Python自动下载论文
下载地址
http://dblp.uni-trier.de/db/conf/sigcomm/
目录
- 先上最终版本:
- 说说sigcomm上论文下载的姿势
- 中间的一些学习笔记:
- bug和debug
先上最终版本:
import urllib.request
import xlrd
def open_excel(file='sigcomm.xls'):
try:
data = xlrd.open_workbook(file)
return data
except Exception as e:
print(str(e))
# 根据索引获取Excel表格中的数据 参数:file:Excel文件路径 colnameindex:表头列名所在行 ,by_index:表的索引
def excel_table_byindex(file='sigcomm.xls', colnameindex=0, by_index=0):
data = open_excel(file)
table = data.sheets()[by_index]
nrows = table.nrows
filenames = []
urls = []
for rownum in range(1, nrows):
row = table.row_values(rownum)
if row:
filenames.append(row[0])
urls.append(row[1])
list = [filenames, urls] # url
return list
if __name__ == "__main__":
tables = excel_table_byindex() # 根据索引获取Excel表格中的数据
nrows = len(tables[1])
add=''
add1='C:\sd\PaperDownload\sigcomm\SDN\\'
add2='C:\sd\PaperDownload\sigcomm\Security\\'
add3= 'C:\sd\PaperDownload\sigcomm\VANET\\'
for i in range(nrows):
file_name = add+tables[0][i]+'.pdf'
url = tables[1][i]
u = urllib.request.urlopen(url)
f = open(file_name, 'wb')
block_sz = 8192
while True:
buffer = u.read(block_sz)
if not buffer:
break
f.write(buffer)
f.close()
print("Sucessful to download " + " " + file_name)
说说sigcomm上论文下载的姿势
0.首先把一年的所有的会议都打开,免得忘记点到那里了
1.打开pdf页面
2.复制名字和对应的下载链接(右键复制下载链接)
3.存储在excel表中,然后自动的下载
4.再excel中复制粘贴为文本格式之后 统一用格式刷刷一遍
中间的一些学习笔记:
爬虫学习笔记
1.最简单最轻量的 一般是打开默认的浏览器进行下载
下载文件保存在本地 运行完全没有问题
import urllib.request
file=urllib.request.urlopen('http://www.math.pku.edu.cn/teachers/lidf/docs/textrick/tricks.pdf')
data=file.read() #读取全部
dataline=file.readline() #读取一行内容
fhandle=open("./1.html","wb") #将爬取的网页保存在本地
fhandle.write(data)
fhandle.close()
2.由1变种过来
下载知网和其他pdf也ok
#sig网址上的论文
url='http://delivery.acm.org/10.1145/3100000/3098829/p85-Narayana.pdf?ip=125.220.159.2&id=3098829&acc=PUBLIC&key=BF85BBA5741FDC6E%2E4977B3C8BBB4AEC7%2E4D4702B0C3E38B35%2E4D4702B0C3E38B35&__acm__=1527593519_2daa7ced3fff47900a0622d05a294e21'
#知网上的论文
url='https://dl.acm.org/ft_gateway.cfm?id=3098829&ftid=1898917&dwn=1&CFID=38978589&CFTOKEN=543fd1d1c019d8fe-B082E90D-0F61-1190-2633B96718CFA3A9'
url2='http://kns.cnki.net/kns/download.aspx?filename=VYORHTaljMnRHV2J0N3RWcpBVZJ9kMrd1K6tSUxF0aqlkY1lDbLNzKxwWUkFENQRGTj9kMFNGOMdURrdkaLd3b=0TP3pnMSpUN2okWhlEVjRzT1EXORtyK34Wax90YktSTEp0Kr1GR5YFUlpHRvYEZUR2aqdjZFJFUXhFSmllVuZ&tablename=IPFDLAST2017&dflag=pdfdown'
file_name = "123.pdf"
u = urllib.request.urlopen(url2)
f = open(file_name, 'wb')
block_sz = 8192
while True:
buffer = u.read(block_sz)
if not buffer:
break
f.write(buffer)
f.close()
print("Sucessful to download sig" + " " + file_name)
3.最后的成功版本 其实就是版本1 在这里就是备份一下
