有想学习node.js可以看下我最近总结的笔记,适合新手入门讲解详细,这是我的笔记地址:node学习笔记
node.js
node.js是一种服务端环境,js可以在这个环境下运行,这样使用js就可以编写服务端代码了。
在本教程中你将学到:
- 使用node.js搭建一个文件系统
- 使用node.js搭建一个http服务器
- 使用node.js实现文件的上传和下载
- 使用node.js爬取京东商城数据
- 使用node.js操作连接MongoDB数据库
- 使用express框架开发网络接口,实现一个todolist服务
- 介绍作者开发的express-router框架,中小型项目最优解决方案
!> node.js是一种服务端的运行环境,可以用来进行服务端开发。
node.js入门
本小结我们主要整理一些node.js的入门知识
搭建环境
我们首先要到node.js官网去下载符合您操作系统的node安装包【建议下载稳定版本】,在安装过程中勾选add to path这个复选框。
在安装结束后,打开cmd(win+r输入cmd)
# 输入以下指令
node -v
npm -v
!> 如果显示了版本号,证明node环境已经安装成功了。如果出现xxx既不是可运行的脚本又不是可执行程序,请重新安装node
运行node.js
首先请在你的目录下新建一个index.js的文件
里面输入以下内容:
function sayHello(){
console.log("HelloWorld")
}
sayHello()
然后在该目录下打开cmd(在文件资源管理器地址输入框输入cmd敲回车即可)
# 输入node index.js
node index.js
然后你会在控制台上看到HelloWorld了
!> node.js依然是遵循javascript语法的,js中可以使用的字符串或数组方法在node.js中也是可以使用的。不过node环境中不支持document对象、window对象等dom或者bom对象,这也不难理解,因为服务器不需要操作dom和bom
运行node.js很简单,只需要进入当前目录(在文件资源管理器地址输入框输入cmd敲回车即可),然后输入node 【js文件】就可以了
模块化编程
node.js讲究的是模块化编程,特别注重模块的导入和导出。模块化编程是多文件编程,从一个文件中引入其他文件进行编程。
我们的目录结构如下:(下面的案例使用这个目录结构)

module.exports
用于整体批量导出成员
m3.js
const str="我爱前端"
const person={
name:'node',
age:'18'
}
module.exports={
a:1,
b:'HelloWorld',
person:person,
str:str
}
require
用于导入成员
main.js
let {
a,b,str,person} =require('./module/m3.js')
console.log(str,person,a,b)
!> 在node.js中,我们使用module.exports和require进行模块化导入导出
node.js基础
通过以上知识的学习,我们了解了如何运行node.js,了解了在node.js中如何使用多文件编程,如何进行模块的导入导出。接下来就要进行node,js基础库的学习,分别包括解析url,解析url参数,相对路径绝对路径转化,文件操作。
URL
URL是一个常见的对象,用于在服务端处理前端发来的请求,从请求中提取有用的参数信息,从而进一步进行操作
url构成
我们现在看一下,url的组成部分
https://www.baidu.com:443/ad/index.html?id=8&name=mouse#tag=110
| 组成部分 | 中文含义 | 英文含义 |
|---|---|---|
| https | 协议 | protocol |
| 443 | 端口 | port |
| /ad/index.html | 路径 | path |
| id=8&name=mouse | url参数 | query |
| #tag=110 | hash值 | hash |
所以:https://www.baidu.com:443/ad/index.html?id=8&name=mouse#tag=110对应的url对象【解析后】如下
Url {
protocol: 'https:',
host: 'www.baidu.com:443',
port: '443',
hostname: 'www.baidu.com',
hash: '#tag=110',
search: '?id=8&name=mouse',
query: 'id=8&name=mouse',
pathname: '/ad/index.html',
path: '/ad/index.html?id=8&name=mouse',
href: 'https://www.baidu.com:443/ad/index.html?id=8&name=mouse#tag=110'
}
URL(url:string)
用途:
用来创建url实例
参数解读:
| 参数 | 数据类型 | 含义 |
|---|---|---|
| url | string | url路径 |
示例代码:
const url=require("url");
var urlInstance=new URL("https://www.baidu.com:443/ad/index.html?id=8&name=mouse#tag=110");
console.log(urlInstance)
console.log("id=>",urlInstance.searchParams.get('id'))
console.log("name=>",urlInstance.searchParams.get('name'))
console.log("hash=>",urlInstance.hash)
运行结果:
URL {
href: 'https://www.baidu.com/ad/index.html?id=8&name=mouse#tag=110',
origin: 'https://www.baidu.com',
protocol: 'https:',
username: '',
password: '',
host: 'www.baidu.com',
hostname: 'www.baidu.com',
port: '',
pathname: '/ad/index.html',
search: '?id=8&name=mouse',
searchParams: URLSearchParams {
'id' => '8', 'name' => 'mouse' },
hash: '#tag=110'
}
id=> 8
name=> mouse
hash=> #tag=110
url.parse(url:string,query:boolean)
用途:
url.parse()用来解析url参数部分
参数解读:
| 参数 | 数据类型 | 含义 |
|---|---|---|
| url | string | url路径 |
| query | boolean | 是否把url参数转化为object |
示例代码:
const url = require('url')
const urlString = 'https://www.baidu.com:443/ad/index.html?id=8&name=mouse#tag=110'
const parsedStr = url.parse(urlString,false)
const parseObject=url.parse(urlString,true)
// 第二个参数为true时,会把query转化为对象
console.log("parsedStr【query未转化为对象】",parsedStr)
console.log("parseObject【query转化为对象】",parseObject)
console.log("URL参数【字符串】",parsedStr.query)
console.log("URL参数【对象】",parseObject.query)
console.log("获取name",parseObject.query.name)
运行结果:
parsedStr【query未转化为对象】 Url {
protocol: 'https:',
slashes: true,
auth: null,
host: 'www.baidu.com:443',
port: '443',
hostname: 'www.baidu.com',
hash: '#tag=110',
search: '?id=8&name=mouse',
query: 'id=8&name=mouse',
pathname: '/ad/index.html',
path: '/ad/index.html?id=8&name=mouse',
href: 'https://www.baidu.com:443/ad/index.html?id=8&name=mouse#tag=110'
}
parseObject【query转化为对象】 Url {
protocol: 'https:',
slashes: true,
auth: null,
host: 'www.baidu.com:443',
port: '443',
hostname: 'www.baidu.com',
hash: '#tag=110',
search: '?id=8&name=mouse',
query: [Object: null prototype] {
id: '8', name: 'mouse' },
pathname: '/ad/index.html',
path: '/ad/index.html?id=8&name=mouse',
href: 'https://www.baidu.com:443/ad/index.html?id=8&name=mouse#tag=110'
}
URL参数【字符串】 id=8&name=mouse
URL参数【对象】 [Object: null prototype] {
id: '8', name: 'mouse' }
获取name mouse
!> url.parse()如果在您的编辑器中出现删除线,那说明这个方法是老旧方法,在新版本的node中可能会被废弃
url.format(URL:Object)
用途:
将一个url对象转化为url地址字符串
参数解读:
| 参数 | 数据类型 | 含义 |
|---|---|---|
| URL | Object | url对象 |
