NumPy(Numerical Python的简称)是高性能科学计算和数据分析的基础包。它是本书所介绍的几乎所有高级工具的构建基础。其部分功能如下
- ndarray, 一个具有矢量算数运算和复杂广播能力的快速且节省空间的多维数组
- 用于对证书数据进行快速运算的标准数学函数(无需编写循环)
- 用于读写磁盘数据的工具以及用于操作内存映射文件的工具
- 线性代数、随机数生成以及傅里叶变换工具
- 用于集成由C、C++、Fortran等语言编写的代码的工具
从生态的角度。由于NumPy提供一个简单易用的API,因此很容易将数据传递给低级语言编写的外部库,外部库也能以NumPy数组的形式将数据返回给Python
NumPy本身并没有提供多么高级的数据分析功能,理解NumPy数组以及面向数组的计算将有助于你更高效地使用诸如Pandas之类的工具
内容提要
- NumPy的ndarray:一种多维数组对象
- 创建ndarray
- ndarray的数据类型
- 数组和标量之间的运算
- 基本的索引和切片
- 一维
- 高维
- 布尔型索引
- 花式索引
- 数组转置和轴对换
- 调用函数:快速的元素级数组函数
- 利用数组进行数据处理
- 将条件逻辑表述为数组运算
- 数学和统计方法
- 用于布尔型数组的方法
- 排序
- 唯一化以及其他的集合逻辑
- 用于数组的文件输入输出
- 线性代数
- 随机数生成
NumPy的ndarray:一种多维数组对象
ndarray是一种通用的同构数据多维容器,也就是说,其中的所有元素必须是相同类型的。每个数组都有一个shape(一个表示各维度大小的元组)和一个dtype(一个用于说明数组数据类型的对象):
In[26]: data.shape
Out[26]: (10,)
In[28]: data.dtype
Out[28]: dtype('int32')这里的data其实是一个比较特殊的秩一矩阵,这跟一般的矩阵有所不同,这里不详细介绍。
虽然大多数数据分析工作不需要深入理解NumPy,但是精通面向数组的编程和思维方式是成为Python科学计算牛人的一大关键步骤
创建ndarray
最简单的方法是使用array函数,它接受一切序列型的对象(包括其他数组),然后产生一个新的包含传入数据的NumPy数组,如下
In[28]: adata1 = [6,7,8,9,10.5]
In[29]: aarr1 = np.array(data1)
In[32]: arr1
Out[32]: array([ 6. , 7. , 8. , 9. , 10.5])嵌套序列将会被转化为一个多维数组
In[33]: data2 = [[1,2,3,4],[5,6,7,8]]
In[34]: arr2 = np.array(data2)
In[35]: arr2
Out[35]:
array([[1, 2, 3, 4],
[5, 6, 7, 8]])除非显式说明,np.array会尝试为新建的这个数据推断出一个较为合适的数据类型,这个类型保存在dtype中,如下
arr1.dtype
Out[37]: dtype('float64')
arr2.dtype
Out[38]: dtype('int32')除此之外,还可以通过一些函数来创建数组,比如,zeros和ones分别可以创建指定长度或形状的全0或全1数组。empty可以创建一个没有任何具体值的数组
In[41] np.zeros(10)
Out[41]: array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
In[42] np.zeros((3,6))
Out[42]:
array([[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.]])