url='http://delivery.acm.org/10.1145/3100000/3098829/p85-Narayana.pdf?ip=125.220.159.2&id=3098829&acc=PUBLIC&key=BF85BBA5741FDC6E%2E4977B3C8BBB4AEC7%2E4D4702B0C3E38B35%2E4D4702B0C3E38B35&__acm__=1527593519_2daa7ced3fff47900a0622d05a294e21'
# url2='http://kns.cnki.net/kns/download.aspx?filename=VYORHTaljMnRHV2J0N3RWcpBVZJ9kMrd1K6tSUxF0aqlkY1lDbLNzKxwWUkFENQRGTj9kMFNGOMdURrdkaLd3b=0TP3pnMSpUN2okWhlEVjRzT1EXORtyK34Wax90YktSTEp0Kr1GR5YFUlpHRvYEZUR2aqdjZFJFUXhFSmllVuZ&tablename=IPFDLAST2017&dflag=pdfdown'
file_name = "1234.pdf"
u = urllib.request.urlopen(url)
f = open(file_name, 'wb')
block_sz = 8192
while True:
buffer = u.read(block_sz)
if not buffer:
break
f.write(buffer)
f.close()
print("Sucessful to download sig" + " " + file_name)
有个问题就是:
虽然浏览器中可以打开得到pdf文件,但是程序好像不能下载了
这个的原理是不获取下载链接而是直接通过cnki进行下载?
他是如何得到下载链接的呢?
4.这个版本实现是通过关键字进行下载 他需要的下载C:\sd\python\chromedriver.exe
#!/usr/bin/env Python
# coding=utf-8
import os
from time import sleep
from selenium import webdriver
def browser_init(isWait):
options = webdriver.ChromeOptions()
prefs = {'profile.default_content_settings.popups': 0, 'download.default_directory': 'C:\\Users\\dell\\Desktop'}
options.add_experimental_option('prefs', prefs)
browser = webdriver.Chrome(executable_path='C:\sd\python\chromedriver.exe', chrome_options=options)
browser.set_window_size(500, 500)
if isWait:
browser.implicitly_wait(50)
return browser
def searchKey(keyword):
browser.get("http://kns.cnki.net/kns/brief/default_result.aspx") #中国知网文献检索
browser.find_element_by_id('txt_1_value1').send_keys(keyword) #搜索框的ID
browser.find_element_by_id('btnSearch').click() #搜索按钮的id
def switchToFrame(browser):
#print 'start switch'
browser.switch_to.frame('iframeResult') #默认是在父级Frame里面操作
#print 'end switch'
def getDownloadLinks(browser,paper_downloadLinks):
for link in browser.find_elements_by_css_selector('a[href^=\/kns\/detail]'): #提取了html语言中的href
#link.click()
url=link.get_attribute('href')
url_part = url.split('&')[3:6] #文章的名称? 只取3-6之间的三个元素
url_str= '&'.join(url_part)
down_url='http://kns.cnki.net/KCMS/detail/detail.aspx?'+url_str #生成了下载链接 很想知道这个下载链接是怎么来的
print(down_url)
paper_downloadLinks.append(down_url)
def switchToPage(browser,n):
for link in browser.find_elements_by_css_selector('a[href^=\?curpage]'):
url=link.get_attribute('href')
print(url)
pageInd='curpage=%d&'%n
print(pageInd)
if pageInd in url:
print("page: "+url)
link.click()
break
def switchNextPage(browser):
browser.find_element_by_link_text(u'下一页').click()
def do_download(driver,urls,fail_downLoadUrl):
for url in urls:
print(url)
driver.get(url) #因为它的链接中直接就是一个脚本 所以访问这个网址 就是下载
paper_title=driver.title
print("paper title"+paper_title)
if u'中国专利全文数据库' in paper_title:
continue
print("try download :"+paper_title)
try:
driver.find_element_by_xpath("//a[contains(text(),'PDF下载')]").click()
print("download success!!!")
