完全小白的pycharm深度学习调试+for循环断点条件设置
写在最前面
之前把seq2seq+attention基础代码,从机器翻译迁移到文本摘要,再加上是自己的数据集,结果全显示截止符;
一方面可能是数据问题,一方面可能是我代码改错了,一方面可能是模型太基础了,一方面程序也没有报错;
所以排查起来很是头疼
一直尝试debug,但是百度不到类似的好方法,所以很是艰辛
今天很幸运的得到了实习的吕老师指点一二
特此记录,方便自己之后查询,也和大家分享一下,有好用的方法欢迎留言交流~
参考:https://zhuanlan.zhihu.com/p/62610785
https://blog.csdn.net/dong_liuqi/article/details/114980453
基础方法
断点调试,breakpoint。
在程序自动运行的过程中,程序只跑到你设置的断点位置处,则会中断下来,此时可以看到之前运行过的所有程序变量。
pycharm断点调试
点击行号后面区域,会出现一个红点,那个点就是设置的断点
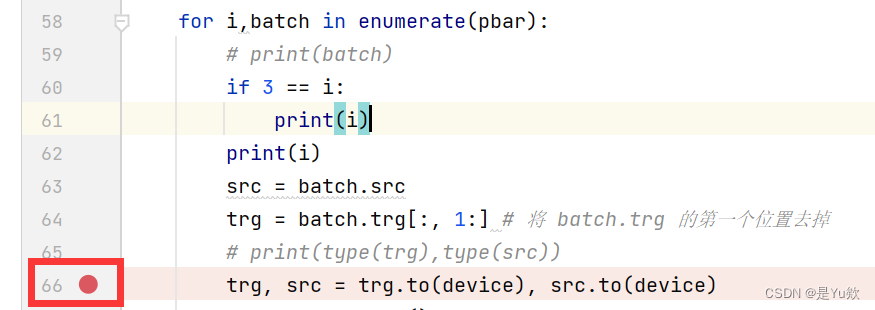
下拉框选择当前.py文件后,点击小虫子图标,进入debug 模式
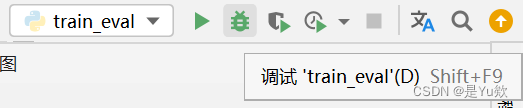
与正常的 run 去运行程序没很大差异
区别就是 pycharm 的控制台部分,从 run 跑到了 debug 显示。
并且可以显示所有的变量。
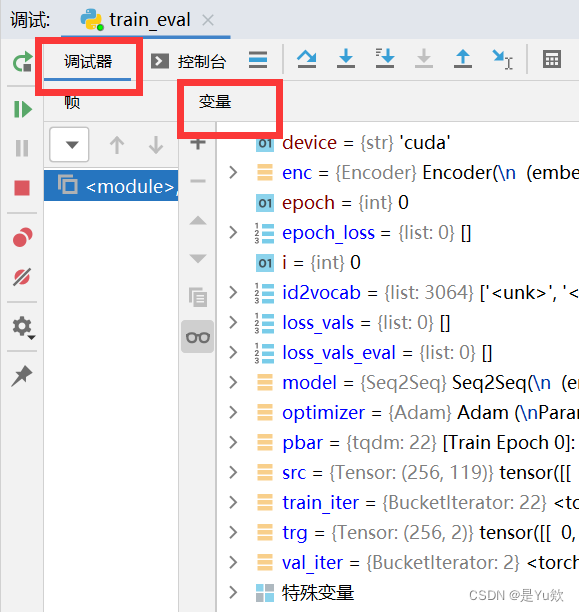
控制台输入
直接打印想要了解的张量or其他变量