示例代码:
const url = require('url')
const urlObject = {
protocol: 'https:',
slashes: true,
auth: null,
host: 'www.baidu.com:443',
port: '443',
hostname: 'www.baidu.com',
hash: '#tag=110',
search: '?id=8&name=mouse',
query: {
id: '8', name: 'mouse'
},
pathname: '/ad/index.html',
path: '/ad/index.html?id=8&name=mouse',
href: 'https://www.baidu.com:443/ad/index.html?id=8&name=mouse#tag=110'
}
const parsedObj = url.format(urlObject)
console.log(parsedObj)
运行结果:
https://www.baidu.com:443/ad/index.html?id=8&name=mouse#tag=110
!> url.format()如果在您的编辑器中出现删除线,那说明这个方法是老旧方法,在新版本的node中可能会被废弃
url.resolve(from:string,to:string)
用途:
把一个url地址切换到另一个路径地址
示例代码:
const url = require('url')
var a = url.resolve('http://example.com/', '/one')
var b = url.resolve('http://example.com/one/a', '/two')
console.log(a,b)
运行结果:
http://example.com/one http://example.com/two
!> 这个api替换的是相对路径,可以理解为是相对路径的替换。这个api可能在将来的node版本中被废弃
URLSearchParams(query:string)
用途:
把字符串的params解析成Map格式的params
name=cqg&age=18=>{name=>‘cqg’,age=>18}
参数解读:
| 参数 | 数据类型 | 含义 |
|---|---|---|
| query | string | url参数(ex:name=cqg&age=19) |
示例代码:
const params=new URLSearchParams("name=cqg&age=18")
console.log("name",params.get('name'))
console.log("age",params.get('age'))
运行结果:
name cqg
age 18
querystring
一个专门用来处理url参数的库,它可以把字符串形式的url参数转化成对象,也可以把对象转换为url参数
querystring.parse(query:string)
用途:
把字符串形式的url参数转化为对象
name=cqg&age=18=>{name:‘cqg’,age:18}
参数解读:
| 参数 | 数据类型 | 含义 |
|---|---|---|
| query | string | url参数字符串(name=cqg&age=18) |
示例代码:
const querystring = require('querystring')
var query = 'name=cqg&age=18'
var queryObject = querystring.parse(query)
console.log(queryObject)
运行结果:
[Object: null prototype] {
name: 'cqg', age: '18' }
querystring.stringfy(qs:object)
用途:
把一个对象转化为url字符串(用&连接)
参数解读:
| 参数 | 数据类型 | 含义 |
|---|---|---|
| qs | object | 一个对象({name:18,age20}) |
示例代码:
const querystring = require('querystring')
var qs = {
age: 18,
name: 'cqg'
}
var str = querystring.stringify(qs)
console.log(str)
运行结果:
age=18&name=cqg
querystring.escape(query:string)
用途:
把url参数进行编码
示例代码:
const querystring = require('querystring')
var str = 'id=3&city=北京&url=https://www.baidu.com'
var escaped = querystring.escape(str)
console.log(escaped)
运行结果:
id%3D3%26city%3D%E5%8C%97%E4%BA%AC%26url%3Dhttps%3A%2F%2Fwww.baidu.com
querystring.unescape(query:string)
用途:
把url参数进行解码
示例代码:
const querystring = require('querystring')
var str = 'id%3D3%26city%3D%E5%8C%97%E4%BA%AC%26url%3Dhttps%3A%2F%2Fwww.baidu.com'
var unescaped = querystring.unescape(str)
console.log(unescaped)
运行结果:
id=3&city=北京&url=https://www.baidu.com
path
path是文件路径库,用来进行文件路径的合并,路径解析
path的写法
// 使用反斜杠书写文件路径:由于\存在转义,需要写成\\;这个道理和%一样,写成%%
var p1="C:\\Users\\cqg\\Desktop\\MyServer\\project"
// 使用正斜杠书写:这个没有转义直接写即可
var p1="C:/Users/cqg/Desktop/MyServer/project"
!> windows系统下我们直接复制的文件路径是带有反斜杠\的,因此写的时候我们要写成\\,这个要注意。
__dirname
表示当前运行环境的绝对路径
console.log(__dirname)
!> 打印结果是运行js文件的绝对路径
path.join(path1:string,path2:string,…pathn)
用途:
进行路径的合并
示例代码:
const path = require('path')
const combine = path.join(__dirname,"/lib","/path")
console.log(combine)
!> 打印结果是当前目录+/lib+/path,path.join可以把相对路径转化为绝对路径
path.parse(path:string)
用途:
把字符串形式的路径转化为path对象
示例代码:
const path = require('path')
var parse = path.parse('D:/home/user/dir/file.txt');
console.log(parse)
console.log("文件名",parse.name)
运行结果:
{
root: 'D:/',
dir: 'D:/home/user/dir',
base: 'file.txt',
ext: '.txt',
name: 'file'
}
文件名 file
Path结构:
D:/home/user/dir/file.txt
| 组成部分 | 中文含义 | 英文含义 |
|---|---|---|
| D:/ | 盘根路径 | root |
| D:/home/user/dir | 目录 | dir |
| file.txt | 文件 | base |
| .txt | 拓展名 | ext |
| file | 文件名 | name |
path.format(path:Path)
用途:
把一个path对象转化为字符串
示例代码:
const path = require('path')
var Path = {
root: 'D:/',
dir: 'D:/home/user/dir',
base: 'file.txt',
ext: '.txt',
name: 'file'
}
var format=path.format(Path);
console.log(format)
运行结果:
D:/home/user/dir/file.txt
fs
node.js中专门处理文件的模块,可以读写文件,进行文件操作。node.js提供了异步和同步的API供开发者使用,同步可以理解为await,会等待任务完成后才会向下运行其他代码;异步指的是不管任务是否完成都会执行下面的代码,在执行结束后调用回调函数。
fs.existsSync(path:string)
用途:
判断目录或目录是否存在,存在返回true,不存在返回false
示例代码:
const fs = require('fs')
if(fs.existsSync('D:/node')){
console.log('存在路径')
}else{
console.log('不存在路径')
}
运行结果
存在路径
!> 我的D盘下有node文件夹,所以存在路径
fs.mkdir(path:string)
用途:
创建一个目录(异步)
!> 异步指的是即使目录没有创建好,代码也会向下进行
示例代码:
const fs = require('fs')
fs.mkdir('./libs', (err) => {
if(!err) console.log("mkdir success")
else throw err
})
运行效果:
发现多了一个libs文件夹
webstorm,和vscode需要点击一下项目根目录,也就是刷新一下才能看到(IDE扫描延迟)
fs.mkdirSync(path:string)
用途:
创建一个目录(同步)
!> 同步指的是目录没有创建好,程序会阻塞不会向下运行其他代码;直到目录创建好了,才会向下运行其他代码
示例代码:
const fs = require('fs')
fs.mkdirSync("./lib")
console.log("lib success")
运行结果:
lib success
思考题:
什么时候用同步API?什么时候用异步API?
