逆向主题:解析出网址里视频下的m3u8链接。
(注:文章所涉及内容只做学习参考交流,不做除此之外的任何其它用途!!!)
新手入门级
参考B站视频系列教程: https://www.bilibili.com/video/BV1yW4y1E7Ug
主打的就是一个白嫖。
使用Base64加密!!!
接口1(逆向m3u8接口):aHR0cHM6Ly9pbTE5MDcudG9wLz9qeD1odHRwczovL3d3dy5iaWxpYmlsaS5jb20vYmFuZ3VtaS9wbGF5L2VwMzI5MTQz
接口2(推荐,我经常使用,m3u8接口无加密):aHR0cHM6Ly9qeC5wbGF5ZXJqeS5jb20vP3VybD1odHRwczovL3d3dy5iaWxpYmlsaS5jb20vYmFuZ3VtaS9wbGF5L2VwMzI5MTQz
**xxx.脱敏.xxx,自己去构建url,headers。**
逆向z参数
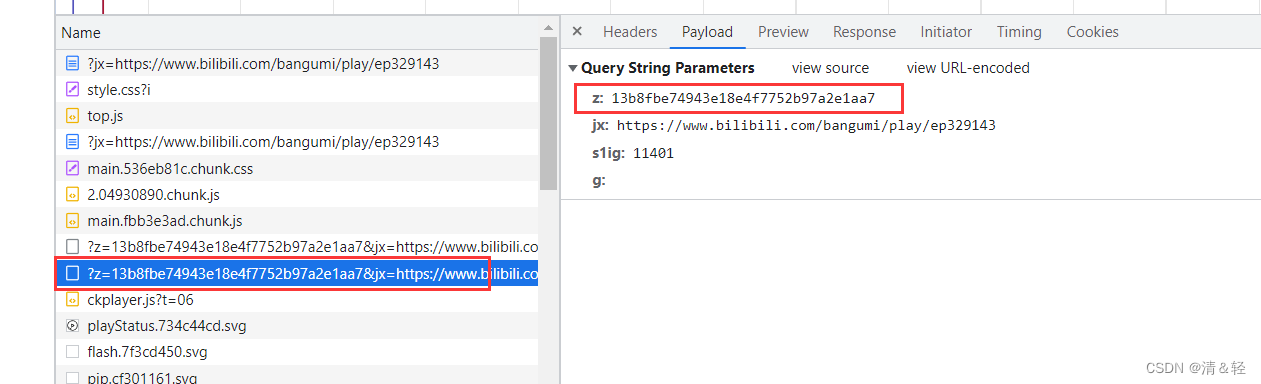
首先,进去之后直接F12打开抓包工具,Never pause here过掉debugger。
Ctrl+R刷新一下,找到如上图的包,然后如下图所示,直接跟进去。

Ctrl+F搜索关键字s1ig(注意:不要搜索z参数),定位到关键字发现框中这一块都是和进行请求携带的参数相关,所以在这里开始进一步调试。
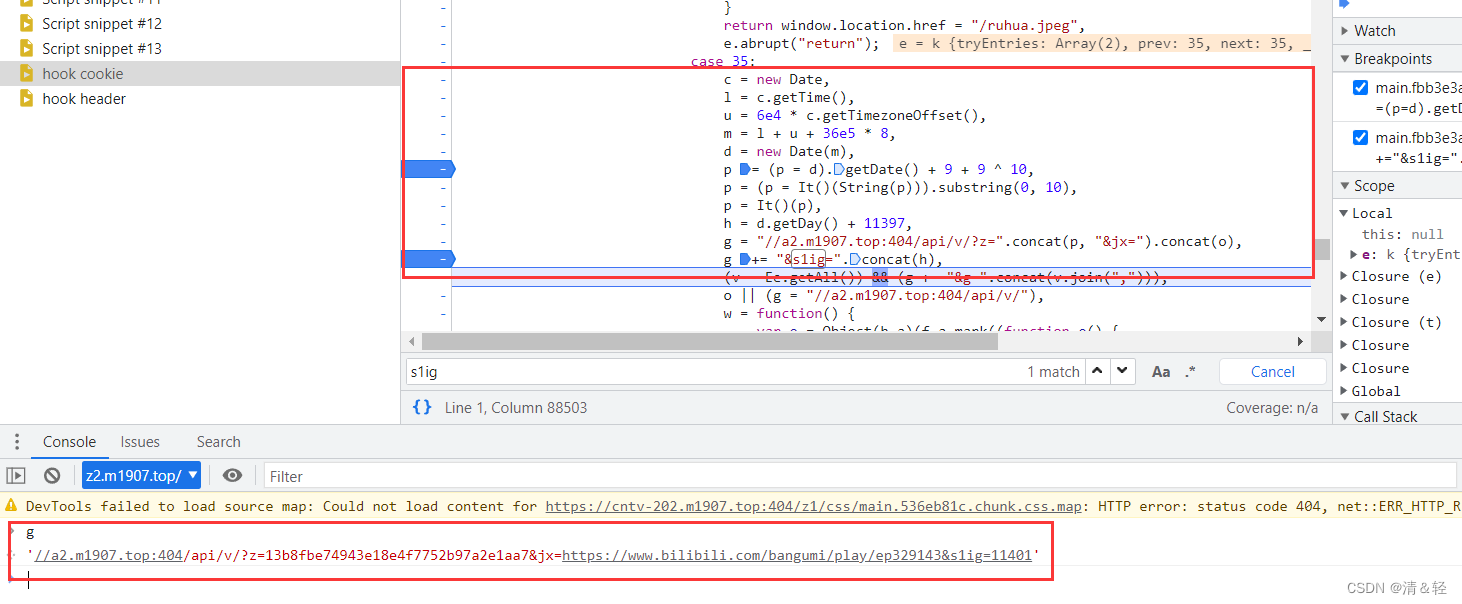
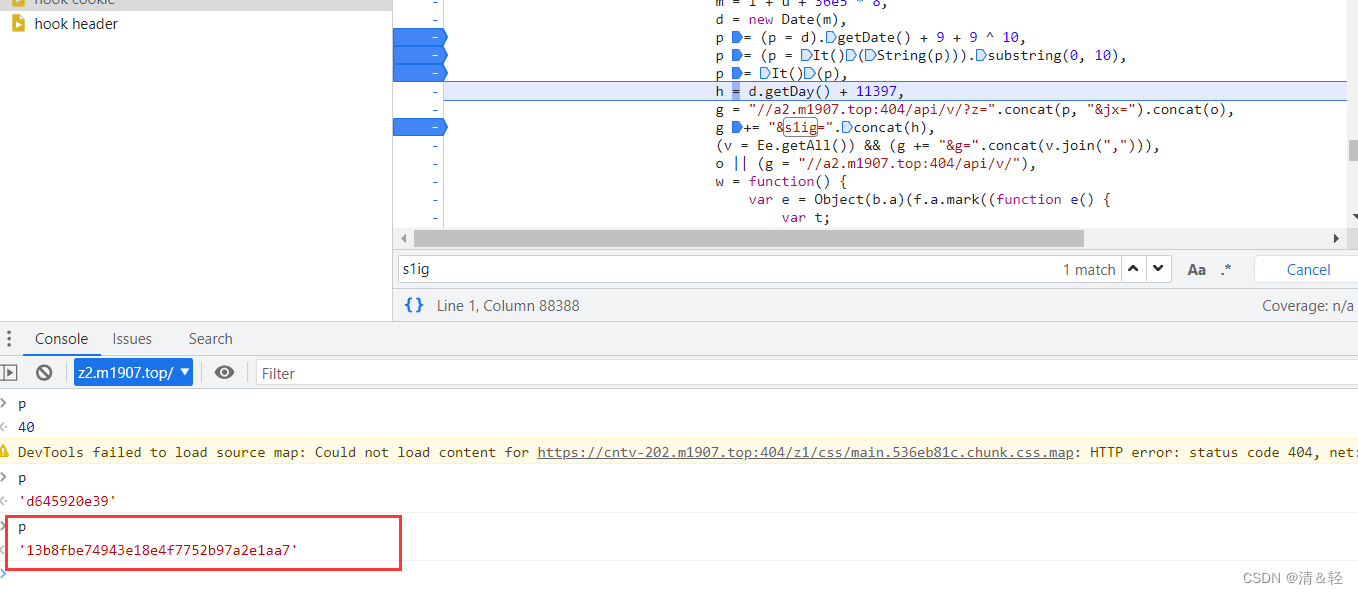
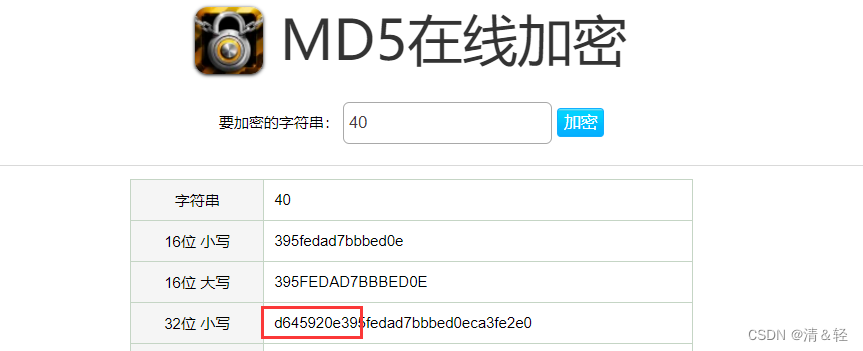
一步一步调试发现(或者直接从结果看(经验)去百度上搜索 在线md5加密 进行对比),就是用md5进行加密的,里面的It()方法就是调用md5方式加密,所以这个加密参数z就ok了,o 就是解析视频的url。后面的g就是字符串拼接操作。
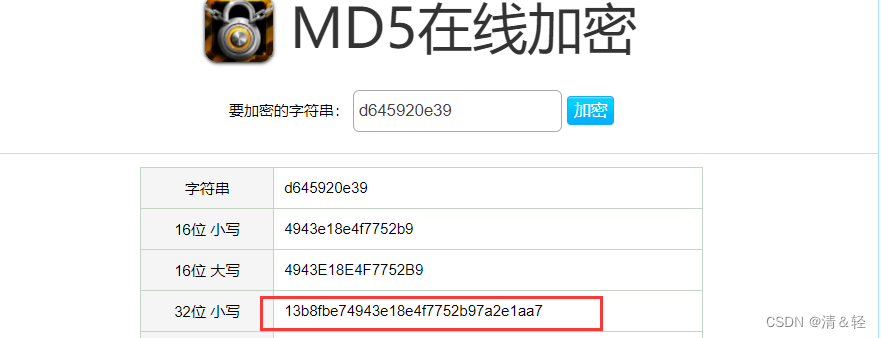
js实现
js md5加密算法直接网上去找。
function md5(md5str) {
var createMD5String = function(string) {
var x = Array()
var k, AA, BB, CC, DD, a, b, c, d
var S11 = 7,
S12 = 12,
S13 = 17,
S14 = 22
var S21 = 5,
S22 = 9,
S23 = 14,
S24 = 20
var S31 = 4,
S32 = 11,
S33 = 16,
S34 = 23
var S41 = 6,
S42 = 10,
S43 = 15,
S44 = 21
string = uTF8Encode(string)
x = convertToWordArray(string)
a = 0x67452301
b = 0xEFCDAB89
c = 0x98BADCFE
d = 0x10325476
for (k = 0; k < x.length; k += 16) {
AA = a
BB = b
CC = c
DD = d
a = FF(a, b, c, d, x[k + 0], S11, 0xD76AA478)
d = FF(d, a, b, c, x[k + 1], S12, 0xE8C7B756)
