常见的数据结构:
1.堆和栈的区别(在Linux)里面,如何理解堆和栈
来源于
[link](https://blog.csdn.net/Eric_01230/article/details/86299949).
一个由C/C++编译的程序占用的内存包括下列几项:
栈区(stack) :栈区由编译器自动分配释放,存放函数的参数值,返回值及局部变量。栈区是向下增长的,所以是先进后出原则。
堆区(heap):堆区调用malloc()函数来申请用户所需内存,内存使用完毕后调用free()函数释放内存。堆区地址向上增长。
静态区(全局区):a是静态全局变量,b是全局变量,c是静态局部变量,它们都存放在静态区。
代码区:代码区的内存由系统控制
代码区的地址是函数的地址、程序的入口地址、函数的名字
常量区:

2.大端模式和小端模式的区别
可以这样理解:高位存放在低地址,小端方式将高位存放在高地址。

3.Linux相关内容:
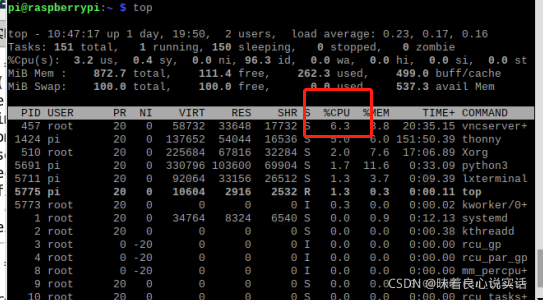
查看CPUI占用率:top
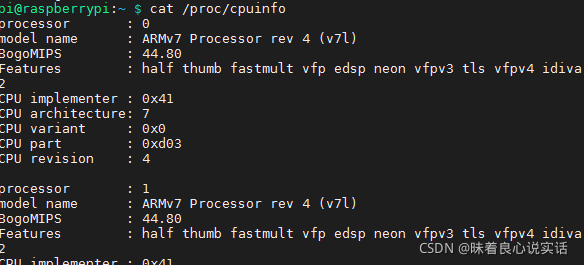
查看cpu的相关信息:cat /proc/cpuinfo
Linux的系统文件夹分类

动态链接库和静态链接库的区别

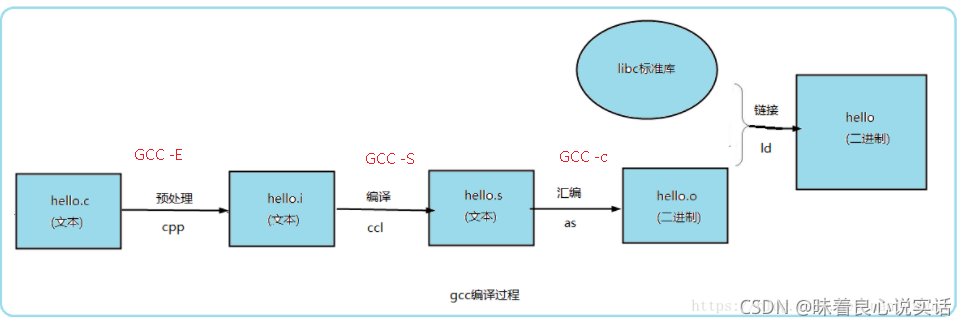
Linux软件完整的编译过程和过程中出现的文件名后缀
基本语法:
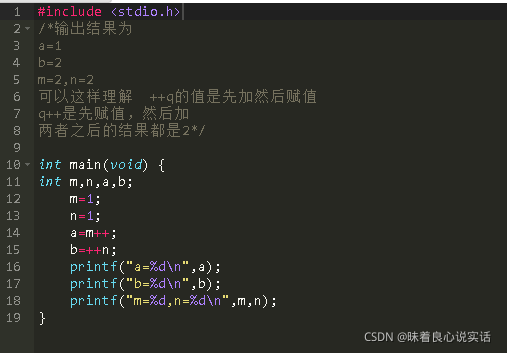
1.q++和++q
TCP/IP的四层架构:
1.应用层:FTP、TELNET、DNS、SMTP、POP3
2.网络层:IP,ICMP,IGMP
3.传输层:
UDP和TCP异同点:
1.TCP面向字节流,而UDP面向数据报。
2.TCP是面向连接的,而UDP不是面向连接的。
3.TCP是可靠的,而UDP是不可靠的。
4.TCP是全双工的,UDP支持多播和广播。
5.UDP 不处理堵塞,应用需要发,就会发送。TCP 还拥有堵塞控制,TCP 会根据网络环境调整 发包的频率。
6.TCP的传输效率低,UDP的传输效率高。