当目录创建完了之后再进行下一步,建议用同步API;其他情况请使用异步API,执行效率高没有阻塞
其实还有fs.rmdir和fs.rmdirSync,这是用来异步/同步删除目录的,用法类似,就不做详细介绍了
fs.stat(path:string,callback:function)
用途:
判断是目录还是文件(异步)
代码演示:
const fs = require('fs')
fs.stat('D:/', (err, stats) => {
if(stats.isFile()){
console.log('是文件')
}else{
console.log('是目录')//输出这个
}
})
fs.statSync(path:string)
用途:
判断是目录还是文件(同步)
代码演示:
const fs = require('fs')
const stats = fs.statSync('D:/')
if(stats.isFile()){
console.log('是文件')
}else{
console.log('是目录')//输出这个
}
fs.writeFile(path:string,data:string|buffer,charset:string,callback:function)
用途:
写入文件(异步)
参数解读:
| 参数 | 数据类型 | 含义 |
|---|---|---|
| path | string | 路径 |
| data | string|buffer | 写入内容(可以是字符串/文件流) |
| charset | string | 字符编码 |
| callback | function | 文件写入结束后的回调函数 |
示例代码1:
const fs = require('fs')
fs.writeFile('./node.txt',"你好,node.js","utf-8",(err)=>{
if(!err) console.log("写入文本成功!")
else throw err
})
运行效果:
出现了一个node.txt的文件,文件内容是:你好node.js
webstorm,和vscode需要点击一下项目根目录,也就是刷新一下文件列表才能看到
示例代码2:
const fs = require('fs')
const data = [{
id: 18413001,
name: 'cqg'
}, {
id: 18413002,
name: 'wht'
}]
fs.writeFile('./demo.json', JSON.stringify(data), 'utf-8', (err) => {
if (!err) console.log('写入json文本成功!')
else throw err
})
运行结果:
出现了demo.json的文件,内容是所写内容
!> fs.writeFile会覆盖上一次写入的文件,如果想接着上一次写入的结尾继续写请使用fs.appendFile,它可以追加写入文件,用法参数和writefile一致
fs.writeFileSync(path:string,data:string|buffer,charset:string)
用途:
同步写入文件
示例代码:
const fs = require('fs')
const data = [{
id: 18413001,
name: 'cqg'
}, {
id: 18413002,
name: 'wht'
}]
fs.writeFileSync('./demo.json', JSON.stringify(data), 'utf-8')
console.log('写入json文件成功!')
fs.appendFile(path:string,data:string|buffer,charset:string,callback:function)
用途:
追加写入文件(异步)
示例代码:
const fs = require('fs')
fs.appendFile('./node.txt',"你好,node.js","utf-8",(err)=>{
if(!err) console.log("追加写入文本成功!")
else throw err
})
node.txt多了一行追加文本
fs.appendFileSync(path:string,data:string|buffer,charset:string,callback:function)
用途:
追加写入文件(同步)
示例代码:
const fs = require('fs')
fs.appendFileSync('./node.txt',"你好,node.js","utf-8")
console.log('追加文本成功!')
fs.readFile(path:string,charset?:string,callback:function)
用途:
读取文件(异步)
参数解读:
| 参数 | 数据类型 | 含义 |
|---|---|---|
| path | string | 路径D:\file\ |
| charset(可选参数) | string | 字符编码 |
| callback | function | 文件读取结束后的回调函数 |
示例代码:
我们现在就读取上面写入的两个文件demo.json和node.txt
const fs = require('fs')
fs.readFile('./demo.json', (err,data) => {
if (!err) console.log(JSON.parse(data.toString()))
else throw err
})
fs.readFile('./node.txt',(err,data)=>{
if(!err) console.log(data.toString())
else throw err
})
运行结果:
运行结果就是读取的文件了,文件读取结果被打印在控制台上了
!> 由于读取文件是异步的,所以你的运行结果可能是txt文件先被读取出来,json文件后被读取出来
fs.readFileSync(path:string, charset:string)
用途:
同步读入文件
示例代码:
const fs = require('fs')
const json = fs.readFileSync('./demo.json')
const txt = fs.readFileSync('./node.txt')
console.log(JSON.parse(json.toString()),txt.toString())
fs.copyFile(src:string,dest:string,callback:function)
用途:
用于复制文件,转存文件(异步)
参数解读:
| 参数 | 数据类型 | 含义 |
|---|---|---|
| src | string | 要复制的文件路径 |
| dest | string | 文件转存路径 |
| callback | function | 回调函数 |
代码解读:
const fs = require('fs')
fs.copyFile('./node.txt','./node_copy.txt',(err,data)=>{
if(!err) console.log('复制文件成功!')
else throw err
})
运行结果:
项目文件夹下多了一个复制的文件
!> 当然我们也可以使用fs.readFile和fs.writeFile实现复制功能
fs.copyFileSync(src:string,dest:string)
用途:
同步复制文件
代码解读:
const fs = require('fs')
fs.copyFileSync('./node.txt','./node_copy.txt')
console.log('复制文件成功!')
fs.createReadStream(src:string)
用途:
创建读入流
代码:
const fs = require('fs')
const readStream = fs.createReadStream('./node.txt')
readStream.on('data',function (chunk){
console.log(chunk)
})
readStream.on('end',function (){
console.log('end')
})
读入流一旦创建就会读入数据,data和end是读入数据的到读入结束的监听函数
fs.createWriteStream(src:string)
用途:
创建写入流
演示复制文件:
const fs = require('fs')
const readStream = fs.createReadStream('./node.txt')
const writeStream = fs.createWriteStream('./node_copy2.txt')
readStream.on('data', function (chunk) {
writeStream.write(chunk,()=>{
console.log('文件复制成功')
})
})
readStream.on('end', function () {
writeStream.end()
})
!> 请思考一个问题:这种复制文件办法是文件流读取结束后再进行写入,是不是很影响效率,有没有一边读一边写的API呢
reader.pipe(writer)
用途:
建立一个管道,一边读取一边通过管道输送文件流进行写入
目录结构:

代码:
const fs = require('fs')
const reader = fs.createReadStream('./music/白月光与朱砂痣.mp3')
const writer = fs.createWriteStream('./music.mp3')
reader.pipe(writer)
reader.on('end',function (){
console.log('复制歌曲结束')
})
音乐地址
<audio src="http://chengqige.com/music/music.mp3" controls/>
运行结果:
出现了music.mp3复制文件
!> 使用管道运输数据流,可以实现边读边写
node.js服务端开发
通过上面node基础库的学习,我们已经可以做一些简单的文件操作。那么接下来我们就把这些基础运用起来,在本小结你将学习到:node.js搭建服务器,get请求,post请求,router封装,后端接口实现文件上传和下载,搭建静态资源服务器等
那么什么是服务端开发呢,其实我们的网页有很多请求,请求后会返回数据。我们的接口就是提供服务的,用以返回前端数据,比如图片的资源链接让前端去渲染。好了现在我们开启服务端编程之旅吧!
