本文分成两部分,先了解理论,然后再进行实战。

理论篇
1.1 调优目标
JVM调优的两大目标是:
提高应用程序的性能和吞吐量: 通过优化JVM的垃圾回收机制、调整线程池大小和优化代码,可以提高应用程序的性能和吞吐量。
减少JVM的内存占用和垃圾回收的次数: JVM的内存占用和垃圾回收对系统性能有很大影响,因此通过调整JVM的内存参数,可以减少内存占用和垃圾回收的次数,从而提高系统的稳定性和可靠性。
1.2 调优策略
- 避免过度分配最大堆内存,除非明确需要超出默认最大堆限制。应该根据应用程序的性能目标选择适当大小的堆内存,以满足吞吐量需求。
- 如果堆增长到最大限制且仍未达到预期的吞吐量目标,则最大堆限制可能过小。此时可以尝试将最大堆大小设置为接近物理内存总量的值,但不会导致系统出现交换。再次运行应用程序,如果仍未达到吞吐量目标,则应该重新考虑性能目标是否合理。
- 如果应用程序可以达到吞吐量目标,但暂停时间过长,则需要考虑选择合适的最大暂停时间目标。选择较大的暂停时间目标可能会导致无法满足吞吐量需求,因此需要在吞吐量和暂停时间之间做出权衡。
- 当垃圾收集器尝试满足各种性能目标时,堆的大小通常会发生波动。即使应用程序已经达到稳定状态,也是如此。因此,在满足吞吐量目标(需要较大堆)和最大暂停时间/最小内存占用目标(需要较小堆)之间需要进行权衡。
1.3 影响GC的因素
总堆大小
在虚拟机初始化时,堆内存的全部空间都被保留下来。可以通过 -Xmx 选项指定堆的最大大小。如果 -Xms 参数指定的值小于 -Xmx 参数指定的值,那么不是所有保留的空间都会立即提交给虚拟机。这些未提交的空间在图中被称为“虚拟空间”。
需要注意的是,虚拟空间并不等同于已经分配的堆内存。老年代和新生代是堆的两个不同部分,它们都可以根据需要增长到虚拟空间的最大限制。
因此,建议根据应用程序的内存需求和性能指标来调整 -Xms 和 -Xmx 参数的值,以充分利用可用的系统内存并达到更好的性能表现。
一些参数是堆的一个部分与另一个部分的比例。例如,参数 -XX:NewRatio 表示老一代与年轻一代的相对大小。
年轻代
在考虑垃圾收集性能时,除了可用内存之外,影响因素的第二个重要因素是年轻代的比例。
较大的年轻代可以减少 minor gc 的频率,但对于有限的堆大小,它也会导致老年代变小,从而增加 major gc 的频率。因此,在选择年轻代大小时,需要考虑应用程序中对象的生命周期分布。
为了取得最佳性能,建议进行一些基准测试来确定最佳的年轻代大小,以确保 minor gc 的频率不会对性能造成太大影响,并且 major gc 的频率也能保持在一个合理的范围内。
年轻代大小选项
默认情况下,年轻代大小由选项 -XX:NewRatio 控制。
比如设置 -XX:NewRatio=3 表示年轻代和年老代的比例为 1:3。换句话说,eden区和survivor区的总大小将是总堆大小的四分之一。