In[43] np.empty((2,3,2))
Out[43]:
array([[[ 8.67740622e-312, 3.16202013e-322],
[ 0.00000000e+000, 0.00000000e+000],
[ 0.00000000e+000, 7.40907173e-038]],
[[ 5.28802037e+174, 8.76294657e+169],
[ 2.02340708e-052, 7.49431806e-067],
[ 8.39356861e+165, 1.86924407e-051]]])很多情况下,np.empty返回的都是一些未初始化的垃圾值
此外,eye也可以创建N N的单位矩阵

ndarray的数据类型
arr1 = np.array([1,2,3], dtype=np.float64)
arr2 = np.array([1,2,3], dtype=np.int32)
In[46]: arr1.dtype
Out[46]: dtype('float64')
In[47]: arr2.dtype
Out[47]: dtype('int32')dtype是NumPy如此强大和灵活的原因之一。多数情况下,它们直接映射到相应的机器表示,这使得“读写磁盘上的二进制数据流”以及“集成低级语言代码(如C、Frortran)”等工作变得更加简单
数值型dtype的命名方式相同:一个类型名(如float或int),后面跟一个用于表示各元素位长的数字
- int8, uint8
- int16, uint16
- …
- float16
- float32
- …
- bool
通过ndarray的astype方式显式地转换其type:
arr = np.array([1,2,3,4,5])
arr.dtype
Out[49]: dtype('int32')
float_arr = arr.astype(np.float64)
float_arr.dtype
Out[51]: dtype('float64')神奇的是,使用astype也可以完成从字符串到浮点数等的转换,就可以在操作文件时很方便地将字符串变成数字,用于下一步处理
numeric_strings = np.array(['1.32','323','1.2'], dtype=np.string_)
numeric_strings
Out[4]:
array([b'1.32', b'323', b'1.2'],
dtype='|S4')注意,调用astype无论如何都会创建出一个新的数组,即使它跟原来的数组完全一样也是如此
数组和标量之间的运算
数组很重要,因为它使你不用编写循环即可对数据执行批量运算。这通常叫矢量化(Vectorization)
- 大小相同的数组之间的任何算数运算都将应用到元素级
- 同样,数组与标量之间的算数运算也会将那个标量值传播到各个元素(broadcasting)
arr = np.array([[1,2,3],[4,5,6]])
arr
Out[8]:
array([[1, 2, 3],
[4, 5, 6]])
arr*arr
Out[9]:
array([[ 1, 4, 9],
[16, 25, 36]])
1/arr
Out[10]:
array([[ 1. , 0.5 , 0.33333333],
[ 0.25 , 0.2 , 0.16666667]])
arr*0.5
Out[11]:
array([[ 0.5, 1. , 1.5],
[ 2. , 2.5, 3. ]])基本的索引和切片
1)一维数据
先建立一个ndarray
arr = np.arange(10)
arr
Out[17]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])NumPy的索引功能在表面上看跟Python的列表功能差不多
arr[5]
Out[18]: 5
arr[5:8]
Out[19]: array([5, 6, 7])
arr[5:8]=12
arr
Out[21]: array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9])当你将一个标量值赋值给一个切片时(如arr [ 5 : 8 ] = 12),该值会自动传播到整个选区。跟列表最重要的一个区别在于,数组切片时原始数组的视图。这意味着数据不会被复制,视图上的任何修改都会直接反映到源数组上:
arr_slice = arr[5:8]
arr_slice[1]
Out[23]: 12
arr
Out[24]: array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9])
arr_slice
Out[25]: array([12, 12, 12])
arr_slice[:]
Out[26]: array([12, 12, 12])
arr_slice[:]=64
arr
Out[28]: array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])
arr = np.arange(10)
arr[5:8] = 12
arr_slice = arr[5:8]
arr_slice[1] = 12345
arr
Out[33]: array([ 0, 1, 2, 3, 4, 12, 12345, 12, 8, 9])
arr_slice[:] = 64
arr
Out[35]: array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])加入NumPy坚持要将数据复制来复制去的话将会产生何等的性能和内存问题
2)高维数据
如果数据是高维的,可以做很多事
arr2d = np.array([[1,2,3], [4,5,6], [7,8,9]])
arr2d[2]
Out[37]: array([7, 8, 9])下面这两种方式是等价的
arr2d[0][2]
Out[38]: 3
arr2d[0, 2]
