文章目录
前言
今天是2023.2.5 在这里先祝各位元宵节快乐,那么今天的话主要是来分析论证一下关于WhiteHole社区的推荐算法的一个解决方案。在这里感谢各位对WhiteHole的支持,虽然到现在差不多一个礼拜,WhiteHole测试版本的用户仅突破4人,但是这依然是不错的成绩。虽然没啥用户,但是该有的东西,一定是需要有的,当然关于推荐系统的解决方案,其实在WhiteHole立项之初就已经考虑到了,只是存在一定的局限性,当前更加适合WhiteHole的解决方案更加倾向于NLP。
设计理念
那么在开始之前,我需要阐述一下,关于WhiteHole交流社区的设计理念,为什么要说这个,因为这里存在一个遗留问题。什么问题呢,那就是在设计之初,我的想法其实就是打造一个不仅仅面向技术交流的社区,例如CSDN,掘金,思否这种,而是偏向知乎这种,更加多元化的一个社区。因此对于文章的一些内容,其实是没有,也做不到一个标签,因为内容具备多元化,它有别于类似购物商场的模式,商品必然是有标签属性的,但是对于这种内容来说,大体上虽然是有的,但是你要细分就很难。因此这就意味者,我们的内容压根就没有人为设置标签。
但是问题来了,如果没有设置标签的话,那么如何做到用户的分类,提供不同的内容呢。这里的话就涉及到另一个理念了,那就是去中心,或者减少中心控制。换一句话说,提供更大的权限给到用户。一开始我的想法其实是想说,搞一个类似于数字藏品的一个社区,凭什么只有“图像,音乐”这种类型的东西算艺术,可以被交易,我觉得知识,想法也是可以被交易的。但是遗憾的有些东西你不能只考虑到技术问题,尤其是作为一个用户产品,至于什么问题,这个懂得都懂。因此我就想到基于社区为最小单位,用户可以加入别人创建的社区,也可以自己创建社区,创建者对于社区具备管理权限,可以对内容进行审核,移除(删除权限仅所有者具备)。同时对于博文,读者可以通过fork来参与到博文的修改。同时为了增加交流特性,加入了问答模块
那么这个你也发现了WhiteHole更像是一个平台,一个平台里面包含了众多由用户自己创建的社区,同时这也实现了用户的细分化。
