目录
一、QT 的信号和槽机制的理解
二、QT 的线程的使用
三、QT 样式表和选择器
四、QT 的 STL 和 C++的 STL 有什么区别?
五、什么是野指针?
六、长连接和短连接
七、客户端掉线和服务端掉线检测
八、哈希表有什么特点 ?
九、子进程继承父进程的哪些资源?
十、为什么选择共享内存?
十一、Linux 下如何调试?
十二、大量客户端连上来,服务器如何处理?
十三、http 协议
十四、大端模式和小端模式
十五、C++静态库和动态库的区别?
十六、双向链表如何实现?
十七、ffmpeg如何实现编码?
十八、ffmpeg如何实现解码?
十九、ffmpeg如何实现转码?
二十、MVC框架
一、QT 的信号和槽机制的理解
Qt 提供了信号和槽机制用于完成界面操作的响应,是完成任意两个 Qt 对象之间的通信机制。 其中,信号会在某个特定情况或动作下被触发,槽是等同于接收并处理信号的函数。
信号槽机制与回调的区别:
1.回调函数的本质是“你想让别人的代码执行你的代码,而别人的代码你又不能动”这种需求下产生的。回调函数是函数指针的一种用法,如果多个类都关注某个类的状态变化,此时需要维护一个列表,以存放多个回调函数的地址。对于每一个被关注的类,都需要做类似的工作,因此这种做法效率低,不灵活。
2.Qt 使用信号与槽机制来解决这个问题,程序员只需要指定一个类含有哪些信号函数、哪些槽函数,Qt 会处理信号函数和槽函数之间的绑定。当信号函数被调用时,Qt 会找到并执 行与其绑定的槽函数。允许一个信号函数和多个槽函数绑定,Qt 会依次找到并执行与一个 信号函数绑定的所有槽函数,这种处理方式更灵活。
3.Qt 信号与槽机制降低了 Qt 对象的耦合度。激发信号的 Qt 对象无须知道是哪个对象的哪 个槽需要接收它发出的信号,它只需要做的是在适当的时间发送适当的信号就可以了,而不 需要知道也不关心它的信号有没有被接收到,更不需要知道哪个对象的哪个槽接收到了信 号。同样地,对象的槽也不知道是哪些信号关联了自己,而一旦关联信号和槽,Qt 就保证 了适合的槽得到了调用。即使关联的对象在运行时被删除。应用程序也不会崩溃。
二、QT 的线程的使用
QThread 类提供了一个与平台无关的管理线程的方法。一个 QThread 对象管理一个线程。QThread 的执 行从 run()函数的执行开始,在 Qt 自带的 QThread 类中,run()函数通过调用 exec()函数来启动事件循环机 制,并且在线程内部处理 Qt 的事件。在 Qt 中建立线程的主要目的就是为了用线程来处理那些耗时的后台操作,从而让主界面能及时响应用户的请求操作。
1. 自定义一个继承 QThread 的类 MyThread,重载 MyThread 中的 run()函数,在 run()函数中写入需 要执行的工作
2. 调用 start()函数来启动线程
三、QT 样式表和选择器
Qt
样式表是另外一种自定义部件外观的机制,使用样式表可以更方便的设置界面的外观,而不用去子类化 QStyle 类
四、QT 的 STL 和 C++的 STL 有什么区别?
C++
中容器类是属于标准模板库中的内容 Qt 提供了它自己的一套容器类,这就是说,在
Qt
的应用程序中,我们可以使用标准
C++
的
STL
,也可以 使用 Qt
的容器类。
Qt 容器类的好处在于,它提供了平台无关的行为,以及隐式数据共享技术。
区别:
1.STL
的
vector
最开始分配的空间是
1
个,而
QVector
开始分配的空间为
4
个(可见
QT
在空间分配上的优化)
2.STL
的
vector
发生超过容量本身的访问,并不一定失败(因为内存可能足够大并存在),而
QVector则发生了断言错误。而显然,第二种处理方式会更好。而第一种可能会造成莫名其妙的错误,尤其是当工程师忘记 vector
的范围,而
vector
本身并不出错的时候。
显然,
QT
的容器基于
STL
进行了升级。如果有类似于
QT
的容器之类的容器,优先选择更好的容器;而如果使用 STL
,要知道
STL
这种特点,并避免这类事情发生。
五、什么是野指针?
