1. grep
grep 是全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
用法:
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]- 1
- 2
首先使用ls命令和输出重定向生成两个用来测试grep命令的文本
root@CGS-21-14:/home/lhp# ls /usr/ > ls_usr.txt
root@CGS-21-14:/home/lhp# ls /etc/ > ls_etc.txt- 1
- 2
1). 在ls_usr.txt中搜索含有“bin”的字符串
root@CGS-21-14:/home/lhp# grep bin ls_usr.txt
bin
sbin- 1
- 2
- 3
2). 从多文件中搜索含有”bin”的字符串
root@CGS-21-14:/home/lhp# grep bin *
ls_etc.txt:bindresvport.blacklist
ls_usr.txt:bin
ls_usr.txt:sbin- 1
- 2
- 3
- 4
root@CGS-21-14:/home/lhp# grep bin ls*
ls_etc.txt:bindresvport.blacklist
ls_usr.txt:bin
ls_usr.txt:sbin- 1
- 2
- 3
- 4
3). 从ls_usr.txt中搜索含“bin”和”BIN”的字符串。
root@CGS-21-14:/home/lhp# echo /BINs >> ls_usr.txt
root@CGS-21-14:/home/lhp# echo /BINABLE >> ls_usr.txt
root@CGS-21-14:/home/lhp# echo /Bining >> ls_usr.txt
root@CGS-21-14:/home/lhp# grep -i bin ls_usr.txt
bin
sbin
/BINs
/BINABLE
/Bining- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4). 在ls_usr.txt中搜索以this开头case结尾的字符串
root@CGS-21-14:/home/lhp# echo "this is test case" >> ls_usr.txt
root@CGS-21-14:/home/lhp# grep -i "this.*case" ls_usr.txt
this is test case- 1
- 2
- 3
5). 在ls_usr.txt中搜索整词is,不像1)中那种含部分,并加上不区分大小写
root@CGS-21-14:/home/lhp# grep -iw "is" ls_usr.txt
this is test case- 1
- 2
6). 显示ls_etc.txt中含emacs匹配行前、后、前后 4行
root@CGS-21-14:/home/lhp# grep -A 4 -w emacs ls_etc.txt
emacs
environment
firefox
fonts
foomatic
root@CGS-21-14:/home/lhp# grep -B 4 -w emacs ls_etc.txt
dictionaries-common
doc-base
dpkg
drirc
emacs
root@CGS-21-14:/home/lhp# grep -C 4 -w emacs ls_etc.txt
dictionaries-common
doc-base
dpkg
drirc
emacs
environment
firefox
fonts
foomatic- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
7). 递归搜索/home/lhp文件目录下文件中含有bin的字符串
root@CGS-21-14:/home# grep -r bin /home/lhp/*
/home/lhp/ls_etc.txt:bindresvport.blacklist
/home/lhp/ls_usr.txt:bin
/home/lhp/ls_usr.txt:sbin- 1
- 2
- 3
- 4
8). 递归搜索/home/lhp文件目录下文件中含有bin的字符串,统计个数
root@CGS-21-14:/home# grep -rc bin /home/lhp/*
/home/lhp/ls_etc.txt:1
/home/lhp/ls_usr.txt:2- 1
- 2
- 3
9). 显示ls_usr.txt中不含bin、local的行
root@CGS-21-14:/home/lhp# grep -v -e bin -e local ls_usr.txt
games
include
lib
share
src
/BINs
/BINABLE
/Bining
this is test case- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
10). 递归搜索/home/lhp文件目录下文件中含有emacs的字符串,并显示文件名
root@CGS-21-14:/home/lhp# grep -rl emacs /home/lhp/*
/home/lhp/ls_etc.txt- 1
- 2
11). 递归搜索/home/lhp文件目录下与bin匹配字符串,并显示行号
root@CGS-21-14:/home/lhp# grep -rn emacs /home/lhp/*
/home/lhp/ls_etc.txt:54:emacs- 1
- 2
2. sed
sed是一个很好的文件处理工具,本身是一个管道命令,主要是以行为单位进行处理,可以将数据行进行替换、删除、新增、选取等特定工作。
sed [OPTION]... {script-only-if-no-other-script} [input-file]...