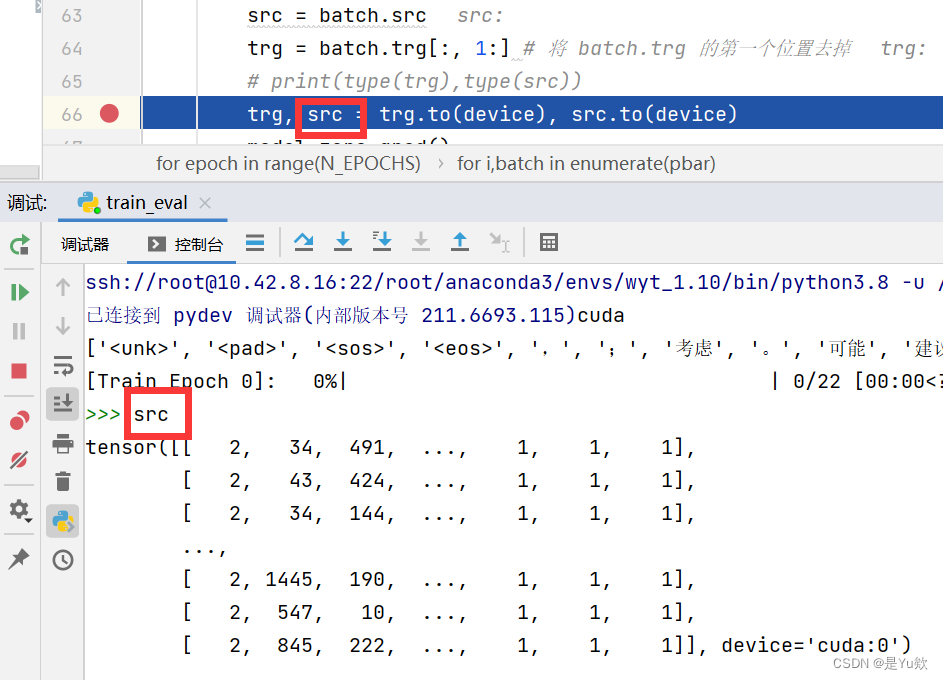
将变量转为numpy,方便更直观的显示
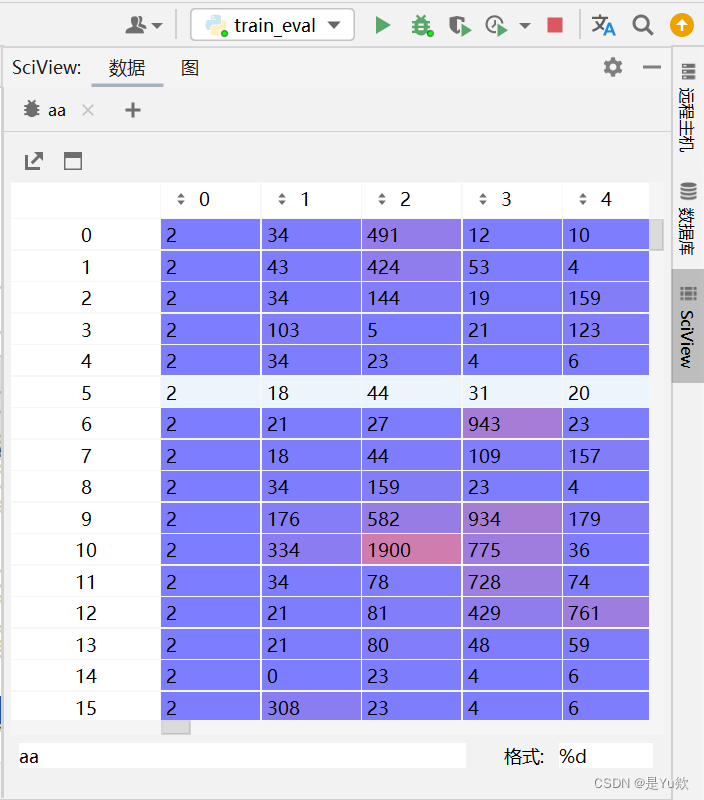
命名为aa,显示在所有变量最前面(小细节太帅了)
如果是gpu跑的代码,记得加上cpu(),将数据转移到本机
aa = src.cpu().numpy()
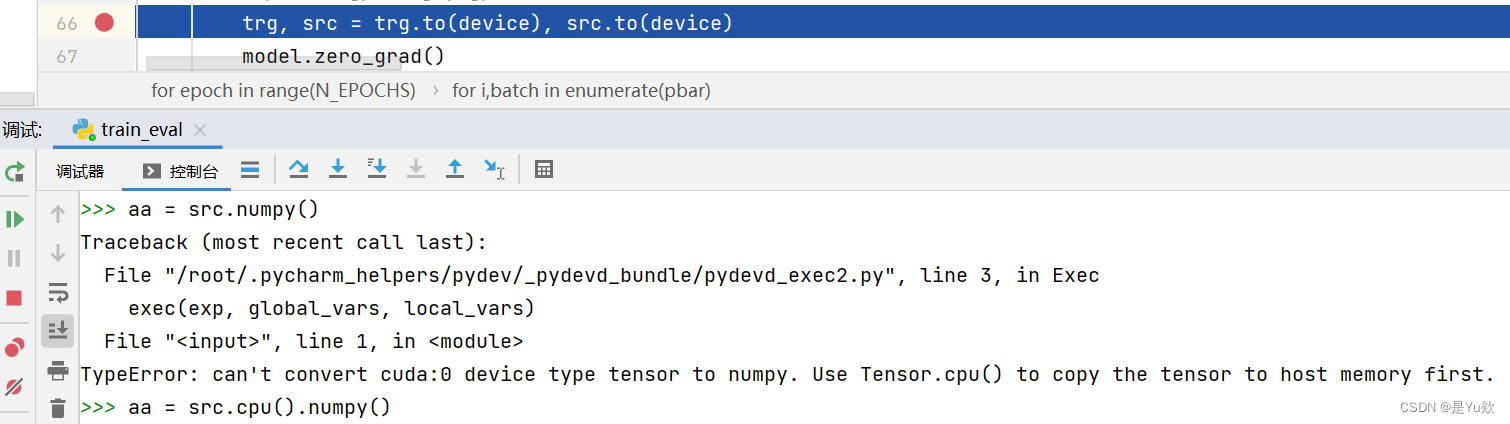
前后区别对比
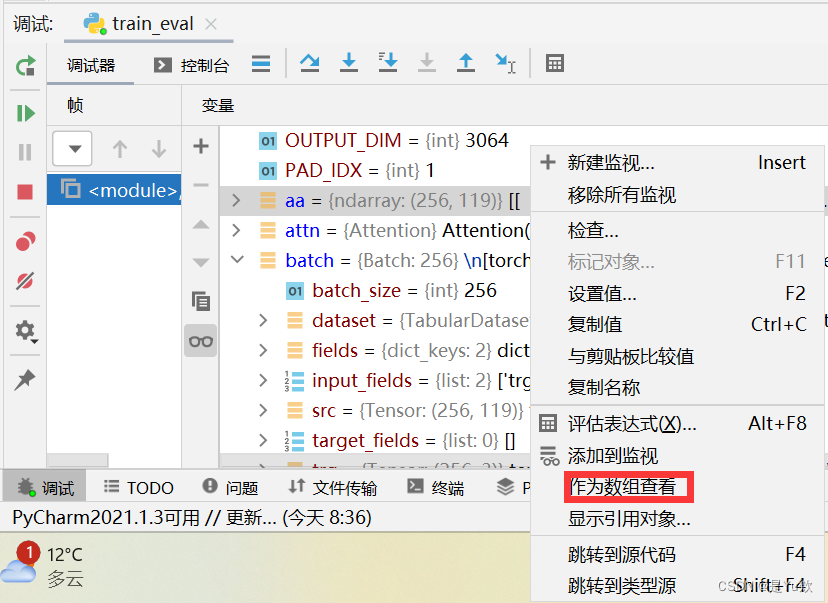
并且作为numpy变量,这个是实时变化的~
也可设置为监视对象
代码中循环的debug方法
想要i=3时停下来
方法一:新增判断语句,并对if的条件设置断点

方法二:断点右键设置条件
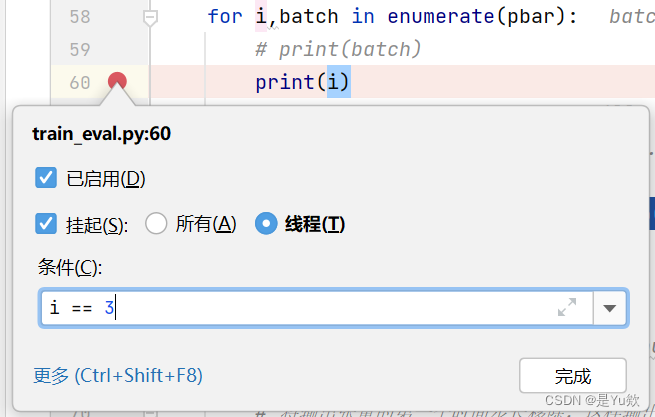
程序直接跳到i=3。简直完美
pycharm中图标的介绍
仅对常用的展开说明,其他的可通过鼠标悬停查看
一般操作步骤就是:
设置好断点,debug运行,
然后 F8单步调试,
遇到想进入的函数 F7 进去,
想出来在 shift + F8,
跳过不想看的地方,直接设置下一个断点,然后 F9 过去。
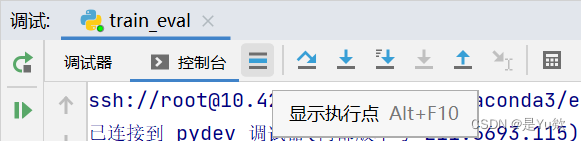
step over(F8快捷键):在单步执行时,在函数内遇到子函数时不会进入子函数内单步执行,而是将子函数整个执行完再停止,也就是把子函数整个作为一步。在不存在子函数的情况下是和step into效果一样的。简单的说就是,程序代码越过子函数,但子函数会执行,且不进入。