野指针:
指向内存被释放的内存或者没有访问权限的内存的指针。
“野指针”的成因主要有 3 种:
1.指针变量没有被初始化。
2.指针 p 被 free 或者 delete 之后,没有置为 NULL。
3.指针操作超越了变量的作用范围。
六、长连接和短连接
短连接:
连接
->
传输数据
->关闭连接。
HTTP
是无状态的,浏览器和服务器每进行一次
HTTP
操作,就建立一次连接,但任务结束后就中断连接。
短连接是指
SOCKET
连接后发送后接收完数据后马上断开连接。
长连接:
连接
->
传输数据
->
保持连接
->
传输数据
->....->关闭连接。
长连接指建立
SOCKET
连接后不管是否使用都保持连接,但安全性较差。
七、客户端掉线和服务端掉线检测
socket 中用心跳包检测客户端与服务端掉线状况
。
心跳包:
它像心跳一样每隔固定时间发一次,以此来告诉服务器,这个客户端还活着。事实上这是为了保持长连接,至于这个包的内容,是没有什么特别规定的,不过一般都是很小的包,或者只包含包头的一个空包。
心跳检测步骤:
1 客户端每隔一个时间间隔发生一个探测包给服务器。
2 客户端发包时启动一个超时定时器。
3 服务器端接收到检测包,应该回应一个包。
4 如果客户机收到服务器的应答包,则说明服务器正常,删除超时定时器。
5 如果客户端的超时定时器超时,依然没有收到应答包,则说明服务器挂了。
八、哈希表有什么特点 ?
哈希表(
Hash Table,也叫散列表),是根据关键码值 (Key-Value) 而直接进行访问的数据结构。也就是 说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。哈希表的实现主要需要解决 两个问题,哈希函数和冲突解决。
特点:
1.
哈希表的查找效率主要取决于构造哈希表时选取的哈希函数和处理冲突的方法。
2.
在各种查找方法中,平均査找长度与结点个数
n
无关的查找方法是哈希表查找法。
3.
哈希函数取值是否均匀是评价哈希函数好坏的标准。
4.
哈希存储方法只能存储数据元素的值,不能存储数据元素之间的关系。
5.
哈希表的装填因子
a<l
,并不可以避免冲突的产生。
九、子进程继承父进程的哪些资源?
在
Linux
系统内,创建子进程的方法是使用系统调用
fork()
函数。
fork()
函数是
Linux
系统内一个非常重要 的函数,它与我们之前学过的函数有一个显著的区别:fork()函数调用一次却会得到两个返回值。
fork()
函数用于从一个
已经存在
的进程内创建一个新的进程,新的进程称为
“
子进程
”
,相应地称创建子进程的进程为“
父进程”。
使用
fork()
函数得到的子进程是父进程的复制品,
子进程完全复制了父进程的资源, 包括进程上下文、代码区、数据区、堆区、栈区、内存信息、打开文件的文件描述符、信号处理函数、进程优先级、进程组号、当前工作目录、根目录、资源限制和控制终端等信息,而子进程与父进程的区别有进程号、资源使用情况和计时器等
。
十、为什么选择共享内存?
共享内存:
顾名思义就是允许两个不相关的进程访问同一个逻辑内存,共享内存是两个正在运行的进程之间共享和传递数据的一种非常有效的方式。
优点:
我们可以看到使用共享内存进行进程之间的通信是非常方便的,而且函数的接口也比较简单,数据
的共享还使进程间的数据不用传送,而是直接访问内存,加快了程序的效率。
十一、Linux 下如何调试?
逻辑错误用
log
,内存错误用
gdb
,单元测试用
gtest
,编译器用
clang
,
log
框架用
log4cplus,性能热点用 gprof。
十二、大量客户端连上来,服务器如何处理?
这时候服务器端应该使用多线程,每连接上一个客户端就给该客户端开启一个线程。监听端口的时候也要单独开一个线程、不然会阻塞主线程。这样做有一个明显的缺点,就是有 N
个客户端请求连接时,就会有 N 个线程,对程序的性能和计算机的性能影响很大,可以使用线程池进行管理。
使用线程池的好处:
主要用于减少因频繁创建和销毁线程带来开销,因此那些经常使用且执行时间短的 线程需要用线程池来管理。
十三、http 协议
对器客户端和 服务器端之间数据传输的格式规范,格式简称为“超文本传输协议”。
十四、大端模式和小端模式
主机字节序就是我们平常说的大端和小端模式:不同的
CPU
有不同的字节序类型,这些字节序是指整数在 内存中保存的顺序,这个叫做主机序。
引用标准的 Big-Endian 和 Little-Endian 的定义如下:
1.Little-Endian 就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
2. Big-Endian 就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
十五、C++静态库和动态库的区别?
