前言
性能分析器是优化模型性能的重要工具,决定如何在单个 GPU 上最好地运行多个模型。
安装测试环境
拉取镜像
docker pull nvcr.io/nvidia/tritonserver:22.08-py3-sdk
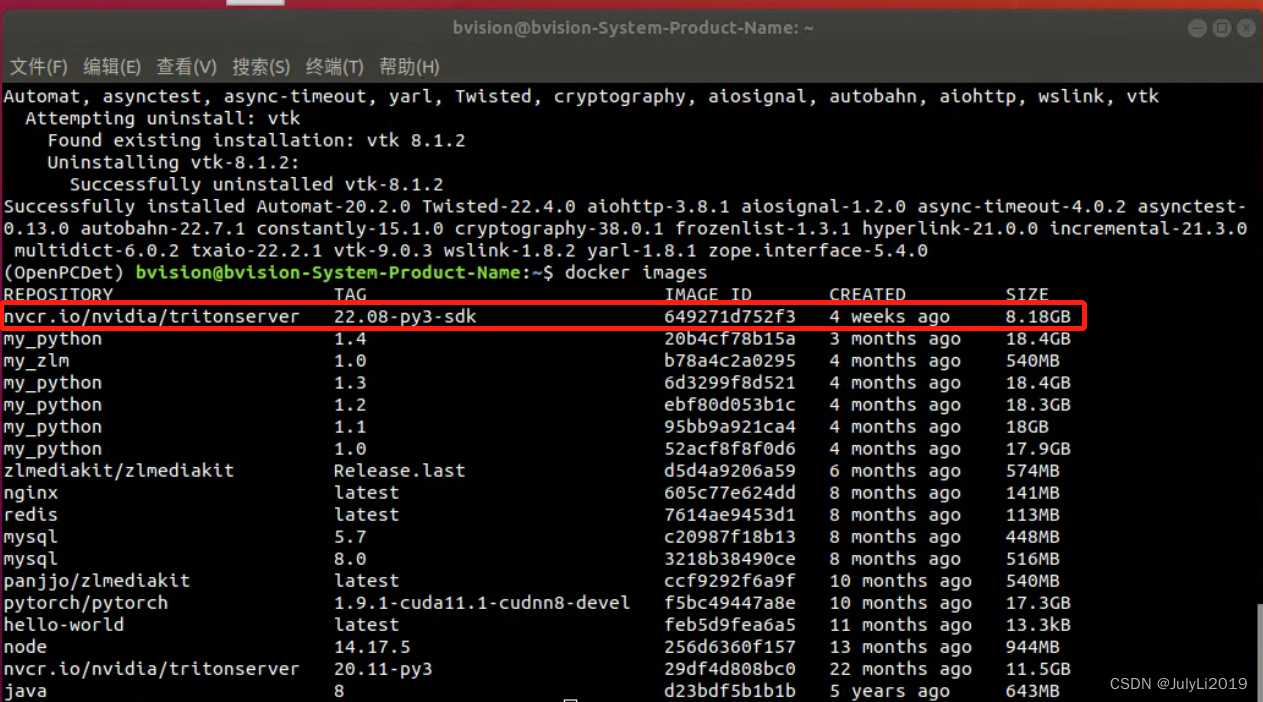
测试
启动测试环境
docker run -it --rm --net=host -v/data/project/triton_deploy/models:/models -v/data/project/triton_deploy/plugins:/plugins nvcr.io/nvidia/tritonserver:22.08-py3-sdk
这里需要根据自己的路径修改models与plugins路径
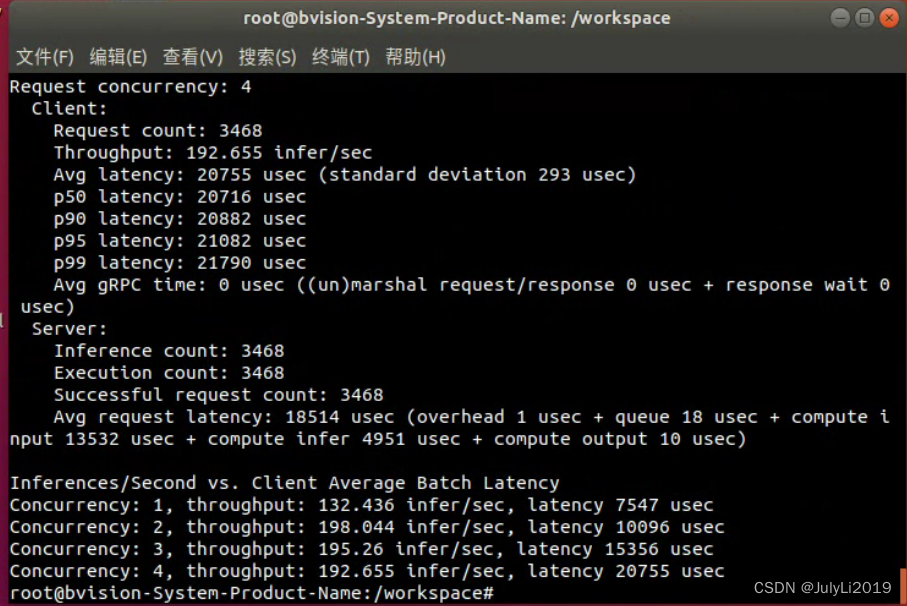
对比同一模型不同并发数的吞吐量
perf_analyzer -m model_name --concurrency-range 1:4 --percentile=95 -i grpc
model_name为测试的模型名称