!> 如果想搭建https服务器,请先购买SSL证书,然后参考本教程附录进行操作
http.createServer(req:Request,res:Responce)
用途
用来创建服务器实例
参数解读
| 参数名 | 数据类型 | 详细说明 |
|---|---|---|
| req | Request | req是一个请求数据对象,用来解析前端发来的请求【获取参数】 |
| res | Responce | res是一个响应对象,指返回给前端什么样的数据,res.end里面的参数就是返回内容,返回内容必须是string|Buffer |
实例方法
http.createServer会返回一个server实例,这个server实例也有它的API
server.listen(port:number,callback:function)
- port:端口号
- callback:启动服务成功后,node会自动调用这个函数
创建一个服务
使用node.js可以搭建一个请求服务器,这些接口的请求类型常见的有GET、POST、PUT、DELETE。接下来就让我们创建一个简单的http服务器
server.js
const http = require('http')
const server = http.createServer((req, res) => {
//向客户端发送数据
res.end('HelloWorld')
})
server.listen(4000,()=>{
console.log('本地服务器启动,端口号4000')
})
接下来需要解释一下这段代码:
首先我们可以使用createServer方法去创建一个服务器实例,然后调用实例的listen方法来确定服务器的端口号,并在服务启动成功后调用回调函数,打印一些提示文本,最后createServer函数中的第二个参数res,调用res.end()向客户端传递相应数据HelloWorld
启动服务:
cmd进入到当前目录,输入:
node server.js
运行效果:
本地服务器启动,端口号4000
在浏览器上输入localhost:4000,可以看到HelloWorld
关闭服务:
这个只需要在控制台点一下,然后按下ctrl+c就可以了,或者直接关了控制台,服务也就随之关闭了
探究createServer参数:req
req是请求对象,让我们看看请求对象中都包含什么吧
实验代码:
const http = require('http')
const server = http.createServer((req, res) => {
console.log('请求方法:',req.method)
console.log('请求路径',req.url)
console.log('请求头:',req.headers)
res.end('HelloWorld')
})
server.listen(4000,()=>{
console.log('本地服务器启动,端口号4000')
})
先启动服务,然后打开浏览器在地址栏输入localhost:4000/demo/list?name=1,然后敲击回车
输出结果:
node控制台输出结果:
请求方法: GET
请求路径 /demo/list?name=1
请求头: {
host: 'localhost:4000',
connection: 'keep-alive',
'cache-control': 'max-age=0',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="99", "Google Chrome";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
accept: 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'none',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'sec-fetch-dest': 'document',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9'
}
请求方法: GET
请求路径 /favicon.ico
请求头: {
host: 'localhost:4000',
connection: 'keep-alive',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="99", "Google Chrome";v="99"',
'sec-ch-ua-mobile': '?0',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
'sec-ch-ua-platform': '"Windows"',
accept: 'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'no-cors',
'sec-fetch-dest': 'image',
referer: 'http://localhost:4000/demo/list',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9'
}
我们发现了竟然有两条结果,这是由于你在访问网页的时候会有一个图标,node在寻找这个图标
这个图标就是网页图标,这个图标你可能显示不出来,所以你要做一个.ico格式的图标,把它命名为favicon放在项目目录下,node找到它后会把它作为网站的图标
总结:
| req属性 | 表达式 | 含义 |
|---|---|---|
| method | req.method | 请求方式:GET、POST… |
| url | req.url | 请求的path路径:/demo/list?name=1(注意:path路径不包括=>域名+协议+端口;但是包括url参数) |
| headers | req.headers | 请求头数据:一般解析前端传递来的头部参数 |
探究createServer参数:res
res是响应对象,让我们看看响应对象都包含什么吧
代码:
const http = require('http')
const server = http.createServer((req, res) => {
res.end('HelloWorld')
console.log('响应码',res.statusCode)
console.log('响应信息',res.statusMessage)
})
server.listen(4000,()=>{
console.log('本地服务器启动,端口号4000')
})
结果:
输入localhost:4000,打印一下结果
响应码:200
响应信息:OK
响应码:200
响应信息:OK
很显然这两次结果也有一次是请求favicon.ico的,res里面的可用信息少的可怜,只有响应码和信息
| res属性 | 表达式 | 含义 |
|---|---|---|
| statusCode | res.statusCode | http状态码 |
| statusMessage | res.statusMessage | 响应信息 |
拓展:
常见的http状态码(statusCode)
200响应成功
301永久重定向
302临时重定向
304资源缓存
403服务器禁止访问
404服务器资源未找到
500 502服务器内部错误
504 服务器繁忙
1xx Informational(信息状态码) 接受请求正在处理
2xx Success(成功状态码) 请求正常处理完毕
3xx Redirection(重定向状态码) 需要附加操作已完成请求
4xx Client Error(客户端错误状态码) 服务器无法处理请求
5xx Server Error(服务器错误状态码) 服务器处理请求出错
ApiPost网络接口测试工具
node.js讲解到现在已经进入网络编程阶段,当我们在测试接口时,我们就需要专业化的测试接口工具。大家可以下载ApiPost这个工具,它可以帮助大家去测试接口。工具下载地址
工具的使用
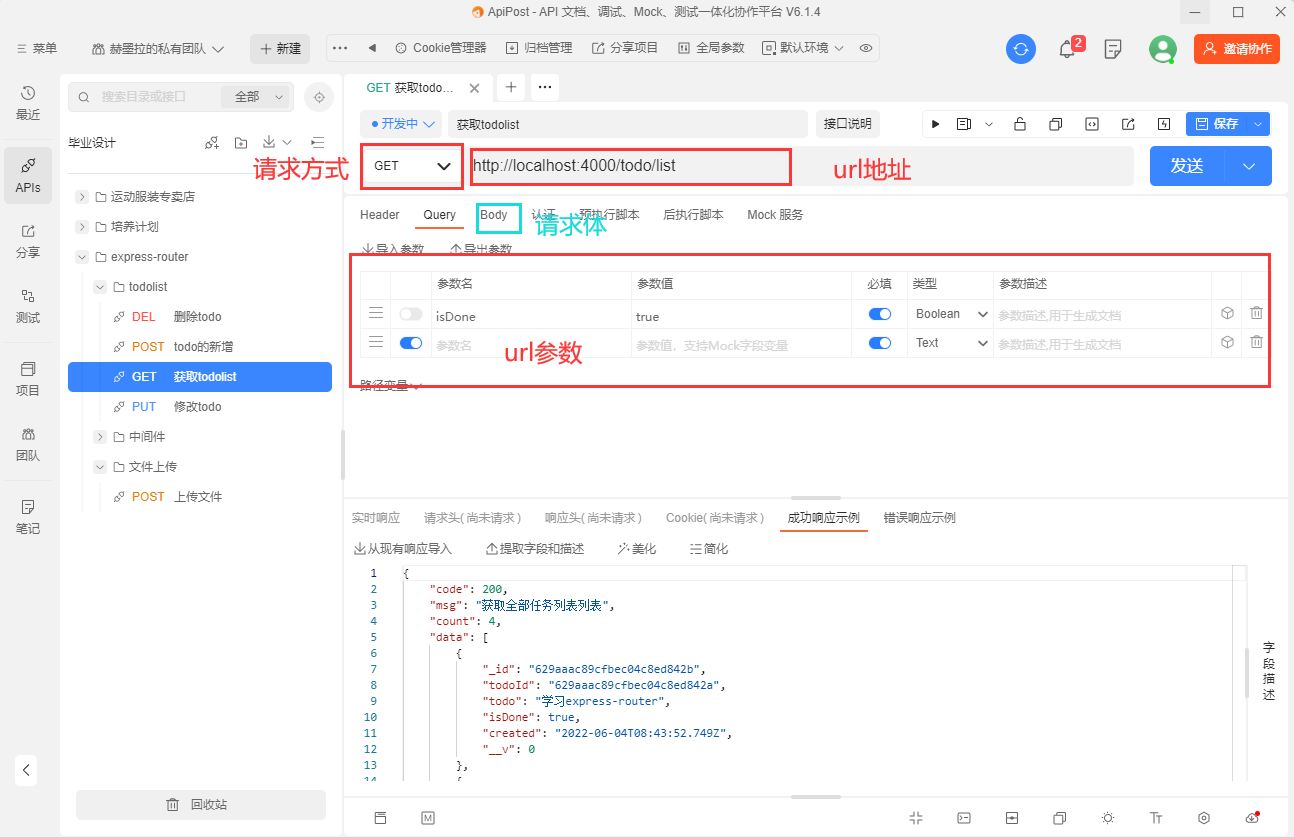
点击发送按钮后,下面即可显示返回结果
处理GET请求
由于GET请求携带的参数在url中,也就是说解析url参数是处理GET请求中必不可少的环节。
const http = require('http')
const url = require('url')
const server = http.createServer((req, res) => {
const urlParse = url.parse(req.url, true)
const result = {
code: 200,
msg: '解析GET请求',
params: urlParse.query
}
res.setHeader('Content-Type', 'application/json;charset=utf-8')
// res.end参数里面的内容必须是字符串,所以要用JSON.stringfy()
res.end(JSON.stringify(result))
})
server.listen(3000, () => {
console.log('解析GET请求服务成功启动,端口3000')
})