如:sed [-nefri] ‘command’ 输入文本- 1
- 2
常用选项:
-n∶使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN的资料一般都会被列出到屏幕上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。
-e∶直接在指令列模式上进行 sed 的动作编辑;
-f∶直接将 sed 的动作写在一个档案内, -f filename 则可以执行 filename 内的sed 动作;
-r∶sed 的动作支援的是延伸型正规表示法的语法。(预设是基础正规表示法语法)
-i∶直接修改读取的档案内容,而不是由屏幕输出。- 1
- 2
- 3
- 4
- 5
常用命令:
a∶新增,a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)
c∶取代,c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d ∶删除
i∶插入,i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p∶打印,亦即将某个选择的内容输出。通常 p 会与参数 sed -n 一起运作~
s∶取代,通常这个 s 的动作可以搭配正规表示法!例1,20s/old/new/g- 1
- 2
- 3
- 4
- 5
- 6
1). 删除ls_usr.txt的第一行 root@CGS-21-14:/home/lhp# sed '1d' ls_usr.txt
2). 删除ls_usr.txt的最后一行 root@CGS-21-14:/home/lhp# sed '$d' ls_usr.txt
3). 删除ls_usr.txt的第3到第4行 root@CGS-21-14:/home/lhp# sed '3,4d' ls_usr.txt
4). 显示ls_usr.txt的第一行 root@CGS-21-14:/home/lhp# sed -n '1p' ls_usr.txt
5). 显示ls_usr.txt的最后一行 root@CGS-21-14:/home/lhp# sed -n '$p' ls_usr.txt
6). 显示ls_usr.txt从开头到结尾 root@CGS-21-14:/home/lhp# sed -n '1,$p' ls_usr.txt
7). 在ls_usr.txt中查找含bin的行,并输出到屏幕上 root@CGS-21-14:/home/lhp# sed -n '/bin/p' ls_usr.txt
8). 在ls_usr.txt第一行后添加字符串 root@CGS-21-14:/home/lhp# sed '1a append after line 1' ls_usr.txt
9). 将ls_usr.txt中的最后一行替换 root@CGS-21-14:/home/lhp# sed '$c replace last line' ls_usr.txt
10). 先查找last,并将其替换为空 root@CGS-21-14:/home/lhp# sed -n '/last/p' ls_usr.txt | sed 's/last//g'
11). 在最后一行插入 root@CGS-21-14:/home/lhp# sed -i '$a over' ls_usr.txt
3. awk
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
使用方法: awk '{pattern + action}' {filenames}
其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令。花括号({})不需要在程序中始终出现,但它们用于根据特定的模式对一系列指令进行分组。 pattern就是要表示的正则表达式,用斜杠括起来。
awk语言的最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息,awk抽取信息后,才能进行其他文本操作。完整的awk脚本通常用来格式化文本文件中的信息。
通常,awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。
使用方式:
1.命令行方式
awk [-F field-separator] 'commands' input-file(s)