Out[39]: 3切片同样类似与Python列表,你可以在一个轴或多个轴上进行切片,也可以跟整数索引混合使用。同样,对切片的表达式的赋值操作也会被扩散到整个选区
arr2d
Out[40]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
arr2d[:2]
Out[41]:
array([[1, 2, 3],
[4, 5, 6]])
arr2d[:2, 1:]
Out[42]:
array([[2, 3],
[5, 6]])
arr2d[:2, 1:]=0
arr2d
Out[44]:
array([[1, 0, 0],
[4, 0, 0],
[7, 8, 9]])三维的这里不多介绍
布尔型索引
先准备两个数组
names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Hello'])
names
Out[48]:
array(['Bob', 'Joe', 'Will', 'Bob', 'Hello'],
dtype='<U5')data
Out[55]:
array([[ 0.3451218 , -1.86290376, -1.5775965 , -2.2219929 ],
[-1.4583581 , -1.42468226, -0.75108119, 0.42112645],
[-0.05190866, -0.26016373, 0.26716395, -0.19266413],
[-0.5527829 , -0.04313535, -1.48816309, -0.4702624 ],
[ 0.16423759, -0.24642226, 2.450234 , 0.27223512]])names == 'Bob'
Out[49]: array([ True, False, False, True, False], dtype=bool)假如每个名字都对应data数组中的一行,而我们想要选出对应名字“Bob“的所有行。跟算数运算一样,数组的比较(如==)也是矢量化的。因此,对names和字符串“Bob”的比较运算将会产生一个布尔型数组。这个数组可以用于数组索引。
data[names == 'Bob']
Out[56]:
array([[ 0.3451218 , -1.86290376, -1.5775965 , -2.2219929 ],
[-0.5527829 , -0.04313535, -1.48816309, -0.4702624 ]])索引和切片可以混用,但需要特别注意有一个维度(data的行)一定是对应与布尔类型的元素个数的
data[names == 'Bob', 2:]
Out[57]:
array([[-1.5775965 , -2.2219929 ],
[-1.48816309, -0.4702624 ]])如果希望对多个条件进行判定,可以采用 & 和 | 等运算符
mask = (names == 'Bob')|(names == 'Will')
mask
Out[60]: array([ True, False, True, True, False], dtype=bool)
data[mask]
Out[61]:
array([[ 0.3451218 , -1.86290376, -1.5775965 , -2.2219929 ],
[-0.05190866, -0.26016373, 0.26716395, -0.19266413],
[-0.5527829 , -0.04313535, -1.48816309, -0.4702624 ]])有了数组索引之后可以很方便地进行数据的批量修改,这理解不再赘述
注意:通过布尔类索引选取数组中的元素,将总是创建数据的副本,即使返回一模一样的数组也是如此
Python中的关键字如and和or在布尔类型中无效
花式索引
花式索引(Fancy indexing)是一个NumPy术语,指利用整数数组进行索引
先建立一个8 8数组
arr = np.empty((8,4))
for i in range(8):
arr[i] = i
arr
Out[66]:
array([[ 0., 0., 0., 0.],
[ 1., 1., 1., 1.],
[ 2., 2., 2., 2.],
...,
[ 5., 5., 5., 5.],
[ 6., 6., 6., 6.],
[ 7., 7., 7., 7.]])为了以特定的顺序选取行子集,只需要传入一个用于指定顺序的整数列表或ndarray即可:
arr[[4,3,0,6]]
Out[67]:
array([[ 4., 4., 4., 4.],
[ 3., 3., 3., 3.],
[ 0., 0., 0., 0.],
[ 6., 6., 6., 6.]])如果index是负数,则可以反序索引
arr[[-3,-5,-7]]
Out[68]:
array([[ 5., 5., 5., 5.],
[ 3., 3., 3., 3.],
[ 1., 1., 1., 1.]])如果希望通过索引得到某些行和某些列交错处的元素,这里有两种方法,第二种是通过np.ix_函数
arr[[1,5,7,2]][:,[0,3,1,2]]
Out[72]:
array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]])
arr[np.ix_([1,5,7,2],[0,3,1,2])]
Out[73]:
array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]])记住,花式索引跟切片不一样,它总是将数据复制到新数组中
数组转置和轴对换
数组的转置,可以使用方法T很简单地得到
arr
Out[75]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
arr.T
Out[76]:
array([[ 0, 5, 10],
[ 1, 6, 11],
[ 2, 7, 12],
[ 3, 8, 13],
[ 4, 9, 14]])计算内积可以采用dot点乘的方法