apipost中的展示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4cZZBsTp-1657028613801)(https://6368-chengqige-7gunki87efeca981-1302748923.tcb.qcloud.la/node/apipost%E8%A7%A3%E6%9E%90GET%E8%AF%B7%E6%B1%82.png?sign=7cb6a34640c2f4378b6aafe31d71319c&t=1654348396)]
处理POST请求
POST请求的携带参数可以在url中,也可以在body中。所以在处理POST请求的时候,我们要分别去解析请求,先用GET请求解析url参数的办法去解析url参数,然后再解析请求体中的参数。
const http = require('http')
const url = require('url')
const qs = require('querystring')
const server = http.createServer((req, res) => {
const urlParse = url.parse(req.url, true)
let data = ''
req.on('data', (chunk) => {
data += chunk
console.log(data)
})
req.on('end', () => {
const result = {
code: 200,
msg: '解析POST请求,params是url参数,body是请求体数据',
params: urlParse.query,
body: qs.parse(data)
}
res.setHeader('Content-Type', 'application/json;charset=utf-8')
res.end(JSON.stringify(result))
})
})
server.listen(3000, () => {
console.log('解析POST请求服务启动,端口号3000')
})
apipost中的展示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vAZ0t5eq-1657028613802)(https://6368-chengqige-7gunki87efeca981-1302748923.tcb.qcloud.la/node/apipost%E8%A7%A3%E6%9E%90POST%E8%AF%B7%E6%B1%82.png?sign=71e03e134df20a080a60a2672125b541&t=1654348748)]
处理请求体里的数据需要使用req的data、end两个生命周期去解析,在本案例中解析结果为打印的name=cqg001&age=18,但是这样的解析结果不是我们想要的,所以我们需要使用querystring.parse方法,将name=cqg001&age=18进行json数据的转化
处理其他请求
除了基础的get请求和post请求除外,还有PUT、UPDATE、DELETE、DISPATCH这些请求,这些请求的处理方式其实和GET、POST都大同小异,因为在网络接口中我们可以携带参数的地方无非就三种:第一种是在url参数里,第二种是在请求体里,第三种是在请求头header里。那么我们对这三种情况进行不同的解析,获取传递的参数信息。
url参数解析
const http = require('http')
const url = require('url')
const server = http.createServer((req, res) => {
//使用url.parse来解析url
const urlParse = url.parse(req.url, true)
//打印解析的结果
console.log(urlParse)
//支持中文编码
res.setHeader('Content-Type', 'application/json;charset=utf-8')
//urlParse.query获取url参数对象
res.end(JSON.stringify(urlParse.query))
})
server.listen(3000, () => {
console.log('解析url参数服务启动,端口号3000')
})
请求体body解析
const http = require('http')
const url = require('url')
const qs = require('querystring')
const server = http.createServer((req, res) => {
let body = ''
req.on('data', (chunk) => {
body += chunk
console.log("未解析前的请求体", body)
})
req.on('end', () => {
body = qs.parse(body)
console.log("qs库解析后的请求体=>json",body)
res.setHeader('Content-Type', 'application/json;charset=utf-8')
res.end(JSON.stringify(body))
})
})
server.listen(3000, () => {
console.log('解析请求体body服务启动,端口号3000')
})
!> 注意:GET请求没有请求体,它的参数只可能存在header里和url参数里
header解析
const http = require('http')
const server = http.createServer((req, res) => {
res.setHeader('Content-Type', 'application/json;charset=utf-8')
res.end(JSON.stringify(req.headers))
})
server.listen(3000, () => {
console.log('解析请求头header服务启动,端口号3000')
})
HTTP响应头
HTTP响应头主要是响应给客户端信息,让客户端根据响应头的一些信息进行下一步的判断和操作。
Content-Type
HTTP的响应头之一,返回的响应的内容类型,方便浏览器进行内容解析
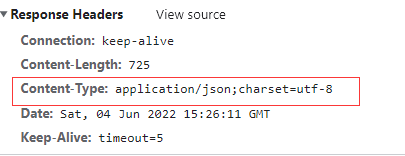
!> 如上图所示,响应头的type类型是json类型,所以浏览器展示的内容是json类型
常见的Content-Type类型:
| content-type | 后缀 | 说明 |
|---|---|---|
| text/plain | .txt | 纯文本 |
| text/html | .html | HTML文档 |
| application/json | .json | JSON格式文档 |
| application/x-www-form-urlencode | form | 表单提交 |
| multipart/form-data | formData | 多种类型表单提交 |
| application/msword | .doc | Word格式 |
| application/vnd.ms-excel | .xls | Excel格式 |
| application/vnd.ms-powerpoint | .ppt | PPT格式 |
| application/zip | .zip | zip压缩文件格式 |
!> 下载mime这个npm库,可以轻松找到更多文件后缀和媒体类型的对应关系
Access-Control-Allow-Origin
用来控制跨域的HTTP响应头,支持的键值格式有*、数组
Access-Control-Allow-Origin: *
Access-Control-Allow-Origin: <origin>
Access-Control-Allow-Origin: [<origin>,<origin>...]
Access-Control-Allow-Credentials
Access-Control-Allow-Credentials 响应头表示是否可以将对请求的响应暴露给页面。返回 true 则可以,其他值均不可以。
我们经常使用它来配置cookie跨域,当然配置cookie跨域,我们前后端都要进行设置。前端需要设置XMLHttpReauest.withCredentials
Cache-Control
用来配置缓存的HTTP响应头,告知浏览器什么资源应该缓存,什么资源不应该缓存,能缓存的话是如何缓存?协商缓存还是强缓存。
// 协商缓存
Cache-control: no-cache
// 不缓存
Cache-control: no-store
// 不缓存的兼容写法,HTTP/1.0时候没有Cache-Control的请求头
Pragma:no-cache
详情请查看:Cache-Control-MDN文档
Access-Control-Expose-Headers
用来自定义暴露的响应头,默认情况下,只有七种 simple response headers(简单响应首部)可以暴露给外部,如果想要自定义则需要设置这个HTTP响应头,否则前端的响应头中获取不到那些自定义的响应头。
Access-Control-Expose-Headers: <header-name>, <header-name>, ...
