目录
一.链表
1.什么是链表
链表是一种
物理存储结构上非连续
存储结构,数据元素的
逻辑顺序
是通过链表中的
引用链接
次序实现的 。

2.链表的分类
链表的类型多种多样,具体可以分为:
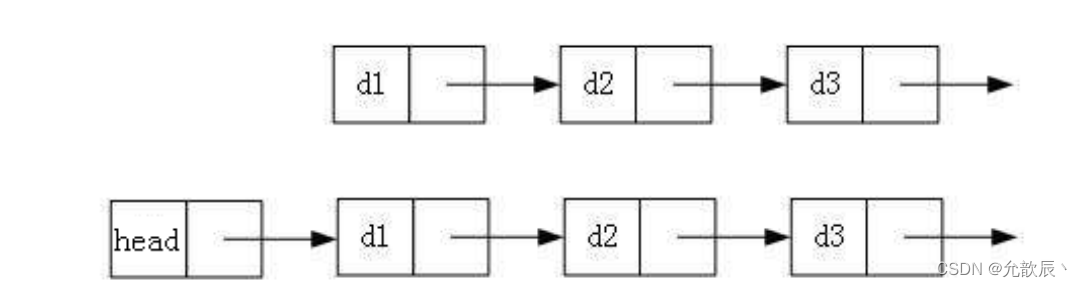
1.带头结点的链表和不带头结点的链表
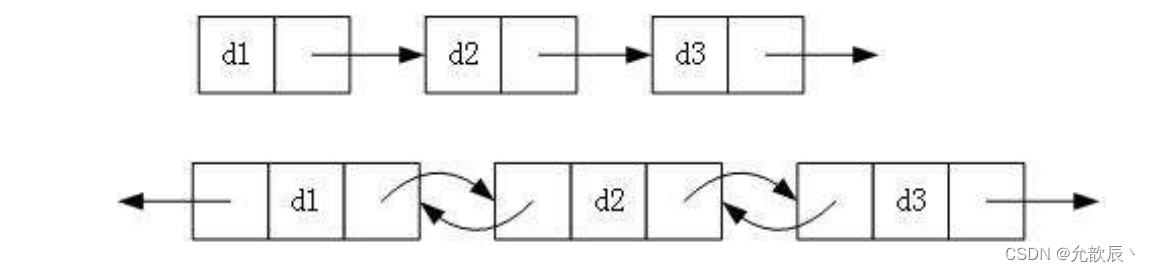
2.单向链表和双向链表
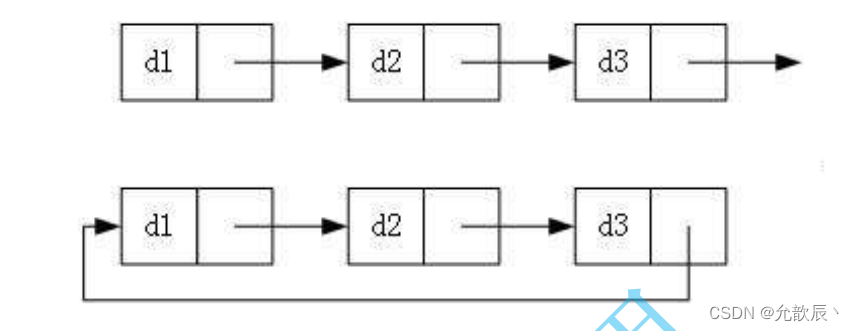
 3.循环的和非循环的
3.循环的和非循环的
二.不带头结点单向链表的非递归实现
1.接口的定义
在实现具体的方法之前,我们先定义一个接口,之后的这些链表都将实现这些接口,实现这些接口内的方法,主要包含了一些常用的CRUD方法.这个接口我们使用了泛型,之后的链表类也将继承这个接口的泛型,元素的类型就是泛型的类型
public interface SeqList<E> {
// 在线性表中的最后插入值为element的新元素
void addLast(E element);
// 在线性表的前边插入新元素,插入后的元素下标为index
void addFirst(E element);
//在索引为index处插入值为element的结点
void add(int index, E element);
// 删除当前线性表中索引为index的元素,返回删除的元素值
E removeByIndex(int index);
// 删除当前线性表中第一个值为element的元素
void removeByValue(E element);
// 删除当前线性表中所有值为element的元素
void removeAllValue(E element);
// 将当前线性表中index位置的元素替换为element,返回替换前的元素值
E set(int index, E element);
// 得到下标为index结点的值
E get(int index);
// 查询链表内是否包含element的结点
boolean contains(E element);
// 查询当前线性表中第一个值为element的下标
int indexOf(E element);
}2. 不带头结点单向链表的结构
我们这里定义了一个内部类Node,为单向链表的结点类,同时单向链表的属性包含了头结点的引用信息和链表结点个数的定义
public class SingleLinkedList<E> implements SeqList<E> {
private Node head; //第一个结点的位置
private int size; //链表结点的个数
private class Node {
E val;
Node next;
public Node(E val) {
this.val = val;
}
}
@Override
public void addLast(E element) {
}
@Override
public void addFirst(E element) {
}
@Override
public void add(int index, E element) {
}
@Override
public E removeByIndex(int index) {
return null;
}
@Override
public void removeByValue(E element) {
}
@Override
public void removeAllValue(E element) {
}
@Override
public E set(int index, E element) {
return null;
}
@Override
public E get(int index) {
return null;
}
@Override
public boolean contains(E element) {
return false;
}
@Override
public int indexOf(E element) {
return 0;
}
}3.链表的添加操作(头插法和尾插法)
1.头插法
@Override
public void addFirst(E element) {
//产生一个值为element的结点
Node newNode = new Node(element);
//当前结点的指向头结点
newNode.next = head;
//更新head的引用,将其指向新节点
head = newNode;
size++;
}2.尾插法
@Override
public void addLast(E element) {
Node temp = head;
if (head == null) {
head = new Node(element);
size++;
return;
}
while (temp.next != null) {
temp = temp.next;
}
temp.next = new Node(element);
size++;
}4. 链表的插入操作
记住:插入和删除的关键是找到插入和删除位置的前驱节点
@Override
public void add(int index, E element) {
//边界的判断
if (!rangeCheck(index)) {
throw new IllegalArgumentException("get index illegal!");
}
//头插
if (index == 0) {
addFirst(element);
return;
}
//尾插
if (index == size) {
addLast(element);
return;
}
Node temp = head;
//找到插入位置的前驱节点
for (int i = 0; i < index - 1; ++i) {
temp = temp.next;
}