arr = np.random.randn(6, 3)
arr
Out[78]:
array([[-1.10327969, 0.24727585, 1.43635061],
[-0.84238257, -0.29703235, 0.62304278],
[ 0.07501379, -0.80060363, -0.95313957],
[ 0.5196952 , 1.18219282, 0.68693995],
[-0.03176577, 0.77445684, 0.11987684],
[-0.14391157, 0.97450534, -0.79426003]])
np.dot(arr.T, arr)
Out[79]:
array([[ 2.22426424, 0.36688025, -1.71354083],
[ 0.36688025, 3.73736365, 1.06412223],
[-1.71354083, 1.06412223, 4.47686638]])调用函数:快速的元素级数组函数
下面给出几个例子
1)sqrt
arr = np.arange(10)
np.sqrt(arr)
Out[82]:
array([ 0. , 1. , 1.41421356, 1.73205081, 2. ,
2.23606798, 2.44948974, 2.64575131, 2.82842712, 3. ])2)exp
np.exp(arr)
Out[83]:
array([ 1.00000000e+00, 2.71828183e+00, 7.38905610e+00,
2.00855369e+01, 5.45981500e+01, 1.48413159e+02,
4.03428793e+02, 1.09663316e+03, 2.98095799e+03,
8.10308393e+03])3)maximun:返回两个数组每一对元素中较大值组成的数组
x = np.random.randn(8)
y = np.random.randn(8)
x
Out[86]:
array([ 0.48018203, 0.74150585, -2.11228157, -0.17637271, -1.1060399 ,
0.67641069, 0.21828948, 0.07999161])
y
Out[87]:
array([ 0.39329222, -0.64868354, -0.7046026 , -0.23677563, -0.1900475 ,
-1.3527468 , -0.74924095, 0.4044749 ])
np.maximum(x, y)
Out[88]:
array([ 0.48018203, 0.74150585, -0.7046026 , -0.17637271, -0.1900475 ,
0.67641069, 0.21828948, 0.4044749 ])另外其他的一些一元函数
- abs、fabs
- sqrt
- square
- exp
- log、log10、log2
- sign(取正负号)
- floor(取下整)
- modf(将数组的小数和整数部分以两个独立数组的形式返回)
- isnan(返回“哪些值是NaN”)
- cos、cosh等
- arcos等
二元函数
- add
- substract(第一个数组减第二个)
- multiply
- divide
- mod
- greater(元素级比较运算)
利用数组进行数据处理
假设我们想在一组值(网络型)上计算sqrt(x^2 + y^2),np.meshgrid函数接受两个数组,并昌盛一个二维矩阵(对应于两个数组中的所有(x,y)对)
points = np.arange(-5,5, 0.01)
xy, ys = np.meshgrid(points, points)xs
Out[102]:
array([[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
...,
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99]])之后使用meshgrid和matplot的imshow方法
import matplotlib.pyplot as plt
z = np.sqrt(xs**2 + ys**2)
plt.imshow(z)
Out[110]: <matplotlib.image.AxesImage at 0x1b35fae5cf8>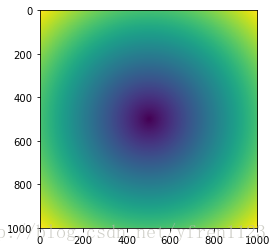
将条件逻辑表述为数组运算
numpy.where函数是三元表达式 x if condition else y 的矢量化版本
为了研究这个问题,先建立三个数组
xarr = np.array([1.1, 1.2, 1.3, 1.4, 1.5])
yarr = np.arange(1.1,1.6,0.1)
cond = np.random.randn(5)>0cond
Out[118]: array([False, True, True, True, True], dtype=bool)分别用魔术指令timeit研究花费时间
%timeit result = [(x if c else y) for x,y,c in zip(xarr, yarr, cond)]
The slowest run took 14.68 times longer than the fastest.
This could mean that an intermediate result is being cached.
100000 loops, best of 3: 2.23 µs per loop
%timeit result = np.where(cond, xarr, yarr)
The slowest run took 21.75 times longer than the fastest.
This could mean that an intermediate result is being cached.
