最近在用python接受网络数据的时候,输出时总是遇到编码的问题,虽然都解决了,但深刻意识到自己其实对python的编码并没有清晰的认识,所以才会遇到这样的问题。今天就此总结一下,以免日后夜长梦多。
1 字符编码
首先,谈一下什么是字符编码。先看看计算机是怎么表示数字的,计算机使用二进制(为什么?),最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的数字个数是256个,比如0~255(二进制11111111 = 十进制255),要想表示更大的数字,就得用更多的字节。也就是说,其实数字最终存在计算机中都是逻辑上的0和1的组合,不同的存储介质有不同的物理表现,比如在磁盘中每个磁质单元的磁性表示位的信息。数字的表示是如此,那字符呢?之所以我们对数字存成二进制有比较直观的理解,是因为二进制的概念在计算机出现之前早就有了,这是数学上的概念,而我们常用的十进制数字对应成二进制自然是比较简单的。但是当碰到字符时,我们就不知道如何下手了。其实也很简单,既然计算机能存数字,那肯定也能存字符,只要我们把字符和数字给对应上就行了,这个需要一套统一的规则进行对应,这样使用者才能达成共识。
计算机是美国人发明的,所以最早的字符编码也是他们规定的,只有127个字符被编码到计算机里,可以用来表示一些字母、数字和其他一些符号,这就是 ASCII码 。
在当时来说,这些已经足够了。但是如果要处理中文,这显然是不够的,所以中国制定了GB2312编码。同理,其他国家也会有其他国家的编码,因为使用的语言不同。很容易想到,这会有一个问题,就是当一个文本中出现多种语言时,该如何进行编码?
所以,Unicode 就是用来解决这个问题的,把所有语言都统一到一个编码里面去,这样就不会出现问题了。
Unicode中大部分的字符都是用两个字节表示(除了一些比较生僻的字符),现代操作系统和大多数编程语言都直接支持Unicode。
比如中字在ascii中是找不到对应编码的,而在unicode中对应的十进制数为20013,表示成二进制就是01001110 00101101。
很显然,unicode比ascii是更加占用空间的,如果文本是中文或者混杂其他非英文语言的话,这是不可避免的,毕竟要编码更多的字符,就得用更大的空间。但如果文本是英文的话,用unicode存储会比ascii大一倍的空间,这显然是不希望看到的。可能会有人想到可以用哈夫曼编码,根据字符出现的频率来决定各个字符的不同长度,这也不失为一种办法,但是世界上这么多字符,要如何统计呢?以哪些文本作为统计的依据?并且不同地区使用的字符频率也不相同。但为了解决这个问题,还是有一种新的编码方式被提出了,那就是utf-8,这种编码采用更加灵活的变长方式,把一个Unicode字符根据不同的数字大小编码成1-6个字节使得原来的ascii编码能表示的字符,仍然按照原来的编码进行,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。举个栗子:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
这样还有一个好处,就是utf-8编码可以兼容以前使用ascii编码的文本,解决一些历史遗留问题。
现在计算机系统通用的字符编码工作方式:在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器。
2 python 的字符串
理清了字符编码的来龙去脉,我们再来看看python中字符串的编码。
python 源代码
首先,python的源代码是文本文件,所以其保存和读取是按一定的编码进行的。保存时的编码按照编辑器指定的保存编码进行,那python解释器在读取源代码时是按照什么格式进行读取的呢?
以python2.7为例,运行下面的代码:
# 中文
没错,这只是一个注释,其实中文不管出现在哪里,都是一样的,因为这个时候都只是被当成文本处理。运行之后会报以下错误:
SyntaxError: Non-ASCII character '\xe4' in file F:/projects/pycharm/test/coding_test.py on line 2, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
说的是文件中存在非ascii字符,并且没有指定编码,所以解释器无法识别该字符,点进去那个链接,可以看到详情。里面有这么一句话:
Python will default to ASCII as standard encoding if no other encoding hints are given.
如果没有其他编码提示,python默认使用ASCII作为标准编码。
保存的时候是按照utf-8编码进行保存的,所以字符串中文在存储中的表示就是'\xe4\xb8\xad\xe6\x96\x87'(实际上是二进制,这种十六进制表示是为了方便讨论,将字节11100100表示为\xe4)。然而由于没有指定编码,所以python解释器默认使用ASCII编码进行读取,遇到\xe4这样的非ASCII字符自然无能为力了。所以需要我们手动对编码进行指定,以确保跟保存时的编码一致。指定的方式是在源文件的第一行或第二行进行注明,注明的字符串需满足以下正则表达式:
^[ \t\f]*#.*?coding[:=][ \t]*([-_.a-zA-Z0-9]+)
常见的方式是:
# -*- coding: utf-8 -*-
加上这一行后,代码就能正常运行了。
python 2.7 中的str和unicode
python 3 和 python 2 的字符编码略有差别,这里以2.7为例进行讨论,理解了这个,再去看python 3 的其实也很好理解,都是类似的道理。注意以下的讨论都是在python 2.7中进行的。
python 2.7 中,有两种字符串类型,一种是str,一种是unicode,两者的差别在于:
str is text representation in bytes, unicode is text representation in unicode characters(or unicode bytes).