except Exception as e:
try:
driver.find_element_by_xpath("//a[contains(text(),'整本下载')]").click()
print("download success!!!")
except Exception as e:
print("download fail!!!")
fail_downLoadUrl.append(url)
def usage():
print("example : python downloadCNKI.py -k keyword -p 1")
if __name__=="__main__":
keyword = u'math' #论文搜索的关键字
pageNum = 1 # 下载多少页的论文
browser = browser_init(True)
searchKey(keyword) #关键词搜索
switchToFrame(browser)
paper_downloadLinks = [] #列表 论文下载链接 一个下载链接一篇文章
curPage = 1 #下载起始页
# 下载文章的过程
while curPage<=pageNum:
getDownloadLinks(browser,paper_downloadLinks) #下载文件的过程
switchNextPage(browser);
curPage+=1
browser.quit()
print("采集了%d条数据",len(paper_downloadLinks))
driver=browser_init(False)
fail_downLoadUrl=[] #记录下失败的网站
do_download(driver,paper_downloadLinks,fail_downLoadUrl)
print(fail_downLoadUrl)
tryNum=0
#尝试最多5次重新下载没有下载成功的丢掉
while tryNum<5:
if len(fail_downLoadUrl) !=0:
paper_downloadLinks=fail_downLoadUrl
fail_downLoadUrl=[]
do_download(driver, paper_downloadLinks, fail_downLoadUrl)
print(fail_downLoadUrl)
else:
break
tryNum+=1
sleep(60)
driver.quit()
5.这是一些其他的版本(我想找个时间吃透一下)
#Python爬取arxiv的paper