c = FF(c, d, a, b, x[k + 2], S13, 0x242070DB)
b = FF(b, c, d, a, x[k + 3], S14, 0xC1BDCEEE)
a = FF(a, b, c, d, x[k + 4], S11, 0xF57C0FAF)
d = FF(d, a, b, c, x[k + 5], S12, 0x4787C62A)
c = FF(c, d, a, b, x[k + 6], S13, 0xA8304613)
b = FF(b, c, d, a, x[k + 7], S14, 0xFD469501)
a = FF(a, b, c, d, x[k + 8], S11, 0x698098D8)
d = FF(d, a, b, c, x[k + 9], S12, 0x8B44F7AF)
c = FF(c, d, a, b, x[k + 10], S13, 0xFFFF5BB1)
b = FF(b, c, d, a, x[k + 11], S14, 0x895CD7BE)
a = FF(a, b, c, d, x[k + 12], S11, 0x6B901122)
d = FF(d, a, b, c, x[k + 13], S12, 0xFD987193)
c = FF(c, d, a, b, x[k + 14], S13, 0xA679438E)
b = FF(b, c, d, a, x[k + 15], S14, 0x49B40821)
a = GG(a, b, c, d, x[k + 1], S21, 0xF61E2562)
d = GG(d, a, b, c, x[k + 6], S22, 0xC040B340)
c = GG(c, d, a, b, x[k + 11], S23, 0x265E5A51)
b = GG(b, c, d, a, x[k + 0], S24, 0xE9B6C7AA)
a = GG(a, b, c, d, x[k + 5], S21, 0xD62F105D)
d = GG(d, a, b, c, x[k + 10], S22, 0x2441453)
c = GG(c, d, a, b, x[k + 15], S23, 0xD8A1E681)
b = GG(b, c, d, a, x[k + 4], S24, 0xE7D3FBC8)
a = GG(a, b, c, d, x[k + 9], S21, 0x21E1CDE6)
d = GG(d, a, b, c, x[k + 14], S22, 0xC33707D6)
c = GG(c, d, a, b, x[k + 3], S23, 0xF4D50D87)
b = GG(b, c, d, a, x[k + 8], S24, 0x455A14ED)
a = GG(a, b, c, d, x[k + 13], S21, 0xA9E3E905)
d = GG(d, a, b, c, x[k + 2], S22, 0xFCEFA3F8)
c = GG(c, d, a, b, x[k + 7], S23, 0x676F02D9)
b = GG(b, c, d, a, x[k + 12], S24, 0x8D2A4C8A)
a = HH(a, b, c, d, x[k + 5], S31, 0xFFFA3942)