因此这就导致了一个问题,我们很难直接通过标签来做。当然这个标签只是用户主动输入的标签,实际上我们通过关键词提取也是可以作为标签的。那么起初我就是这样想的。
原始方案
那么这里的话,就不得不聊一聊我们原来的方案了,随便说一下咱们这个社区开发的进度,当初承诺的很多功能确实还在开发,当前完成度大概是70%左右,当然还有很多优化啥的。算法部分两个部分,一个当然就是咱们的这个推荐算法,另一个自然就是网页智能助手,那么关于这个助手的话,最终的话,还是选择这个GPT2,当然关于这个可以在这里体验一下:https://gitee.com/Huterox/gpt-play。是的我一开始是打算还是自己在transformer上面然后基于公开数据集做点工作,但是咋说呢,工作量挺大的,没有那么多时间进行验证,实验,测试,当然如果成功了,水一篇论文应该没事问题。
这里再给一下我们这个社区的一个基本架构图吧:
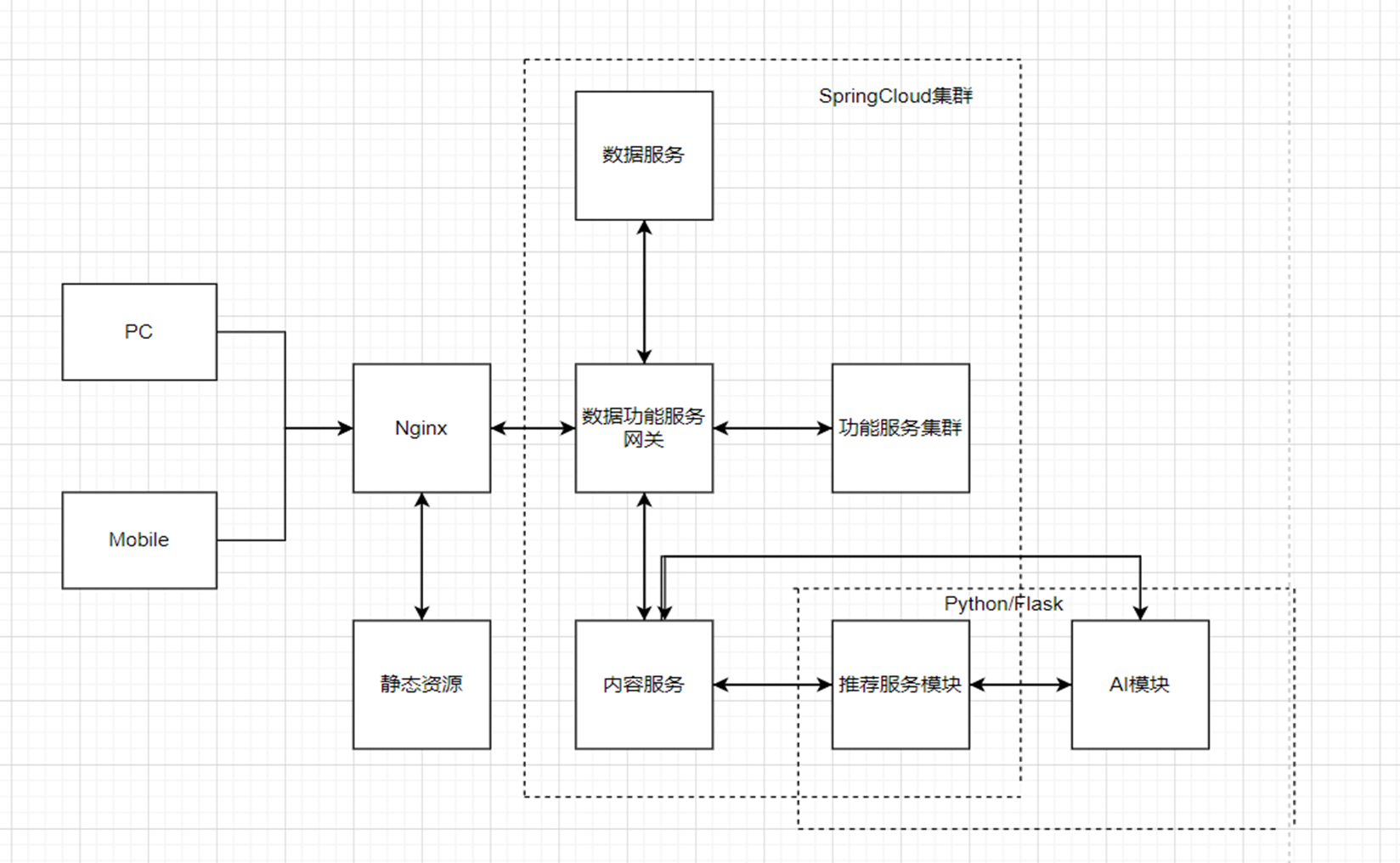
(这里的话,flask–>fastapi)
那么原始方案的话,其实就是依赖ES,来做的。大概的架构图如下:
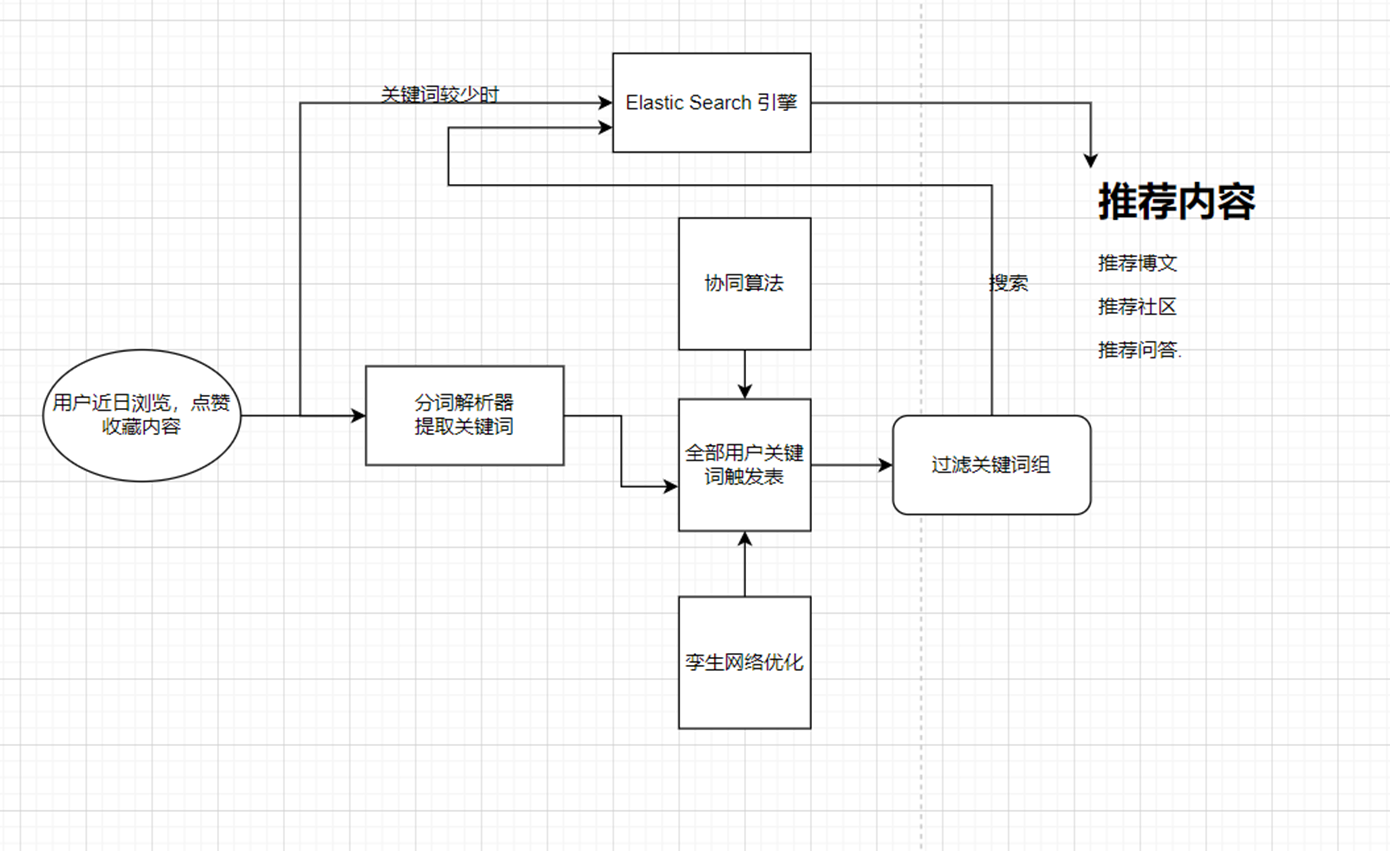
这块的话,没错就是我们通过用户的行为,然后呢,我们提取推荐特征词,然后到我们的ES当中去找到对应的一些内容,同时我们可以再对这些内容进行一个处理过滤排序。
那么这个时候,可能有好奇宝宝来问了,直接提取这些文章的关键词不就完了,然后到ES当中去检索不就好了。首先这样干当然是木有问题的,但是,假设,你的抖音天天给你推荐小姐姐,你会不会刷吐?特别同学除外。所以的话,我们的推荐系统必须能够做到“通人性”。什么意思,我知道你喜欢刷小姐姐,然后我发现喜欢刷小姐姐的其他同学还比较喜欢刷小妹妹,所以为了防止用户刷小姐姐刷腻了,我们这边还应该再推荐一下小妹妹,如果根据用户的行为发现不太细化小妹妹,那么我们下次就把小妹妹给屏蔽了。所以说啥,为什么我们这边还有一个协同算法,我们得到的词叫做推荐特征词,反正我这里是这样叫的。