二者的不同点在于
代码被载入的时刻不同
。
静态库:
在程序编译时会被连接到目标代码中,程序运行时将不再需要该静态库,
因此体积较大
。
动态库:
在程序编译时并不会被连接到目标代码中,而是在程序运行是才被载入,因此在程序运行时还需
要动态库存在,
因此代码体积较小
。
动态库的好处:
不同的应用程序如果调用相同的库,那么在内存里只需要有一份该共享库的实例。
十六、双向链表如何实现?
双向循环链表:
即在单链表
(
上文描述的链表为单链表
)
的基础上进行改进,每个结点不光有存储下一个 结点地址的指针域 next
,还增加了存储上一个结点地址的指针域
prev
,其中头
(
第一个结点
)
的
prev
指向尾结点(
最后一个结点
)
,尾结点的
next
指向头结点。
实现:
在操作时创建
temp
指针指向链表中各元素,更改
prev
及
next
指向的结点就可以实现对链表的 基本增删查改等操作。
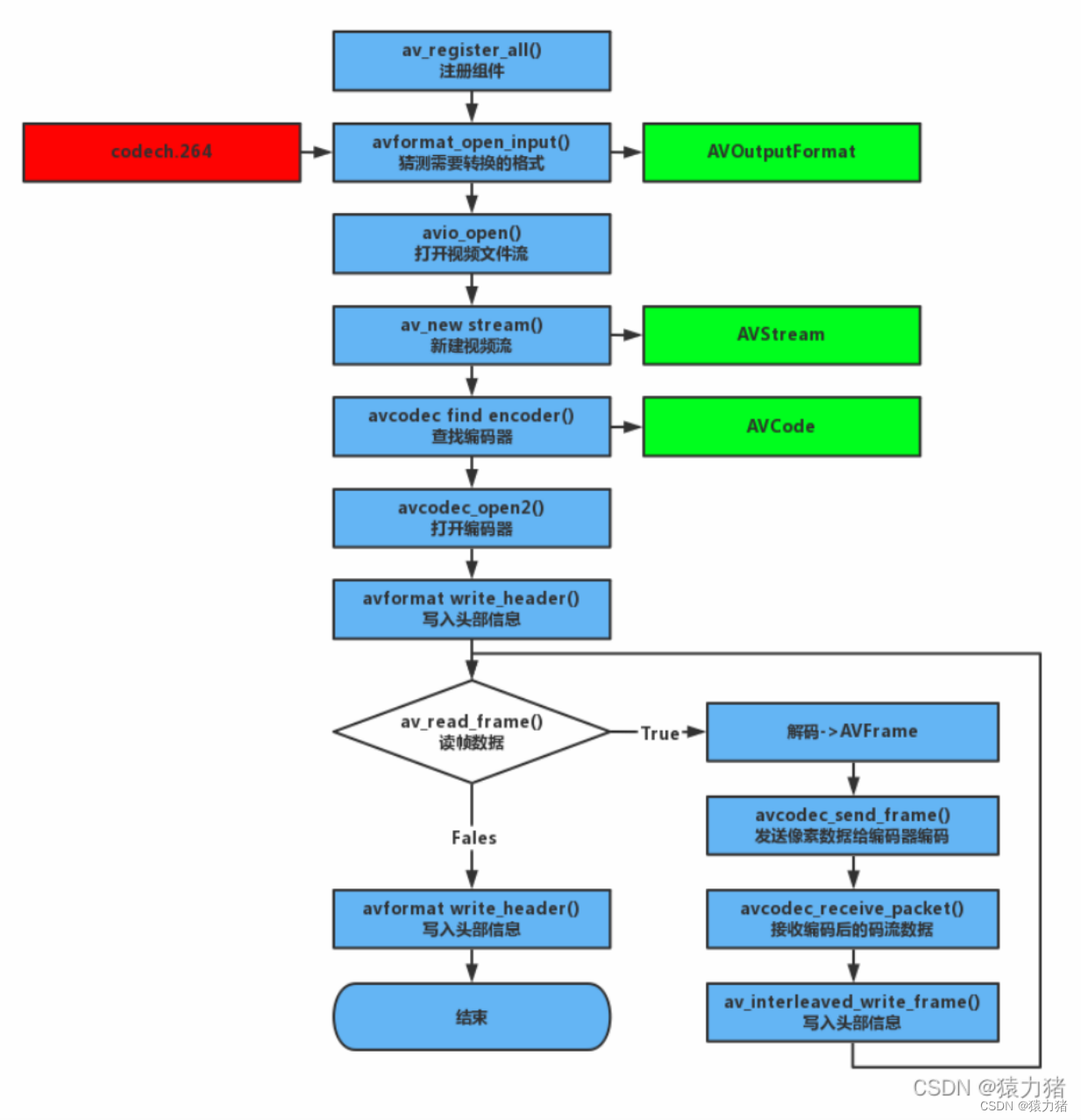
十七、ffmpeg如何实现编码?
