目录标题
前言
伴随着信息量的爆炸式增长,以及构建的应用系统越来越多样化、复杂化,特别是伴随着近年来企业级应用互联网化的超势,缓存(Cache)对应用程序性能的优化变得越来越重要。将所需服务请求的数据放到缓存中,既可以提高应用程序的访问效率,又可以减少数据库服务器的压力,从面让用户获得更为极致的体验。
Spring 开发者正是因为看到了缓存在应用中的重要地位,从 Spring 3.1 开始,就以一贯的优雅风格提供了一种透明的缓存解决方案,这使得 Spring 可以在后台使用不同的缓存框架( 如 EhCache、 GemFire、 HazelCast 和 Guava)时保持编程的一致性。而从 Spring4.0 开始则全面支持 JSR-107 annotations 和自定义的缓存标签。
一、缓存的概念
缓存作为系统架构中提升性能的一种重要支撑技术,在企业级应用中的地位越来越突显。
用过Maven 的朋友应该知道,在找依赖构件的时候,先从本机仓库找,如果没有再从本地服务器仓库找,最后才到远程服务器仓库找。所以可将缓存定文为一种 存储机制 ,它将数据保存在某个地方,并以一种更快的方式提供服务。较为常见的一种情况是在应用中使用缓存机制,以避免方法的多次执行,从而克服性能缺陷,也可减少应用服务器或者数据库的压力。
1.缓存策略选择
缓存的策略有很多种,在应用系统中可根据实际情况选择:
- 通常会把一些
静态数据或者变化频率不高的数据放到缓存中,如配置参数、字典表等。 - 而有些场景可能要寻求替代方案,比如,想提升全文检索的速度,在复杂的场景下建议使用
搜索引擎,如 Solr 或 ElasticSearch.
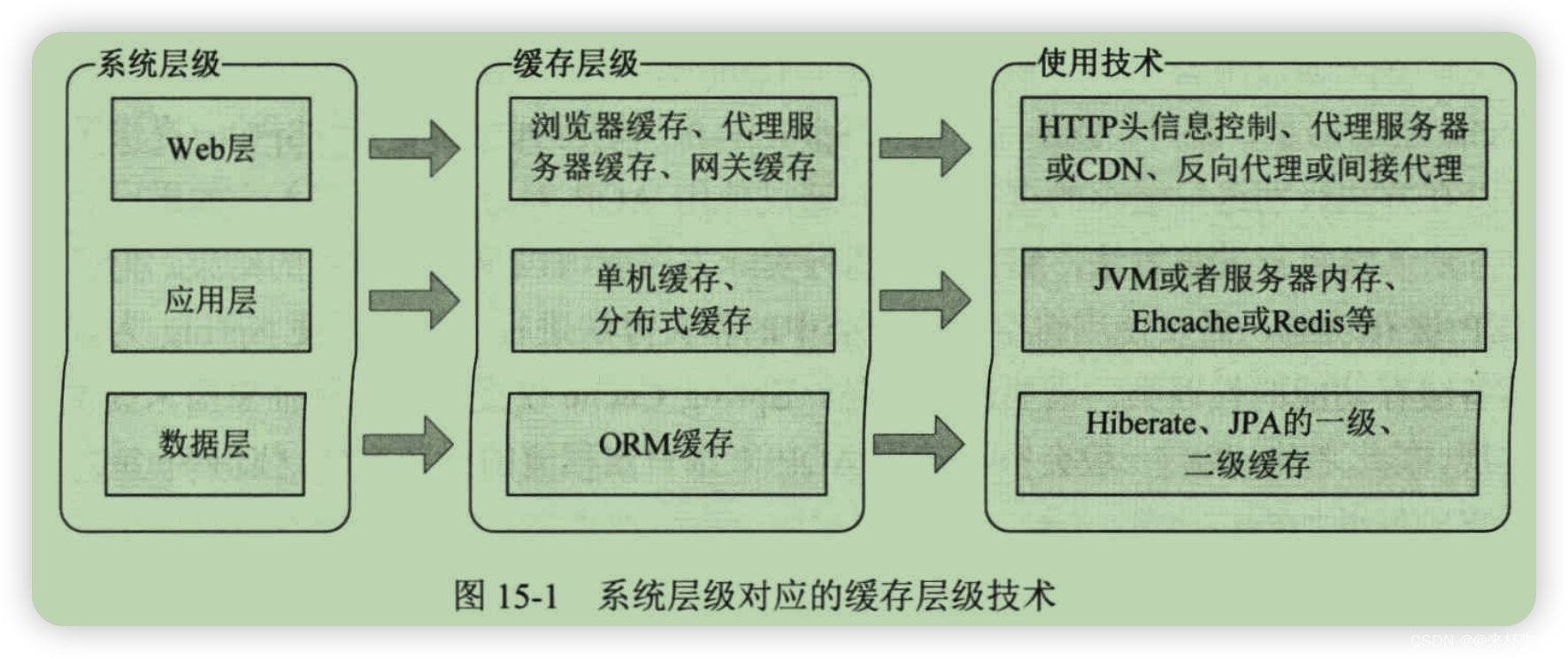
通常在 Web 应用开发中,不同层级对应的缓存要求和缓存策略全然不同。如图15-1所示列举了系统不同层级对应的缓存技术选型:
2.缓存中的重要概念
要了解缓存,必须对其中的一些基本概念有所了解。下面先来了解一下缓存中两个比较重要的基本概念。
1.缓存命中率
即从缓存中读取数据的次数与总读取次数的比率。一般来说,命中率越高越好。
命中率= 从缓存中读取的次数/(总读取次数[从缓存中读取的次数+从慢速设备上读取的次数])
Miss率 = 没有从缓存中读取的次数/(总读取次数[从缓存中读取的次数+从慢速设备上读取的次数)
这是一个非常重要的监控指标,如果要做缓存,就一定要监控这个指标,来看缓存是否工作良好。还是之前举的例子,假设京东的某个分仓库通过监控发现某个仓库的命中率一直很低,经常无法找到待发货的商品,那么这时候就需要调整策略,否则就会造成搏击里面“出拳百次,无一命中”的笑话。
2. 过期策略
即如果缓存满了,从缓存中移除数据的策略。常见的有 LFU、 LRU、 FIFO:
- FIFO (First In First Out):先进先出策略,即先放入缓存的数据先被移除。
- LRU (Least Recently Used):最久未使用策略,即使用时间距离现在最久的那个数据被移除。
- LFU (Least Frequently Used):最近最少使用策略,即一定时间段内使用次数(频率)最少的那个数据被移除。
- TTL (Time To Live):存活期,即从缓存中创建时间点开始直至到期的一个时间段(不管在这个时间段内有没有访问都将过期)。
TTI(Time To Idle):空闲期,即一个数据多久没被访问就从缓存中移除的时间。
至此,我们基本了解了缓存的一些基本知识。在 Java 中,一般会对调用方法进行缓存控制。比如调用“findUserByld(String id)”,应该在调用这个方法之前先从缓存中查找有没有符合查询条件的数据,如果没有,则执行该方法从数据库中查找该用户,然后添加到缓存中,下次调用时将会从缓存中获取该数据。
二、Spring Cache
从 Spring 3.1 开始,提供了类似于@Transactional 事务注解的缓存注解,且提供了Cache 层的抽象。此外,JSR-107 也从 Spring 4.0 开始得到全面支持。
1.Spring Cache介绍
1.底层-AOP
Spring提供了一种可以在方法级别进行缓存的缓存抽象:
- 通过使用 AOP 对方法进行织入,如果已经为特定方法入参执行过该方法,那么不必执行实际方法就可以返回被缓存的结果。
- 为了启用AOP 缓存功能,需要使用缓存注解对类中的相关方法进行标记,以便 Spring 为其生成具备缓存功能的代理类。
需要注意的是,Spring Cache 仅提供了一种抽象而未提供具体实现。在此之前,我们一般会自己使用 AOP 来做一定程度的封装实现。
2.使用好处
使用 Spring Cache带来的好处如下:
- 支持开箱即用 (Out-Of-The-Box),并提供基本的 Cache 抽象,方便切换各种底层 Cache。
- 类似于 Spring提供的数据库事务管理,通过 Cache 注解即可实现缓存逻辑透明化,让开发者关注业务逻辑。
- 当事务回滚时,缓存也会自动回滚。
- 支持比较复杂的缓存逻辑。 提供缓存编程的一致性抽象,方便代码维护。
3.注意事项
需要注意的是:
1、Spring Cache 并不针对多进程的应用环境进行专门的处理。也就是说,当应用程序处于分布式或者集群环境下时,需要针对具体的缓存进行相应的配置。如 EhCache 可以通过 RMI、JGroups 及 EhCache Server 等方式来配置其多播集群环境。