流程
OK,我们来看一下大概的流程:
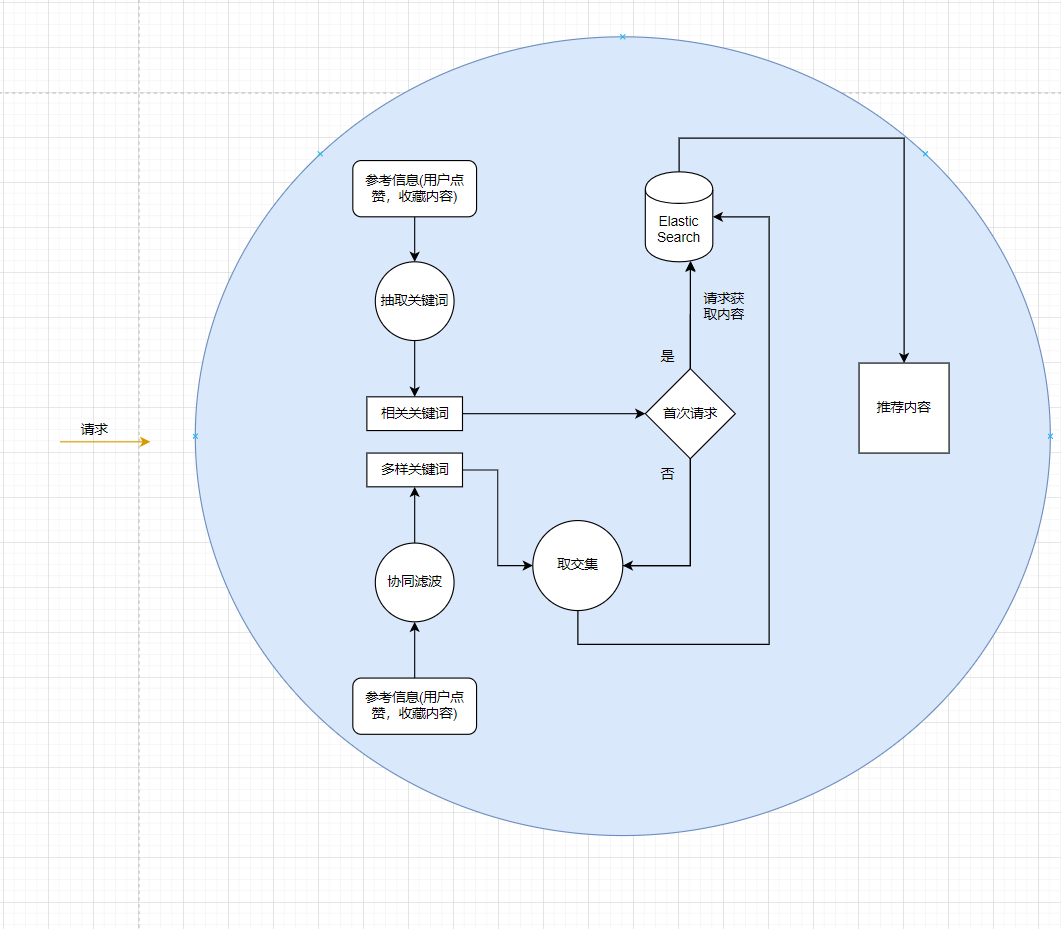
那么在实际的使用过程中,通过对用户的行为判断,来决定,是相关关键词的权重更大还是多样性关键词的权重更大。例如我们很多软件都有一个换一批和更多这样的功能,如果用户选择更多,那么显然是希望得到更多同类的一些内容,也就是相关关键词的权重要大一点,那么反之多样性关键词权重大一点。
问题
这个方案看起来还是挺好的,充分考虑到用户的需求。但是问题在于啥呢,首先提取关键词,这个肯定是没啥问题的,这个超级简单。那么问题就在于协同滤波,那么协同滤波的难点在于哪里呢?首先排除算法的实现,协同滤波说白了就是做用户之间的相关度分析,然后做一个评价,也就是排序。
那么问题在哪呢,User!User!User!首先我们需要足够多的用户来做支撑,这一点是非常重要的,当然前期我们可以说只是根据几个用户来做推荐,因为此时社区内的内容就不多嘛,内容数量与用户必然是成正相关的。之后是啥呢,就是咱们的这个这个协同滤波需要维护的是一个表,但是咱们的这个网站是没有标签的,如果我们通过文章内容的一些关键词来做标签的话,那么问题就是这个尺度不好掌握,然后就是关于这个表需要进行更新。
最后就是评价的问题,看上面的那个大致的图,你也发现了这里有个孪生网络,那么这个是干啥的,当然就是为了进行再评价优化呗。通过一个神经网络来代替遍历计算,那么对于这个推荐系统来说,实时性也是比较重要的,如果需要消耗的资源过多的话,那么你懂的,而且这种服务必然是对所有用户提供的。后面用户多了,内容多了,这个就更麻烦了。
Feature-aware Diversified Re-ranking with Disentangled
其实让我真正想到说好像可以解决这个问题的方案,其实是来源于这篇论文:
Feature-aware Diversified Re-ranking with Disentangled