编码思路分析:
1.注册所有的组件
2.根据需要的码流数据的格式,来猜测的需要的编码器
3.打开目标文件流
4.新建视频流
5.设置编码器上下结构的一系列参数,为编码做好准备
6.查找对应的编码器
7.打开编码器
8.读取普通视频数据 or 摄像头数据,进行解码,保证得到的是YUV的像素数据
9.先写入编码的头部信息
10.正式开始,进行编码,将一帧像素数据压缩成码流数据
11.保存写入文件中
12.得到最终的编码后的码流数据
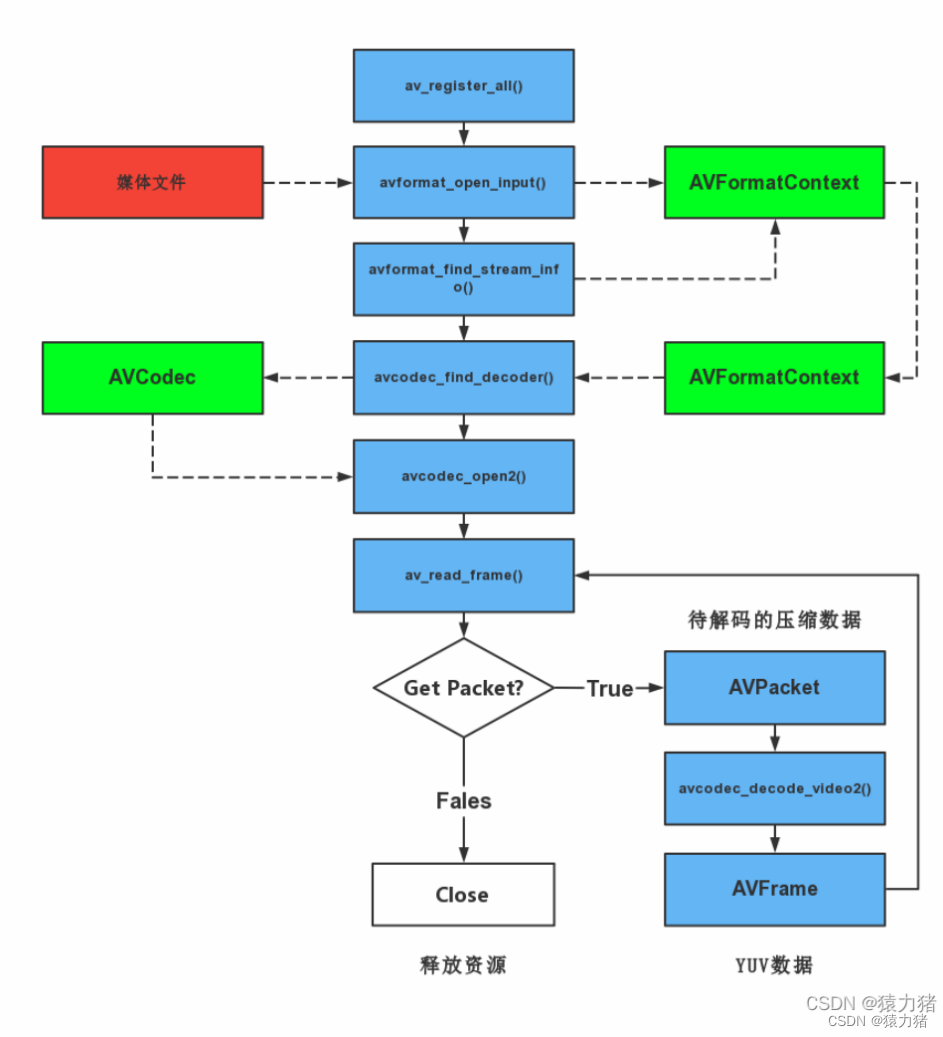
十八、ffmpeg如何实现解码?