1000000 loops, best of 3: 1.13 µs per loop发现第二种使用where比直接用三元表达式,对于ndarry来说会快一些
where函数除了对比筛选两个数组的元素之外还可以仅对一个数组进行操作,这是因为where的第二个和第三个参数可以是标量而非必须是数组
from numpy.random import randn
arr = randn(4,4)
arr
Out[127]:
array([[-0.327697 , -0.26761273, 0.96735603, -0.45267616],
[ 0.61436942, 0.97031185, 1.79803702, -0.57428651],
[ 2.15022337, 0.86897193, -0.21703771, -0.65488062],
[-0.23657917, -0.29383179, 1.44716779, 1.20383425]])可以把两个值都设成标量
np.where(arr>0, 2, -2)
Out[128]:
array([[-2, -2, 2, -2],
[ 2, 2, 2, -2],
[ 2, 2, -2, -2],
[-2, -2, 2, 2]])或者仅在一些条件下才去修改值
np.where(arr>0, 2, arr)
Out[129]:
array([[-0.327697 , -0.26761273, 2. , -0.45267616],
[ 2. , 2. , 2. , -0.57428651],
[ 2. , 2. , -0.21703771, -0.65488062],
[-0.23657917, -0.29383179, 2. , 2. ]])此外,如果希望用where表达出更为复杂的逻辑,比如说两个condition的四种逻辑组合,这也是可以实现的。关键在于一个条件一个条件地判断,类似if-else嵌套
np.where(cond1 & cond2, 0
np.where(con1, 1
np.where(cond2, 2,3)))这段代码在我的电脑上运行的时候除了些问题 SyntaxError: invalid syntax, 但是到目前还没找到原因
数学和统计方法
基本数组统计方法
- sum
- mean
- std、var
- min、max
- argming、argmax(分别为最大和最小元素的索引)
下面是一个例子
arr = randn(5,4)
arr.mean()
Out[157]: -0.28263045040153451
np.mean(arr)
Out[158]: -0.28263045040153451
arr.sum()
Out[159]: -5.6526090080306899
arr.mean(axis = 1)
Out[160]: array([-0.41301646, -0.48808497, 0.12634617, -0.54985955, -0.08853744])
arr.mean(axis = 0)
Out[161]: array([ 0.01609314, -0.4316564 , -0.15895508, -0.55600346])cumsum和cumprod函数用来计算累积的和或者乘积,比如cumsum(0)将会保留数组第一行,第二行变成第一行对应元素加第二行对应元素,第三行则再加上第三行的元素;cumprod即是将加减关系变成乘积关系即可
(这两个方法不聚合,即产生一个由中间结果组成的数组)
实现如下
arr = np.array([[0,1,2],[3,4,5],[6,7,8]])
arr.cumsum(0)
Out[164]:
array([[ 0, 1, 2],
[ 3, 5, 7],
[ 9, 12, 15]], dtype=int32)arr.cumprod(1)
Out[167]:
array([[ 0, 0, 0],
[ 3, 12, 60],
[ 6, 42, 336]], dtype=int32)用于布尔型数组的方法
这一部分虽然很简单,但是有了解和掌握的必要
布尔类型和sum方法组合起来可以很方便地实现某种特定类型数据的计数
arr = randn(100)
(arr>0).sum()
Out[169]: 43any方法用于检查是否有 True,而all方法检查是否全为 True
bools = np.array([False, False, True, True, False])
bools.any()
Out[171]: True
bools.all()
Out[172]: False排序
arr = randn(8)
arr
Out[174]:
array([ 0.37390646, -1.11366161, 0.77423332, 1.36087061, -2.10089985,
0.86290529, -0.06616976, -0.69619387])
arr.sort()
arr
Out[176]:
array([-2.10089985, -1.11366161, -0.69619387, -0.06616976, 0.37390646,
0.77423332, 0.86290529, 1.36087061])如果是多维数据,同样可以调用sort方法,不同的是需要传入一个参数说明排序时依据的维度
arr = randn(5, 3)
arr
Out[178]:
array([[-0.89934378, 0.29774338, -0.24432043],
[-0.02535895, -0.06797855, 1.19498898],
[-0.24759842, -1.41577916, -0.91543578],
[-1.41058173, -0.97930016, -0.87050935],
[ 0.76031622, -0.91769174, 0.81146533]])
arr.sort(1)
arr
Out[180]:
array([[-0.89934378, -0.24432043, 0.29774338],