其中,commands 是真正awk命令,[-F域分隔符]是可选的。 input-file(s) 是待处理的文件。
在awk中,文件的每一行中,由域分隔符分开的每一项称为一个域。通常,在不指名-F域分隔符的情况下,默认的域分隔符是空格。
2.shell脚本方式
将所有的awk命令插入一个文件,并使awk程序可执行,然后awk命令解释器作为脚本的首行,一遍通过键入脚本名称来调用。
相当于shell脚本首行的:#!/bin/sh
可以换成:#!/bin/awk
3.将所有的awk命令插入一个单独文件,然后调用:
awk -f awk-script-file input-file(s)
其中,-f选项加载awk-script-file中的awk脚本,input-file(s)是待处理的文件。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
1). 使用last命令只显示前5个用户信息的第一个域 root@CGS-21-14:~# last -n 5 | awk '{print $1}' awk工作流程是这样的:读入有'\n'换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符是"空白键" 或 "[tab]键"
2). 只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以tab键分割 root@CGS-21-14:~# cat /etc/passwd |awk -F ':' '{print $1"\t"$7}'
3). 显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以逗号分割,而且在所有行添加列名name,shell,在最后一行添加”end, end” root@CGS-21-14:~# cat /etc/passwd |awk -F ':' 'BEGIN {print "name,shell"} {print $1","$7} END {print "end,end"}' 先执行BEGING,然后读取文件,读入有/n换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域,随后开始执行模式所对应的动作action。接着开始读入第二条记录...直到所有的记录都读完,最后执行END操作
4). 在/etc/passwd中搜索有root关键字的所有行 root@CGS-21-14:~# awk -F: '/root/' /etc/passwd
root:x:0:0:root:/root:/bin/bash
这种是pattern的使用示例,匹配了pattern(这里是root)的行才会执行action(没有指定action,默认输出每行的内容)。
搜索支持正则,例如找root开头的: awk -F: ‘/^root/’ /etc/passwd
5). 搜索/etc/passwd有root关键字的所有行,并显示对应的第1个域 root@CGS-21-14:~# awk -F: '/root/{print $1}' /etc/passwd
awk内置变量
ARGC 命令行参数个数
ARGV 命令行参数排列
ENVIRON 支持队列中系统环境变量的使用
FILENAME awk浏览的文件名
FNR 浏览文件的记录数
FS 设置输入域分隔符,等价于命令行 -F选项
NF 浏览记录的域的个数
NR 已读的记录数
OFS 输出域分隔符
ORS 输出记录分隔符
RS 控制记录分隔符- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
6). 统计/etc/passwd:文件名,每行的行号,每行的列数,对应的完整行内容 root@CGS-21-14:~# awk -F: '{print "filename:" FILENAME ",linenumber:" NR ",columns:" NF ",linecontent:"$0}' /etc/passwd
或可以用printf 代替 print root@CGS-21-14:~# awk -F: '{printf("filename:%10s,linenumber:%s,columns:%s,linecontent:%s\n",FILENAME,NR,NF,$0)}' /etc/passwd
awk编程