d = HH(d, a, b, c, x[k + 8], S32, 0x8771F681)
c = HH(c, d, a, b, x[k + 11], S33, 0x6D9D6122)
b = HH(b, c, d, a, x[k + 14], S34, 0xFDE5380C)
a = HH(a, b, c, d, x[k + 1], S31, 0xA4BEEA44)
d = HH(d, a, b, c, x[k + 4], S32, 0x4BDECFA9)
c = HH(c, d, a, b, x[k + 7], S33, 0xF6BB4B60)
b = HH(b, c, d, a, x[k + 10], S34, 0xBEBFBC70)
a = HH(a, b, c, d, x[k + 13], S31, 0x289B7EC6)
d = HH(d, a, b, c, x[k + 0], S32, 0xEAA127FA)
c = HH(c, d, a, b, x[k + 3], S33, 0xD4EF3085)
b = HH(b, c, d, a, x[k + 6], S34, 0x4881D05)
a = HH(a, b, c, d, x[k + 9], S31, 0xD9D4D039)
d = HH(d, a, b, c, x[k + 12], S32, 0xE6DB99E5)
c = HH(c, d, a, b, x[k + 15], S33, 0x1FA27CF8)
b = HH(b, c, d, a, x[k + 2], S34, 0xC4AC5665)
a = II(a, b, c, d, x[k + 0], S41, 0xF4292244)
d = II(d, a, b, c, x[k + 7], S42, 0x432AFF97)
c = II(c, d, a, b, x[k + 14], S43, 0xAB9423A7)
b = II(b, c, d, a, x[k + 5], S44, 0xFC93A039)
a = II(a, b, c, d, x[k + 12], S41, 0x655B59C3)
d = II(d, a, b, c, x[k + 3], S42, 0x8F0CCC92)
c = II(c, d, a, b, x[k + 10], S43, 0xFFEFF47D)
b = II(b, c, d, a, x[k + 1], S44, 0x85845DD1)
a = II(a, b, c, d, x[k + 8], S41, 0x6FA87E4F)
d = II(d, a, b, c, x[k + 15], S42, 0xFE2CE6E0)
c = II(c, d, a, b, x[k + 6], S43, 0xA3014314)
b = II(b, c, d, a, x[k + 13], S44, 0x4E0811A1)
a = II(a, b, c, d, x[k + 4], S41, 0xF7537E82)
d = II(d, a, b, c, x[k + 11], S42, 0xBD3AF235)
c = II(c, d, a, b, x[k + 2], S43, 0x2AD7D2BB)
b = II(b, c, d, a, x[k + 9], S44, 0xEB86D391)
a = addUnsigned(a, AA)