[-0.06797855, -0.02535895, 1.19498898],
[-1.41577916, -0.91543578, -0.24759842],
[-1.41058173, -0.97930016, -0.87050935],
[-0.91769174, 0.76031622, 0.81146533]])这里传入的参数axis意思是希望重新排列的维度,这里1,即是将列元素重新排列,下面是对axis参数的官方解释
axis : int or None, optional
Axis along which to sort. If None, the array is flattened before
sorting. The default is -1, which sorts along the last axis.在此提供一种计算上百分位数的方法(当然是基于采样的),原理是排列后,输出第 位的元素
large_arr = randn(1000)
large_arr.sort()
large_arr[int(0.05 * len(large_arr))]
Out[183]: -1.5999638137283376值得注意的: 顶级方法 np.sort 返回的是数组的已排列副本,而就地排列则会修改数组本身
唯一化以及其他的集合逻辑
NumPy提供一些针对一维ndarry的基本集合运算。最常用的可能要数np.unique了
unique方法返回一维数组中唯一的值
names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will'])
np.unique(names)
Out[187]:
array(['Bob', 'Joe', 'Will'],
dtype='<U4')用纯Python代码也可以实现相同的功能
sorted(set(names))
Out[188]: ['Bob', 'Joe', 'Will']in1d方法用于测试成员资格
values = np.array([6, 0, 0, 3, 2, 5, 6])
np.in1d(values, [2,3,6])
Out[190]: array([ True, False, False, True, True, False, True], dtype=bool)数组的集合运算有
- unique(x)
- intersect1d(x,y)计算公共元素并返回有序结果
- union1d(x,y)计算并集,返回有序结果
- in1d(x,y)得到一个表示“x的元素是否包含于y”的布尔类型数组
- setdiff1d(x,y)集合的差
- setxor1d(x,y)集合的对称差,不同时在两个集合中出现的元素
用于数组的文件输入输出
1)将数组以二进制形式保存到磁盘
使用save或者savez顶级方法可以把数组保存在磁盘中,不同的是后者会是压缩文件,数组以关键字形式传入,而且打开的时候会略有不同
arr = np.arange(10)np.save('C:\\...\\some_array', arr)
np.load('C:\\...\\some_array.npy')
Out[195]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])np.savez('C:\\...\\some_array.npz', a=arr, b=arr)
arch = np.load('C:\\...\\some_array.npz')
arch
Out[198]: <numpy.lib.npyio.NpzFile at 0x1b3626e7320>
arch['b']
Out[199]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])存取文件数据
以csv文件为例,以loadtxt顶级方法将数组写入txt文件
arr1 = np.loadtxt('C:\\...\\some_array.txt', delimiter = ' ')
arr1
Out[205]: array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])存放文件需要调用savetxt方法,进行的是相反的操作
np.savetxt( 'C:\\...\\some_array.txt',arr)线性代数
线性代数是任何数组库的重要组成部分。不像某些语言(如MATLAB),通过 * 对两个二维数组相乘得到的是一个元素的积,而不是一个矩阵的点积。因此,NumPy提供了一个用于矩阵乘法的dot函数(既是一个数组方法也是numpy命名空间中的一个函数)
下面两种点乘的方法是等价的
x = randn(2,3)
x
Out[208]:
array([[ 0.15559238, 1.49449673, -1.99422526],
[-0.11226719, 0.31720685, -1.22516887]])
y = randn(3,2)
x.dot(y)
Out[210]:
array([[ 4.33865103, -0.39957067],
[ 1.15569863, -0.52946933]])
np.dot(x,y)
Out[211]:
array([[ 4.33865103, -0.39957067],
[ 1.15569863, -0.52946933]])numpy.linalg中有一组标准的矩阵分解运算以及诸如求逆和行列式之类的东西
from numpy.linalg import inv,qr
X = randn(5,5)
mat = X.T.dot(X)
inv(mat)
Out[215]:
array([[ 72.20418764, 8.19885106, 59.50148537, -65.61706261,
-18.84852826],
[ 8.19885106, 1.22918189, 7.05021401, -7.56980496,
-2.33725571],