7). 统计/etc/passwd的账户人数 root@CGS-21-14:~# awk 'BEGIN {count=0;print "start counting ..."} {count=count+1;print $0;} END{printf("total user num : %d\n", count)}' /etc/passwd
8). 统计某个文件夹下的文件占用的字节数 root@CGS-21-14:/home/lhp# ls -r -l |awk 'BEGIN {size=0;} {size=size+$5;} END{printf("total file size is %d\n", size)}'
9). 统计某个文件夹下的文件占用的字节数,过滤4096大小的文件(一般都是文件夹),并以M为单位 root@CGS-21-14:/home/lhp# ls -l |awk 'BEGIN {size=0;printf("start counting...")} {if($5!=4096){size=size+$5;}} END{printf("the total size of files is %fM\n", size/1024/1024)}'
总结,awk语法上很多地方是借鉴于C,所以在输出、循环、数组上很类似。
但要注意数组,因为awk中数组的下标可以是数字和字母,数组的下标通常被称为关键字(key)。值和关键字都存储在内部的一张针对key/value应用hash的表格里。由于hash不是顺序存储,因此在显示数组内容时会发现,它们并不是按照你预料的顺序显示出来的。数组和变量一样,都是在使用时自动创建的,awk也同样会自动判断其存储的是数字还是字符串。一般而言,awk中的数组用来从记录中收集信息,可以用于计算总和、统计单词以及跟踪模板被匹配的次数等等
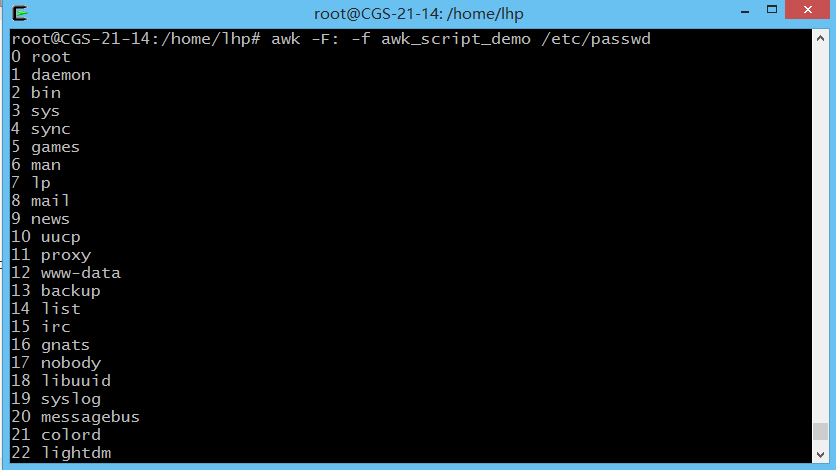
10). 通过awk脚本运行(注意左大括号的位置,不错会报错),我在测试中把脚本命名为awk_script_demo
BEGIN {
count=0;
}
{
name[count] = $1;
count ++;
};
END {
for(i=0;i < NR; i++)
printf("%d %s\n", i, name[i])
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
运行:
root@CGS-21-14:/home/lhp# awk -F: -f awk_script_demo /etc/passwd- 1
结果:
11) 上面还提到使用shell的方式运行awk,这是就不再赘述了
4. tcpdump
tcpdump就是:dump the traffic on a network,根据使用者的定义对网络上的数据包进行截获的包分析工具。 tcpdump可以将网络中传送的数据包的“头”完全截获下来提供分析。它支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助你去掉无用的信息。
命令格式:
常用参数描述:
-A 以ASCII码方式显示每一个数据包(不会显示数据包中链路层头部信息). 在抓取包含网页数据的数据包时, 可方便查看数据.
-c count tcpdump将在接受到count个数据包后退出.
-C file-size (此选项用于配合-w file 选项使用)
该选项使得tcpdump 在把原始数据包直接保存到文件中之前, 检查此文件大小是否超过file-size. 如果超过了, 将关闭此文件,另创一个文件继续用于原始数据包的记录. 新创建的文件名与-w 选项指定的文件名一致, 但文件名后多了一个数字.该数字会从1开始随着新创建文件的增多而增加. file-size的单位是百万字节(这里指1,000,000个字节,并非1,048,576个字节, 后者是以1024字节为1k, 1024k字节为1M计算所得, 即1M=1024 * 1024 = 1,048,576)
-d 以容易阅读的形式,在标准输出上打印出编排过的包匹配码, 随后tcpdump停止.
-D 打印系统中所有tcpdump可以在其上进行抓包的网络接口. 每一个接口会打印出数字编号, 相应的接口名字, 以及可能的一个网络接口描述. 其中网络接口名字和数字编号可以用在tcpdump 的-i flag 选项, 来指定要在其上抓包的网络接口.
-e 每行的打印输出中将包括数据包的数据链路层头部信息
-f 显示外部的IPv4 地址时, 采用数字方式而不是名字
-F file 使用file 文件作为过滤条件表达式的输入, 此时命令行上的输入将被忽略.