在node.js中我们可以使用createServer中的res参数,res.setHeader进行设置,支持数组写法
设置响应头
在node.js中共提供了两种api设置http响应头,它们分别是setHeader和writeHead
res.setHeader(header:string,value:string)
const http = require('http')
const server = http.createServer((req, res) => {
// 设置跨域
res.setHeader('Access-Control-Allow-Origin', '*')
// 设置媒体类型和字符编码
res.setHeader('Content-Type', 'application/json;charset=utf-8')
// 设置不缓存资源
res.setHeader('Cache-Control', 'no-store')
// 设置暴露的响应头
res.setHeader('Access-Control-Expose-Headers', ['me', 'cqg'])
// 设置自定义头
res.setHeader('me', 'cqg')
res.setHeader('cqg', true)
// 返回响应体
res.end(JSON.stringify({
code: 200, msg: 'json格式,使用utf-8汉字编码' }))
})
server.listen(3000, () => {
console.log('探究设置响应头服务启动,端口号3000')
})
!> 在apipost测试工具中,如果不设置Access-Control-Expose-Headers,你会发现也是能看到自定义响应头的,这是由于apipost使用了服务器代理,并不存在头跨域的问题,但是如果客户端使用axios进行数据接口请求的时候就会出现没有响应头的问题。
res.writeHead(statusCode:number,headers:{[key:value]})
const http = require('http')
const server = http.createServer((req, res) => {
res.writeHead(200, {
'Access-Control-Allow-Origin': '*',
'Content-Type': 'application/json;charset=utf-8',
'Cache-Control': 'no-store',
'Access-Control-Expose-Headers': ['me', 'cqg'],
'me': 'cqg',
'cqg': true
})
// 返回响应体
res.end(JSON.stringify({
code: 200, msg: 'json格式,使用utf-8汉字编码' }))
})
server.listen(3000, () => {
console.log('探究设置响应头服务启动,端口号3000')
})
!> 使用writeHead可以一次性设置多个响应头
服务端路由
我们不难发现我们之前所写的网络接口,无论我后面的路径写什么,只要端口和ip正确都会进行访问。在网络接口开发中,这显然是不科学的,我们希望每个服务都有自己的路由,都能处理自己的逻辑,也就是独立分隔开,那么我们如何实现这种服务端路由呢?
const http = require('http')
const server = http.createServer((req, res) => {
res.writeHead(200, {
'Access-Control-Allow-Origin': '*',
'Content-Type': 'application/json;charset=utf-8',
'Cache-Control': 'no-store',
})
console.log(req.url)
switch (req.url) {
case '/todo/list':
res.end(JSON.stringify({
code:200,msg:'获取todo列表'}))
break;
case '/todo/add':
res.end(JSON.stringify({
code:200,msg:'添加todo列表'}))
break;
case '/todo/remove':
res.end(JSON.stringify({
code:200,msg:'移除todo列表'}))
break;
case '/todo/update':
res.end(JSON.stringify({
code:200,msg:'更新todo列表'}))
break;
default:
res.end(JSON.stringify({
code: 200, msg: '没有匹配的路由' }))
}
})
server.listen(3000, () => {
console.log('后端路由服务启动,端口号3000')
})
这样我们访问http://localhost:3000/todo/list就能访问特定的服务了。
!> 这里只是演示了基础,如果想自己封装路由器可以自己封装,本教程不再介绍路由的封装
http.request()
这是用来请求服务端接口的库,由于node.js本身也是一个服务器,所以服务器请求服务器是没有跨域这个说法的,CORS协议只会限制客户端请求服务端接口,却不会限制服务端。
const http = require('http')
const req = http.request('http://api.chengqige.com:8080/course/list', {
method: 'GET'
},(res)=>{
res.setEncoding('utf8');
res.on('data', (chunk) => {
console.log(JSON.parse(chunk));
})
})
// 如果是POST请求,需要在这里写入请求正文,并在http.request第二个参数里写入content-type【请求正文类型】
// req.write(null);
req.end()
更多http.request用法参考官方文档
node.js文件传输
node.js可以实现文件传输接口,实现文件的上传和下载。至于文件的上传,只需要客户端使用fileReader读取文件的ArrayBuffer,然后将二进制的数据流数组传入到服务器,服务器接受这些流后使用fs库对文件流进行写入;至于文件的下载,就是服务端返回一个数据流,并且返回后端content-type告知浏览器媒体类型,然后可以实现文件的下载。
文件的上传
node.js端
const http = require('http')
const url = require('url')
const fs = require('fs')
const path = require('path')
http.createServer((req, res) => {
const {
file } = url.parse(req.url, true).query
if (!file) {
res.end('params error no file')
return
}
res.setHeader('Access-Control-Allow-Origin', '*')
req.pipe(fs.createWriteStream(path.join(__dirname, './file/' + file)))
res.end(JSON.stringify({
code: 200, msg: '上传文件接口',file }))
}).listen(3000, () => {
console.log('文件上传服务已经启动,端口3000')
})
前端
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>file</title>
<script src="js/axios.min.js"></script>
</head>
<body>
<input type="file" name="file" onchange="upload()">
<script>
function upload () {
var file = document.querySelector('[type=file]')
var fileReader = new FileReader()
// file.files[0]是值第一个文件,这里调用readAsArrayBuffer是读成二进制流数组
fileReader.readAsArrayBuffer(file.files[0])
// fileReader读取文件并转化二进制流需要时间,在读取结束后就可以调用filereader实例的result属性查看读取的二进制流数组
fileReader.onload = function () {
// 直接使用axios上传
axios.post('http://localhost:3000?file=' + file.files[0].name, fileReader.result).then(res => {
//上传成功
console.log(res.data)
alert(JSON.stringify(res.data))
})
}
}
</script>
</body>
</html>
!> 文件上传前端需要用到H5新增的fileReader对象,具体详情请看源码注释
文件的下载
node.js端
const fs = require('fs')
const mime = require('mime')
const http = require('http')
const path = require('path')
const url = require('url')
const server = http.createServer((req, res) => {
const {
src } = url.parse(req.url, true).query
const filePath = path.join(__dirname, src || '')
res.setHeader('Access-Control-Allow-Origin', '*')
fs.stat(filePath, (err, stats) => {
if (!err && stats.isFile()) {
fileReader(res, filePath)
} else {
res.setHeader('Content-Type', 'application/json;charset=utf-8')
res.end(JSON.stringify({
code: 400, msg: '文件读取失败', err: err || '不存在这个文件' }))
}
})
})
const fileReader = (res, filePath) => {
fs.readFile(filePath, (err, data) => {
res.setHeader('Content-Type', mime.getType(filePath))
res.end(data)
})
}
server.listen(3000, () => {
console.log('成功启动服务,端口3000')
})
前端
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="referrer" content="no-referrer">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Title</title>