在于计算相关性和多样性时引入了特征维度的信息,由于在推荐系统中,item通常具有大量丰富的side information特征 ,虽然可以从不同维度来表征item,这些特征通常是相关的或冗余的。因此论文中提出了一种解耦注意力编码器(DAE)来将这些特征进行解耦,学习item的分离表征 ,该模块是FDSB方法中进行相关性和多样性建模的基础。 DAE 的整体架构如图:
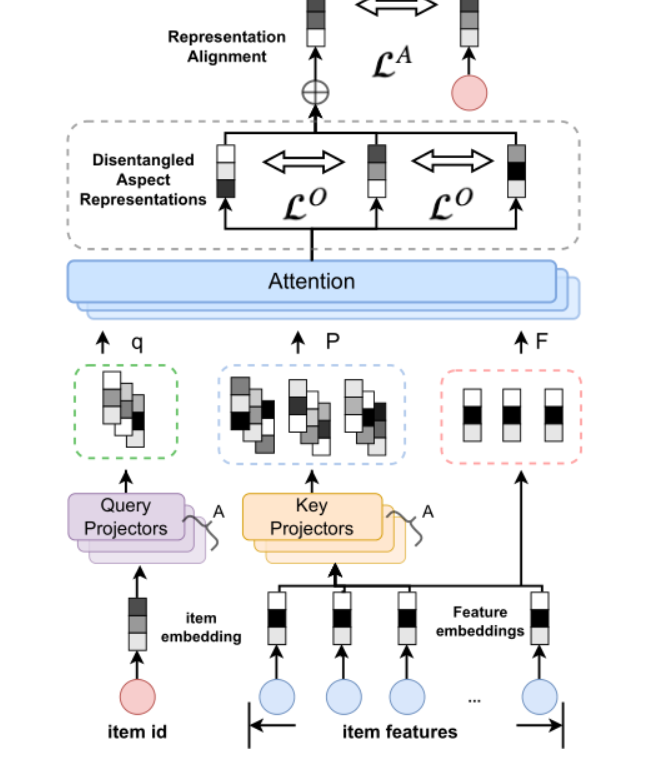
由于物品的特征信息可以从不同潜在方面描述该物品的特性,基于解耦的思想,将这些特征,根据所描述物品的不同方面分解为不同的表示。我们将称之为对应于物品不同方面的细粒度特征感知表示,后统称为分离表征。
为了学习分离表征,论文采用一种基于多头自注意力机制的方法DAE。具体地,以物品原始特征作为value,以物品embedding与特征的投影向量作为query和key来计算注意力分数,具体公式为:

(诶这个好像有点眼熟呀~)
以物品原始特征作为value,以物品embedding与特征的投影向量作为query和key来计算注意力分数。
由于物品的相关性和多样性本质上是相互矛盾的(这也是为什么一开始我就直接设计两套系统的原因),即多样性更强时,相关性就更弱。然而我们的相关推荐既要保证所推荐的物品与触发物品之间的相关性,又要保证一定的多样性。因此当多样性表现得更强时,我们应该提高相关性的权重,反之亦然,从而实现二者的平衡。
论文中认为学到的item表征应该更接近item id的embdding。因此论文中设计了两个alignment loss用来对齐item id的embdding和特征分离表征这两部分信息,loss的定义如公式:
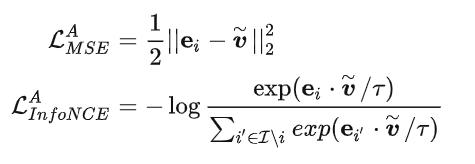
此外又引入了一个orthogonalization loss。我们的目的很简单,输入一组特征,得到一组新的特征,在新的特征里面具备多样性(人话:输入用户最近的一些点赞啥的,得到推荐,这些推荐关键词具备多样性和相关性,二者之间需要进行平衡)