Node newNode = new Node(element);
newNode.next = temp.next;
temp.next = newNode;
size++;
}
//index的检查
private boolean rangeCheck(int index) {
//如果插入的位置索引不合理,返回false
if (index < 0 || index > size) {
return false;
}
return true;
}
5.链表的删除操作
1.删除指定索引的结点
@Override
public E removeByIndex(int index) {
//边界的判断
if (!rangeCheck(index)) {
throw new IllegalArgumentException("get index illegal!");
}
//判断头结点的删除
if (index == 0) {
Node node = head;
head = head.next;
node.next = null;
size--;
return node.val;
}
//除头结点的输出,找到要删除位置的前驱节点
Node temp = head;
for (int i = 0; i < index - 1; ++i) {
temp = temp.next;
}
Node node = temp.next;
temp.next = temp.next.next;
node.next = null;
size--;
return node.val;
}2.删除指定值的第一个结点
@Override
public void removeByValue(E element) {
if (head == null)
return;
//删除的恰好是头结点
if (head.val.equals(element)) {
head = head.next;
size--;
return;
}
//删除的是其他节点
Node temp = head;
while (temp.next != null) {
if (temp.next.val.equals(element)) {
temp.next = temp.next.next;
size--;
return;
}
temp = temp.next;
}
//没有要删除值的结点
System.out.println("当前链表中不存在值为:" + element + "的结点");
}3.删除指定值的所有结点
@Override
public void removeAllValue(E element) {
if (head == null) {
return;
}
//删除的恰好是头结点
while (head != null && head.val.equals(element)) {
head = head.next;
size--;
}
//链表全部删完了
if (head == null) {
return;
}
//删除的是其他节点
Node temp = head;
while (temp.next != null) {
if (temp.next.val.equals(element)) {
temp.next = temp.next.next;
size--;
} else {
//只有后继节点不是element的时候才能移动
temp = temp.next;
}
}
}
6.链表的其他操作
1.将指定索引的结点的值更换为指定值
@Override
public E set(int index, E element) {
//边界的判断
if (!rangeCheck(index)) {
throw new IllegalArgumentException("get index illegal!");
}
Node temp = head;
//找到索引为index的结点
for (int i = 0; i < index; ++i) {
temp = temp.next;
}
//保存结点的旧值
E oldValue = temp.val;
//将索引为index结点的值更换为element
temp.val = element;
return oldValue;
}2.获得指定索引结点的值
@Override
public E get(int index) {
//边界的判断
if (!rangeCheck(index)) {
throw new IllegalArgumentException("get index illegal!");
}
Node temp = head;
//找到索引为index的结点
for (int i = 0; i < index; ++i) {
temp = temp.next;
}
return temp.val;
}3.判断链表是否包含指定值
@Override
public boolean contains(E element) {
Node temp = head;
while (temp != null) {
if (temp.val.equals(element)) {
return true;
}
temp = temp.next;
}
return false;
}4.获得指定值的第一个索引
@Override
public int indexOf(E element) {
//头结点为空
if (head == null)
return -1;
Node temp = head;
for (int i = 0; i < size; ++i) {
if (temp.val.equals(element)) {
return i;
}
temp = temp.next;
}
//表示没有找到值为element的结点的索引
return -1;
}5.toString方法
@Override
public String toString() {
Node temp = head;