<script src="https://6368-chengqige-7gunki87efeca981-1302748923.tcb.qcloud.la/node/code/FileSaver.min.js"></script>
<script src="https://6368-chengqige-7gunki87efeca981-1302748923.tcb.qcloud.la/node/code/axios.min.js"></script>
</head>
<body>
<button onclick="downloads()">下载文件</button>
<script>
// 使用前需要启动node.js服务在项目目录下node index.js
function downloadFile (fileStream, saveFileName) {
return new Promise((resolve) => {
const blob = new Blob([fileStream])
if (navigator.msSaveBlob) {
navigator.msSaveBlob(blob, saveFileName)// 兼容IE
} else {
const url = window.URL.createObjectURL(blob)
saveAs(url, saveFileName)
}
resolve()
})
}
function downloads () {
// 直接在浏览器访问http://localhost:3000?src='/img/byte.png',会显示图片不会下载,因为图片是浏览器支持的媒体类型
axios.get('http://localhost:3000', {
responseType: 'blob',
responseEncoding: 'utf-8',
params: {
src: '/img/byte.png'
}
}).then(res => {
downloadFile(res.data, '下载bytedance.png')
})
}
</script>
</body>
</html>
!> mime这个库不是node.js的基本库,需要自行使用npm安装,npm install mime -S。文件下载这个服务使用起来也很容易,只需要在浏览器地址栏输入:http://localhost:3000?src=文件相对路径即可
!> 启动这个服务后你会发现浏览器无法识别的文件会自动下载,浏览器可以识别的文件则直接在浏览器中显示了,如果你想用前端代码实现下载逻辑,请使用fileSaver.js;本项目案例采用axios.js进行后端接口的调用,如果没有了解过axios可以点击链接学习。
!> 源代码中,代码文件中的index.html就是前端调用服务下载文件的例子,可以参照学习。
实现静态资源服务器
node.js可以实现一个静态资源服务器,实现原理很简单,就是返回正确的content-type和二进制文件流给浏览器,让浏览器正确解析并显示页面。
静态资源服务器支持所有文件类型,浏览器能解析的文件类型将会展示到客户端,浏览器不能支持的文件类型会直接下载文件。
对于office文件的展示,建议使用online的office工具microsoft提供的在线office工具,那么它的使用方法也很简单只需要提供网络资源路径作为参数进行传递即可。
const fs = require('fs')
const http = require('http')
const path = require('path')
const mime = require('mime')
const chalk = require('chalk')
async function dataLoader (filePath) {
const fileType = await getFileType(filePath)
var _data = '没有找到资源,资源可能移动或删除', _type = 'text/txt'
switch (fileType) {
// 没有找到资源
case 0:
console.log('没有找到资源=>', filePath)
// 文件
case 1:
_data = await getResource(filePath)
_type = mime.getType(filePath)
break
// 目录
case 2:
_data = await getResource(filePath + '/index.html')
_type = mime.getType(filePath)
break
// 资源没有找到
default:
console.log('500', '没有这个参数')
}
return new Promise(resolve => {
resolve({
data: _data,
type: _type
})
})
}
// 获取文件类型 0-不存在 1-是文件 2-是目录
function getFileType (filePath) {
return new Promise(resolve => {
fs.stat(filePath, (err, stats) => {
err ? resolve(0) : stats.isFile() ? resolve(1) : resolve(2)
})
})
}
function getResource (filePath) {
return new Promise(resolve => {
fs.readFile(filePath, (err, data) => {
err ? resolve(null) : data ? resolve(data) : resolve(null)
})
})
}
function pathRewrite (req, res) {
const regExp = /\/[^.?\/]+$/
if (regExp.test(req.url) && req.method.toUpperCase() === 'GET') {
res.writeHead(302, {
'Location': `${
req.url}/`
})
res.end()
return true
}
return false
}
function server (port, folder = './dist') {
http.createServer(async (req, res) => {
if (pathRewrite(req, res)) {
return
}
const filePath = req.url == '/' ? path.join(__dirname, folder) : path.join(__dirname, folder, req.url)
const {
data, type } = await dataLoader(filePath)
res.setHeader('Content-Type', type + ';charset=utf8')
res.end(data)
}).listen(port, () => {
console.log(chalk.green('server is running at http://localhost:' + port))
})
}
server(3000)
核心代码解读
_type = mime.getType(filePath)
res.setHeader('Content-Type', type + ';charset=utf8')
!> 上面这段代码我们使用了mime这个npm库,它可以根据文件的路径快速返回这个文件的媒体类型,把它作为content-type返回给浏览器,浏览器才会进行正确的解析。
function getResource (filePath) {
return new Promise(resolve => {
fs.readFile(filePath, (err, data) => {
err ? resolve(null) : data ? resolve(data) : resolve(null)
})
})
}
!> 这段代码非常关键,它可以把读取的数据以二进制流的方式进行返回
function pathRewrite (req, res) {
const regExp = /\/[^.?\/]+$/
if (regExp.test(req.url) && req.method.toUpperCase() === 'GET') {
res.writeHead(302, {
'Location': `${
req.url}/`
})
res.end()
return true
}
return false
}
!> 这个正则表达式的匹配含义指的是,如果遇到/aaa、/xxx等后面没有/的路径,自动添加/,以免出现路径拼接的问题,例如如/xxx和/xxx/分别于aa拼接的结果是:/xxxaa和/xxx/aa,显然后者是对的,前者会找不到路径/xxxaa不存在,原因就是省略了/的烦恼。
当然这个只适用于GET请求,POST请求则不需要这样设置,因为POST请求请求的是服务端接口,随意重定向会使得路径错误进而返回不了资源
node.js爬虫
node.js可以用来搭建爬虫服务,这个爬虫服务是基于axios作为网络请求工具,cheerio进行文档解析工具。axios是一个强大的http请求库,在浏览器端基于XMLHttpRequest进行编写,在node端基于http.request进行编写,可以应用在node端和浏览器端。cheerio是基于jQuery开发的解析文档结构的库,其语法和jQuery一样。
首先jQuery大家可能忘记怎么使用了,这里带领大家回忆一下,因为一会儿解析文档需要用到jQuery
简单的jQuery语法:
// 选中元素
$('.container')
// 获取元素内部文本
$('.text').text()
// 获取元素属性
$('.prop').attr('src')
// 在筛选元素的基础上进行二次节点查找
$('.fisrt').find('.second')
// 进行节点循环
$('ul>li').each((index,item)=>{
})
node.js爬虫案例
下面我们就会使用node.js做一个爬虫案例,那么做爬虫一般有两个思路:第一种比较简单,就是先获取整个网站的HTML文档,然后通过jQuery进行标签解析,解析出标签的属性值(比如img的src)和标签内包含的文字进而实现内容的提取;第二种就是解析网络请求的原子操作,通过依次请求远程网络接口来实现内容的提取。
第一种办法适用于SSR(服务端渲染)的网站,这种网站是由服务端渲染好静态页面返回给浏览器完整的前端页面,是前后端不分离的项目,目前京东在使用SSR技术,大家熟知的JSP和PHP也都是这种技术,使用服务端渲染使得SEO优化变好,但是容易被爬虫抓取。
第二种办法适用于CSR(客户端渲染)的网站,这种网站需要进行接口的解析才能实现爬虫的运作,因为不是服务端渲染,所以直接抓取页面可能什么也获取不到,因为CSR(客户端渲染)是前后端分离的项目,前端那个时候还没有发送ajax返回数据渲染,所以自然返回的页面是空白页,那么这个时候我们只能解析原子操作,也就是解析接口。我们通过请求一个个接口来实现用户的注册,登录,购买等操作。这种爬虫思路的执行难度较大,需要考察程序员解析网络请求和查看源码的功底。
!> 爬虫不止于获取,还可以模拟提交,修改等操作。也就是说正常网页可以做的事情,爬虫都能用程序去做。所以爬虫有时候也叫作脱机挂
京东商品列表