选项 -XX:NewSize 和 -XX:MaxNewSize 限制了年轻代的大小。将这些设置为相同的值可以固定年轻代,就像将 -Xms 和 -Xmx 设置为相同的值可以固定总堆大小一样。这对于以比 -XX:NewRatio 允许的整数倍更细的粒度调整年轻代很有用。
幸存者空间大小
调整幸存者空间的大小可以使用 -XX:SurvivorRatio 选项,但通常并不会对性能产生重大影响。
如果幸存者空间过小,则可能会导致对象直接溢出到老年代;如果幸存者空间过大,则会浪费内存空间。虚拟机会在每次垃圾回收时选择一个阈值数,以确保幸存者空间保持在一定的填充率。这个阈值数可以通过配置日志 -Xlog:gc,age 来查看。
对于观察应用程序中对象的生命周期分布,显示这个阈值和新生代对象的年龄非常有用。因此,建议进行一些基准测试来确定最佳的幸存者空间大小,以确保在减少对象溢出老年代的同时,也不会浪费过多的内存空间。
选择垃圾收集器
除非应用程序有相当严格的暂停时间要求,否则使用JVM默认的收集器。
- 如果应用程序的主要目标是低延迟和高吞吐量,可以考虑使用并行收集器(Parallel)或CMS收集器。
- 如果应用程序的主要目标是低延迟和对暂停时间敏感,可以考虑使用G1收集器。
- 如果应用程序的主要目标是最小化内存占用,并且可以接受更长的暂停时间,则可以考虑使用串行收集器(Serial)或CMS收集器。
- 如果应用程序的工作负载是长时间运行的,则可能需要考虑使用CMS或G1收集器,以便在垃圾回收期间最小化暂停时间。
- 如果应用程序需要处理大量大型对象,则可以考虑使用G1收集器。
- 如果应用程序的主要目标是实现最高的吞吐量,可以尝试使用ZGC或Shenandoah等新型收集器,这些收集器使用了更先进的算法和技术,可以在更高的吞吐量下保持更短的暂停时间。
1.4 一些推荐参数
- 应将
-Xms与-Xmx设置为同一值,无论扩展还是缩小空间都会进行Full GC。 -Xmx需要根据系统的配置来确定,要给操作系统和JVM本身留下一定的剩余空间。 推荐配置系统或容器里可用内存的 70-80% 最好。-Xmn可以方便指定新生代空间的初始值和最大值。- Xms, -Xmx:在堆大小上放置边界以增加垃圾收集的可预测性。副本服务器中的堆大小受到限制,因此即使 Full GC 也不会触发 SIP 重传。Xms设置起始大小以防止堆扩展引起的暂停。
- XX:+UseG1GC:使用垃圾优先 (G1) 收集器。
- XX:MaxGCPauseMillis:设置最大 GC 暂停时间的目标。这是一个软目标,JVM 将尽最大努力实现它。
- XX:ParallelGCThreads:设置垃圾收集器并行阶段使用的线程数。默认值因运行 JVM 的平台而异。
- XX:ConcGCThreads:并发垃圾收集器将使用的线程数。默认值因运行 JVM 的平台而异。