-i interface 指定tcpdump 需要监听的接口. 如果没有指定, tcpdump 会从系统接口列表中搜寻编号最小的已配置好的接口- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
1) 默认启动,该情况下将监视第一个网络接口上所有流过的数据包 root@CGS-21-14:/home/lhp# tcpdump
2) 使用-i参数,指定网络接口 root@CGS-21-14:/home/lhp# tcpdump -i eth0
3) 使用host指定主机(用主机名或者ip) root@CGS-21-14:/home/lhp# tcpdump -i eth0 host localhost root@CGS-21-14:/home/lhp# tcpdump -i eth0 host 127.0.0.1
4) 将在本机上执行tcpdump -i eth0截获的内容重定向到dump.txt中
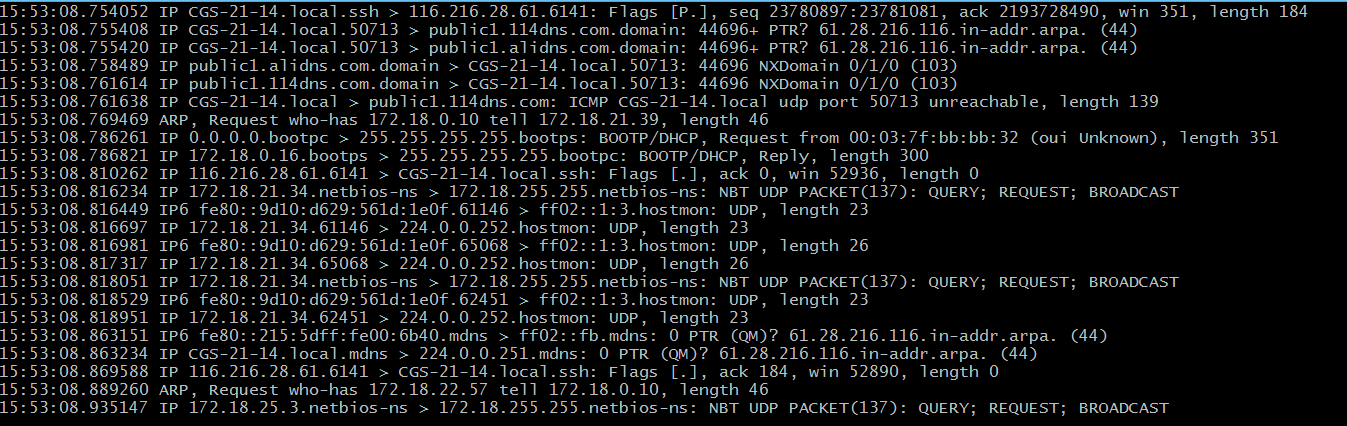
从上图中可以看出我当前是通过ssh的方式远程到我使用的Linux主机的,并可以得知ssh是基于TCP的。
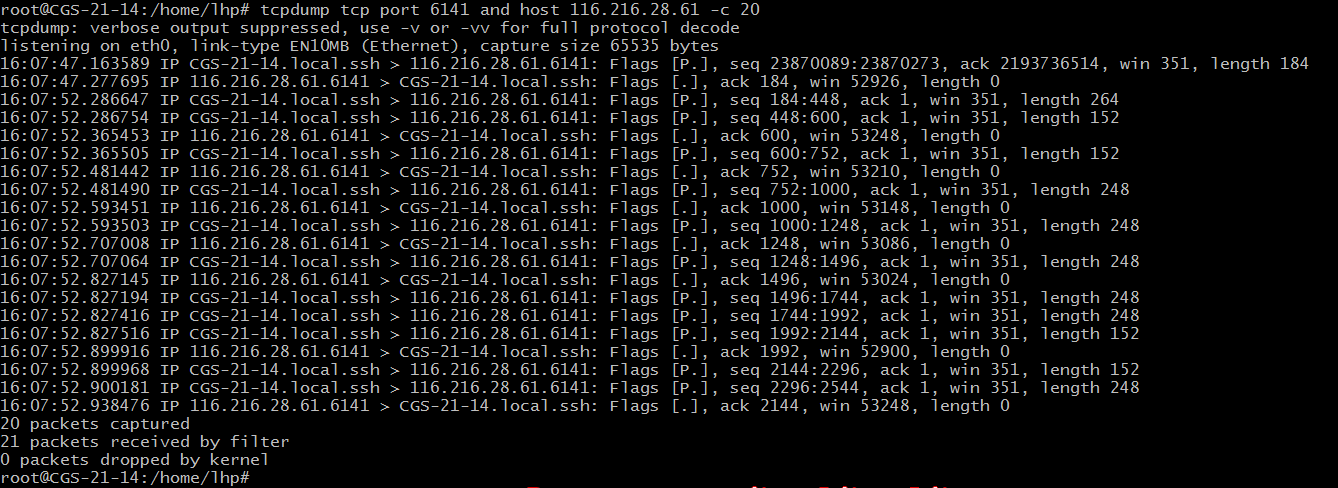
5) 所以可以尝试监视指定主机和端口的数据包,这里只截取20条数据 root@CGS-21-14:/home/lhp# tcpdump tcp port 6141 and host 116.216.28.61 -c 20
6) 监听指定主机和目标主机之前的通信,这里截获的本机和网关之间的数据 root@CGS-21-14:/home/lhp# tcpdump host 172.18.0.10 and 172.18.21.14
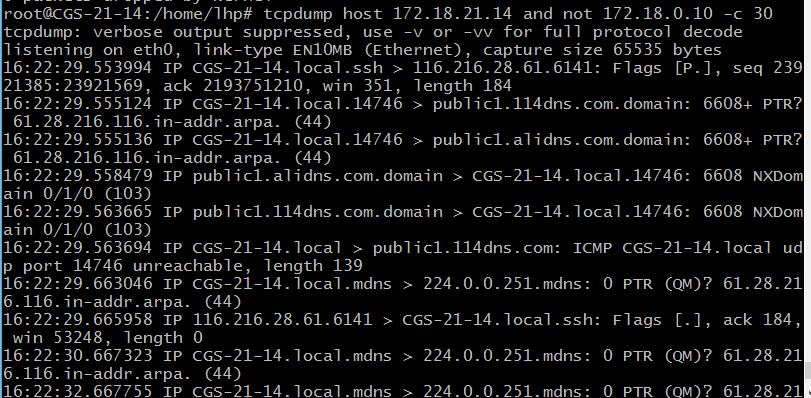
