Python爬虫—Scrapy框架—Win10下载安装
- 什么是框架?
- 就是一个集成了很多功能并且有很强通用性的一个项目模块
- 如何学习框架?
- 专门学习框架封装的各种功能的详细用法
- 什么是scrapy框架?
- 爬虫中封装最好的一个明星框架。
- 功能:
- 高性能的持久化存储操作,
- 异步的数据下载,
- 高性能的数据分析,
- 分布式
- 爬虫中封装最好的一个明星框架。
1. 下载wheel
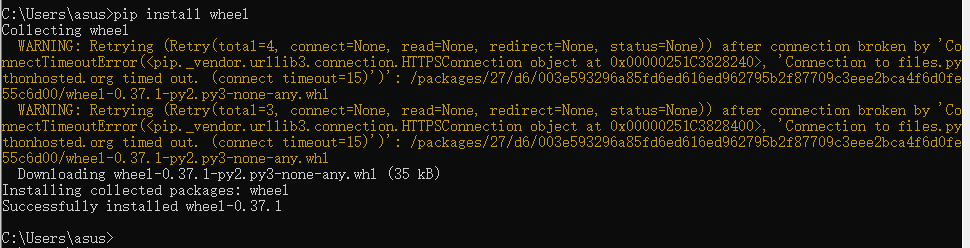
pip install wheel
2.下载twisted
# 进入下面的网站,搜twisted
https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
# 使用python --verison 查看电脑安装的python版本
# 点击想要现在的版本,就可以直接下载到电脑上面
# 然后在命令窗口输入你下载的路径加文件名
# 我的下载地址为 C:\Users\asus\Downloads
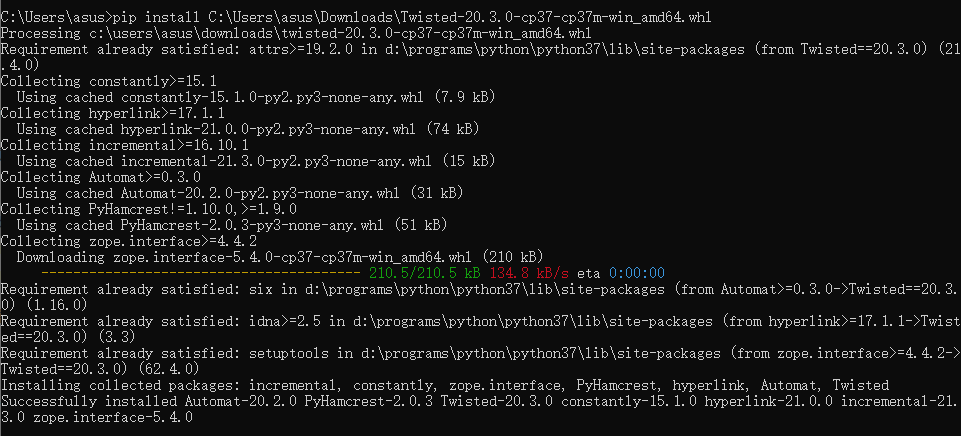
pip install C:\Users\asus\Downloads\Twisted-20.3.0-cp37-cp37m-win_amd64.whl
# 如果在安装过程中报错,说明你下载的文件和系统python不兼容,或者版本不一样(最简单的方法就是再重新试一遍安装,我反正安装了两次才成功安装)
# 此时就想要出现下载其它python对应版本的twiste