- XX:InitiatingHeapOccupancyPercent:启动并发 GC 周期的(整个)堆占用百分比。基于整个堆的占用率而不只是其中一代(包括 G1)的占用率触发并发 GC 周期的 GC 使用此选项。值 0 表示“执行恒定的 GC 循环”。默认值为 45。
- -XX:+InitiatingHeapOccupancyPercent(简称 IHOP):G1 内部并行回收循环启动的阈值,默认为 Java Heap 的 45%。这个可以理解为老年代使用大于等于 45% 的时候,JVM 会启动垃圾回收。这个值非常重要,它决定了在什么时间启动老年代的并行回收。
- -XX:MaxGCPauseMills:预期 G1 每次执行 GC 操作的暂停时间,单位是毫秒,默认值是 200 毫秒,G1 会尽量保证控制在这个范围内。
- -XX:G1NewSizePercent (默认:5) Young region 最小值 -XX:G1MaxNewSizePercent (默认: 60) Young region 最大值
○ 正常来说,大部分在 Young 的对象都不会存活很长时间。如果不符合这个规则 (大部分在 Young 的对象都不会存活很长时间),你可能需要调整一下 Young 区域占比。来降低 Young 对象的拷贝时间。
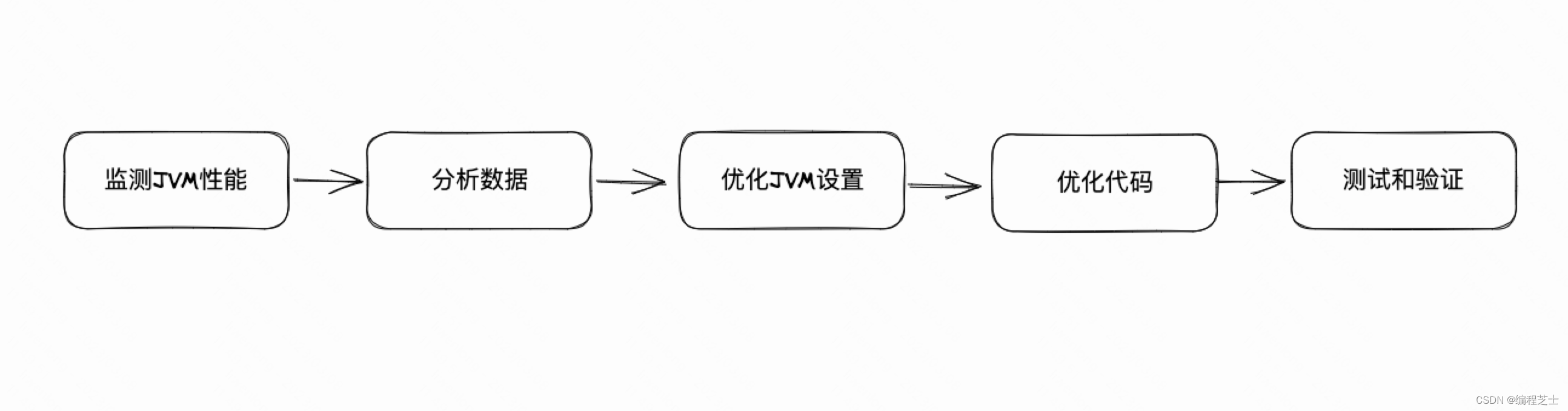
1.5 JVM调优步骤
-
监测JVM性能:使用工具,如JConsole、VisualVM或Java Mission Control来监测JVM的性能,包括内存使用、垃圾收集频率和时间、线程使用等指标。
-
分析数据:收集JVM性能数据后,需要进行分析,识别性能瓶颈和潜在的问题,例如频繁的Full GC或长时间的暂停。
-
优化JVM设置:根据性能数据分析结果和应用程序的特性,可以调整JVM设置来优化性能。例如,增加内存大小、调整垃圾收集器、优化线程数等。
-
优化应用程序代码:除了调整JVM设置,还可以通过优化应用程序代码来提高性能。例如,减少对象的创建、缓存数据、避免使用同步等。
-
测试和验证:进行JVM调优后,需要进行测试和验证,确保调优的结果能够满足性能需求,并且不会引入新的问题或风险。
-
监控和维护:在应用程序运行期间,需要继续监控JVM性能,以便及时发现和解决问题,并进行维护,例如定期清理日志文件、备份数据等。
实战篇
2.1 发现问题
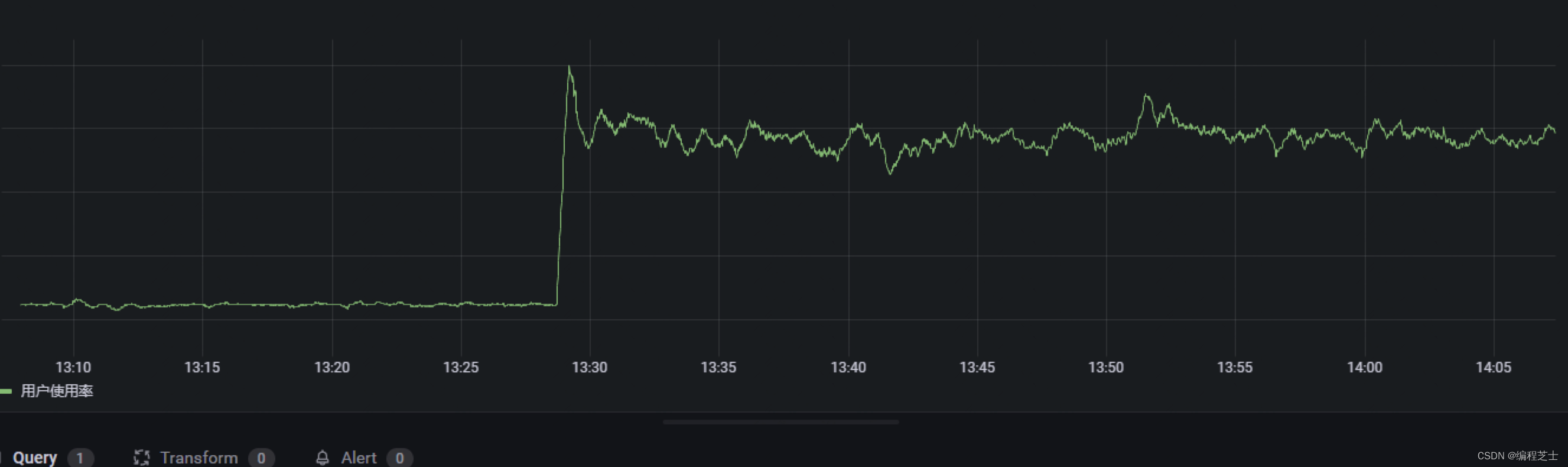
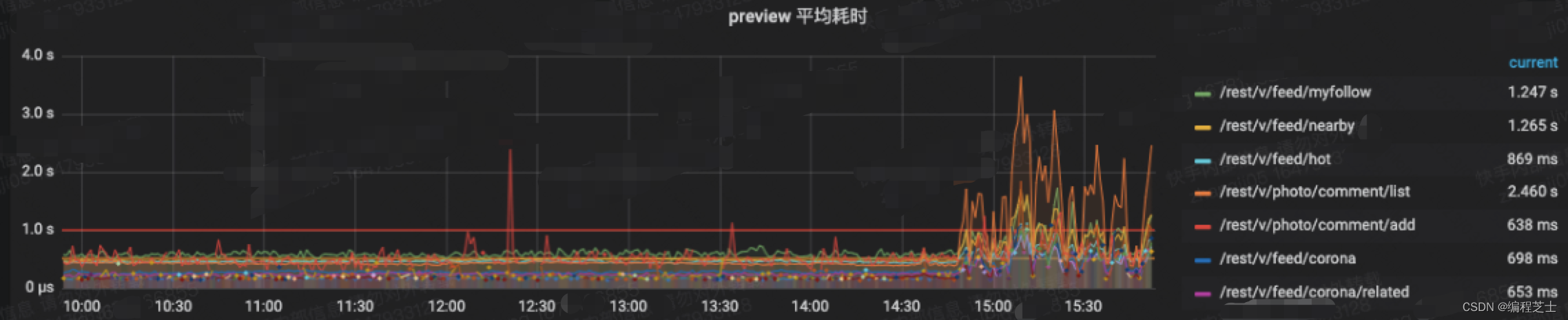
在某一天线上服务的grafna监控突然发出告警,显示服务器的CPU负载产生了异常上升,服务的接口耗时也开始突增,针对这种情况,立刻开始了排查。
2.2 定位问题
查看火焰图