7) 除了可以像6)中使用and,还可以使用or、not,比如: root@CGS-21-14:/home/lhp# tcpdump host 172.18.21.14 and not 172.18.0.10 -c 30 root@CGS-21-14:/home/lhp# tcpdump host 172.18.21.14 and \(172.18.0.10 or 172.18.255.255\) -c 30
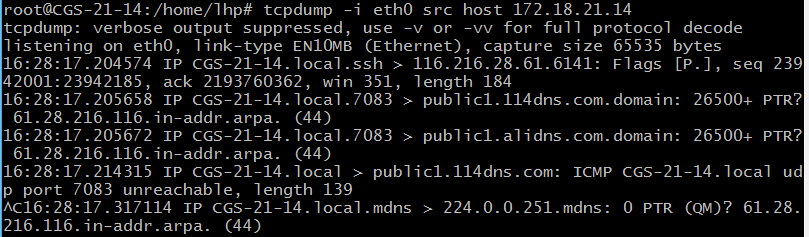
8) 截获指定主机发送的所有数据 root@CGS-21-14:/home/lhp# tcpdump -i eth0 src host 172.18.21.14
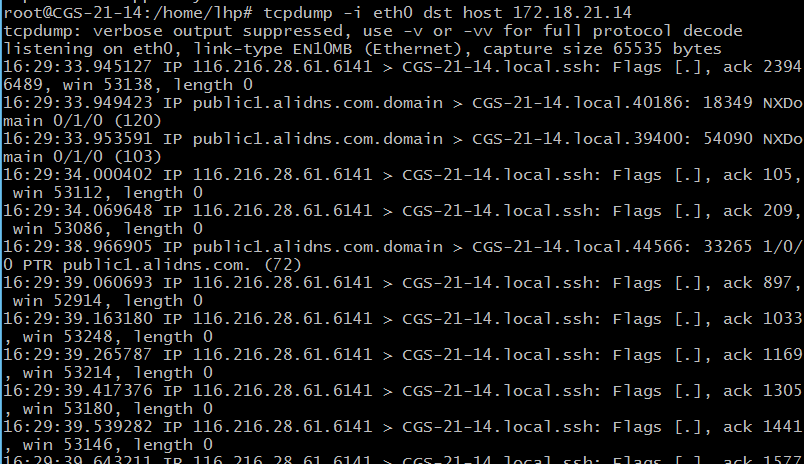
9) 截获指定主机收到的所有数据 root@CGS-21-14:/home/lhp# tcpdump -i eth0 dst host 172.18.21.14
10) 监听本地主机与本场网络上的主机之间的所有通信数据包 root@CGS-21-14:/home/lhp# tcpdump net 172.18.0.0/16
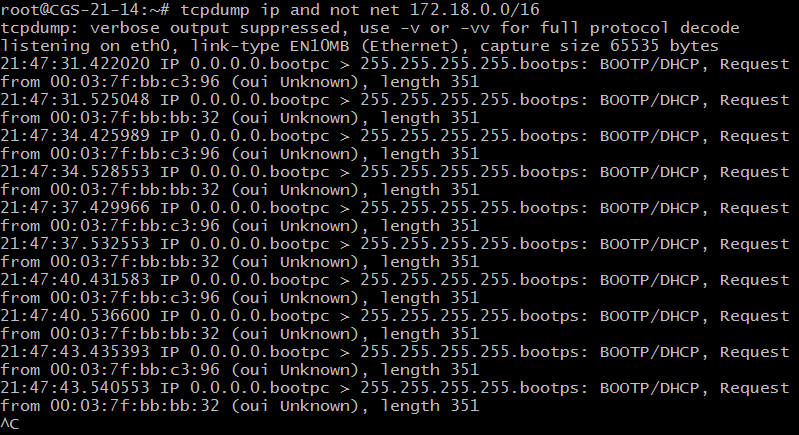
11) 打印所有源地址或目标地址是本地主机的IP数据包,如果本地网络通过网关连到了另一网络, 则另一网络并不能算作本地网络 root@CGS-21-14:/home/lhp# tcpdump 172.18.21.14 and not net 172.18.0.0/16
12)tcpdump抓包复杂实例 root@CGS-21-14:/home/lhp# tcpdump tcp -i eth0 -t -s 0 -c 100 and dst port ! 22 and src net 172.18.0.0/16 -w /home/lhp/log1.txt