2、另外,在 Spring Cache 抽象的操作中没有锁的概念, 当多线程并发操作(更新或者删除)同一个缓存项时,将可能得到过期的数据。有些缓存实现提供了锁的功能,如果需要考虑如上场景,则可以详细了解具体缓存的一些相关特性,如 EhCache 就提供了针对缓存元素 key 的 Read(读)、Write(写)锁。
2.使用Spring Cache
这里先展示一个自定义的缓存实现,即不通过任何第三方组件来实现对象的内存缓存,然后通过 Spring Cache 来实现缓存操作,以体会 Spring Cache 所带来的优雅和便捷性。
1.POJO缓存与序列化的关系
Java 对象的缓存和序列化是息息相关的,一般情况下,需要被缓存的实体类需要实现 Seriaizable,只有实现了 Serializable 接口的类,JVM 才可以对其对象进行序列化。对于 Redis、 EhCache 等缓存套件来说,被缓存的对象应该是可序列化的,否则在网络传输、硬盘存储时都会抛出序列化异常。
实体类始终实现Serializable 接口是一个好的编程习惯。实现 Serializable 接口的实体类,一般要求声明一个 serialVersionUID 成员变量,以表明该实体类的版本。如果实体类的结构发生变化,则可以修改 serialVersionUID 值以支持反序列化工作。关于对象序列化和反序列化的更多知识,读者可自行查找相关资料学习,在此不再展开。
2.自定义缓存实现
书中手写缓存代码示例略。
3.Spring Cache方式实现缓存
略。
三、掌握Spring Cache抽象
1.缓存注解
2.缓存管理器
3.使用SpEL表达式
4.基于XML的Cache声明
5.以编程方式初始化缓存
在实际项目中,有时可能需要在使用之前就完成缓存的初始化。最典型的示例是当启动并且运行应用程序时将数据加载到缓存中。 实现该方法很简单,首先访问缓存管理器,然后将数据手工加载到不同的缓存中(这些缓存根据缓存名称进行区分)。在下面的示例中,当初始化应用程序上下文时,将用户列表加载到缓存区域中。
代码清单15-10 展示了在 Sping Bean 的@PostConstrut 注解方法中初始化缓存 users。
具体代码实现,请看书。
6.自定义缓存注解
四、配置 Cache 存储
在企业级应用中往往会有更复杂的功能和性能需求,所以在日常开发过程中,大部分情况下会使用第三方的缓存实现,而不是 SimpleCacheManager 的简单实现。在企业级 Java 领域,Spring缓存提供了与不同缓存框架的集成支持。
书中并没有过多的对下面几种存储方式做过多的介绍。
1.EhCache
2.Guava
3.HazelCast
4.GemFire
5.JSR-107 Cache
五、实战经验
Spring Cache使用实战经验,略。
总结
待补充。