火焰图如何解读可以参考:性能分析利器:火焰图。查看了CPU的火焰图看了一下,发现GC相关的函数占了一半的CPU调用,然后查看了JVM的监控,发现实例出现了频繁的Full GC,此时基本上可以确定是GC导致的问题。

重新部署了一遍,发现还是有问题,说明很可能和代码应该有关系,和部署的机器关系不大。接下来开始定位JVM的具体问题并进行优化。
分析GC日志
在JVM启动的时候添加以下参数,就可以将GC日志打印出来:
-XX:+PrintGCDetails 打印GC日志细节
-XX:+PrintGCTimeStamps 打印GC日志时间
-Xloggc:gc.log 将GC日志输出到指定的磁盘文件上去,这里会把gc.log输出到项目根路径
其中一个日志内容如下:
2022-05-17T11:35:04.163+0800: [GC pause (G1 Evacuation Pause) (young) (to-space exhausted), 1.46786732 secs]
[Parallel Time: 1205.9 ms, GC Workers: 20]
[GC Worker Start (ms): Min: 5038821026.8, Avg: 5038821026.9, Max: 5038821027.0, Diff: 0.2]
[Ext Root Scanning (ms): Min: 0.7, Avg: 1.0, Max: 2.6, Diff: 1.8, Sum: 13.6]
[Update RS (ms): Min: 12.4, Avg: 13.8, Max: 14.7, Diff: 2.3, Sum: 179.6]
[Processed Buffers: Min: 71, Avg: 87.8, Max: 106, Diff: 35, Sum: 1141]
[Scan RS (ms): Min: 0.0, Avg: 0.2, Max: 0.3, Diff: 0.3, Sum: 2.8]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Object Copy (ms): Min: 1094.0, Avg: 1094.5, Max: 1094.7, Diff: 0.7, Sum: 22728.8]
[Termination (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 1.5]
[Termination Attempts: Min: 1, Avg: 1.1, Max: 2, Diff: 1, Sum: 14]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.3]
[GC Worker Total (ms): Min: 609.6, Avg: 609.7, Max: 609.9, Diff: 0.2, Sum: 7926.6]