b = addUnsigned(b, BB)
c = addUnsigned(c, CC)
d = addUnsigned(d, DD)
}
var tempValue = wordToHex(a) + wordToHex(b) + wordToHex(c) + wordToHex(d)
return tempValue.toLowerCase()
}
var rotateLeft = function(lValue, iShiftBits) {
return (lValue << iShiftBits) | (lValue >>> (32 - iShiftBits))
}
var addUnsigned = function(lX, lY) {
var lX4, lY4, lX8, lY8, lResult
lX8 = (lX & 0x80000000)
lY8 = (lY & 0x80000000)
lX4 = (lX & 0x40000000)
lY4 = (lY & 0x40000000)
lResult = (lX & 0x3FFFFFFF) + (lY & 0x3FFFFFFF)
if (lX4 & lY4) return (lResult ^ 0x80000000 ^ lX8 ^ lY8)
if (lX4 | lY4) {
if (lResult & 0x40000000) return (lResult ^ 0xC0000000 ^ lX8 ^ lY8)
else return (lResult ^ 0x40000000 ^ lX8 ^ lY8)
} else {
return (lResult ^ lX8 ^ lY8)
}
}
var F = function(x, y, z) {
return (x & y) | ((~x) & z)
}
var G = function(x, y, z) {
return (x & z) | (y & (~z))
}
var H = function(x, y, z) {
return (x ^ y ^ z)
}
var I = function(x, y, z) {
return (y ^ (x | (~z)))
}
var FF = function(a, b, c, d, x, s, ac) {
a = addUnsigned(a, addUnsigned(addUnsigned(F(b, c, d), x), ac))
return addUnsigned(rotateLeft(a, s), b)
}
var GG = function(a, b, c, d, x, s, ac) {
a = addUnsigned(a, addUnsigned(addUnsigned(G(b, c, d), x), ac))
return addUnsigned(rotateLeft(a, s), b)
}
var HH = function(a, b, c, d, x, s, ac) {
a = addUnsigned(a, addUnsigned(addUnsigned(H(b, c, d), x), ac))
return addUnsigned(rotateLeft(a, s), b)
}
var II = function(a, b, c, d, x, s, ac) {