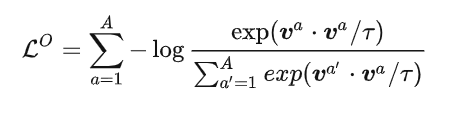
其中 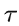 是温度参数,
是温度参数, 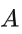 是分离表征的维度。通过联合优化以上两部分,可以有效地将丰富的特征信息抽象成高层的特征表示。
是分离表征的维度。通过联合优化以上两部分,可以有效地将丰富的特征信息抽象成高层的特征表示。
之后的话就是如何选择排序的问题了,不过在我们当前的设计方案当中,选择排序交给了ES,因此我们要做的只是提取出需要输入推荐特征词
Transformer方案
那么在我们的WhiteHole当前,其实就是受到了这篇论文的启发,尤其是在损失函数上面,这对于我来说是非常理想的函数。
那么在套路这个方案是否可行之前,我们先来说说为什么我们在使用协同滤波的时候可以保证到多样性,也就是得到多样关键词。举一个非常形象的例子就是:假设A用户提取出的关键词时“小姐姐”,(A用户在想当长一段时间内只刷了小姐姐内容,八头牛都拉不回来的那种),那么通过协同滤波,我们发现到喜欢刷“小姐姐”的用户其实也非常喜欢刷“小妹妹”,所以我们认为这个用户A可能也会喜欢“小妹妹”的,所以给他推荐这个。这个过程我们始终坚持了一句话:“群众的眼光是雪亮的”。那么问题来了,为什么是“雪亮”的,为什么喜欢刷“小姐姐”的用户还会喜欢刷“小妹妹”,不是“小哥哥”,“小狗狗”,“小蓉蓉”,“小飞飞”,“小酸酸”,“帅侯侯”。显然是因为他们之间存在一定的关系,但是这种关系是什么?我们不知道,但是我们可以通过用户们的反应知道,比如你看到小姐姐的时候,我不知道你在想什么,但是你在疯狂点赞,那么我就知道,你喜欢这种东西。
那么本质就是通过用户去发现物品A和B之间存在某种程度上的关系,导致类似的用户可以接受到物品B,那么什么样的用户呢?喜欢A的这种用户。
所以当我们采用协同滤波的时候,其实就是相当于让用户们去探索,利用用户自己去代替很复杂的算法找打A,B之间的关系,约束条件是用户们喜欢A的情况下。