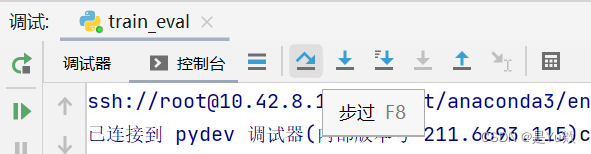
step into(F7快捷键):在单步执行时,遇到子函数就进入并且继续单步执行,有的会跳到源代码里面去执行。
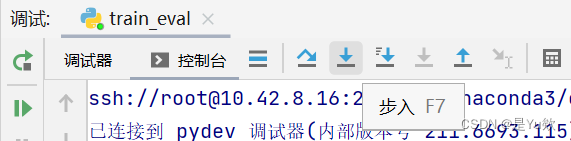
step into my code(Alt+Shift+F7快捷键):在单步执行时,遇到子函数就进入并且继续单步执行,不会进入到源码中。

step out(Shift+F8快捷键):假如进入了一个函数体中,你看了两行代码,不想看了,跳出当前函数体内,返回到调用此函数的地方,即使用此功能即可。
可输入表达式,然后进行evaluate

Resume program(F9快捷键):继续恢复程序,直接运行到下一断点处。
常见的Bug
深度模型的Debug与一般程序的Debug有很大的不同。
一般程序的Debug通常可以通过简单地打断点调试出来,而深度模型通常会出现程序的所有模块都可以正常跑通,但就是模型效果与正常情况相去甚远,这种Debug就非常的困难.
对于大模型来说,一处"笔误"可能也会导致很大的问题。
-
某一部分参数梯度总为0
可能是程序里存在"笔误", 有一部分的参量并没有加入模型中进行运算 -
Loss不下降
(未完待续)
Debug经验
1. 检查激活函数的输入值
使用Relu系的激活函数时, 如果输入激活函数前的数值异常大, 那么可能导致之后的结果出现问题.
使用Sigmoid时, 如果输入激活函数前的数值远远超出了其激活范围(即[-1,1]), 也可能导致训练出现严重问题.
2. 检查梯度
检查梯度是否消失
检查梯度是否爆炸
具体方法:直接输出各个参数的梯度