解码思路分析:
1.注册所有的组件 av_register_all()
2.打开视频文件 avformat_open_input() 有可能打开失败
3.获取视频信息 视频码流、音频码流、文字码流
4.查找流信息 avformat_find_stream_info()
5.找到解码器 avcodec_find_decoder() 有可能没找到
6.打开解码器 avcodec_open2()
7.读取码流中的一帧码流数据 av_read_frame()
8.解码读到一帧码流数据 得到一帧的像素数据 YUV RGB
9.重复7-8的动作 直到视频所有的帧都处理完
10.关闭解码器
11.关闭视频文件
十九、ffmpeg如何实现转码?
转码思路分析:
1.注册组件
2.打开视频流 打开视频文件
3.查找有没有流数据
4.查找视频码流数据
5.根据要的封装格式 来猜测格式对应编辑器
6.打开对应文件
7.新建流
8.写入头部信息
9.读取一帧一帧的码流数据
10.转码---->时间基的转化
11.写入对应的一帧数据到文件中

二十、MVC框架
MVC框架能够将业务进行分离,数据和界面进行分离,在团队项目中容易分工各个模块给不同的人员。
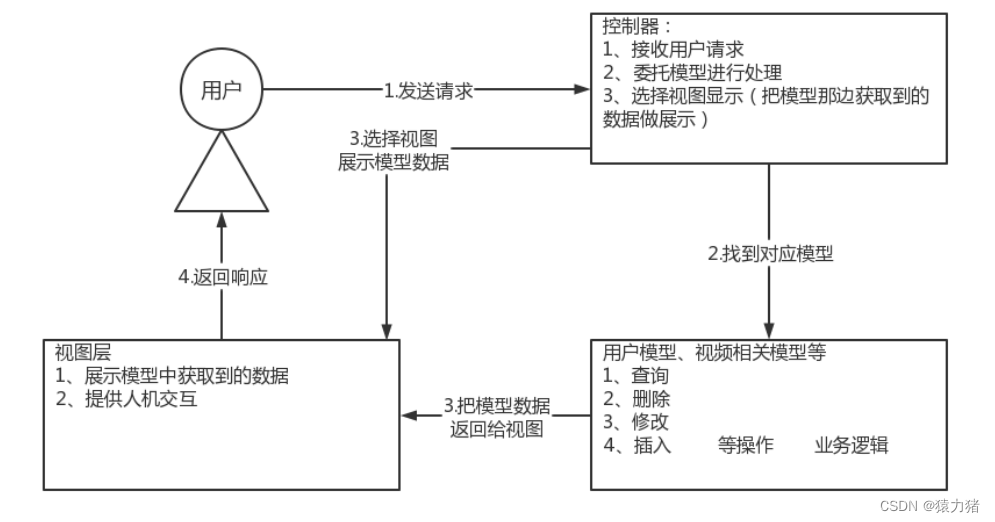
使用MVC架构模拟用户登录的流程:
举例 用户登录界面:
1、发送请求到控制器。
2、控制器委托用户模型去做用户数据的查询。
3、用户模型查询用户表得到结果。
4、用户模型把查询到的结果返回给控制器。
5、控制器将用户模型返回的结果反馈给用户登录界面。
MVC的优点:
代码模块化,分工明确,提高工作效率。耦合性低,增加了组件的重用性,降低了维护成本。
MVC的缺点:
系统结构复杂,实现起来比较困难,所以小型项目不适用,只适合大型项目,view和controller联系过于紧密,mvc将其分离,导致应用的范围会受到限制,虽然mvc对代码进行了模块化处理,但是由于关联性,很难实现独立重用。