a = addUnsigned(a, addUnsigned(addUnsigned(I(b, c, d), x), ac))
return addUnsigned(rotateLeft(a, s), b)
}
var convertToWordArray = function(string) {
var lWordCount
var lMessageLength = string.length
var lNumberOfWordsTempOne = lMessageLength + 8
var lNumberOfWordsTempTwo = (lNumberOfWordsTempOne - (lNumberOfWordsTempOne % 64)) / 64
var lNumberOfWords = (lNumberOfWordsTempTwo + 1) * 16
var lWordArray = Array(lNumberOfWords - 1)
var lBytePosition = 0
var lByteCount = 0
while (lByteCount < lMessageLength) {
lWordCount = (lByteCount - (lByteCount % 4)) / 4
lBytePosition = (lByteCount % 4) * 8
lWordArray[lWordCount] = (lWordArray[lWordCount] | (string.charCodeAt(lByteCount) << lBytePosition))
lByteCount++
}
lWordCount = (lByteCount - (lByteCount % 4)) / 4
lBytePosition = (lByteCount % 4) * 8
lWordArray[lWordCount] = lWordArray[lWordCount] | (0x80 << lBytePosition)
lWordArray[lNumberOfWords - 2] = lMessageLength << 3
lWordArray[lNumberOfWords - 1] = lMessageLength >>> 29
return lWordArray
}
var wordToHex = function(lValue) {
var WordToHexValue = '',
WordToHexValueTemp = '',
lByte, lCount
for (lCount = 0; lCount <= 3; lCount++) {
lByte = (lValue >>> (lCount * 8)) & 255
WordToHexValueTemp = '0' + lByte.toString(16)
WordToHexValue = WordToHexValue + WordToHexValueTemp.substr(WordToHexValueTemp.length - 2, 2)
}
return WordToHexValue
}
var uTF8Encode = function(string) {
string = string.toString().replace(/\x0d\x0a/g, '\x0a')
var output = ''