[GC Worker End (ms): Min: 5038821636.6, Avg: 5038821636.6, Max: 5038821636.6, Diff: 0.1]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.4 ms]
[Other: 320.7 ms]
[Evacuation Failure: 315.7 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.5 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.5 ms]
[Humongous Register: 0.1 ms]
[Humongous Reclaim: 3.5 ms]
[Free CSet: 0.6 ms]
[Eden: 2176.0M(2360.0M)->0.0B(1920.0M) Survivors: 96.0M->0.0B Heap: 3764.9M(4096.0M)->1750.9M(4096.0M)]
[Times: user=6.67 sys=2.00, real=1.53 secs]
另一个日志内容:

通过观察GC日志,发现了两个异常GC的场景,但是这两种场景都出现了to space exhausted的问题。打开谷歌查询了一下具体含义:
- 第一张图显示是因为大对象分配提前触发了young gc
- 另一次是因为eden区中的对象,在一次young gc后存活的对象,因为升级到Survivor区空间不够,进而升级到old区空间也不够而触发的
因此可以初步得出结论:服务的GC出现了问题,具体是因为出现了大量的大对象的分配造成的。在服务中新建了大量的大对象被分配到老年区,导致了老年区空间过度碎片化,而且老年区的垃圾回收只发生在mix gc和full gc,而当触发了young gc的时候,eden区存活下来的对象,升级到old区又没有足够空间用来存放,从而导致 to space exhausted。(补充说明:G1中,新创建的大对象,是直接分配到old区的,不会分配在eden区中)
堆栈分析
现在以及基本能够确认是由于大对象引起的GC问题,导致JVM频繁的被触发FULL GC。接下来需要通过heap dump来确认这个大对象到底是个什么玩意。
使用命令行来下载服务的堆栈dump信息:
jmap -dump:format=b,file=[文件名].hprof [pid]
- [pid]:是指你要分析的服务进程id
- [文件名]:就是dump下来的堆栈文件的名字
- 举个例子:jmap -dump:format=b,file=test1234.hprof 14123