对比同一模型不同实例数的吞吐量
将instance_group [ { count: 4}]添加到模型配置的末尾文件,然后重新启动 Triton
perf_analyzer -m model_name --concurrency-range 1:4 --percentile=95 -i grpc
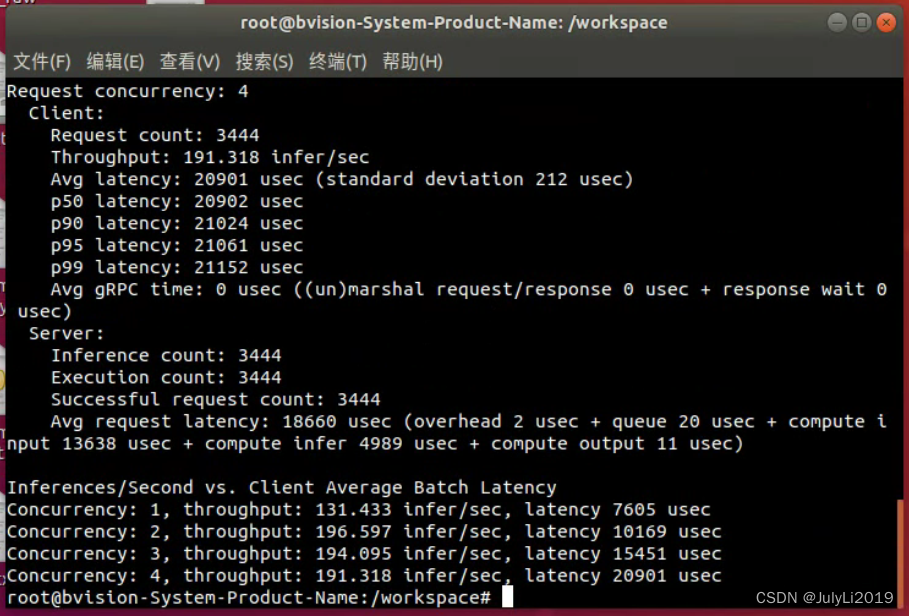
这里看起来好像与默认实例相比没什么变化,不知道是不是因为我用的是yolov5x模型的原因,不太清楚!
总结
除了启用模型实例,还是可以设置启用动态批处理器,这两项也可以同时启用,可以根据自己的配置进行设置比较。通过模型分析器部分介绍了一种工具,可帮助我们了解模型的GPU 内存利用率,以便决定如何在单个 GPU 上最好地运行多个模型。
参考文档:https://github.com/triton-inference-server/server/blob/main/docs/user_guide/optimization.md
如果阅读本文对你有用,欢迎一键三连呀!!!
2022年9月15日20:12:35