for (var n = 0; n < string.length; n++) {
var c = string.charCodeAt(n)
if (c < 128) {
output += String.fromCharCode(c)
} else if ((c > 127) && (c < 2048)) {
output += String.fromCharCode((c >> 6) | 192)
output += String.fromCharCode((c & 63) | 128)
} else {
output += String.fromCharCode((c >> 12) | 224)
output += String.fromCharCode(((c >> 6) & 63) | 128)
output += String.fromCharCode((c & 63) | 128)
}
}
return output
}
return createMD5String(md5str)
}
function get_url(o){
c = new Date,
l = c.getTime(),
u = 6e4 * c.getTimezoneOffset(),
m = l + u + 36e5 * 8,
d = new Date(m),
p = (p = d).getDate() + 9 + 9 ^ 10,
p = (p = md5(String(p))).substring(0, 10),
p = md5(p),
h = d.getDay() + 11397,
g = "https:"+"xxx.脱敏.xxx?z=".concat(p, "&jx=").concat(o),
g += "&s1ig=".concat(h)
return g+"&g="
}
py实现
import time,datetime, pytz
from hashlib import md5
def get_url(video_url):
l = int(time.time()*1000)
# 获取当前时间
now = datetime.datetime.now()
# 获取当前时区的时区对象
tz = pytz.timezone('Asia/Shanghai')
# 计算当前时区与UTC的时间差
utc_offset = tz.utcoffset(now).total_seconds() / 60
u = 6e4 * int(-utc_offset)
m = int(l + u + 36e5 * 8)
today = datetime.date.today().day
p = today + 9 + 9 ^ 10
p = md5(str(p).encode('utf-8')).hexdigest()[:10]
p = md5(p.encode('utf-8')).hexdigest()
h = datetime.date.today().weekday()+1 + 11397
g = "https:" + "xxx.脱敏.xxx?z="+p+"&jx="+video_url
g += "&s1ig="+str(h)
return g + "&g="
如果不知道如何用python实现js的部分算法,直接用ChatGPT叫它帮你写,哈哈哈。
确实很6,比在百度上搜快多了!!!