http://gwang-cv.github.io/2016/04/01/Python%E7%88%AC%E5%8F%96arxiv%E7%9A%84paper/
bug和debug
1只有定位到相应的frame才能获得相应的元素的控制 所以有的时候 需要定位该元素是在哪个iframe
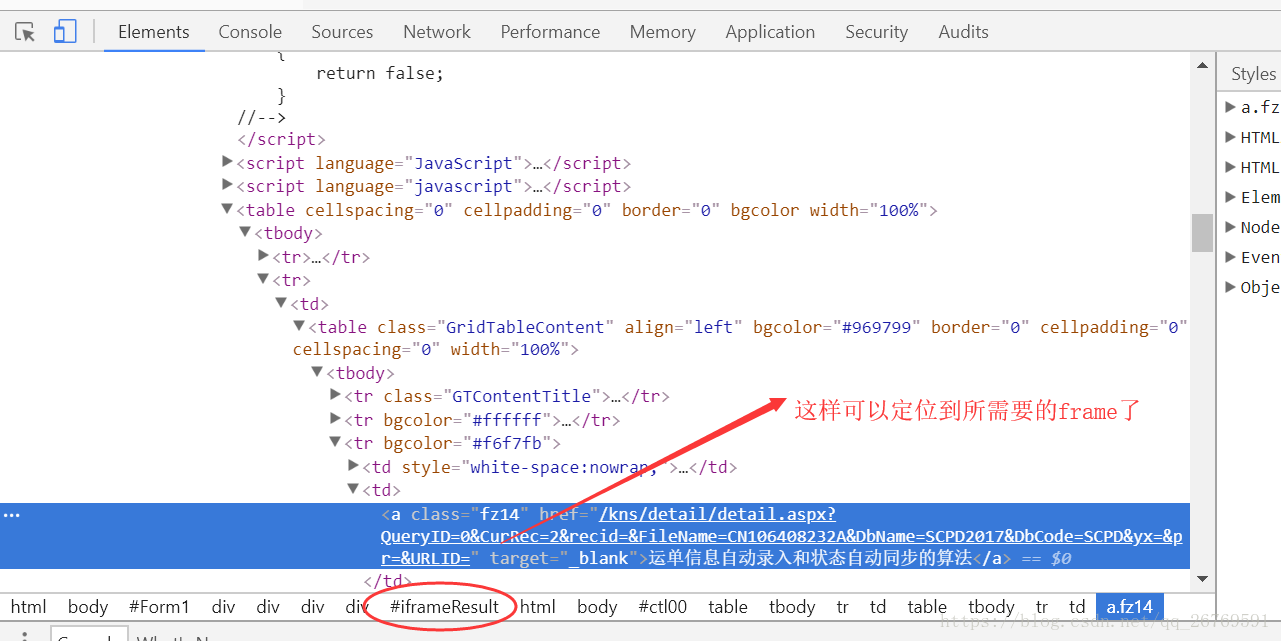
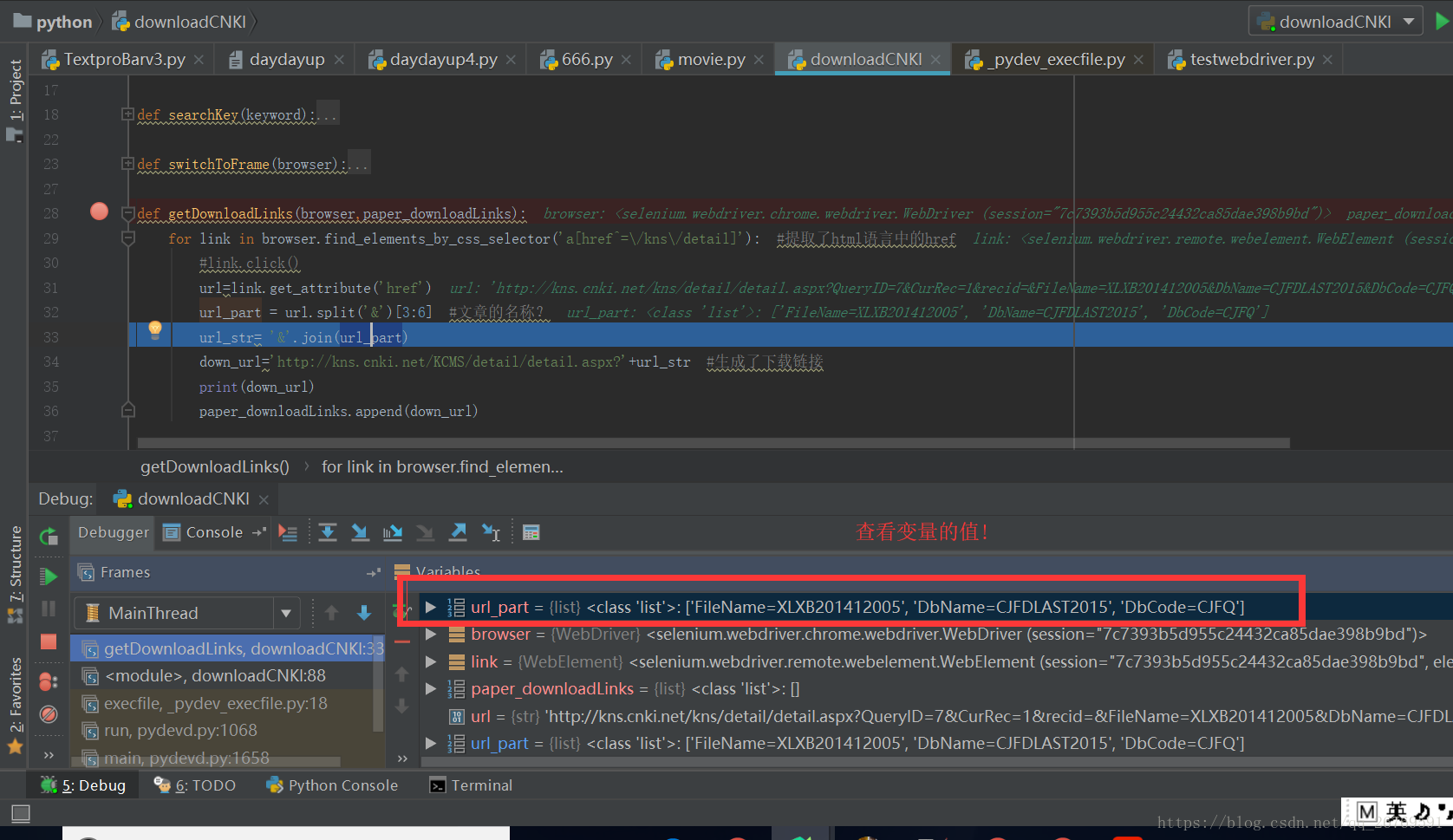
2 显示程序运行中的值
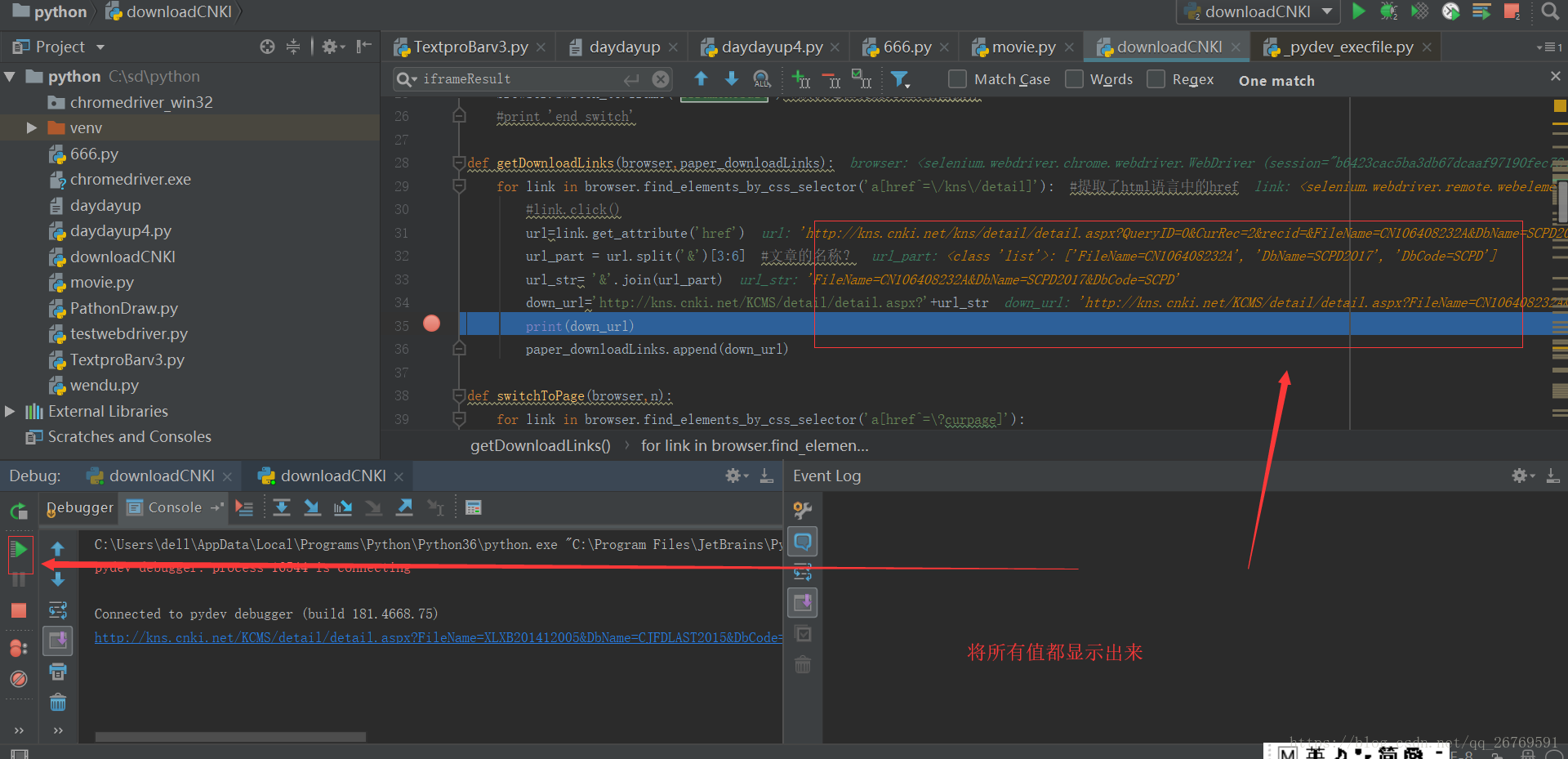
3.pycharm 提供cmd 控制台