[ 59.50148537, 7.05021401, 50.36474881, -54.59396668,
-16.38856402],
[-65.61706261, -7.56980496, -54.59396668, 60.20497746,
17.36232989],
[-18.84852826, -2.33725571, -16.38856402, 17.36232989,
5.65262268]])下面是对求逆的验证
mat.dot(inv(mat))
Out[216]:
array([[ 1.00000000e+00, 1.95476672e-16, -2.46939653e-15,
6.14988415e-15, 4.56821619e-19],
[ 5.93199587e-15, 1.00000000e+00, 4.99832164e-15,
-1.88621540e-15, -3.08131420e-15],
[ -5.31931653e-14, -3.93317322e-15, 1.00000000e+00,
2.17178973e-14, 4.00687521e-15],
[ -2.13698344e-14, -1.96838412e-15, -1.01795298e-14,
1.00000000e+00, -6.89476788e-15],
[ -7.22821555e-14, -1.02214020e-14, -5.20671004e-14,
5.06812847e-14, 1.00000000e+00]])qr分解
q, r = qr(mat)
r
Out[218]:
array([[-2.2892243 , -0.92854491, 1.72436093, -1.77921582, 2.49996696],
[ 0. , -4.27812108, 0.90476811, 0.38789915, -0.35927152],
[ 0. , 0. , -7.10303235, -4.18630656, -7.84542987],
[ 0. , 0. , 0. , -0.34938752, 1.19495687],
[ 0. , 0. , 0. , 0. , 0.03222928]])常用的numpy.linalg函数
- diag 以一维数组的形式返回方阵的对角线元素
- dot 矩阵乘法
- trace 计算对角元素的和
- det 计算矩阵行列式
- eig 计算方阵本征值和本征向量
- inv、pinv(伪逆)、qr、svd、solve、lstsq
随机数生成
numpy.random模块对Python内置的random进行了补充,增加了多种概率分布的样本值的函数
下面代码可以批量产生正态样本值
sample = np.random.normal(size=(4,4))
sample
Out[221]:
array([[-0.23389552, -0.34752079, -0.05250925, -1.54045825],
[ 0.29437078, 0.60195994, 0.54874058, 2.60415144],
[-0.3864727 , -0.50628474, -1.27594881, -0.53637305],
[-0.1301617 , 0.08488417, -0.89745459, -0.25479357]])而Python内置的random模块只能一次生成一个样本值,如果希望产生大量样本值,numpy.random快了不止一个数量级。
这一点可以通过timeit魔术指令得到
可以生成的随机分布
- randn 标准正态分布
- binomial 二项分布
- normal 正态分布
- beta
分布
- chisquare 卡方分布
- gamma Gamma分布
- uniform (0,1)的均匀分布
范例:随机漫步
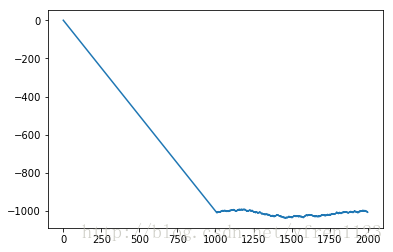
首先使用纯Python代码
from numpy import random
steps = 1000
for i in range(steps):
step = 1 if random.randint(0,2) else -1
position += step
walk.append(position)按照官方说明randint(low, high=None, size=None, dtype='l')
这个地方high应该取2才行,但是本书里面是写的1,特此说明
得到如下图像
采用numpy的方法
nsteps = 1000
draws = np.random.randint(0, 2, size=nsteps)
steps = np.where(draws > 0, 1, -1)
walk = steps.cumsum()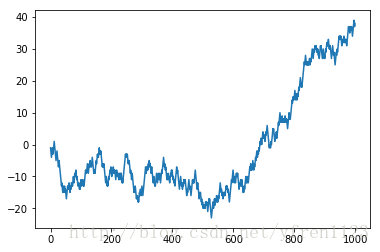
感觉比之前方法得到的图像稍微科学一些
现在可以做一些统计工作
walk.min()
Out[268]: -23
walk.max()
Out[269]: 39如果希望得到首次通过某个位子的时间,可以采用argmax方法,argmax返回出现第一次出现最大值的序号,详细说明请见附录
(np.abs(walk) >= 10).argmax()
Out[270]: 33此外,如果希望一次得到多个随机漫步,只需要对代码进行少量修改即可。
大功告成!
附录:
argmax官方说明
argmax(a, axis=None, out=None)
Returns the indices of the maximum values along an axis.本文中代码使用的Python版本是3.6,如果你是使用的Python2,可能有细微差异,即使对于两个整数之间的除法 “ / ” ,Python3中也是浮点运算
写到排序的时候,想起这学期DS里面的排序算法,忽然觉得多掌握底层知识也是很有必要的
以及这是到目前为止写的最长的一篇博文~
Never mind happiness, do your mission