实战
接口1
# -*- coding:utf-8 -*-
"""
@Author : 小尹
@Time : 2023/3/16 16:18
"""
import requests, execjs
import time,datetime, pytz
from hashlib import md5
def get_url(video_url):
l = int(time.time()*1000)
# 获取当前时间
now = datetime.datetime.now()
# 获取当前时区的时区对象
tz = pytz.timezone('Asia/Shanghai')
# 计算当前时区与UTC的时间差
utc_offset = tz.utcoffset(now).total_seconds() / 60
u = 6e4 * int(-utc_offset)
m = int(l + u + 36e5 * 8)
today = datetime.date.today().day
p = today + 9 + 9 ^ 10
p = md5(str(p).encode('utf-8')).hexdigest()[:10]
p = md5(p.encode('utf-8')).hexdigest()
h = datetime.date.today().weekday()+1 + 11397
g = "https:" + "xxx.脱敏.xxx?z="+p+"&jx="+video_url
g += "&s1ig="+str(h)
return g + "&g="
def im1907_top(video_url):
# url = execjs.compile(open('./im1907_top.js', mode='r', encoding='utf-8').read()).call('get_url', video_url) # 使用execjs 执行js代码
url = get_url(video_url)
headers = {
"authority": "xxx.脱敏.xxx",
"accept": "*/*",
"origin": "xxx.脱敏.xxx",
"referer": "xxx.脱敏.xxx",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
}
data = requests.get(url, headers=headers).json()['data']
all_video_url_list = []
for i in data:
name = i['name']
year = i['year']
for j in i['source']['eps']:
name2 = j['name']
print(f"视频名:{
name}\t年份:{
year}\t{
name2}")
all_video_url_list.append(j['url'])
parse_video_url = all_video_url_list[0]
if len(all_video_url_list) == 1:
return parse_video_url
print("###请选择要解析第几集视频的m3u8_url###")
while True:
try:
video_num = int(input("请输入(0退出)>>>").strip())
if video_num>len(all_video_url_list) or video_num<0:
raise Exception("没有此集视频!")
exit_flag = video_num
parse_video_url = all_video_url_list[video_num - 1]
break
except:
print("输入集数错误!!!")
if exit_flag==0: return '已退出!!!'
def get_m3u8_url(url):
headers = {
"authority": "xxx.脱敏.xxx",
"accept": "*/*",
"origin": "xxx.脱敏.xxx",
"referer": "xxx.脱敏.xxx",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
m3u8_url = response.text.split('\n')
m3u8_url = url.replace('index.m3u8', m3u8_url[-1])
return m3u8_url
# 二选一即可
# m3u8_url = parse_video_url.replace('index.m3u8', '2000kb/hls/index.m3u8') # 从规律中解析的m3u8_url
m3u8_url = get_m3u8_url(parse_video_url) # 按照网站的抓包流程进行解析完整的m3u8_url
return m3u8_url
if __name__ == '__main__':
video_url = ""
print(im1907_top(video_url))
接口2
# -*- coding:utf-8 -*-
"""
@Author : 小尹
@Time : 2023/3/16 15:47
"""
import requests, re
def jx_playerjy_com(video_url):
headers = {
"authority": "xxx.脱敏.xxx",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"referer": "xxx.脱敏.xxx",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
}
url = "xxx.脱敏.xxx?url="+video_url
text = requests.get(url, headers=headers).text
timestamp = re.findall('"time": "(.*?)",', text)[0]
key = re.findall('"key": "(.*?)",', text)[0]
headers = {
"authority": "xxx.脱敏.xxx",
"accept": "application/json, text/javascript, */*; q=0.01",
"origin": "xxx.脱敏.xxx",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36",
"x-requested-with": "XMLHttpRequest"
}
url = "xxx.脱敏.xxx"
data = {
"url": video_url,
"time": timestamp,
"key": key
}
response = requests.post(url, headers=headers, data=data)
m3u8_url = response.json()['url']
print(f"video_url={
video_url}的m3u8_url为>>>\n", m3u8_url)
return m3u8_url
if __name__ == '__main__':
video_url = ""
jx_playerjy_com(video_url)