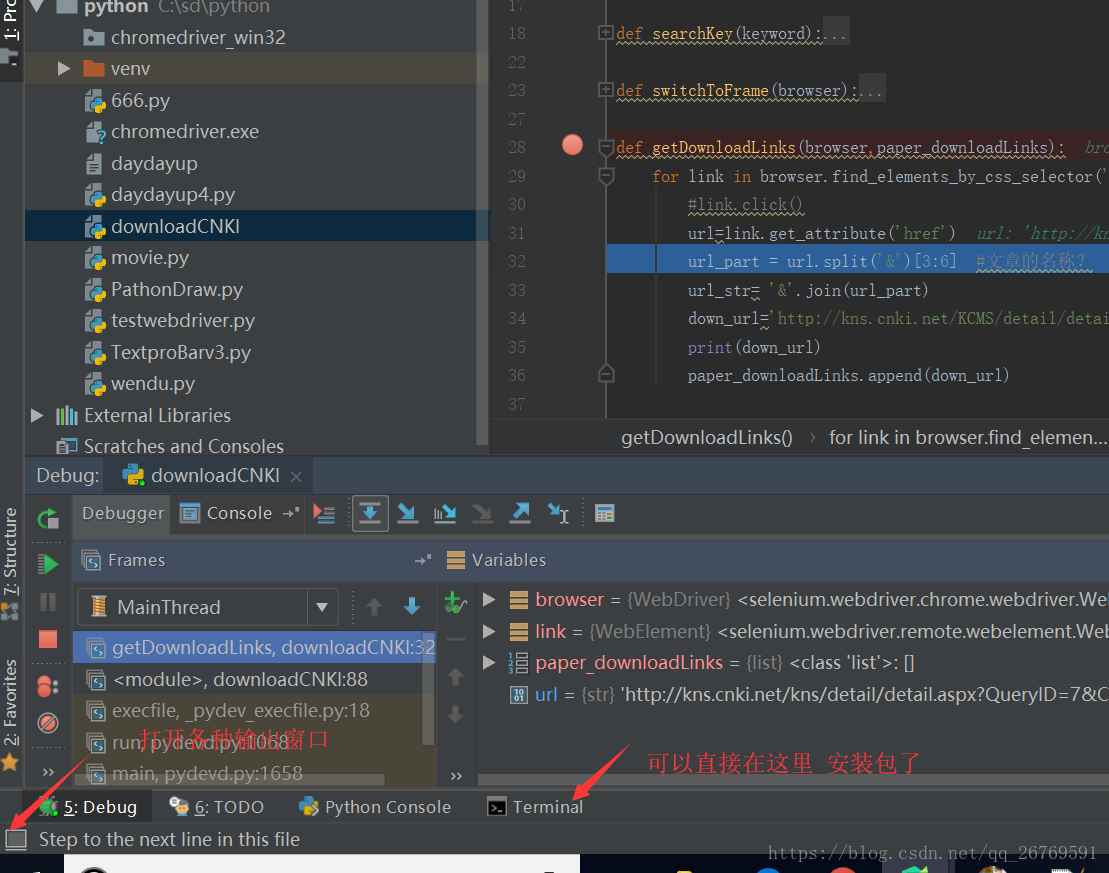
4 右键add watch可以监视变量的值
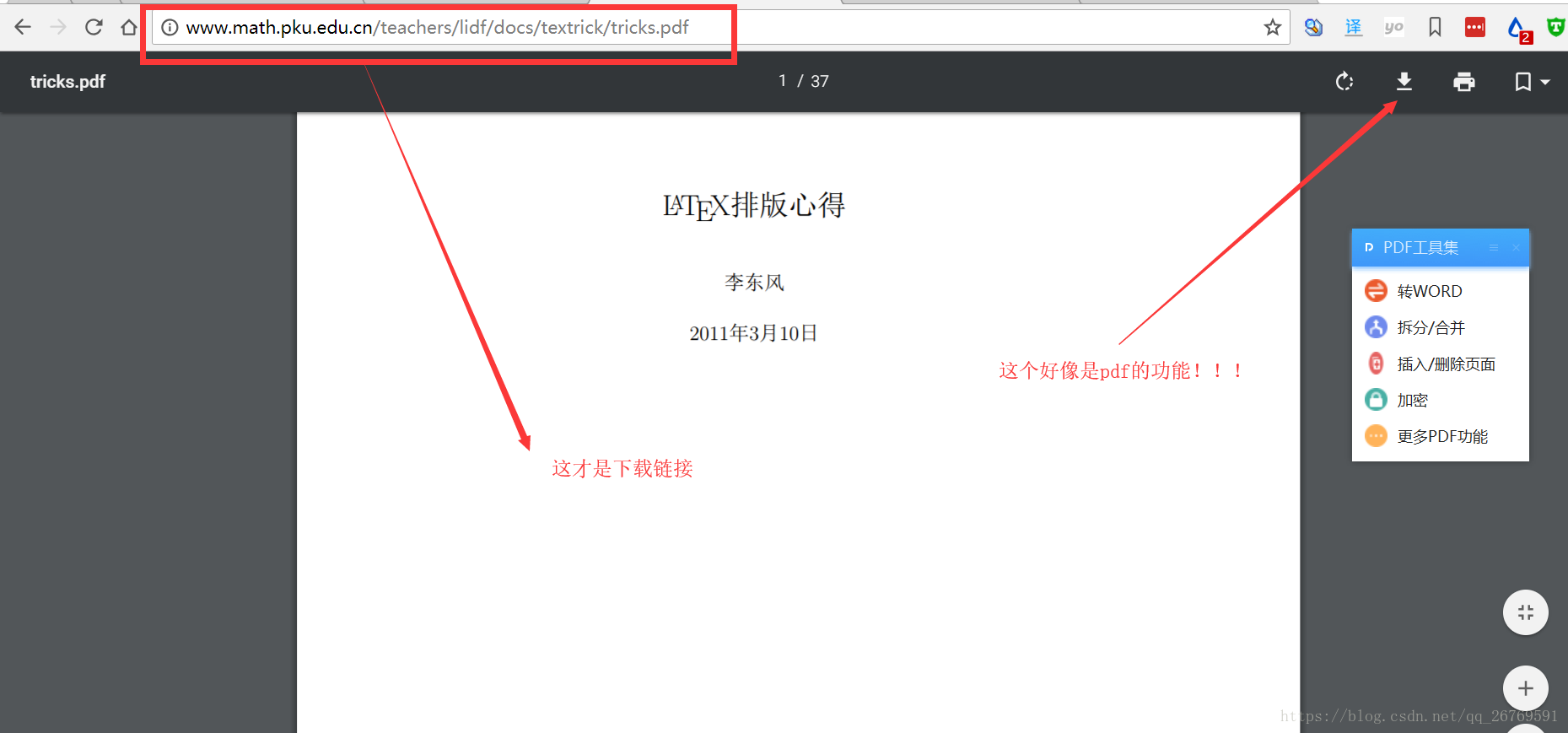
5 pdf的下载链接就是地址框里面的 浏览器自带的下载按钮就是根据这个下载链接进行下载
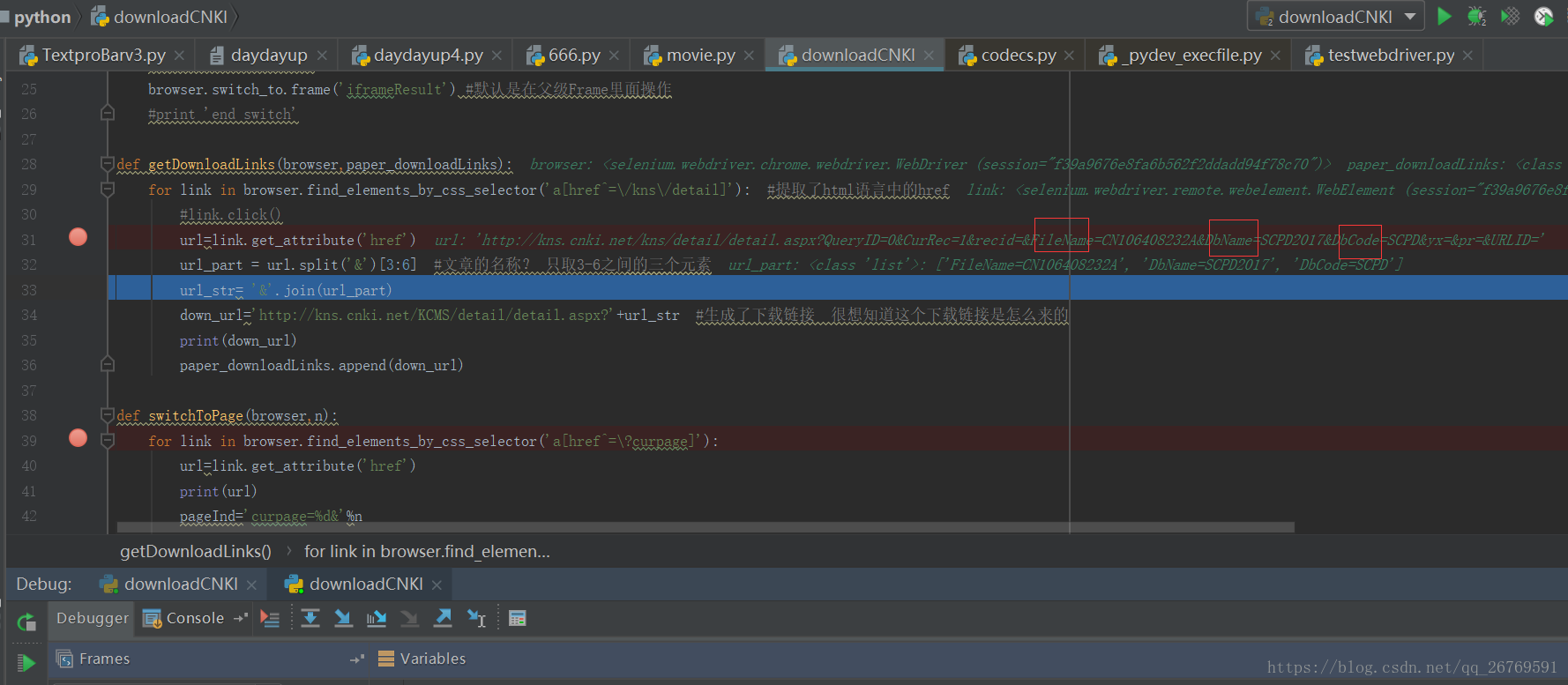
6.pdf的下载地址 只需要那三个参数 其他的值是无关参数 另外就是 可以直接就调用该list元素
7.关于嵌套列表的创建和使用

8.动态list的增加好像只能用apped 而不能用赋值的那种方式