价函数 Cost Function)来衡量我们对结果的不满意程度。直观地讲,当评分函数输出结果与真实结果之间差异越大,损失函数输出越大,反之越小。
多类支持向量机损失 Multiclass Support Vector Machine Loss:
SVM损失函数的目标:SVM在正确分类上的得分始终比不正确分类上的得分高出一个边界值
。
对于第i个数据中包含图像
的像素和代表正确类别的标签
,多类SVM的损失函数定义如下:
- 为第j个类别的得分
即对于每一个不正确分类,计算
并与0进行比较。也就是比较
。如果不满足正确分类类别
的分数比不正确类别分数至少高
,就开始计算损失值。
面对线性评分函数
,我们又可以把损失函数的公式稍微改写一下:
-
为权重的第j行
折叶损失(hinge loss):
关于0的阈值:max(0, -)函数常被称为折叶损失(hinge loss)。此外还有平方折叶损失SWM,它使用的是
正则化(Regularization):
最常用的正则化惩罚是L2范式,L2范式通过对所有参数进行逐元素的平方惩罚来抑制大数值的权重:
这样子,完整的多类SVM损失函数由两个部分组成:数据损失(data loss)和正则化损失(regularization loss),完整的公式如下所示:
- N为训练集的数量, 为正则化程度。正则化参数 越大,权重W就会被惩罚的更多,那么他的权重数值就会更小。
Softmax分类器:
SVM最常用的两个分类器之一,另一个就是Softmax分类器。对于学习过二元逻辑回归分类器的读者来说,Softmax分类器就可以理解为逻辑回归分类器面对多个分类的一般化归纳。
折叶损失(hinge loss)替换为交叉熵损失(cross-entropy loss),公式如下:
或等价的
- 表示分类评分向量f中的第j个元素。
- 被称为softmax函数:输入值是一个向量,函数对其进行压缩,输出一个向量,其中每个元素值在0到1之间,且所有元素之和为1。
处理技巧:由于中间项存在指数函数,所以数值可能会非常大。除以大数值可能导致数值计算的不稳定,所以学会使用归一化技巧。
通常将logC设为向量f中的最大值。这里的操作可以理解为,对向量f中的数值进行平移,使得最大值为0,其他值均小于0,那么每个指数项便都小于等于1.
折叶损失和交叉熵损失的比较:
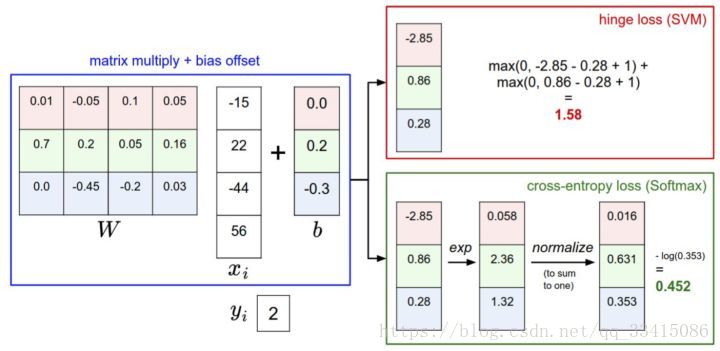
针对一个数据点,SVM和Softmax分类器的不同处理方式的例子。两个分类器都计算了同样的分值向量f(本节中是通过矩阵乘来实现)。不同之处在于对f中分值的解释:SVM分类器将它们看做是分类评分,它的损失函数鼓励正确的分类(本例中是蓝色的类别2)的分值比其他分类的分值高出至少一个边界值。Softmax分类器将这些数值看做是每个分类没有归一化的对数概率,鼓励正确分类的归一化的对数概率变高,其余的变低。SVM的最终的损失值是1.58,Softmax的最终的损失值是0.452,但要注意这两个数值没有可比性。只在给定同样数据,在同样的分类器的损失值计算中,它们才有意义。
总结:
- 评分函数: 该函数将原始图像像素映射为分类评分值
- 损失函数: 该函数能够根据分类评分和训练集图像数据实际分类的一致性,衡量某个具体参数集的质量好坏。损失函数有多种版本和不同的实现方式。
最优化篇
最优化是寻找能使得损失函数值最小化的参数的过程。
梯度(gradient):
在一维函数中,斜率是函数在某一点的瞬时变化率,梯度是函数斜率的一般化表达,它不是一个值,而是一个向量。在输入空间中,梯度是各个维度的斜率组成的向量(或者称为导数derivatives)。对一维函数的求导公式如下:
当函数有多个参数的时候,我们称导数为偏导数。而梯度就是在每个唯独上偏导数所形成的向量。
在梯度负方向上更新:沿着梯度的负方向更新,因为我们希望损失函数值是降低而不是升高。即, (df为梯度)。这里的步长也就是我们说的学习率。学习率过小时,收敛速度比较缓慢;学习率过大时,收敛速度较快,但是可能错过最低点导致更高的损失值。
梯度的计算:使用有限差值近似计算梯度比较简单,但缺点在于终究只是近似,且耗费计算资源太多。我们可以使用微分分析计算梯度。这种方法唯一不好的就是实现的时候容易出错。为了解决这个问题,在实际操作时常常将分析梯度法的结果和数值梯度法的结果作比较,以此来检查其实现的正确性,这个步骤叫做梯度检查。
梯度下降:
就是沿着梯度的负方向,重复地计算梯度并对参数进行更新。
# 普通的梯度下降
while True:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += - step_size * weights_grad # 进行梯度更新到目前为止,梯度下降是对神经网络的损失函数最优化中最常用的方法。
小批量数据梯度下降(Mini-batch gradient descent):
在大规模应用中, 如果通过计算整个训练集来获得一个参数的更新就太浪费了。一个常用的方法是计算训练集中的小批量(batches)数据。
# 普通的小批量数据梯度下降
while True:
data_batch = sample_training_data(data, 256) # 256个数据
weights_grad = evaluate_gradient(loss_fun, data_batch, weights)
weights += - step_size * weights_grad # 参数更新随机梯度下降:
小批量数据策略有个极端情况,那就是每个批量中只有1个数据样本,这种策略被称为随机梯度下降(Stochastic Gradient Descent 简称SGD),有时候也被称为在线梯度下降。这种策略在实际情况中相对少见,因为向量化操作的代码一次计算100个数据 比100次计算1个数据要高效很多。