意思就是,unicode的字符编码类型是unicode,给出一个unicode字符串,我就会按unicode的方式去解码,也就是说他表示的字符也确定了;但str不是这样的,它只是一些字节,如果不知道编码格式的话,那就不知道如何处理,只有最初打出来的人才能通过适当的编码集进行解码。而python在print一个str的时候是默认按照utf-8进行解码的,所以当打印以下字符时,会出现乱码:
s = '\xd6\xd0\xce\xc4'
print s
原因是以上的字节其实是字符串中文按照gbk编码得到的结果,而默认用utf-8解码进行打印时,自然就出现乱码了,要想正常显示,可以指定用gbk的方式进行解码:
s = '\xd6\xd0\xce\xc4'
print s.decode('gbk')
这样就能正常地打印出中文两个字了。
str
当我们以引号的方式进行一个字符串字面量的声明时,表示的是str类型,比如:
# -*- coding: utf-8 -*-
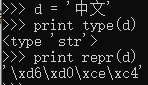
d = '中文'
print type(d)
print repr(d)
repr返回对象的canonical string(标准字符串)形式,当为str类型时,如果字符在ascii编码范围内,则显示的是字符本身,否则,以\xXX的形式表示,其中XX为其十六进制表示。输出的结果是:
<type 'str'>
'\xe4\xb8\xad\xe6\x96\x87'
这里的字节码结果是采用utf-8进行编码的,但这是不一定的,得看当前编辑器的设置。比如如果在命令行下运行以上python语句的话,出来的结果是'\xd6\xd0\xce\xc4',这是因为在该环境下是gbk编码。所以当我们在处理字符串的时候,不能看表面显示出来的字符,否则很容易出错,我们看到的中文在不同环境下可能是不一样的。
unicode
那如果要声明一个unicode字符串怎么做呢?只需要在字符串的引号前加一个u即可:
d = u'中文'
print type(d)
print repr(d)
输出为:
<type 'unicode'>
u'\u4e2d\u6587'
str和unicode之间的转换
str和unicode之间是可以进行转换的,可以使用encode和decode方法。
- encode
encode的输入必须是unicode类型,返回的一定是一个str类型,也就是将一个unicode字符串按照指定的编码进行,转成str。
输出为:d = u'中文' print repr(d.encode('utf-8')) print repr(d.encode('gbk')) print type(d.encode('utf-8')) print type(d.encode('gbk'))'\xe4\xb8\xad\xe6\x96\x87' '\xd6\xd0\xce\xc4' <type 'str'> <type 'str'> - decode
decode的输入必须是str类型,返回的一定是一个unicode类型,也就是将一个unicode字符串按照指定的编码进行解码,转成unicode。
输出为:s1 = '\xd6\xd0\xce\xc4' s2 = '\xe4\xb8\xad\xe6\x96\x87' print repr(s1.decode('gbk')) print repr(s2.decode('utf-8')) print type(s1.decode('gbk')) print type(s1.decode('gbk'))u'\u4e2d\u6587' u'\u4e2d\u6587' <type 'unicode'> <type 'unicode'>
以上说encode的输入必须是unicode类型,decode的输入必须是str类型,那么如果不是相应的类型,会怎么样?试一下吧:
d = u'中文aa'
print d.decode('utf-8')
然后就报错了:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
说的是ascii无法对位置0-1的字符进行编码,为什么会有编码?我不是在解码吗?思考了之后,我有了一个合理的推测:如果decode输入不是str类型,那么会先将其转为str,也就是说,会对其调用encode,并且此时由于没有指定编码,所以默认以ascii进行编码,遇到中文就报错了。可以做个试验:
d = u'cc中文aa'
d.encode()
果然报的错是一样的:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 2-3: ordinal not in range(128)
再看看下面的代码:
d = u'hello'
# print repr(d)
print repr(d.decode('utf-8'))
print repr(d.encode())
没有报错,输出是:
u'hello'
'hello'
这样看来,上面的推测是合理的。
以上就是对python编码的总结,一边查资料一边思考一边写,有种豁然开朗的感觉。如果有任何错误,欢迎在评论区留言指正。
此外,在写这篇文章的时候,对encode(‘base64’)和‘unicode-escape’还没有完全搞明白,等以后有时间再总结。
参考:
[1] 廖雪峰python教程:字符串和编码
[2] 0和1
[3] Python encode和decode
补充:
对于encode输入必须是unicode的问题,在这里补充以下,encode(‘base64’)是个例外,其输入为str。
试验如下:
s = u'hhe哈eh'
print type(s.encode('base64'))
报错:
UnicodeEncodeError: 'ascii' codec can't encode character u'\u54c8' in position 3: ordinal not in range(128)
从结果来看,程序对s进行了ascii编码,那只能猜想其先对s做了一次encode,并且默认为ascii编码,再次试验:
s = u'hhe哈eh'
print type(s.encode().encode('base64'))
报的错误是一样的:
UnicodeEncodeError: 'ascii' codec can't encode character u'\u54c8' in position 3: ordinal not in range(128)
改为:
s = u'hhe哈eh'
print s.encode('utf-8').encode('base64')
print type(s.encode('utf-8').encode('base64'))
输出:
aGhl5ZOIZWg=
<type 'str'>
可见encode(‘base64’)的输入为str时可以正常,而为unicode时会将其先进行一次encode转为str(默认采用ascii,如果出现非ascii字符会报错),所以可以推测其输入应该为str。
其实再跑一下下面的代码就明白了:
print 'aGhl5ZOIZWg='.decode('base64')
print type('aGhl5ZOIZWg='.decode('base64'))
输出:
print 'aGhl5ZOIZWg='.decode('base64')
print type('aGhl5ZOIZWg='.decode('base64'))
可见decode的结果也不一定是unicode,在使用base64解码时,其值仍然是str。之所以base64编码解码的输入和输出都是str,可能与base64的编码规则有关。