def _print_grad(self, model):
'''Print the grad of each layer'''
for name, parms in model.named_parameters():
print('-->name:', name, '-->grad_requirs:',parms.requires_grad, ' -->grad_value:',parms.grad)
先输出该层参数是否存在梯度, 再输出梯度值. 这个函数应该放在梯度反向传播计算之后, 即loss.backward()之后.
3. 消融实验
如果一个深度模型中有多个模块, 可以使用消融实验的方法对每个模块进行测试.
这样可以先定位出问题出在哪个模块里, 即缩小bug的范围.
如果每个模块都有问题, 那么则应该去检查数据输入以及训练部分是否存在问题.
⭐️ 我觉得这各方法非常重要, 因为他能帮助定位bug的范围. 其实debug最大的难点就在于确定bug的位置.
4. 使用最短的时间
如果问题不是训练本身的精度不够等问题, 可以适当调整batch size的大小来加快训练.
这样可以提高debug效率.
5. 静下心来
遇到bug首先要静下心来想问题可能出现的地方, 然后一步步去排查.
最好是能将问题以及排查结果进行记录, 这样可以更好地分析问题所在.
切忌还没有想好问题就一遍遍地跑训练, 其实这样做是非常浪费时间的.
在很多次尝试后, 都没能够将bug排除也是很有可能遇到的事情, 这时候会非常烦躁, 不利于问题的分析. 建议先去完成其他的任务, 在冷静下来后再继续进行debug(本人亲测有效, 有时甚至第二天一开始就干掉了bug).