- 可以添加’live’,来只dump存活数据 -> jmap -dump:live,format=b,file=[文件名].hprof [pid]
- 注意在生产环境执行jmap的时候,选择低峰期执行,jmap的时候,会导致你所有的应用暂时停止,停止的时间随着你当前内存越大,而时间越长,一般都是几s-几十s的影响

上图以类的维度做的统计(就是这个类在当前内存中创建的对象占用空间大小),我发现perf打点的这个类,在本服务当前内存中占比最高,且它在之前的图里确实显示产生了大对象,所以现在它成了重大嫌疑犯。
但是嫌疑犯,归嫌疑犯,毕竟没有确凿证据,且因为别的组的服务也引入的perf打点,但是他们的服务确没有问题,所以我没信心说它就是凶手。反而我更加怀疑是我heap dump的时机不对,在我dump堆栈的时候,大对象真凶是不是已经被回收了。(非OOM自动dump,所以自己主动dump的时候,可能出现dump的时机不好,导致找不到原因)
当前服务打印出的gc日志,已经不能够给我提供更多的信息了,于是我想到打印出更多的gc日志,来观察现象。新增启动参数“-XX:+PrintAdaptiveSizePolicy”。
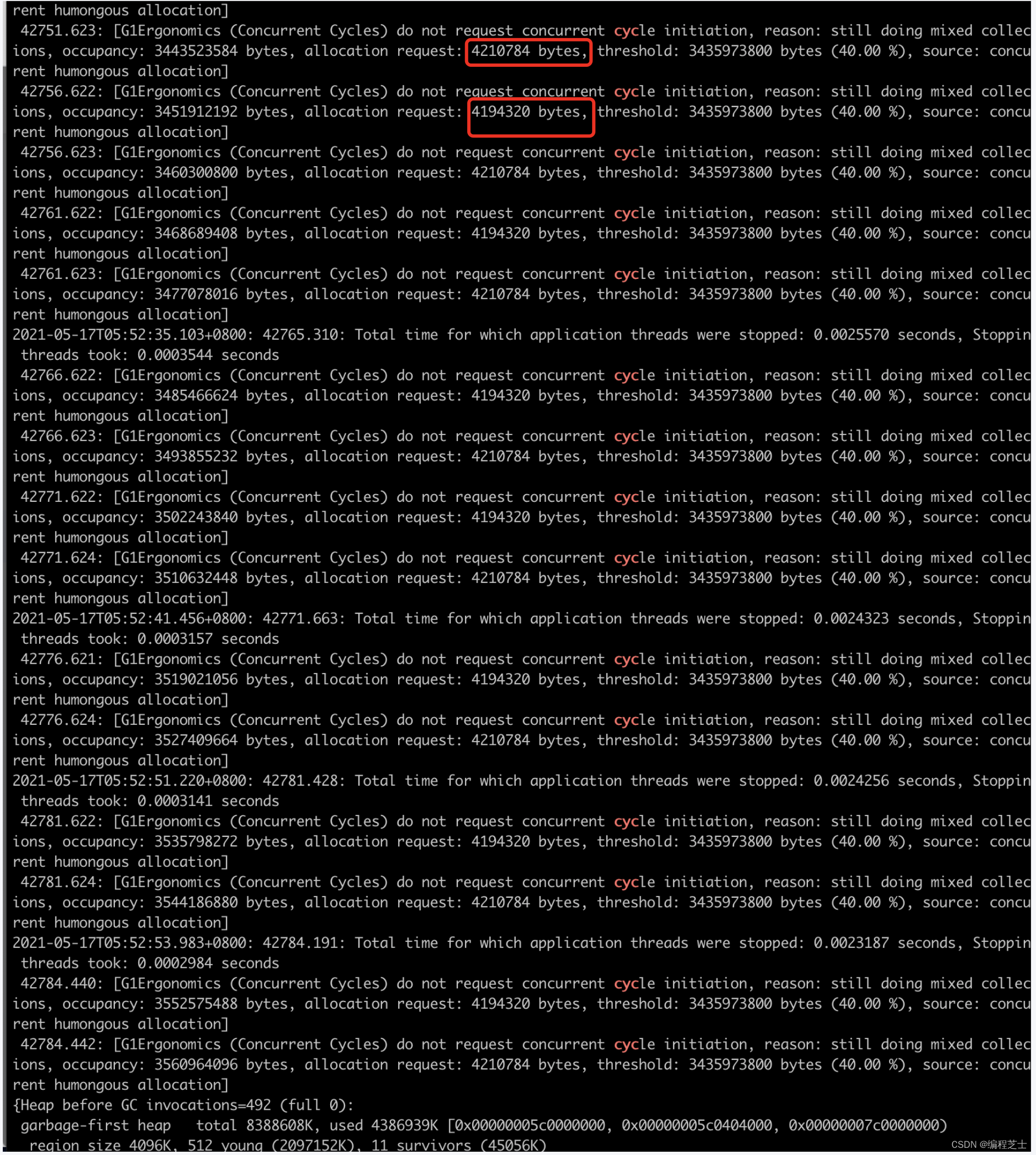
发现大量的concurrent Cycles阶段的原因是:humongous allocation,且发现申请的大对象size 都是4210784byte,和4194329byte,并且每5s就会发生一次这样的大对象分配。到这里,可以肯定造成本次gc问题的,大对象凶手有两个,且都是同时期先后分配的。
解决方案
per团队修改代码:从原来每一次聚合perf打点信息,都新创建一次对象 -> 每一次聚合perf打点信息复用同一个对象(就是首次使用创建一次对象,后面再用一直复用这个空间)
同时临时修改jvm参数,试图解决问题。
调整前的关键jvm参数:Xmx8G -Xms4G -XX:InitiatingHeapOccupancyPercent=50
调整后的关键jvm参数:Xmx8G -Xms8G -XX:InitiatingHeapOccupancyPercent=40 -XX:+UnlockExperimentalVMOptions -XX:G1MaxNewSizePercent=25
Xmx8G -Xms4G -> Xmx8G -Xms8G :锁死内存,不允许内存波动,减少消耗资源。
-XX:InitiatingHeapOccupancyPercent=50 -> 40 : 提前触发并发gc周期
新增-XX:+UnlockExperimentalVMOptions -XX:G1MaxNewSizePercent=25:限制新生区的大小上限不超过内存的25%,这样能尽量保证old区有足够的空间来存储每次young gc后存活的对象。
结论
无论是gc次数,还是gc时间,都很明显得到了极大改善。