那么这样一来我们直接去找到,或者表述这种关系不就好了,然后,You Only Recommend Once–>YORO 算法诞生(狗头)
本质表示
那么在这里,我们刚刚分析了一下可行性。那么如果你对自然语言稍微熟悉一点,我想应该就很容易发现,一个东西,每次就是Embedding。
我们要做的,其实就是,找到一种词空间,这种词空间可以表示出来,在用户喜欢A的情况下,可以发现B和A很近,可以认为到A,B是在这个空间内是相似的东西。
那么这个我认为其实也是协同滤波的原理之一,只不过,前者显然似乎是通过“社会工程学”来进行的,后者是通过计算机+算法近似求解的。
大致思路
那么现在的话,可以说说大致是如何做了,同样的,我们需要采用的注意力机制,不过在这里咱们直接采用到Transformer当中的多头注意力机制,是的在这里可能有有点区别,但是损失函数是一致的,只是输入的QKV将不同。
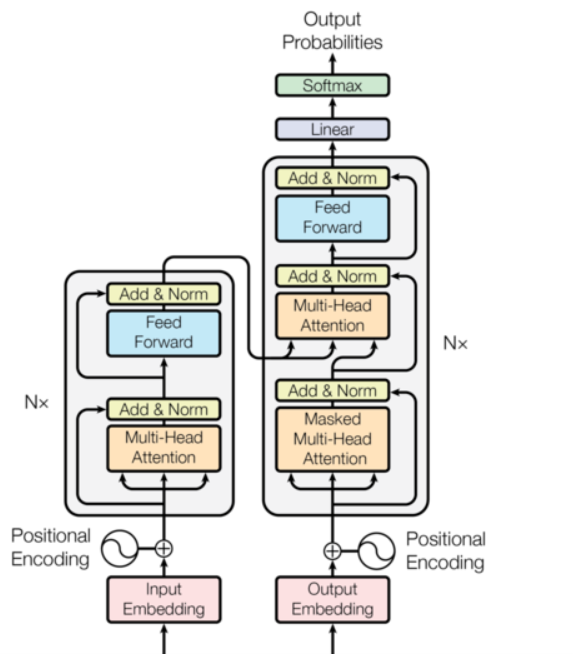
为什么使用Transfomer,其实很简单,我们的系统需要的不是特征向量,而是特征推荐词,类似于Seq2Seq的一个任务。只是这个比较特殊,包括最后直接由网络输出的是否是一组词语都不是很重要,因为还会做处理。
那么在这里的话,Q=V=提取内容,K=关键词。
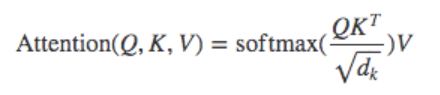
之后在损失函数上,与 Feature-aware Diversified Re-ranking with Disentangled 类似。也是使用到那里的先验信息。
学到的item表征应该更接近item id的embdding。在这里是inputEm与outEm
之后是orthogonalization loss,得到的关键词和提取到的关键词之间的一个平衡。
总结
这个目前还只是一个想法,后面还会不断优化,当然会尽快去上线,实在不行,在搞一个测试版呗(狗头),
项目体验地址:http://47.100.239.95,不删档测试~