StringBuffer sb = new StringBuffer();
while (temp != null) {
sb.append(temp.val + "->");
temp = temp.next;
}
sb.append("NULL");
return sb.toString();
}
三.带头结点单向链表的非递归实现
1.带头结点单向链表的结构
带头结点的单链表有一个虚拟头结点,头结点里面存储的值并不是链表中真实的值,没有实际意义,只是作为一个头结点的存在,同时size的值不会因为虚拟头结点的存在加一.
public class SingleLinkedListWithHead<E> implements SeqList<E> {
private class Node {
E val;
Node next;
public Node(E val) {
this.val = val;
}
}
private Node dummyHead = new Node(null);
int size = 0;
@Override
public void addFirst(E element) {
}
@Override
public void addLast(E element) {
}
@Override
public void add(int index, E element) {
}
@Override
public E removeByIndex(int index) {
return null;
}
@Override
public void removeByValue(E element) {
}
@Override
public void removeAllValue(E element) {
}
@Override
public E set(int index, E element) {
return null;
}
@Override
public E get(int index) {
return null;
}
@Override
public boolean contains(E element) {
return false;
}
@Override
public int indexOf(E element) {
return 0;
}
}
2.链表的添加操作(头插法和尾插法)
1.头插法
@Override
public void addFirst(E element) {
Node node = new Node(element);
node.next = dummyHead.next;
dummyHead.next = node;
size++;
}2.尾插法
@Override
public void addLast(E element) {
Node temp = dummyHead;
for (int i = 0; i < size; ++i) {
temp = temp.next;
}
Node node = new Node(element);
temp.next = node;
size++;
}3. 链表的插入操作
@Override
public void add(int index, E element) {
//边界的判断
if (!rangeCheck(index)) {
throw new IllegalArgumentException("get index illegal!");
}
if (index == 0) {
addFirst(element);
return;
}
if (index == size) {
addLast(element);
return;
}
Node temp = dummyHead;
Node node = new Node(element);
for (int i = 0; i < index; ++i) {
temp = temp.next;
}
node.next = temp.next;
temp.next = node;
size++;
}4.链表的删除操作
1.删除指定索引的结点
@Override
public E removeByIndex(int index) {
//边界的判断
if (!rangeCheck(index)) {
throw new IllegalArgumentException("get index illegal!");
}
Node temp = dummyHead;
for (int i = 0; i < index; ++i) {
temp = temp.next;
}
Node node = temp.next;
temp.next = temp.next.next;
return node.val;
}2.删除指定值的第一个结点
@Override
public void removeByValue(E element) {
Node temp = dummyHead;
while (temp.next != null) {
if (temp.next.val.equals(element)) {
temp.next = temp.next.next;
size--;
return;
}
temp = temp.next;
}
System.out.println("当前链表中不存在值为:" + element + "的结点");
}3.删除指定值的所有结点
@Override
public void removeAllValue(E element) {
Node temp = dummyHead;
while (temp.next != null) {
if (temp.next.val.equals(element)) {
temp.next = temp.next.next;
size--;
} else {
temp = temp.next;
}
}
}5.链表的其他操作
这里不对其他操作进行描述,因为大致方法和不带头结点的单链表的操作一致
四.不带头结单向点链表的递归实现
1.基本介绍
