作业1.1
- 流水线前传机制
-
流水线前传机制(Pipeline Forwarding)指的是操作数转发(Operand Forwarding)(或数据转发(Data Forwarding)),是CPU中的一种优化机制,以限制由于流水线失速(Pipeline Stall)而发生的性能缺陷。Pipeline Stall指的是当前操作,必须等待尚未完成的较早操作的结果,才能进行。
-
例子:如果下列两条汇编指令在Pipeline中运行,则在获取(Fetch)并解码(Decode)第二条指令后,Pipeline将暂停,等待第一条语句读取操作数(Read Operands),执行(Execute)ADD,并写入结果(Write Result)。
// A=B+C ADD A B C // D=C-A SUB D C A -
未进行Operand Forwarding的Pipeline
1 2 3 4 5 6 7 8 Fetch ADD Decode ADD Read Operands for ADD Execute ADD Write Result Fetch SUB Decode SUB Stall Stall Read Operands for SUB Execute SUB Write Result -
Operand Forwarding之后的Pipeline,此时完全消除Stall
1 2 3 4 5 6 Fetch ADD Decode ADD Read Operands for ADD Execute ADD Write Result Fetch SUB Decode SUB Read Operands for SUB(利用较早操作时的缓存) Execute SUB Write Result -
从上述例子可见,同样的指令,经过Pipeline Forwarding之后,所需步骤缩减了,从而对应的机器周期也缩减了
- CPU的三级缓存
- 三级缓存的特点:CPU的三级缓存是指三个层级的高速缓存,其作用是进一步降低内存的延迟,同时提升大量数据计算时的性能。它通常分为大小不等的三个层级,分别是L1 Cache、L2 Cache和L3 Cache。其中L3 Cache是多个核心共享的。程序执行时,会先将内存中的数据加载到共享的L3 Cache中,再加载到每个核心独有的L2 Cache,最后进入到最快的L1 Cache,之后才会被CPU读取
- 不同缓存适合存储哪些内容:L1 Cache分为L1i和L1d,分别用来存储指令和数据。L2 Cache是不区分指令和数据的。L3 Cache多个核心共用一个,通常也不区分指令和数据
- 最基本的使用是:数据从RAM流向L3 Cache,然后是L2 Cache,最后是L1 Cache。当处理器寻找执行操作所需的数据时,它首先尝试在L1 Cache中查找它,如果CPU找到了它,则称为高速缓存命中。然后再在L2 Cache和L3 Cache中查找
- 什么样的问题适合GPU
- 大量数据并行计算,比如图形渲染、深度学习、科学模拟
- 所谓并行计算,指的是对大量数据进行相同或者相似的计算
- 对于GPU而言,读取数据到它的显存上,是最为耗时的,但是对显存上的数据进行并行计算,延时极小,且几乎不随数据规模变化而变化
作业1.2
- 线程束(warp)
- 线程束是如何在软件和硬件端执行的:
- 从硬件上看,GPU最基本的处理单元是流处理器(SP),它也被称为CUDA核心,每个SP具有自己的寄存器(Register)和局部内存(Local Memory),不可被其他SP使用。一个流多处理器(SM)由多个CUDA核心组成,每个SM根据GPU架构不同有不同数量的CUDA核心,每个SM具有自己的共享内存(Shared Memory),可被同一SM内的所有SP访问
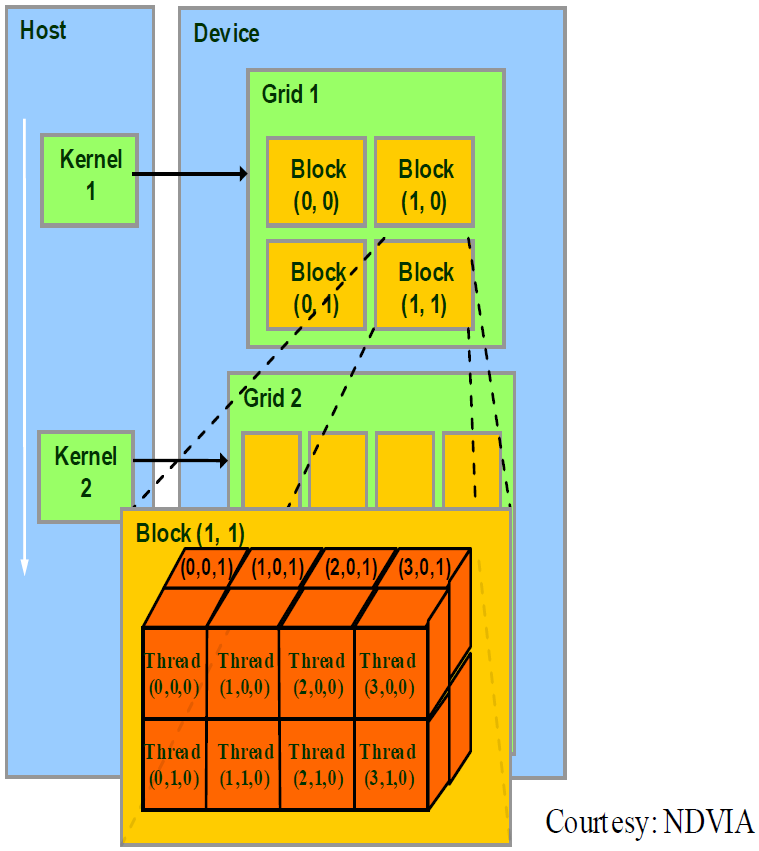
- 从软件上看,一个CUDA并行程序会被许多个线程来执行。数个线程会被群组成一个块(Block),同一个Block中的线程可以同步,也可以通过共享内存进行通信。多个块则会再构成网格(Grid),多个Grid组成一个设备(GPU)。一个Grid执行一个核函数(Kernel)
- SM采用SIMT架构,即单指令多线程架构。warp是最基本的执行单元,一个warp包含32个并行线程,这些线程以不同的数据资源执行相同的指令。由于warp的大小为32,所以Block所含的线程个数一般要设置为32的倍数
- 当一个Kernel被执行时,Grid中的Block被分配到SM上,一个Block的线程只能在一个SM上调度。SM一般可以调度多个Block,大量的线程可能被分到不同的SM上
- 为什么说线程束是执行核函数的最基本单元:因为SM采用SIMT架构,即单指令多线程架构。而一个warp包含32个并行线程,这些线程以不同的数据资源执行相同的指令,因此同一个warp内的线程无法执行不同的指令,从而在SIMT架构下,warp是执行Kernel的最基本单元
- 线程ID(Thread ID)
- 计算下图中Thread(3,0,0)的Thread ID:设坐标顺序是(x,y,z),水平向右为x,竖直向下为y,垂直向里为z
grid_dim = (2, 2); block_idx = (1, 1); block_id = block_idx.y* grid_dim.x + block_idx.x = 3; block_dim = (4, 2, 2); thread_idx = (3, 0, 0); thread_idx = block_id * (block_dim.x + block_dim.y + block_dim.z) + thread_idx.z * (block_dim.x + block_dim.y) + thread_idx.y* block_dim* x + thread_idx.x = 51;