3. 下载pywin32
pip install pywin32

4. 下载安装Scrapy
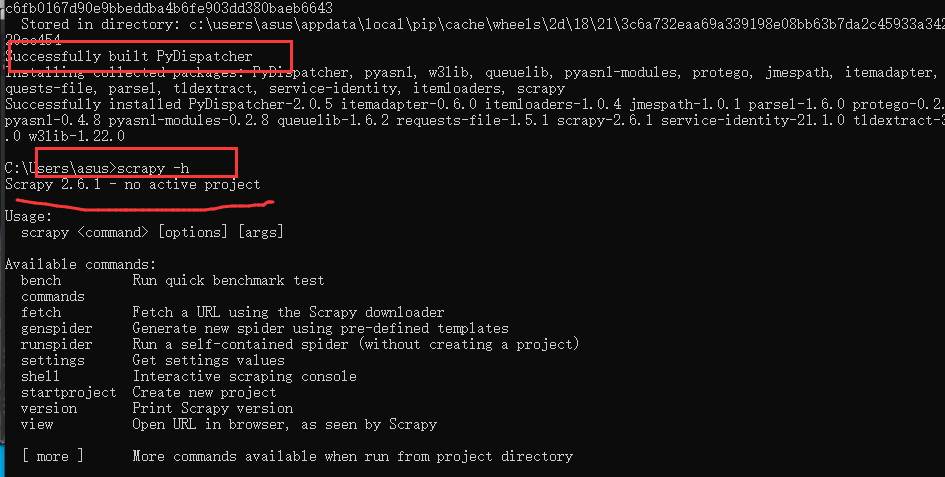
pip install scrapy
# 检验scrapy是否成功安装
# 在终端中输入scrapy -h,出现版本号说明安装成功
scrapy -h
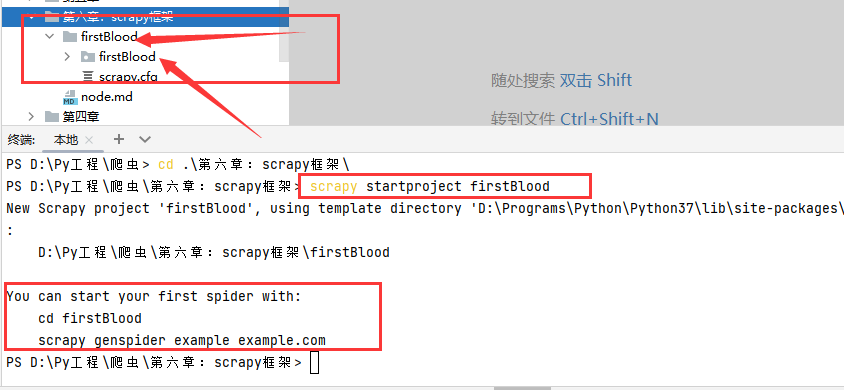
5. 创建一个scrapy项目
# 在cmd命令中,进去想要需要创建工程的文件夹
# 输入下面指令
scrapy startproject 工程名称
# 在spiders文件下创建一个爬虫文件
# 在cmd中输入scrapy genspider 爬虫名 爬取范围域名(可以在后面爬虫的源文件中修改)
scrapy genspider first www.xxx.com
# 所有操作代码写完后,执行工程
# 在cmd中输入,scrapy crawl 爬虫名
scrapy crawl first
# 输入完后爬虫文件就可以执行
文件的功能:
| 文件名称 | 用途 |
|---|---|
| scrapy.cfg | 配置文件 |
| spiders | 存放你Spider文件,也就是你爬取的py文件(需要你放入爬虫的源代码) |
| items.py | 相当于一个容器,和字典较像 |
| middlewares.py | 定义Downloader Middlewares(下载器中间件)和Spider Middlewares(蜘蛛中间件)的实现 |
| pipelines.py | 定义Item Pipeline的实现,实现数据的清洗,储存,验证。 |
| settings.py | 全局配置(经常使用) |
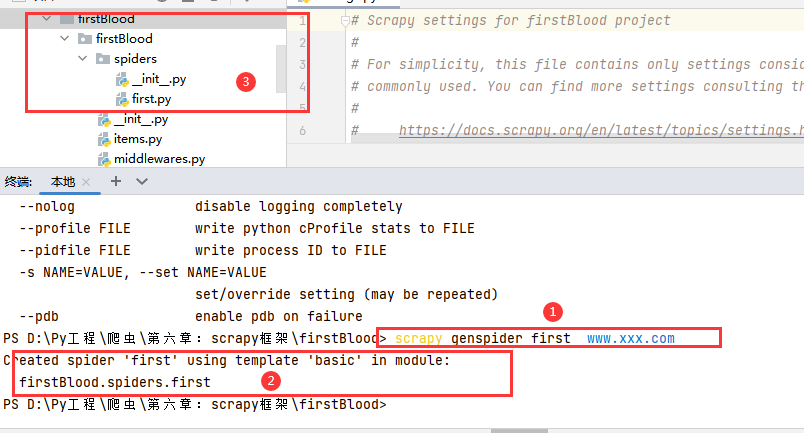
6. first.py(cmd中创建的爬虫文件名称)文件详解
import scrapy
class FirstSpider(scrapy.Spider):
# 爬虫文件的名称,在cmd中创建好了,:就是爬虫源文件的唯一标识(不能重复)
name = 'first'
# 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送(通常情况下我们不会使用这个allowed_domains)
allowed_domains = ['www.xxx.com']
# 起始的url列表,最初在cmd中创建的:该列表中 存放的url会被scrapy自动进行请求发送
# 可以存在多个url
start_urls = ['http://www.baidu.com/', 'http://www.sogou.com']
# start_urls = ['http://www.baidu.com/']
# 用作于数据解析的,response参数表示的就是请求成功后对应的响应对象
# parse可以被调用多次,此时是由start_urls中url的个数来决定的
def parse(self, response):
print(response)

7. 运行、日志
# 运行程序,发现请求成功,并且打印了日志
scrapy crawl first

如果不需要打印日志,加上–nolog

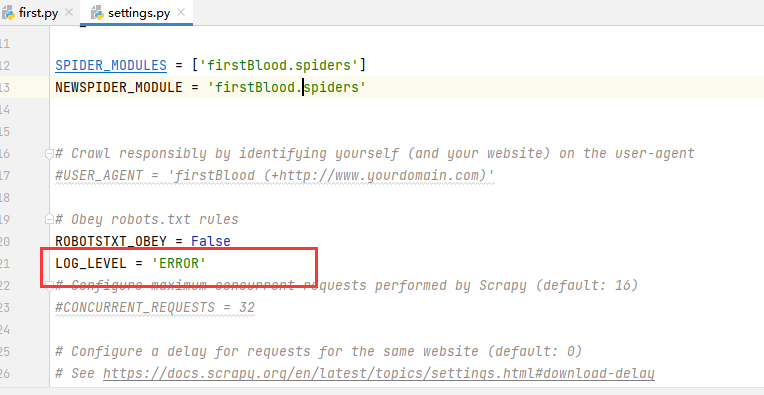
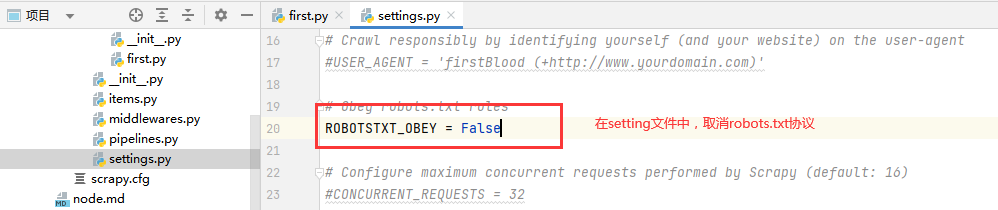
此时如果程序运行错误,我们无法定位到错误的位置,所有需要在settings配置文件中加入
LOG_LEVEL = 'ERROR'