我们采用第一种爬虫思路,爬取京东商城,苹果笔记本电脑的商品列表数据(1-100页,共3000件商品)
爬取链接:Mac笔记本商品列表
爬虫思路:先抓取整个页面的HTML文档,然后用jQuery解析
const fs = require('fs')
const path = require('path')
const axios = require('axios')
const cheerio = require('cheerio')
const globalData = []
function requestHTMLDocument (url) {
return new Promise(resolve => {
axios.get(url).then(res => {
resolve(res.data)
})
})
}
function fileSaver (data, filename = 'doc', extent = '.html') {
const filePath = path.join(__dirname, './output/', filename + extent)
try {
if (!fs.existsSync('./output')) {
fs.mkdirSync('./output')
}
fs.writeFileSync(filePath, data)
} catch (e) {
throw e
}
}
function dataParser (doc) {
const $ = cheerio.load(doc)
const shopElements = $('.gl-warp').find('li')
const shopList = []
shopElements.each(function () {
let pic = $(this).find('.p-img img')
let price = $(this).find('.p-price')
let name = $(this).find('.p-name em')
let shop = $(this).find('.p-shop a')
shopList.push({
pic: pic.attr('data-lazy-img'),
price: price.text().trim(),
name: name.text().trim(),
shop: shop.text().trim()
})
})
globalData.push(...shopList)
}
async function crawler (page = 1) {
try {
var document = await requestHTMLDocument(encodeURI('https://search.jd.com/Search?keyword=苹果笔记本&page=' + page))
} catch (err) {
document = '请求错误' + err
}
dataParser(document)
}
async function run () {
for (let i = 1; i <= 100; i++) {
console.log('正在爬取苹果笔记本第' + i + '页商品数据')
await crawler(i)
}
fileSaver(JSON.stringify(globalData), 'shopData', '.json')
console.log('爬取完毕,共获取商品数据:' + globalData.length + '个')
return globalData
}
// 启动爬虫服务
run()
这样我们在output文件夹中可以看到我们爬取的商品数据了
腾讯校招宣传视频
腾讯校招的宣传视频,当你按下F12的时候你试图去偷取video标签下的视频,你会发现它会返回403的状态码。这是因为腾讯启用了refer验证,也就是说如果你发起请求的源不是tencent.com,那么就会被禁止。
所以我们要使用node.js去伪造请求,由于node.js是服务端,所以伪造请求就是一件很容易的事情了。
需要爬取的宣传视频:宣传视频链接
校招官网:腾讯校招
const Axios = require('axios')
const fs = require('fs')
const path = require('path')
async function downloadFile(url, filepath) {
if (!fs.existsSync(filepath)) {
fs.mkdirSync(filepath);
}
const mypath = path.resolve(filepath, url.split('/').pop());
const writer = fs.createWriteStream(mypath);
const response = await Axios({
url,
method: "GET",
responseType: "stream",
headers:{
Referer: "https://join.qq.com/"
}
});
response.data.pipe(writer);
return new Promise((resolve, reject) => {
if(response.code===403) reject('没有权限呀')
writer.on("finish", ()=>{
resolve('下载成功了')
});
writer.on("error", ()=>{
reject('失败了')
});
});
}
if(!fs.existsSync('./video')){
fs.mkdirSync('./video')
}
downloadFile('https://cdn.multilingualres.hr.tencent.com/joinqq/static/video/video-banner.m4v','./video').then(res=>{
console.log(res)
}).catch(err=>{
console.log(err)
})
nodejs数据库编程
在本教程中我们以MongoDB作为数据库进行学习,MongoDB是一种NoSQL数据库,也就是非关型数据库。常见的NoSQL数据库类型有:文档型、键值对型、对象存储、图存储、列存储、XML存储。我们的MongoDB属于文档存储型数据库。
安装MongoDB
我们首先需要安装MongoDB数据库,点击这里可以下载安装。但是需要注意的是,不要勾选安装Compass,因为如果在国内环境下载它会感觉很慢。
安装Compass
Compass是MongoDB的可视化数据操作界面,使用它之后操作数据库会有很大的效率提升。点击这里下载安装。
nodejs操作数据库
下面我们使用nodejs来操作数据库,实现数据库的增删查改。
准备工作
# 使用npm安装操作数据库的包,mongoose
# mongoose中文文档地址:http://www.mongoosejs.net/
npm i mongoose --save
!> 如果没有初始化npm的话记得先npm init
插入数据
const mongoose = require('mongoose')
const Schema = mongoose.Schema
const {
String, Boolean } = Schema.Types
// 连接数据库,最后面的node_mongo是数据库名字。如果没有这个数据库,mongodb会自己创建
mongoose.connect('mongodb://127.0.0.1:27017/node_mongo').then()
// 定义表中的数据类型
const Todo = Schema({
todo: String,
isDone: Boolean
})
// 创建表(没有则创建,有则直接使用)
const todoTable = mongoose.model('todo', Todo)
// 创造一条数据
const todo = new todoTable({
todo: '添加记录', isDone: true })
// 保存数据到表格(插入一条数据1)
todo.save().then(res => {
console.log(res, '添加记录成功')
})
// 插入多条数据
todoTable.insertMany([{
todo: '数据1',
isDone: true
}, {
todo: '数据2',
isDone: false
}]).then(r => {
console.log(r, '批量插入成功')
})
删除数据
const mongoose = require('mongoose')
const Schema = mongoose.Schema
const {
String, Boolean } = Schema.Types
mongoose.connect('mongodb://127.0.0.1:27017/node_mongo').then()
const Todo = Schema({
todo: String,
isDone: Boolean
})
const todoTable = mongoose.model('todo', Todo)
// 删除一条记录
todoTable.deleteOne({
todo:'数据1'}).then(r=>{
console.log(r,"删除成功")
})
!> deleteOne只能删除1条记录,如果想删除所有符合条件的记录请使用deleteMany
查询数据
const mongoose = require('mongoose')
const Schema = mongoose.Schema
const {
String, Boolean } = Schema.Types
mongoose.connect('mongodb://127.0.0.1:27017/node_mongo').then()
const Todo = Schema({
todo: String,
isDone: Boolean
})
const todoTable = mongoose.model('todo', Todo)
// 查询数据
todoTable.find().then(data=>{
console.log(data)
})
// 查询符合条件的数据
todoTable.find({
todo:'数据2'}).then(r=>{
console.log(r)
})
修改数据
const mongoose = require('mongoose')
const Schema = mongoose.Schema
const {
String, Boolean } = Schema.Types
mongoose.connect('mongodb://127.0.0.1:27017/node_mongo').then()
const Todo = Schema({
todo: String,
isDone: Boolean
})
const todoTable = mongoose.model('todo', Todo)
// 修改数据
todoTable.updateOne({
todo:'数据2'},{
todo:'修改后的数据'}).then(res=>{
console.log(res)
})
!> 如果想修改所有符合条件的数据请使用updateMany
其实mongodb还有很多高级操作,如:关联查询,聚合查询,管道处理,对象/数组操作,深度对象修改操作等。在本nodejs教程中就不再讲述了,大家感兴趣的话可以看下下面几个博客。
!> 如果想进行正则表达式的模糊查询,请百度搜索mongodb $regex操作符