参数说明如下: (1)tcp: ip icmp arp rarp 和 tcp、udp、icmp这些选项等都要放到第一个参数的位置,用来过滤数据报的类型
(2)-i eth1 : 只抓经过接口eth1的包
(3)-t : 不显示时间戳
(4)-s 0 : 抓取数据包时默认抓取长度为68字节。加上-S 0 后可以抓到完整的数据包
(5)-c 100 : 只抓取100个数据包
(6)dst port ! 22 : 不抓取目标端口是22的数据包
(7)src net 192.168.1.0/24 : 数据包的源网络地址为192.168.1.0/24
(8)-w ./target.cap : 保存成cap文件,方便用ethereal(即wireshark)分析
13) 使用tcpdump抓取HTTP包 root@CGS-21-14:/home/lhp# tcpdump -XvvennSs 0 -i eth0 tcp[20:2]=0x4745 or tcp[20:2]=0x4854
其中0x4745 为”GET”前两个字母”GE”,0x4854 为”HTTP”前两个字母”HT”

tcpdump 对截获的数据并没有进行彻底解码,数据包内的大部分内容是使用十六进制的形式直接打印输出的。显然这不利于分析网络故障,通常的解决办法是先使用带-w参数的tcpdump 截获数据并保存到文件中,然后再使用其他程序(如Wireshark)进行解码分析
5. strace
strace常用来跟踪进程执行时的系统调用和所接收的信号。 在Linux世界,进程不能直接访问硬件设备,当进程需要访问硬件设备(比如读取磁盘文件,接收网络数据等等)时,必须由用户态模式切换至内核态模式,通过系统调用访问硬件设备。strace可以跟踪到一个进程产生的系统调用,包括参数,返回值,执行消耗的时间.