递归方式主要实现的是插入操作和删除操作,它的结构和不带头结点的单链表的结构一样
2. 链表的插入操作
//在索引值为index处插入val的结点
public void add(int index, int val) {
head = addInternal(head, index, val);
}
private Node addInternal(Node head, int index, int val) {
if (index < 0 || index > size) {
throw new IllegalArgumentException("不合法");
}
//头插
if (index == 0) {
Node node = new Node(val);
node.next = head;
head = node;
size++;
return head;
}
//index不在头结点插入
head.next = addInternal(head.next, index - 1, val);
return head;
}3.递归打印链表结点的值
1.正序打印
//正序打印
public void print(Node head) {
if (head == null) {
System.out.print("NULL");
return;
}
System.out.print(head.val + "->");
print(head.next);
}2.逆序打印
//逆序打印
public void printReverse(Node head) {
if (head == null) {
return;
}
printReverse(head.next);
if (head == this.head) {
System.out.print(head.val + "->NULL");
} else {
System.out.print(head.val + "->");
}
}4.链表的删除操作
1.删除指定值的所有结点
力扣:力扣
public ListNode removeElements(ListNode head, int val) {
if (head == null)
return null;
head.next = removeElements(head.next, val);
return head.val == val ? head.next : head;
}2.删除链表中的重复值(保留)
力扣:力扣
public ListNode deleteDuplicates(ListNode head) {
if (head == null || head.next == null) {
return head;
}
head.next = deleteDuplicates(head.next);
return head.val == head.next.val ? head.next : head;
}3.删除链表中的重复值(不保留)
力扣:力扣
解法一:
public ListNode deleteDuplicates(ListNode head) {
if (head == null || head.next == null) {
return head;
}
if (head.val != head.next.val) {
head.next = deleteDuplicates(head.next);
return head;
} else {
//头结点就是重复的结点
while (head.next != null && head.val == head.next.val) {
head = head.next;
}
head = deleteDuplicates(head.next);
return head;
}
}解法二:
public ListNode deleteDuplicates(ListNode head) {
if(head==null||head.next==null){
return head;
}
if(head.val!=head.next.val){
head.next=deleteDuplicates(head.next);
return head;
}else{
//头结点就是重复的结点
ListNode cur=head.next;
while(cur!=null&&cur.val==head.val){
cur=cur.next;
}
return deleteDuplicates(cur);
}
}5.链表的其他操作
在这里不做细致的介绍
五.不带头结点双向链表的非递归实现
1.不带头结点双向链表的结构
public class DoubleLinkedList<E> implements SeqList<E> {
private class DoubleNode {
E val;
DoubleNode pre;
DoubleNode next;
public DoubleNode(E val) {
this.val = val;
}
public DoubleNode(E val, DoubleNode pre, DoubleNode next) {
this.val = val;
this.pre = pre;
this.next = next;
}
}
private DoubleNode head;
private DoubleNode tail;
private int size = 0;
//尾插法
@Override
public void addLast(E element) {
}
@Override
public void addFirst(E element) {
}
//找到索引为index的位置的结点
private DoubleNode node(int index) {
return null;
}
@Override
public void add(int index, E element) {
}
