一、目的
本次实验通过使用request方法爬取目标数据,再使用pandas对数据进行清洗最后输出CSV保存。
二、实验环境
Python 3.7(anaconda3 2020.02)
Pycharm 2020.3.5
三、实验内容
使用requests库获取腾讯疫情数据。可用到的参考代码:
import requests #导入requests
import pandas as pd #导入pandas
import json #导入json
#定义url
url = 'https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=localCityNCOVDataList,diseaseh5Shelf'
#爬取疫情数据
html = requests.get()
#展开数据
data = json.loads(html)['data']
……………………….
………………………..
#清洗数据
data_list = []
for i in data:
data_dic={}
data_dic['省份']=i['name']
data_list.append(data_dic)
#转位Dataframe导出为csv
df = pd.DataFrame(data_list).sort_values(by='当日新增',ascending=False)
df.to_csv('当日疫情数据.csv')
四、实验步骤
1、获取url
点进腾讯疫情网站(接口公开,可以用 request 方法获取数据),进去之后按键盘上的 F12 按键或者鼠标右键-->检查来打开控制台(这里用的是Edge浏览器)
这里我们点击网络,再点击清除(为了待会儿方便查询)
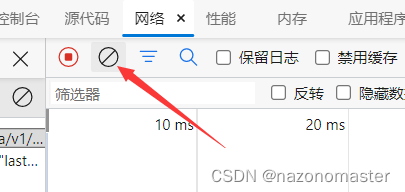
此时刷新网页,点击刚刚清除按钮旁边的查找,这里我们输入重庆二字并搜索,获得以下界面后双击
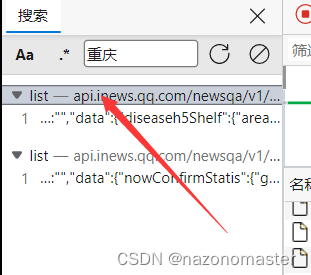

这个时候在右边会返回一些值,我们点击标头->常规->请求URL,右键他,选择复制值。
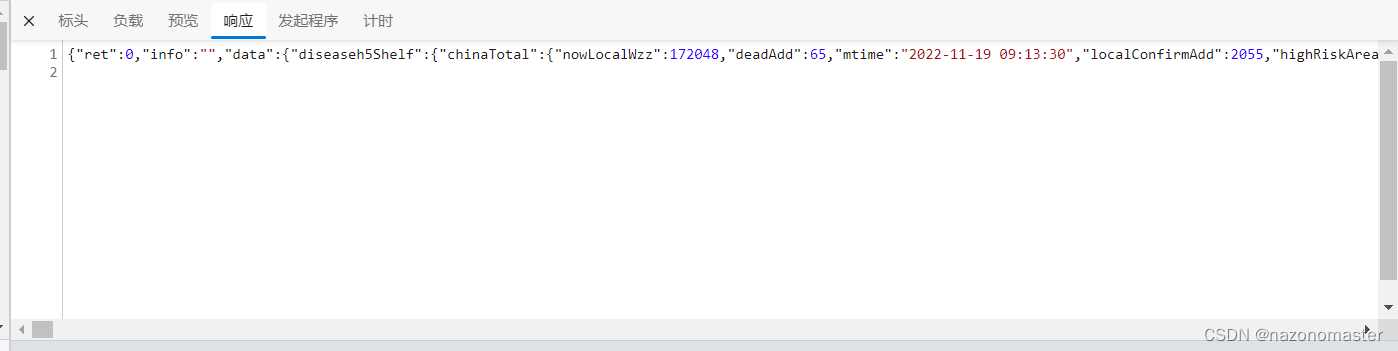
把刚刚复制的 url 在新的网页中打开,注意:我这里用了Edge浏览器的拓展工具“JSON Beauty Formatter”,不然我们新打开的这个网站的代码就会非常杂乱。

至此,我们便获得了我们需要的 url。
2、展开数据
在 url 网页中我们可以看到,我们所要的信息位于 data->diseaseh5Shelf->areaTree 中的第一个子类里面,则我们可以用代码
data = json.loads(html)['data']['diseaseh5Shelf']['areaTree'][0]
而我们所要获取的重庆区县的数据位于刚刚的 data 中的 children 的第6个子类的 children 中。因此我们可以使用代码
cqqx_data = data['children'][5]['children']注意,并不是每次打开都是在同一个位置
至此,我们已经获取了重庆各区县的疫情信息。
3、数据清洗
将 cqqx_data (重庆区县的数据)放进字典,然后在放入 list 中。
data_list = []
for i in cqqx_data:
data_dic = {}
data_dic['区县名称'] = i['name']
data_dic['新增无症状'] = i['today']['wzz_add']
data_dic['新增确诊'] = i['today']['confirm']
data_dic['总确诊人数'] = i['total']['nowConfirm']
data_list.append(data_dic)4、 输出CSV保存
df = pd.DataFrame(data_list)
df.to_csv('重庆疫情数据.csv', encoding='utf-8')
#也可以输出Excel文件保存
#df.to_excel('重庆疫情数据.xlsx', encoding='utf-8')
五、代码实现
# 实验六 使用requests库获取腾讯疫情数据
import requests
import pandas as pd
import json
#获取的腾讯疫情的url
URL = 'https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=localCityNCOVDataList,diseaseh5Shelf'
html = requests.get(URL, verify=False).content
#展开数据
data = json.loads(html)['data']['diseaseh5Shelf']['areaTree'][0] # 0代表第一个
cqqx_data = data['children'][5]['children'] # 5代表第6个
#数据清洗
data_list = []
for i in cqqx_data:
data_dic = {}
data_dic['区县名称'] = i['name']
data_dic['新增无症状'] = i['today']['wzz_add']
data_dic['新增确诊'] = i['today']['confirm']
data_dic['总确诊人数'] = i['total']['nowConfirm']
data_list.append(data_dic)
df = pd.DataFrame(data_list)
df.to_csv('重庆疫情数据.csv', encoding='utf-8') #采用'utf-8'格式编码,避免中文乱码