4.数据链路层(接口层):Ethernet 802.3、Token Ring 802.5、X.25、Frame relay、HDLC、PPP ATM
Linux的启动次序
Linux启动顺序
加电—加电自检(BIOS)—硬件检查 ---------BIOS可以理解成电脑主板自带的硬件检查工具,可以排除硬件异常
—MBR(找到需要启动的系统,由于实际计算机上可能会装有多个系统) -----------------这里的MBR类似于电脑的引导选项,安装双系统的人应该见过
—bootloader系统初始化,装载kenel到内存 -----------------加载内核到运存里面,开始跑程序
—内核执行,决定哪些设备需要驱动程序初始化,挂载根文件系统,启动第一个进程init ----------------执行设备的初始化,挂载文件系统,启动1号进程init
—启动/etc/rc.d/sysinit ----------------执行系统的初始化
(这是由init执行的第一个脚本,在Redhat中,/etc/rc.d/rc.sysinit主要做在各个运行模式中相同的初始化工作,包括:调入keymap以及系统字体,启动swapping,设置主机名,设置NIS域名,检查(fsck)并mount文件系统,打开quota,装载声卡模块,设置系统时钟)
(rc--run command运行命令,d-精灵进程,启动过程看不到的进程,/etc文件下是很重要的配置文件,不要乱修改)
—加载其他模块(内存、硬盘、光驱等) ---------------加载外部模块
—run level script(/etc/rc.d/rc $RUNLEVEL # $RUNLEVEL为缺省的运行模式,最多6层,每个层次启动的程序是不一样的,各个层次之间没有关系) ----按照层次运行脚本
—执行/etc/rc.d/rc.local(非常重要,在安装tomcat后需要设置自启动时修改这个)
—执行/bin/login—shell启动 ---------开启内核解释器
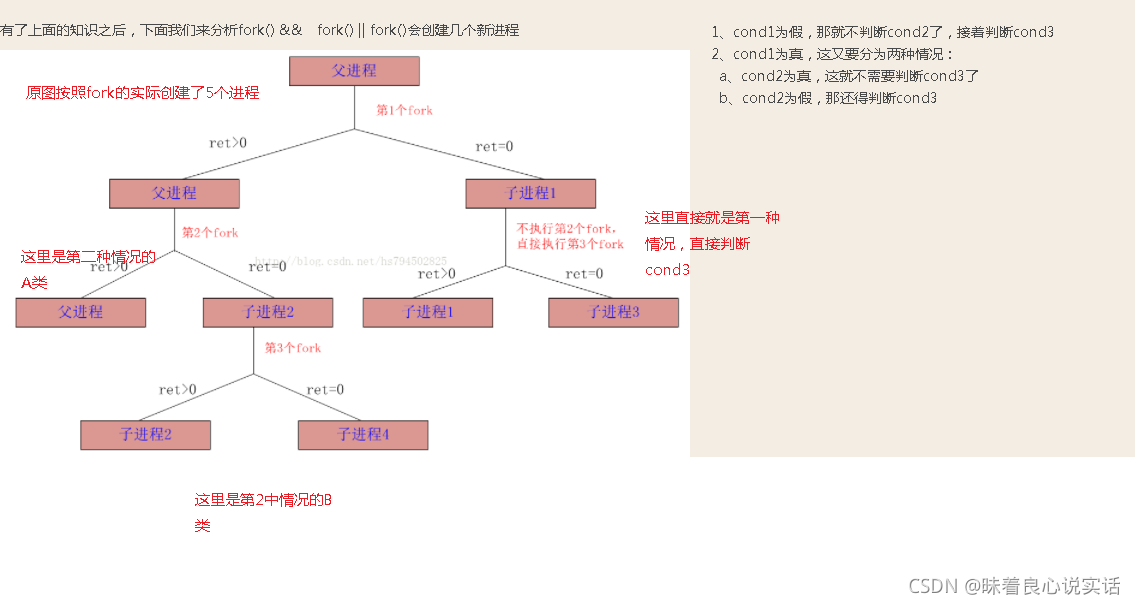
对于进程的一个问题:
//出了main函数之外创建了多少进程? 一共创建了1+8+10=19个新的进程
/*这里的总结来源于https://www.cnblogs.com/liudehao/p/5751291.html
基本的一个知识点是:fork创建进程,会返回三个值,分别为父进程内,即fork()>0,返回子进程的进程ID;子进程fork()=0;出现错误,fork()<0
*/
#include <unistd.h>
#include <stdio.h>
int main()
{
fork(); //这里创建了第一个进程
fork() && fork() || fork();/*这里我的理解是在原有的父进程上又创建了2+4+2=8个进程*/
fork();/*原本有1+1+8个进程,我需要注意一个问题,就是fork之后是所有的进程又复制了一次,所以是10个*/
}
**
**
进程和线程之间的关系和区别:
关系:
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。 (我以你的qq为例,你的qq作为一个进程,可以在window的任务管理器看到进程号,Linux里面叫pid,他含有视频,文字聊天等多个功能,而这每一个功能就是一个线程)
(2)资源分配给进程,同一进程的所有线程共享该进程的所有资源。(我的理解就是资源的分配,如堆栈之类的内存分配和cpu分配)进程是是独立运行和独立调度的基本单位。线程是程序执行的基本单位。**进程是是独立运行和独立调度的基本单位。线程是程序执行的基本单位。*进程是是独立运行和独立调度的基本单位。线程是程序执行的基本单位。(重点)
(3)处理机分给线程,即真正在处理机上运行的是线程。
(4)线程在执行过程中,需要协作同步。不同进程的线程间要利用消息通信的办法实现同步。线程是指进程内的一个执行单元,也是进程内的可调度实体.
区别:
(1)调度:线程作为资源CPU和内存调度和分配的基本单位,进程作为拥有资源的基本单位和程序执行的基本单位。
(2)并发性:不仅进程之间可以并发执行,同一个进程的多个线程之间也可并发执行
(3)拥有资源:进程是拥有资源的一个独立单位,线程不拥有系统资源,但可以访问隶属于进程的资源.