@Override
public E removeByIndex(int index) {
return null;
}
@Override
public void removeByValue(E element) {
}
@Override
public void removeAllValue(E element) {
}
@Override
public E set(int index, E element) {
return null;
}
@Override
public E get(int index) {
return null;
}
@Override
public boolean contains(E element) {
return false;
}
@Override
public int indexOf(E element) {
return 0;
}
}
2.链表的添加操作(头插法和尾插法)
1.头插法
@Override
public void addFirst(E element) {
DoubleNode node = new DoubleNode(element);
if (tail == null) {
tail = node;
} else {
head.pre = node;
node.next = head;
}
head = node;
size++;
}2.尾插法
//尾插法
@Override
public void addLast(E element) {
DoubleNode node = new DoubleNode(element);
if (head == null) {
head = node;
} else {
tail.next = node;
node.pre = tail;
}
tail = node;
size++;
}3. 链表的插入操作
//找到索引为index的位置的结点
private DoubleNode node(int index) {
DoubleNode result = null;
if (index < (size >> 1)) {
result = head;
for (int i = 0; i < index; ++i) {
result = result.next;
}
} else {
result = tail;
for (int i = size - 1; i > index; --i) {
result = result.pre;
}
}
return result;
}
private boolean rangeCheck(int index) {
if (index < 0 || index > size) {
return false;
}
return true;
}
@Override
public void add(int index, E element) {
if (!rangeCheck(index)) {
throw new IllegalArgumentException("illegal index!!!");
}
if (index == 0) {
addFirst(element);
}
if (index == size) {
addLast(element);
}
DoubleNode pre = node(index - 1);
DoubleNode next = pre.next;
DoubleNode node = new DoubleNode(element, pre, next);
pre.next = node;
next.pre = node;
size++;
}4.链表的删除操作
1.删除指定索引的结点
//在当前链表中删除node结点
private DoubleNode unlink(DoubleNode node) {
DoubleNode pre = node.pre;
DoubleNode next = node.next;
// 先处理左半区域
if (pre == null) {
this.head = next;
} else {
node.pre = null;
pre.next = next;
}
// 在处理右半区域
if (next == null) {
this.tail = pre;
} else {
node.next = null;
next.pre = pre;
}
size--;
return node;
}
@Override
public E removeByIndex(int index) {
if (!rangeCheck(index)) {
throw new IllegalArgumentException("illegal index!!");
}
DoubleNode node = node(index);
return unlink(node).val;
}2.删除指定值的第一个结点
@Override
public void removeByValue(E element) {
DoubleNode node = head;
for (int i = 0; i < size; i++) {
if (node.val.equals(element)) {
unlink(node);
return;
}
node = node.next;
}
}3.删除指定值的所有结点
@Override
public void removeAllValue(E element) {
DoubleNode node = head;
// 因为每次unlink之后都会修改size的值,但是删除所有元素,
// 要把所有链表节点全部遍历一遍
int length = this.size;
for (int i = 0; i < length; i++) {
DoubleNode next = node.next;
if (node.val.equals(element)) {
unlink(node);
}
node = next;
}
}