常用参数说明:
-p 跟踪指定的进程
-f 跟踪由fork子进程系统调用
-F 尝试跟踪vfork子进程系统调吸入,与-f同时出现时, vfork不被跟踪
-o filename 默认strace将结果输出到stdout。通过-o可以将输出写入到filename文件中
-ff 常与-o选项一起使用,不同进程(子进程)产生的系统调用输出到filename.PID文件
-r 打印每一个系统调用的相对时间
-t 在输出中的每一行前加上时间信息。 -tt 时间确定到微秒级。还可以使用-ttt打印相对时间
-v 输出所有系统调用。默认情况下,一些频繁调用的系统调用不会输出
-s 指定每一行输出字符串的长度,默认是32。文件名一直全部输出
-c 统计每种系统调用所执行的时间,调用次数,出错次数。
-e expr 输出过滤器,通过表达式,可以过滤出掉你不想要输出- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
使用实例(跟踪ps运行):
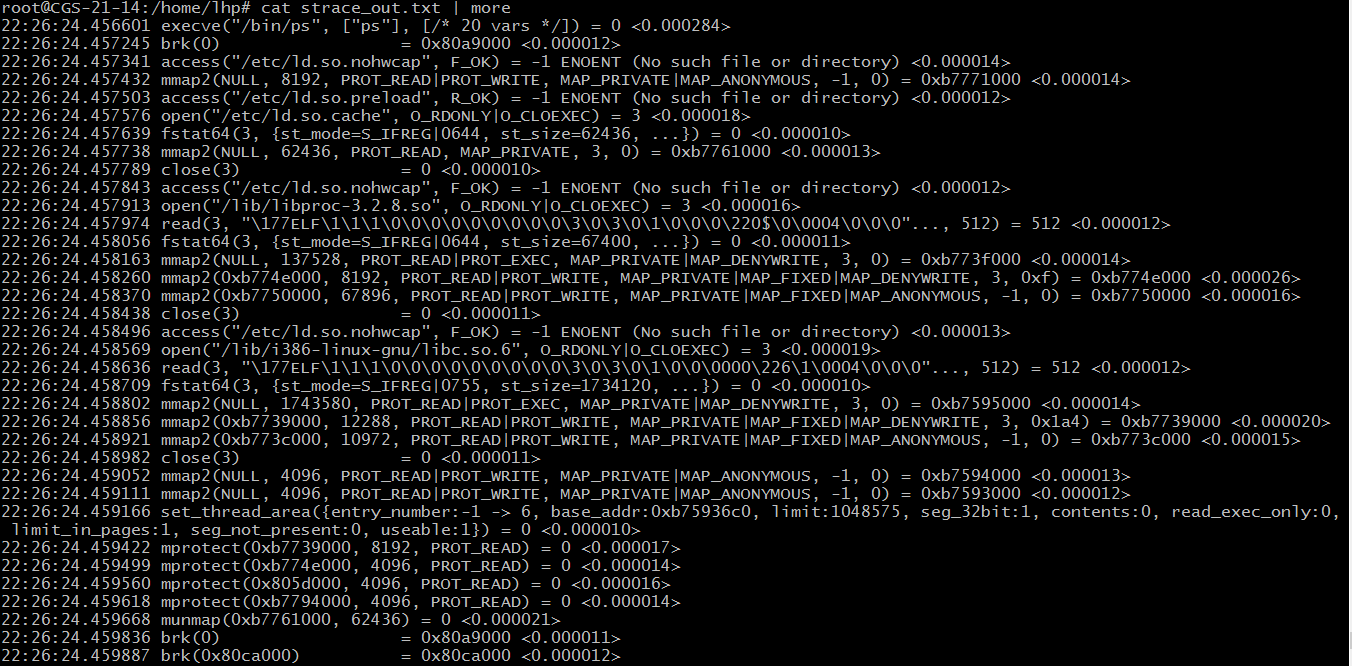
root@CGS-21-14:/home/lhp# strace -o strace_out.txt -T -tt -e trace=all ps- 1
结果:
附:删除已输入的命令
ctrl + w —往回删除一个单词,光标放在最末尾
ctrl + k —往前删除到末尾,光标放在最前面(可以使用ctrl+a)
ctl + u 删除光标以前的字符
ctl + k 删除光标以后的字符
ctl + a 移动光标至的字符头
ctl + e 移动光标至的字符尾
ctl + l 清屏
参考资料
http://www.cnblogs.com/ggjucheng/archive/2013/01/13/2856896.html
http://www.cnblogs.com/dong008259/archive/2011/12/07/2279897.html
http://www.cnblogs.com/ggjucheng/archive/2013/01/13/2858470.html
http://www.cnblogs.com/ggjucheng/archive/2012/01/14/2322659.html
http://www.cnblogs.com/ggjucheng/archive/2012/01/08/2316692.html