(4)系统开销:在创建或撤消进程时,由于系统都要为之分配和回收资源,导致系统的开销明显大于创建或撤消线程时的开销。
进程的通信方式:
管道pipe:有名管道、无名管道
信号量:sem
套接字:socket
消息队列:queue
共享内存:shmget
-1>>1 和 -1 <<1
//需要知道一下的概念
/*正数是以其二进制出现
而负数是以其正值的补码形式 补码是反码+1
举例为:-1 的原码为00000000 00000000 00000000 00000001
反码为11111111 11111111 11111111 11111110
补码就是11111111 11111111 11111111 11111111
<<1 补码就是 11111111 11111111 11111111 1111110
反码就是00000000 00000000 00000000 00000001
原码就是00000000 00000000 00000000 00000010
*/
#include<stdio.h>
int main()
{
int i,j,m;
i=-1;
j=i<<1;
m=i>>1;
printf("-1 左移1=%d ",j);
printf("-1 you移1=%d ",m);
}
死锁产生的必要条件:
个人的总结:1.进程的资源只能独享,进程互斥使用资源,即资源只能给一个进程使用 2.资源在被用完后,必须由使用资源的进程释放 3 申请资源的同时,保持对原有资源的占有 4.形成进程等待的环路,形成一个闭环。
互斥条件:资源是独占的且排他使用,进程互斥使用资源,即任意时刻一个资源只能给一个进程使用,其他进程若申请一个资源,而该资源被另一进程占有时,则申请者等待直到资源被占有者释放。
不可剥夺条件:进程所获得的资源在未使用完毕之前,不被其他进程强行剥夺,而只能由获得该资源的进程资源释放。
请求和保持条件:进程每次申请它所需要的一部分资源,在申请新的资源的同时,继续占用已分配到的资源。
循环等待条件:在发生死锁时必然存在一个进程等待队列{P1,P2,…,Pn},其中P1等待P2占有的资源,P2等待P3占有的资源,…,Pn等待P1占有的资源,形成一个进程等待环路,环路中每一个进程所占有的资源同时被另一个申请,也就是前一个进程占有后一个进程所深情地资源。
关于二叉树的一些问题(抱怨下,我他喵做个软件测试,你他喵也让我搞数据结构,握草,还尼玛现场笔试,我去)
已知前序、中序或者中序、后序都可以唯一确定一棵二叉树,但是已知前序、后序是无法唯一确定一棵二叉树的,解不唯一。
前序遍历:根左右
中序遍历:左根右
后序遍历:左右根
C语言关键字
include 不是关键字,是预处理命令
auto 声明自动变量
short 声明短整型变量或函数
int 声明整型变量或函数
long 声明长整型变量或函数
float 声明浮点型变量或函数
double 声明双精度变量或函数
char 声明字符型变量或函数
struct 声明结构体变量或函数
union 声明共用数据类型
enum 声明枚举类型
typedef 用以给数据类型取别名
const 声明只读变量
unsigned 声明无符号类型变量或函数
signed 声明有符号类型变量或函数
extern 声明变量是在其他文件正声明
register 声明寄存器变量
static 声明静态变量
volatile 说明变量在程序执行中可被隐含地改变
void 声明函数无返回值或无参数,声明无类型指针
if 条件语句
else 条件语句否定分支(与 if 连用)
switch 用于开关语句
case 开关语句分支
for 一种循环语句
do 循环语句的循环体
while 循环语句的循环条件
goto 无条件跳转语句
continue 结束当前循环,开始下一轮循环
break 跳出当前循环
default 开关语句中的“其他”分支
sizeof 计算数据类型长度
return 子程序返回语句(可以带参数,也可不带参数)循环条件
常见的网页响应码:
1××:消息响应
2××:成功响应
200 OK 请求成功,表示已经请求成功,默认情况下的状态码为200的响应就可以被缓存了。
Partial Content 206 部分内容,当客户端通过使用range头字段进行文件分段下载时使用该状态码。
3××:重定响应
Moved Permanently 301 永久移动,该状态码表示所请求的URI资源路径已经改变,新的URL会在响应的Location:头字段里找到。
Found 302临时移动,该状态码表示所请求的URI资源路径临时改变,并且还可能继续改变.因此客户端在以后访问时还得继续使用该URI.新的URL会在响应的Location:头字段里找到。
4××:客户端错误
Not Found 404 错误请求,因发送的请求语法错误,服务器无法正常读取。
Forbidden 403 禁止访问,客户端没有权利访问所请求内容,服务器拒绝本次请求。
Bad Request 400 错误请求,因发送的请求语法错误,服务器无法正常读取。
Unauthorized 401 未经授权,需要身份验证后才能获取所请求的内容,类似于403错误.不同点是.401错误后,只要正确输入帐号密码,验证即可通过。
5××:服务器端错误
Internal Server Error 500内部服务器错误,服务器遇到未知无法解决的问题。
Bad Gateway 502 网关错误,服务器作为网关且从上游服务器获取到了一个无效的HTTP响应。